目录
一.引入
二. 什么是文件
2.1 什么是文件
2.2 程序文件
2.3 数据文件
2.4 文件名
三.文件的打开和关闭
3.1 文件指针
3.2 文件的打开和关闭
四.文件的顺序读写
4.1 函数汇总
4.2 printf/fprintf/sprintf
4.3 scanf/fscanf/sscanf
五. 文件的随机读写
5.1 引入
5.2 fseek()
5.3 ftell()
5.4 rewind()
六. 文本文件和二进制文件
七. 文件读取结束的判定
7.1 被误解的feof()
7.2 如何判定文件读取结束
7.3 使用示例
八. 文件缓冲区
8.1 为什么要有文件缓冲区
8.2 什么是文件缓冲区
8.3 感受文件缓冲区的存在
一.引入
我们知道,当我们程序开始运行时,数据是保存在内存中的,由于内存中的数据具有易失性,当我们关闭程序后本程序在内存中的数据将会丢失。但是往往在许多程序我们需要将数据保存起来,例如通讯录、信息管理系统等等,我们需要将录入的数据存放起来,在使用时将数据读取出来,这又该怎么做呢?
我们一般使数据持久化的方法有:将数据存放在磁盘文件中,将数据存放在数据库中等方式。
本期我们介绍的就是如何把数据存放文件中,使用文件我们可以将数据直接存放到我们电脑的硬盘中,实现数据的持久化。
二. 什么是文件
2.1 什么是文件
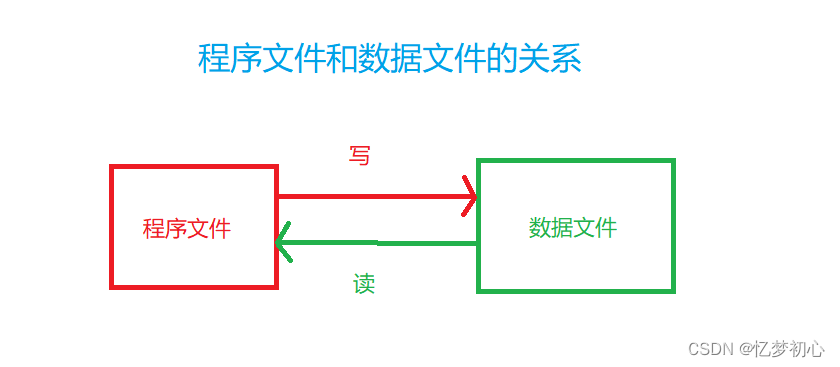
文件想必各位都不陌生。在我们电脑上,存放在C盘,D盘等硬盘上的文件就称作文件。只不过在我们程序设计中,我们一般谈到的文件有两种:程序文件和数据文件。(按文件功能来分类)
2.2 程序文件
包括我们自己编写的源文件(后缀为.c、.cpp等等),目标文件(windows环境后缀为.obj),可执行文件(windows环境后缀为.exe)
2.3 数据文件
文件的内容不一定是程序,而是程序运行时需要读写的数据,例如程序运行需要从中读取数据的文件, 或者输出内容的文件。
本期我们将要讨论的就是数据文件。
在过去,我们对数据进行输入输出都是以终端为对象,即从终端的键盘读取数据,将数据输出到终端的显示器。实际上,键盘和显示器也可以当作数据文件。
而在有些时候,我们会把信息输出到磁盘上,当需要的时候再从磁盘上把数据读取到内存中使用,这里处理的就是磁盘上文件。
2.4 文件名
一个文件要有一个唯一的文件标识,以便用户识别和引用。
文件标识包含三个部分:文件路径+文件名主干+文件后缀
例如: c:\code\test.txt,这就是一个文件标识。其中c:\code\就是文件路径,test是文件名主干,txt是文件后缀,代表是一个文本文件。
另外:为了方便起见,文件标识常被称为文件名
三.文件的打开和关闭
3.1 文件指针
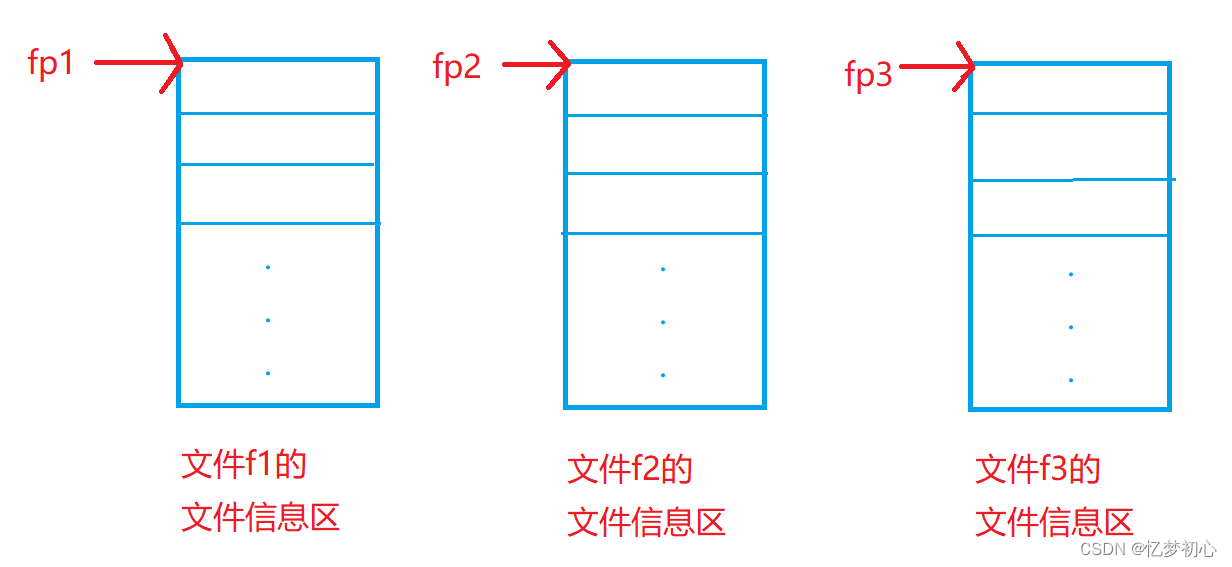
每个被打开使用的文件都会在内存中开辟一个相应的文件信息区,用来存放文件的相应信息(如文件的名字,文件状态及文件当前的位置等)。这些信息是保存在一个结构体变量中的。该结构体类型是由系统声明的,取名为FILE。文件指针就是一个FILE*类型的指针。
例如,在VS2013编译环境提供的 stdio.h 头文件中有以下的FILE类型声明:
struct _iobuf
{
char *_ptr;
int _cnt;
char *_base;
int _flag;
int _file;
int _charbuf;
int _bufsiz;
char *_tmpfname;
};
//类型重命名
typedef struct _iobuf FILE;注:在不同的C编译器中FILE类型包含的内容可能有所差异,但是大同小异。
