文章目录
- OMP parallel
- OpenMP安装
- OpenMP示例
- 1) OMP Hello World
- 2) OMP for 并行
- 3. OMP 官方示例
- 4) map使用OMP遍历
- TBB的安装和使用
- Gcc9的安装
- TBB 安装
- TBB使用
在图像处理等应用中,我们经常需要对矩阵,大数量STL对象进行遍历操作,因此并行化对算法的加速也非常重要。
除了使用opencv提供的**parallel_for_**函数可对普通STL容器进行并行遍历,如vector。
参见 https://blog.csdn.net/weixin_41469272/article/details/126617752
本文介绍其他两种并行办法。 TBB和OMP。
OMP parallel
OpenMP安装
sudo apt install libomp-dev
OpenMP示例
1) OMP Hello World
OMP是相对使用较为简洁的并行工具,仅需在需要并行的语句前加入#pragma omp parallel,便可实现并行。
#pragma omp parallel { 每个线程都会执行大括号里的代码 }
说明:以下出现c++代码c的写法
参考:https://blog.csdn.net/ab0902cd/article/details/108770396
https://blog.csdn.net/zhongkejingwang/article/details/40350027
omp_test.cpp
#include <omp.h>
int main(){
printf("The output:\n");
#pragma omp parallel /* define multi-thread section */
{
printf("Hello World\n");
}
/* Resume Serial section*/
printf("Done\n");
}
g++ omp_test.cpp -fopenmp -o omptest
./test
Result:
The output:
Hello World
Hello World
Hello World
Hello World
Hello World
Hello World
Hello World
Hello World
Done
2) OMP for 并行
当需要将for循环并行,则可在for语句之前加上:#pragma omp parallel for
int main(int argc, char *argv[]) {
int length = 6;
float *buf = new float[length];
#pragma omp parallel for num_threads(3)
for(int i = 0; i < length; i++) {
int tid = omp_get_thread_num();
printf("i:%d is handled on thread %d\n", i, tid);
buf[i] = i;
}
}
其中num_threads用于指定线程个数。
Result
i:0 is handled on thread 0
i:1 is handled on thread 0
i:4 is handled on thread 2
i:5 is handled on thread 2
i:2 is handled on thread 1
i:3 is handled on thread 1
3. OMP 官方示例
#include <stdlib.h> //malloc and free
#include <stdio.h> //printf
#include <omp.h> //OpenMP
// Very small values for this simple illustrative example
#define ARRAY_SIZE 8 //Size of arrays whose elements will be added together.
#define NUM_THREADS 4 //Number of threads to use for vector addition.
/*
* Classic vector addition using openMP default data decomposition.
*
* Compile using gcc like this:
* gcc -o va-omp-simple VA-OMP-simple.c -fopenmp
*
* Execute:
* ./va-omp-simple
*/
int main (int argc, char *argv[])
{
// elements of arrays a and b will be added
// and placed in array c
int * a;
int * b;
int * c;
int n = ARRAY_SIZE; // number of array elements
int n_per_thread; // elements per thread
int total_threads = NUM_THREADS; // number of threads to use
int i; // loop index
// allocate spce for the arrays
a = (int *) malloc(sizeof(int)*n);
b = (int *) malloc(sizeof(int)*n);
c = (int *) malloc(sizeof(int)*n);
// initialize arrays a and b with consecutive integer values
// as a simple example
for(i=0; i<n; i++) {
a[i] = i;
}
for(i=0; i<n; i++) {
b[i] = i;
}
// Additional work to set the number of threads.
// We hard-code to 4 for illustration purposes only.
omp_set_num_threads(total_threads);
// determine how many elements each process will work on
n_per_thread = n/total_threads;
// Compute the vector addition
// Here is where the 4 threads are specifically 'forked' to
// execute in parallel. This is directed by the pragma and
// thread forking is compiled into the resulting exacutable.
// Here we use a 'static schedule' so each thread works on
// a 2-element chunk of the original 8-element arrays.