每当文件打开时,系统会根据文件的情况自动创建一个FILE结构的变量,并填充其中的信息, 使用者不必关心细节。我们一般通过FILE*文件指针来维护这个结构体变量(文件信息区),可以创建一个文件指针变量如下:
FILE* fp; //文件指针变量上面的pf就是一个指向FILE类型数据的指针变量,可以使pf指针指向文件信息区(FILE类型的结构体变量)。通过文件信息区的内容就可以访问该文件。换句话说,通过pf文件指针变量能够找到与它关联的文件。例如:
3.2 文件的打开和关闭
在文件进行读写之前要打开文件,在使用结束之后要关闭文件。
在我们编写的程序中,当我们打开文件,都会返回一个FILE*类型的指针变量指向该文件,相当于建立了指针和文件的关系。
在ANSIC标准中,规定使用fopen函数打开文件,用fclose函数关闭文件。

打开方式如下表所示:
| 文件使用方式 | 含义 | 如果指定文件不存在 |
| “r” (只读) | 为了输入数据,打开一个已经存在的文本文件 | 出错 |
| “w” (只写) | 为了输出数据,打开一个文本文件 | 建立一个新的文件 |
| “a” (追加) | 向文本文件末尾追加数据 | 建立一个新的文件 |
| “rb” (只读) | 为了输入数据,打开一个已经存在的二进制文件 | 出错 |
| “wb” (只写) | 为了输出数据,打开一个的二进制文件 | 建立一个新的文件 |
| “ab” (追加) | 向一个二进制文件尾追加数据 | 出错 |
| “r+” (读写) | 为了读和写,打开一个文本文件 | 出错 |
| “w+” (读写) | 为了读和写,建立一个新的文件 | 建立一个新的文件 |
| “a+” (读写) | 打开一个文件,在文件尾进行读写 | 建立一个新的文件 |
| “rb+” (读写) | 为了读和写,打开一个二进制文件 | 出错 |
| “wb+” (读写) | 为了读和写,建立一个新的二进制文件 | 建立一个新的文件 |
| “ab+” (读写) | 打开一个二进制文件,在文件尾进行读和写 | 建立一个新的文件 |
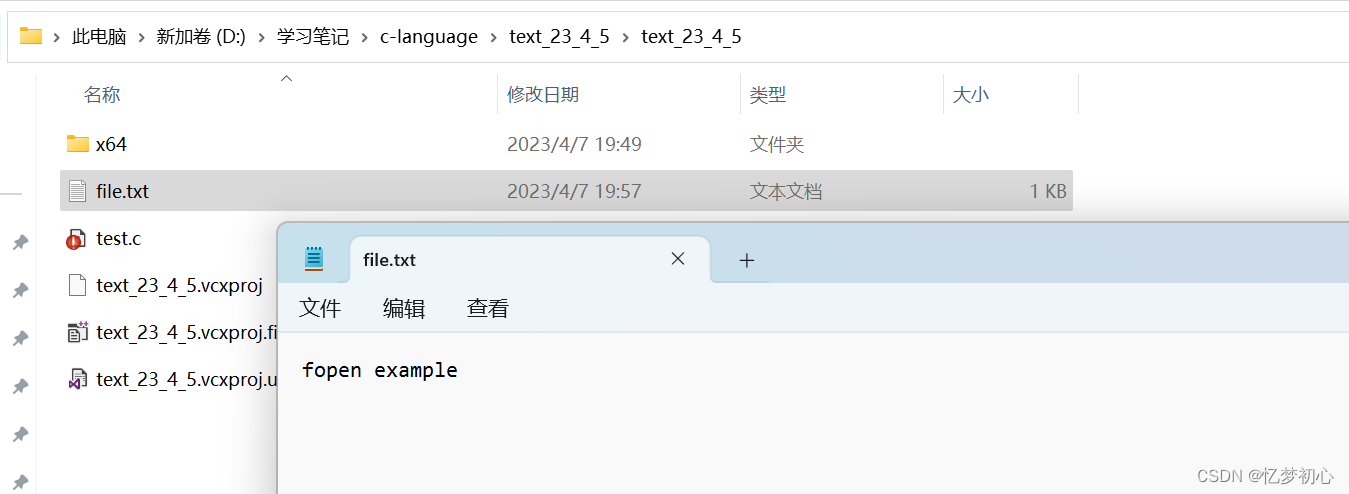
例如,我们可以以写的方式打开file.txt进行操作:
#include<stdio.h>
int main()
{
FILE* fp;
//打开文件
fp = fopen("file.txt", "w");
//打开失败
if (fp == NULL)
{
printf("open file false\n");
exit(-1);
}
//打开成功
//输出到文件
fputs("fopen example", fp);
//关闭文件
fclose(fp);
fp = NULL;
return 0;
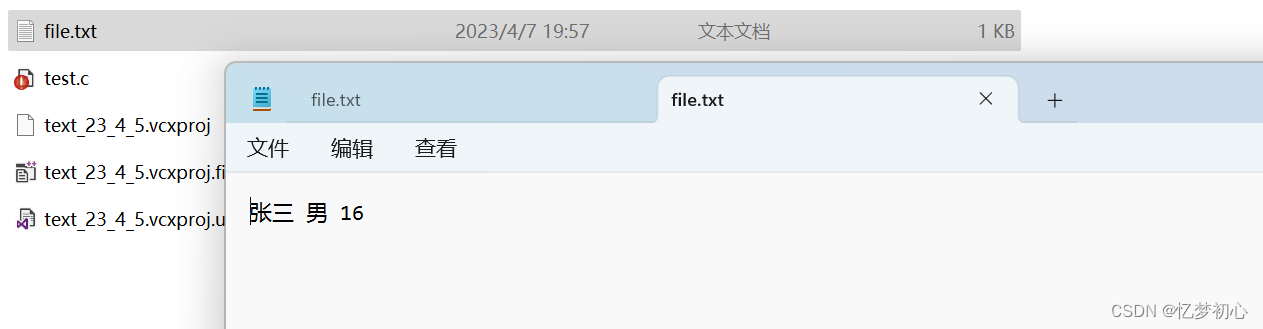
}我们编译代码运行后就可以在当前项目目录下找到file.txt文件,文件的内容为我们输出的内容:
四.文件的顺序读写
4.1 函数汇总
C语言给我们提供了许多函数来实现对文件的顺序读写操作,如下表所示:
| 函数名 | 功能 | 适用于 |
| fgetc | 字符输入函数 | 所有输入流 |
| fputc | 字符输出函数 | 所有输出流 |
| fgets | 文本行输入函数 | 所有输入流 |
| fputs | 文本行输出函数 | 所有输出流 |
| fscanf | 格式化输入函数 | 所有输入流 |
| fprintf | 格式化输出函数 | 所有输入流 |
| fread | 二进制输入函数 | 文件 |
| fwrite | 二进制输出函数 | 文件 |
这里可能有人会想:好多函数啊,脑子不够用呀。不用记,作为一个程序员要学会利用工具,这里推荐一个网站:cplusplus.com - The C++ Resources Network ,我们可以通过这个网站来搜索一些我们需要的函数,例如:
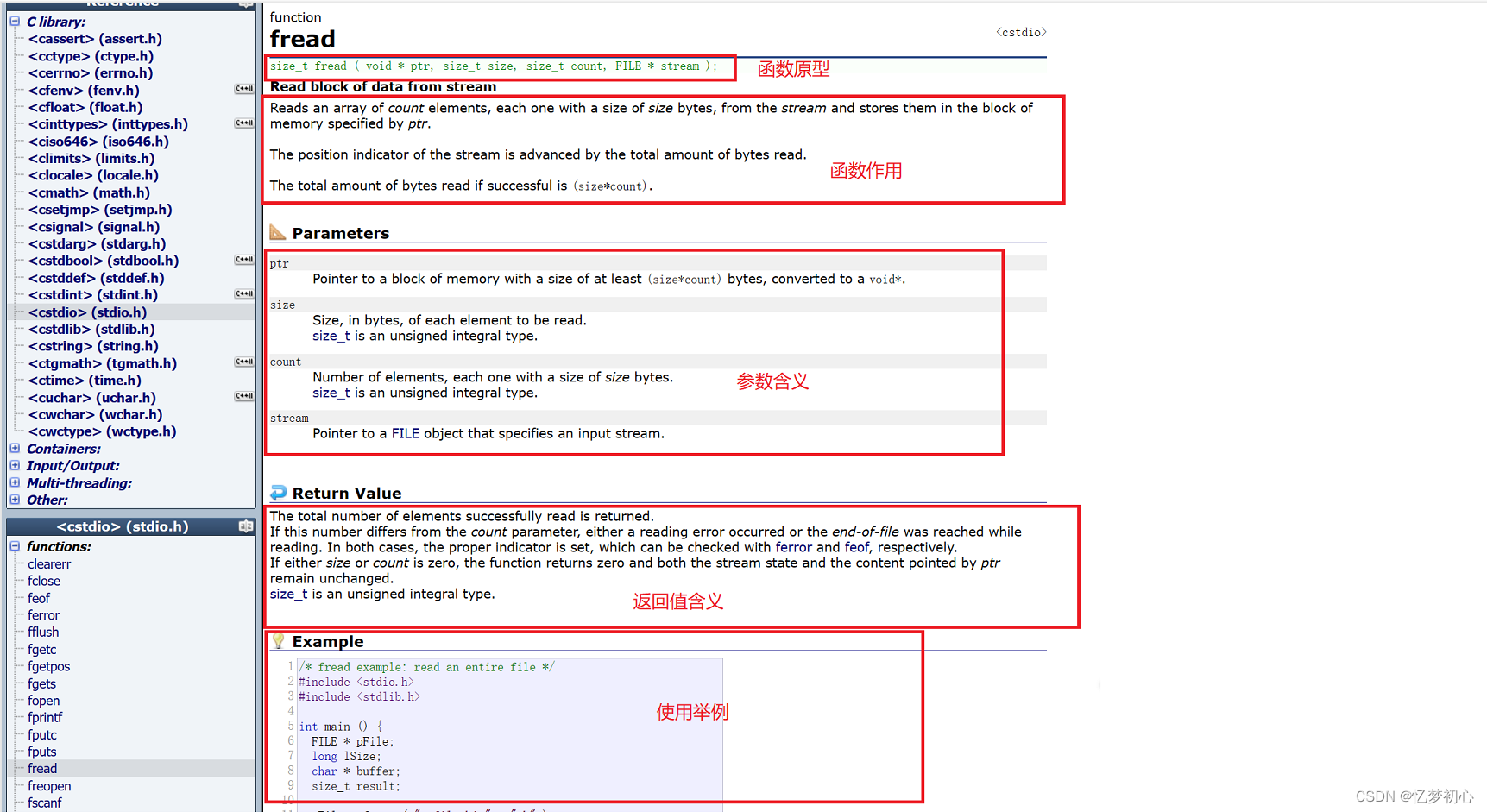
我们可以从中获得许多我们需要的信息。熟能生巧,当我们使用的次数多了,自然而然就记住了。即使你忘了,查一下不就好了。
4.2 printf/fprintf/sprintf
下面我们来对比一下这组很相似的函数:
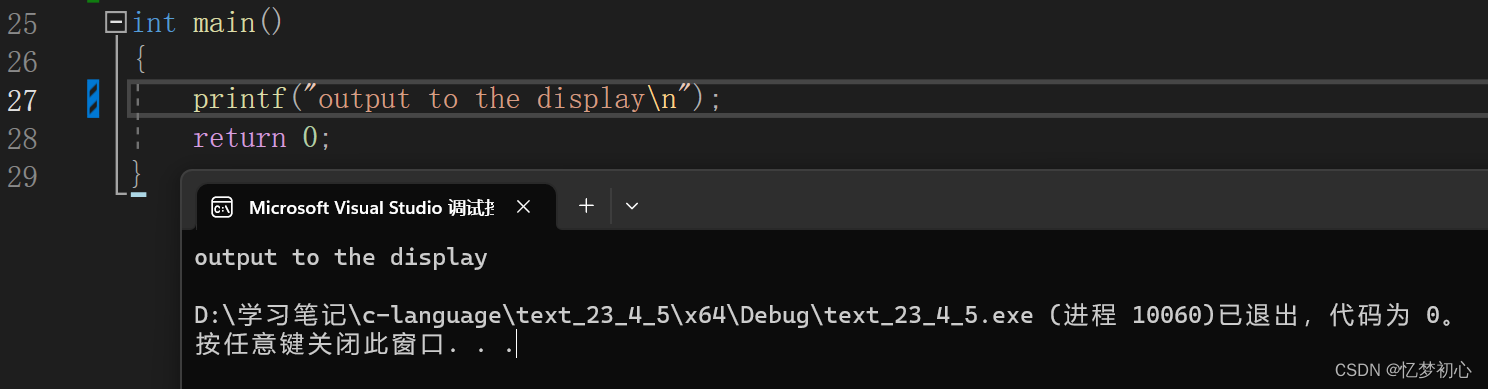
- printf()我们已经很熟悉了,将数据格式化输出到标准输出设备上,即输出到我们的显示器:
2.fprintf()的原型如下:
 它和printf函数的差别就是多了一个文件指针类型的参数。fprintf()函数可以将数据格式化输出到文件当中,如下:
它和printf函数的差别就是多了一个文件指针类型的参数。fprintf()函数可以将数据格式化输出到文件当中,如下:
struct Student
{
char name[20];
char sex[5];
int age;
};
int main()
{
FILE* fp;
struct Student s = { "张三","男",16 };
//打开文件
fp = fopen("file.txt", "w");
//打开失败
if (fp == NULL)
{
printf("open file false\n");
exit(-1);
}
//打开成功
//格式化输出到文件
fprintf(fp, "%s %s %d", s.name, s.sex, s.age);
//关闭文件
fclose(fp);
fp = NULL;
return 0;
}
fprintf()函数除了可以将数据格式化输出到文件中,也可以和printf一样将数据输出到我们的显示器上,只需指定第一个参数为stdout(标准输出流)即可,如下:
struct Student
{
char name[20];
char sex[5];
int age;
};
int main()
{
struct Student s = { "张三","男",16 };
//格式化输出到显示器(标准输出设备)
fprintf(stdout, "%s %s %d", s.name, s.sex, s.age);
return 0;
}
3.sprintf()函数的原型如下:

类似的,sprintf比起printf多了一个char*类型的参数。我们可以猜测一下:fprintf()可以将数据格式化输出到文件中,那sprintf是不是将数据格式化输出到字符串中呢?恭喜你猜对了!<撒花><撒花>
第一个参数就是指向目标字符串,它的用法也和printf基本一致,将数据格式化打印到目标字符串中,如下:
int main()
{
int a = 100;
char c = 'a';
char dest[20] = { 0 };
//输出到字符串dest中
sprintf(dest, "%d%c", a, c);
//打印字符串dest
printf("%s", dest);
return 0;
}
在一些情景下sprintf()函数可能会有妙用,例如我们需要将整型等数据转化为字符串,使用sprintf函数可以很方便的做到。
4.3 scanf/fscanf/sscanf