#pragma omp parallel for shared(a, b, c) private(i) schedule(static, n_per_thread)
for(i=0; i<n; i++) {
c[i] = a[i]+b[i];
// Which thread am I? Show who works on what for this samll example
printf("Thread %d works on element%d\n", omp_get_thread_num(), i);
}
// Check for correctness (only plausible for small vector size)
// A test we would eventually leave out
printf("i\ta[i]\t+\tb[i]\t=\tc[i]\n");
for(i=0; i<n; i++) {
printf("%d\t%d\t\t%d\t\t%d\n", i, a[i], b[i], c[i]);
}
// clean up memory
free(a); free(b); free(c);
return 0;
}
Result:
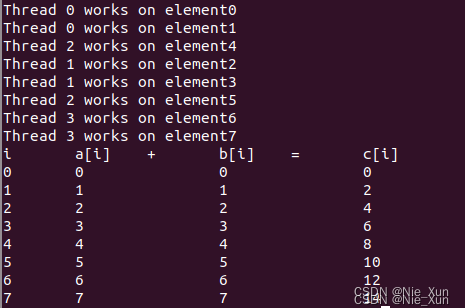
其中,shared括号中说明所有线程公用的变量名,private括号中的变量为各个线程均独立的变量。
schedule()用于指定循环的线程分布策略,默认为static。
具体不同:
schedule(kind [, chunk_size])
kind:
• static: Iterations are divided into chunks of size chunk_size. Chunks are assigned to threads in the team in round-robin fashion in order of thread number.
• dynamic: Each thread executes a chunk of iterations then requests another chunk until no chunks remain to be distributed.
• guided: Each thread executes a chunk of iterations then requests another chunk until no chunks remain to be assigned. The chunk sizes start large and shrink to the indicated chunk_size as chunks are scheduled.
• auto: The decision regarding scheduling is delegated to the compiler and/or runtime system.
• runtime: The schedule and chunk size are taken from the run-sched-var ICV
static: OpenMP会给每个线程分配chunk_size次迭代计算。这个分配是静态的,线程分配规则根据for的遍历的顺序。
dynamic:动态调度迭代的分配是依赖于运行状态进行动态确定的,当需要分配新线程时,已有线程结束,则直接使用完成的线程,而不开辟新的线程。
guided:循环迭代划分成块的大小与未分配迭代次数除以线程数成比例,然后随着循环迭代的分配,块大小会减小为chunk值。chunk的默认值为1。开始比较大,以后逐渐减小。
runtime:将调度决策推迟到指定时开始,这选项不能指定块大小?(暂未测试)
参考:
https://blog.csdn.net/gengshenghong/article/details/7000979
https://blog.csdn.net/yiguagua/article/details/107053043
4) map使用OMP遍历
关于invalid controlling predicate的问题
OMP不支持终止条件为“!=”或者“==”的for循环,因为无法判断循环的数量。
int main()
{
map<int,int> mii;
map<int, string> mis;
for (int i = 0; i < 50; i++) {mis[i] = to_string(i);}
clock_t start,end;
start = clock();
#if 1
mutex m;
auto it = mis.begin();
#pragma omp parallel for num_threads(3) shared(it)
//Error '!=" can not be used in omp: invalid controlling predicate
for (int i = 0; i < mis.size(); i++)
{
int tid = omp_get_thread_num();
m.lock();
mii[it->first] = atoi(it->second.c_str());
cout << "Thread " << tid << " handle " << it->first << endl;
m.unlock();
it++;
}
#else
for (auto it : mis)
{
int tid = omp_get_thread_num();
mii[it.first] = atoi(it.second.c_str());
cout << "Thread " << tid << " handle " << it.first << endl;
}
#endif
end = clock();
cout<<"time = "<<double(end-start)/CLOCKS_PER_SEC<<"s"<<endl;
for (auto it = mii.begin(); it != mii.end(); it++)
{
cout << "it->first: " << it->first << " it->second: " << it->second << endl;
}
}
Result:
加OMP:time = 0.000877s
不加并行:time = 0.001862s
TBB的安装和使用
关于Intel的oneTBB工具与g++版本相互制约,因此在安装时较为麻烦
以下测试选择的工具版本:
TBB:v2020.0
Gcc:9.4
Gcc9的安装
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt-get update
sudo apt-get install gcc-9 g++-9
TBB 安装
wget https://github.com/oneapi-src/oneTBB/archive/refs/tags/v2020.0.tar.gz
tar zxvf v2020.0.tar.gz
cd oneTBB
cp build/linux.gcc.inc build/linux.gcc-9.inc
修改 build/linux.gcc-9.inc 15,16 行:
CPLUS ?= g++-9
CONLY ?= gcc-9
#build
make compiler=gcc-9 stdver=c++17 -j20 DESTDIR=install tbb_build_prefix=build
#***************************** TBB examples build *****************************************
#build test code:
g++-9 -std=c++17 -I ~/Download/softpackages/oneTBB/install/include/ -L/home/niebaozhen/Download/ softpackages/oneTBB/install/lib/ std_for_each.cpp -ltbb -Wl,-rpath=/home/niebaozhen/Download/soft packages/oneTBB/install/lib/
参考链接:https://blog.csdn.net/weixin_32207065/article/details/112270765
Tips:
当TBB版本大于v2021.1.1时,cmake被引入,但是该版本TBB不支持gcc9/10
但是gcc版本高等于9时,才支持对TBB的使用,且编译标准建议为c++17。
说明链接
v2021.1.1版本编译命令
#tbb version >= v2021.1.1: cmake employed, however,
#libc++9&10 are incompatible with TBB version > 2021.xx
mkdir build install
cd build
cmake -DCMAKE_INSTALL_PREFIX=../install/ -DCMAKE_CXX_STANDARD=17 -DCMAKE_CXX_COMPILER=/usr/bin/g++-9 -DTBB_TEST=OFF ..cmake -DCMAKE_INSTALL_PREFIX=../install/ -DTBB_TEST=OFF ..