与printf相对应,scanf也有三组非常相似的函数:
1.scanf()函数作用就是从标准输入设备中格式化输入数据到内存当中,即从键盘中格式化输入数据到内存中:
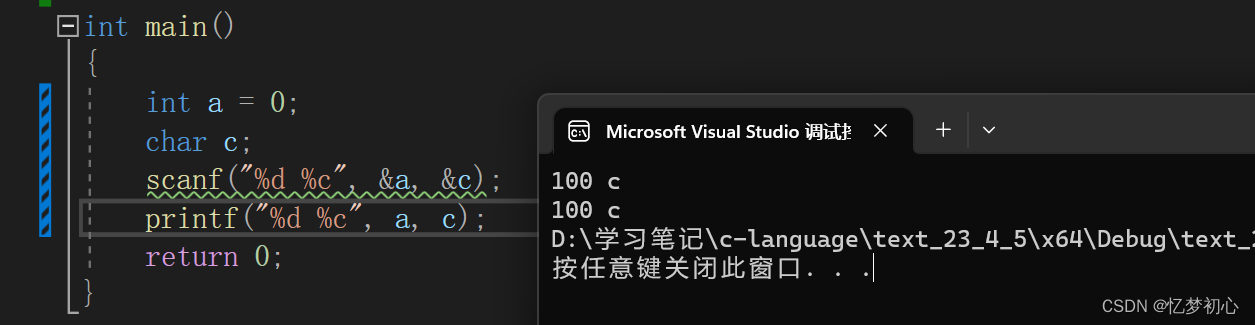
2.fscanf()函数的原型如下:

它和scanf函数的差别也是多了一个文件指针类型的参数。fscanf函数是将文件的数据内容格式化输入到内存当中,如下:
struct Student
{
char name[20];
char sex[5];
int age;
};
int main()
{
FILE* fp;
struct Student s;
//打开文件,以读的形式
fp = fopen("file.txt", "r");
//打开失败
if (fp == NULL)
{
printf("open file false\n");
exit(-1);
}
//打开成功
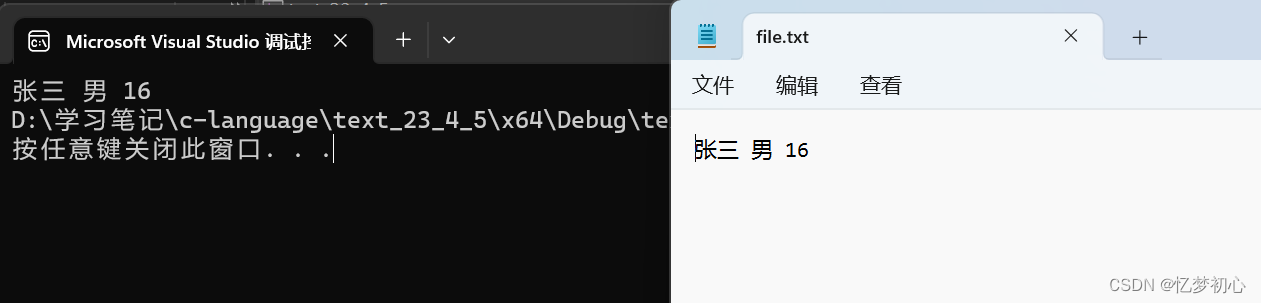
//将文件的内容格式化输入到结构体s中
fscanf(fp, "%s %s %d", s.name, s.sex, &s.age);
//显示结构体s内容
printf("%s %s %d", s.name, s.sex, s.age);
//关闭文件
fclose(fp);
fp = NULL;
return 0;
}
与fprintf同理,fscanf函数除了可以将文件的内容格式化输入到内存中,也可以像scanf函数一样从键盘上输入数据到内存中,只需指定第一个参数为stdin(标准输入流)即可,如下:
struct Student
{
char name[20];
char sex[5];
int age;
};
int main()
{
struct Student s;
//从键盘格式化输入数据(标准输入设备)
fscanf(stdin, "%s %s %d", s.name, s.sex, &s.age);
//显示结构体s内容
printf("%s %s %d", s.name, s.sex, s.age);
return 0;
}
3.sscanf()函数的函数原型如下:

它的作用是将字符串的内容格式化输入到内存的对应空间中,第一个参数s指向一个字符串的首元素地址,这个字符串就是我们的数据来源。如下:
struct Student
{
char name[20];
char sex[5];
int age;
};
int main()
{
char src[20] = "wangwu 男 19";
struct Student s;
//将字符串src内容格式化输入到结构体s中
sscanf(src, "%s %s %d",s.name ,s.sex,&s.age);
//打印结构体s内容
printf("%s %s %d", s.name, s.sex, s.age);
return 0;
}
利用sprintf()函数我们可以将整型等数据转化为字符串,而利用sscanf()函数我们可以将字符串转化为整型等数据。
五. 文件的随机读写
5.1 引入
前面几个函数都是对文件进行顺序读写,每次进行一次读写操作后文件指针都会移动到下一个位置。下面我们再介绍一些有关文件的随机读写的函数,通过这些函数我们可以更加灵活地对文件进行操作,可以让文件指针的反复横跳(qwq)。
5.2 fseek()
其作用是:根据文件指针的位置和偏移量来定位文件指针。
 对于第三个参数起始位置,我们有三个位置可以选择,分别用三个宏来定义,如下:
对于第三个参数起始位置,我们有三个位置可以选择,分别用三个宏来定义,如下:
| 宏名称 | 含义 |
| SEEK_SET | 文件的起始位置 |
| SEEK_CUR | 当前文件指针的所处位置 |
| SEEK_END | 文件末尾 |
以下是一个使用例子:
#include <stdio.h>
int main()
{
FILE* pFile;
pFile = fopen("example.txt", "wb");
//输出到文件
fputs("This is an apple.", pFile);
//将文件指针偏移到文件头向后9字节处,即移动到字符n处
fseek(pFile, 9, SEEK_SET);
//从当前文件指针的位置开始写入,覆盖
fputs(" sam", pFile);
fclose(pFile);
return 0;
}
使用fseek()函数需要注意的是:
对于二进制模式打开的二进制文件:文件指针的新位置可以通过上述三个参考起始位置加上偏移量来定义。
而对于文本模式打开的文本文件:文件指针的偏移量应是0或者先前调用ftell()函数返回的值,且起始位置应是SEEK_SET。如果使用其他参数,则取决于特定的库和系统,即不具有可移植性。下面我们来介绍一下ftell()这个函数。
5.3 ftell()
其作用是:返回文件指针相对于起始位置的偏移量。
 函数只有一个参数,就是我们的文件指针。当函数调用成功时,返回当前文件指针相对于文件开头所处的偏移量;如果函数调用失败,则返回-1。
函数只有一个参数,就是我们的文件指针。当函数调用成功时,返回当前文件指针相对于文件开头所处的偏移量;如果函数调用失败,则返回-1。
以下是使用例子:
#include <stdio.h>
int main()
{
FILE* pFile;
pFile = fopen("example.txt", "wb");
//输出到文件
fputs("This is an apple.", pFile);
printf("当前文件指针偏移量为:%ld\n", ftell(pFile));
//将文件指针偏移到文件头向后9字节处,即移动到字符n处
fseek(pFile, 9, SEEK_SET);
printf("更新后文件指针偏移量为:%ld\n", ftell(pFile));
//从当前文件指针的位置开始写入,覆盖
fputs(" sam", pFile);
fclose(pFile);
return 0;
}
5.4 rewind()
其作用是:让文件指针的位置回到文件的起始位置

以下是使用例子:
#include <stdio.h>
int main()
{
int n;
FILE* pFile;
char buffer[27];
//以读写的形式打开一个文本文件
pFile = fopen("myfile.txt", "w+");
//将字母‘A’-‘Z’写入文件
for (n = 'A'; n <= 'Z'; n++)
{
fputc(n, pFile);
}
//文件指针回到开头
rewind(pFile);
//从文件开头读26个字节到buffer数组中,即把‘A’-‘Z’读入数组
fread(buffer, 1, 26, pFile);
//关闭文件
fclose(pFile);
buffer[26] = '\0';
//输出buffer数组到显示器
puts(buffer);
return 0;
}
六. 文本文件和二进制文件
根据数据的组织形式,数据文件又被称为文本文件和二进制文件。我们上面也有提过这两种文件,那究竟什么是文本文件,二进制文件又是什么呢?