make -j30
make install
TBB使用
std_for_each.cpp
#include <iostream>
#include <unistd.h>
#include <map>
#include <algorithm>
#include <chrono>
#define __MUTEX__ 0
#if __MUTEX__
#include <mutex>
#endif
#if __GNUC__ >= 9
#include <execution>
#endif
using namespace std;
int main ()
{
//cout << "gnu version: " << __GNUC__ << endl;
int a[] = {0,1,3,4,5,6,7,8,9};
map<int, int> mii;
#if __MUTEX__
mutex m;
#endif
auto tt1 = chrono::steady_clock::now();
#if __GNUC__ >= 9
for_each(execution::par, begin(a), std::end(a), [&](int i) {
#else
for_each(begin(a), std::end(a), [&](int i) {
#endif
#if __MUTEX__
lock_guard<mutex> guard(m);
#endif
mii[i] = i*2+1;
//sleep(1);
//cout << "Sleep one second" << endl;
});
auto tt2 = chrono::steady_clock::now();
auto dt = chrono::duration_cast<chrono::duration<double>>(tt2 - tt1);
cout << "time = " << dt.count() << "s" <<endl;
for(auto it = mii.begin(); it != mii.end(); it++) {
cout << "mii[" << it->first << "] = " << it->second << endl;
}
}
build:
g++ std_for_each.cpp
或:
g++-9 -std=c++17 -I ~/Download/softpackages/oneTBB/install/include/ -L/home/niebaozhen/Download/softpackages/oneTBB/install/lib/ std_for_each.cpp -ltbb -Wl,-rpath=/home/niebaozhen/Download/softpackages/oneTBB/install/lib/
Result:
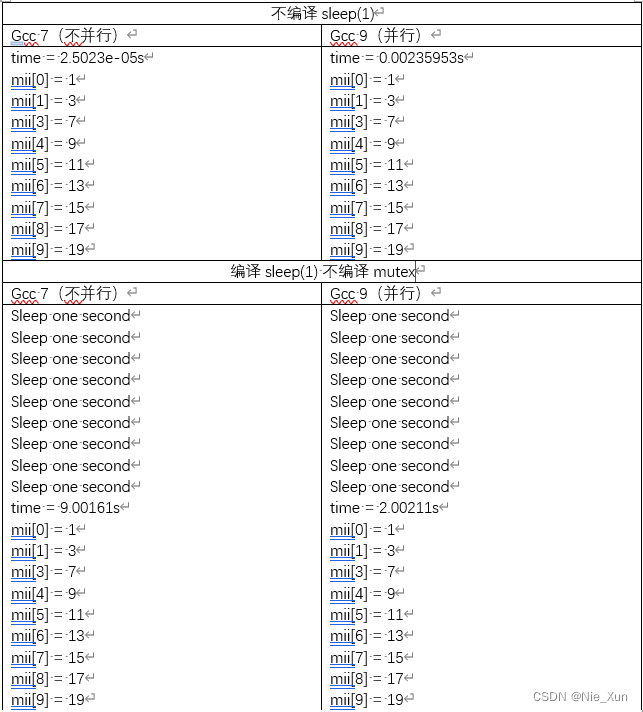
可以看出,当遍历所操作的工作比较少时,并行反而会带来更多的耗时。
当遍历的操作较多,这里sleep来模拟较多的工作,并行体现出优势。
总之:






![运行Spring Boot项目时[ java: 错误: 不支持发行版本 17 ]](https://img-blog.csdnimg.cn/ff6316686e8c4b2ab3c1f8933984eed7.png)