我们知道,数据在内存中以二进制的形式存储,如果我们不加以转换直接将内存中的数据输出到文件中,那这个文件就是二进制文件。如果我们直接查看,是看不懂的。
如果要求在文件中以ASCII码的形式存储,则需要在存储前进行转换。以ASCII字符的形式存储的文件就是文本文件。这是我们看得懂的。
那么,数据在文件中是怎么存储的呢?
字符一律以ASCII码形式存储,数值型数据既可以用ASCII形式存储,也可以使用二进制形式存储。
例如:整数10000,如果以ASCII码的形式输出到文件,则文件中占用5个字节(每个字符一个字节),而二进制形式输出,则在磁盘上只占4个字节(一个整型的大小)。
我们可以测试一下:
//测试代码
#include <stdio.h>
int main()
{
int a = 10000;
FILE* pf1 = fopen("test1.txt", "wb");
FILE* pf2 = fopen("test2.txt", "w");
fwrite(&a, 4, 1, pf1);//二进制的形式写到文件1中
fprintf(pf2, "%d", a);//以ASCII码的形式写到文件中
fclose(pf1);
fclose(pf2);
pf1 = NULL;
pf2 = NULL;
return 0;
}结果如下,和我们的预期相符:
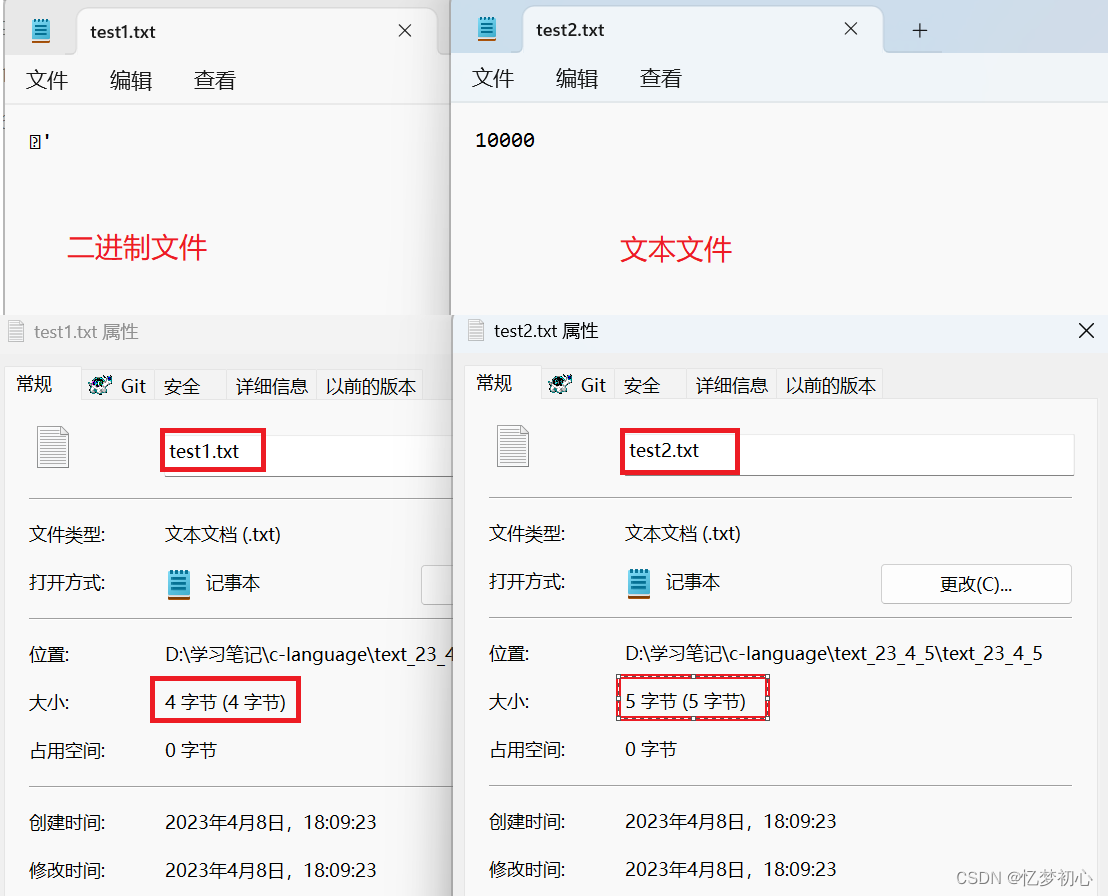
如果你还不确定,我们可以使用VS中的二进制编辑器查看两个文件的二进制信息:
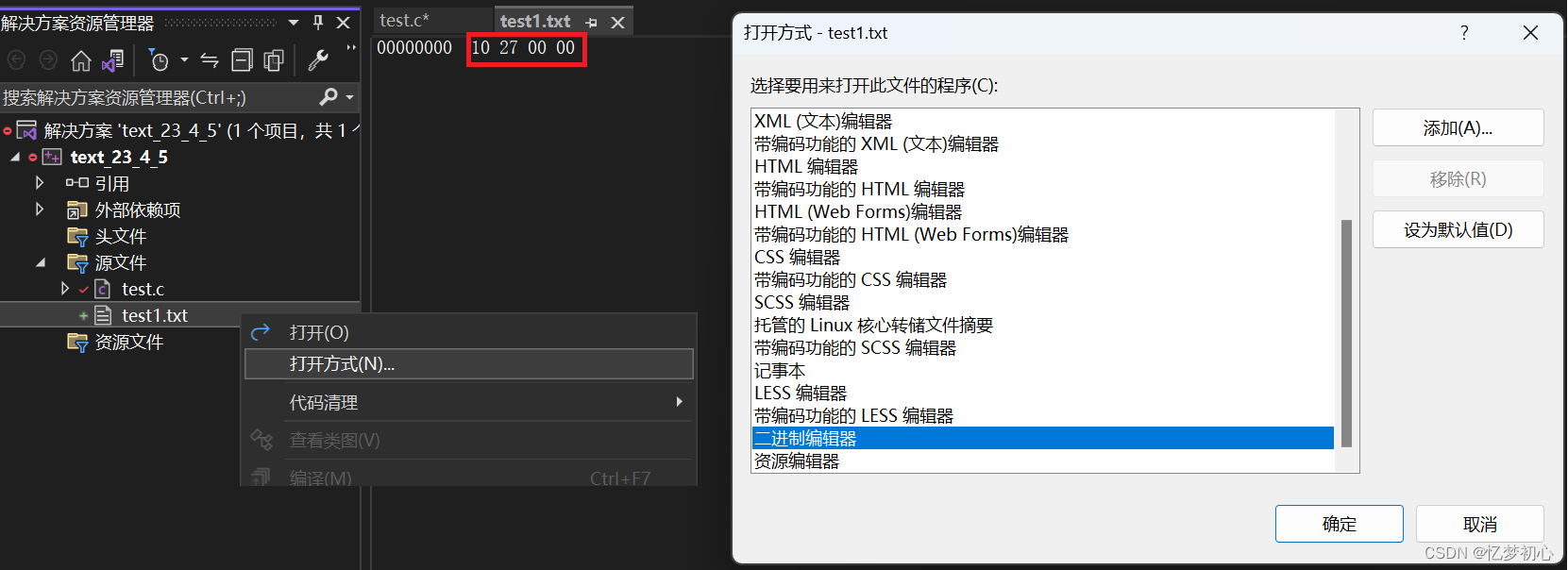
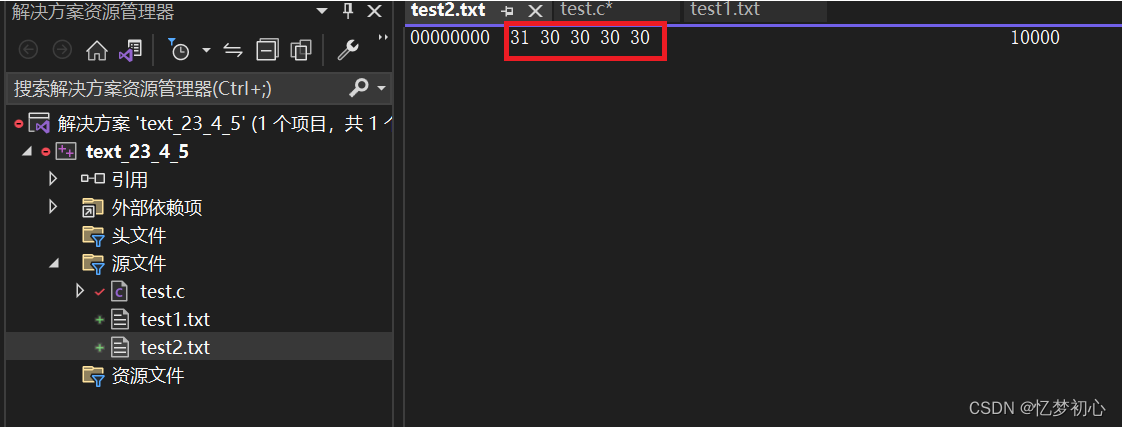
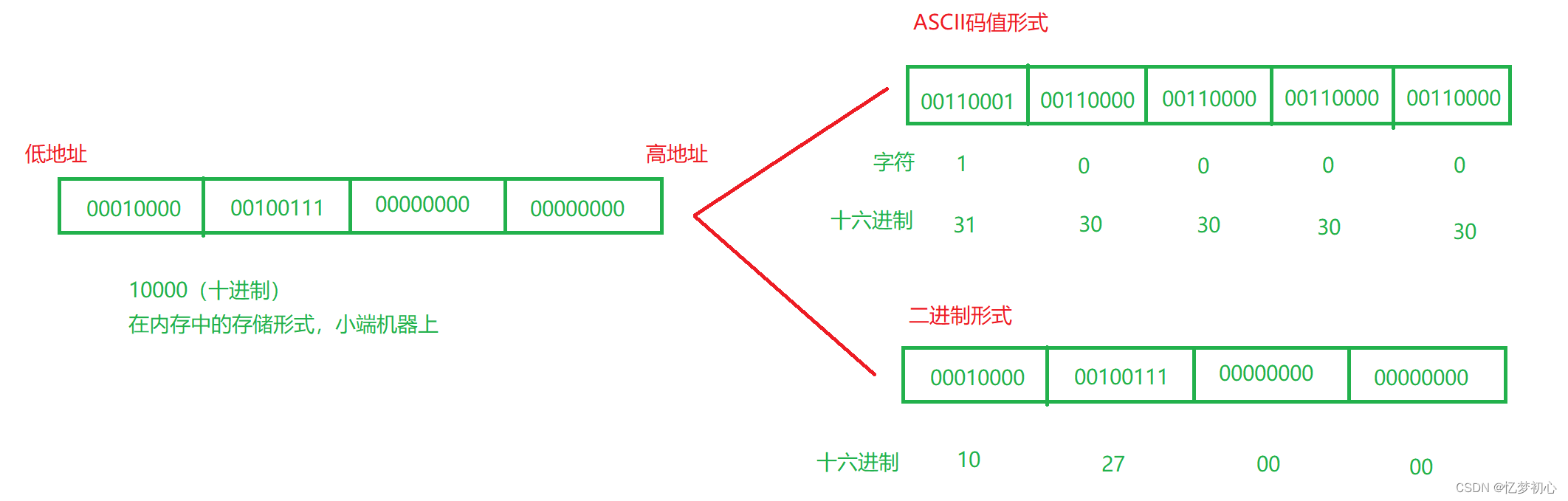
综上,我们发现两个文件的二进制内容和我们分析的如出一辙,证明了我们之前的结论是正确的。
七. 文件读取结束的判定
7.1 被误解的feof()
很多人使用feof()函数来判断一个文件是否结束,实际上这是错误的做法。
feof()函数的作用不是判断文件是否结束,而是当文件读取结束时,判断是因为读取失败而结束,还是遇到文件末尾的EOF而结束。如果读取失败而结束则返回0,遇到文件末尾结束则返回非0值。
与之对应的还有ferror()函数,这个函数也是用来判断文件是因为什么原因才读取结束。当读取失败而结束则返回非0值,当遇到文件末尾结束则返回0。
那么,这两个函数是如何来判断文件是出于哪种原因结束呢?
事实上,当我们进行文件读取时,如果遇到文件末尾,会设置一个EOF指示器;而如果遇到错误结束,就会设置一个error指示器。feof()和ferror()函数就是通过检查是否设置的对应的指示器来判断文件出于何种原因结束。如下:

7.2 如何判定文件读取结束
这与我们使用什么函数读取文件,读取什么类型的文件具有很大的关联。不同的函数判断结束的方式可能有所不同,例如:
- 文本文件判断是否读取结束,应判断返回值是否为EOF(fgetc函数),或者返回值是否为NULL(fges函数)。

- 二进制文件判断是否读取结束,应判断fread()返回值是否小于实际要读的个数。

7.3 使用示例
对于文本文件,我们可以这样进行判断:
#include <stdio.h>
#include <stdlib.h>
int main()
{
int c; // 注意:这里使用int而非char类型是为了判断是否为EOF(-1)
FILE* fp = fopen("test3.txt", "r");
//文件打开失败
if (!fp)
{
perror("File opening failed");
return EXIT_FAILURE;
}
//文件打开成功
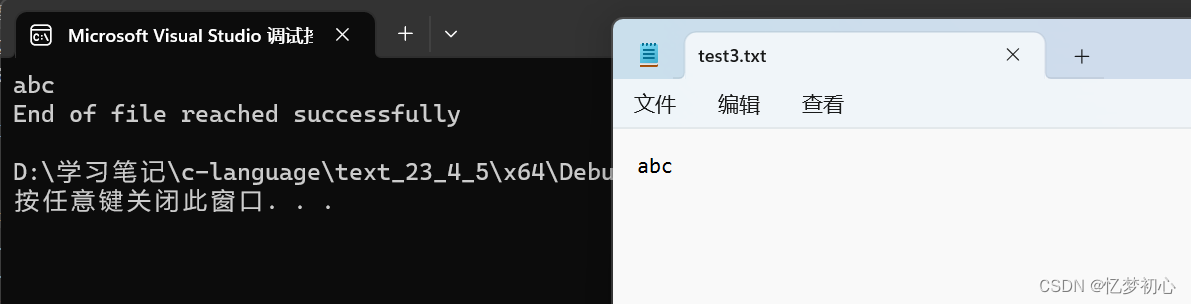
//fgetc 当读取失败结束或者遇到文件尾结束的时候,都会返回EOF
while ((c = fgetc(fp)) != EOF) // 标准C I/O读取文件循环
{
putchar(c);
}
//文件读取结束
//判断是什么原因结束的
if (ferror(fp))
puts("\nI/O error when reading");
else if (feof(fp))
puts("\nEnd of file reached successfully");
fclose(fp);
fp=NULL;
}
对于二进制文件,我们可以这样进行判断:
#include <stdio.h>
#define SIZE 5
int main(void)
{
double a[SIZE] = { 1.0,2.0,3.0,4.0,5.0 };
FILE* fp = fopen("test.bin", "wb"); // 用二进制模式写入
fwrite(a, sizeof(a[0]), SIZE, fp); // 写 double 的数组
fclose(fp);
double b[SIZE];
fp = fopen("test.bin", "rb");// 用二进制模式读出
size_t ret_code = fread(b, sizeof * b, SIZE, fp); // 读 double 的数组
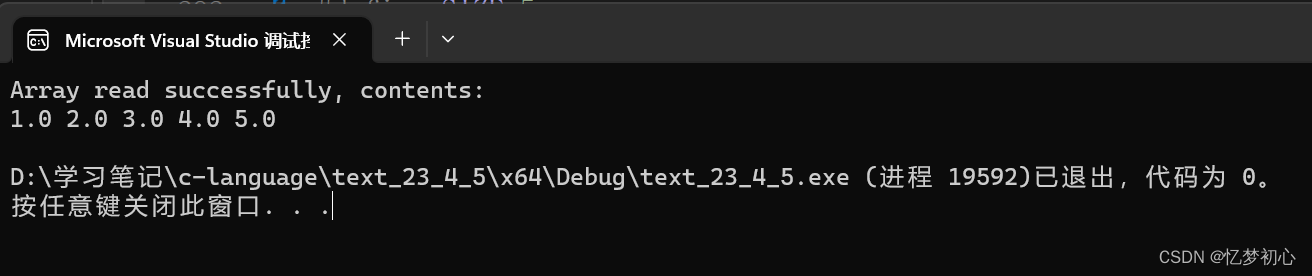
if (ret_code == SIZE) //全部读入成功
{
puts("Array read successfully, contents: ");
for (int n = 0; n < SIZE; ++n)
{
printf("%.1f ", b[n]);
}
putchar('\n');
}
else // 中途遇到文件读取结束,判断结束原因
{
if (feof(fp))
printf("Error reading test.bin: unexpected end of file\n");
else if (ferror(fp))
perror("Error reading test.bin");
}
fclose(fp);
}
八. 文件缓冲区
8.1 为什么要有文件缓冲区
我们知道,计算机的各大组成硬件的速度存在着较大的差异,位于顶端的CPU和我们的IO设备执行速度相差甚远。而假设我们进行文件操作的时候,每读取一次数据就保存一次数据,当我们进行多次操作时,势必需要进行多次的IO操作,占用大量的CPU时间。为了缓和高速的CPU和低速的IO设备的速度不匹配问题,提高CPU的效率,我们就引入的文件缓冲区的概念。
这就好比你妈妈在煮饭,发现盐不够了,让你下去楼下的便利店买包盐;待你买完上来后,又发现油也不够了,再让你下去提一桶油上来;你又气喘吁吁的提了一桶油上来,你妈妈又说,今天家里要来客人,菜可能不太够,让你再下去买点大鱼大肉,你这时肯定小小的脑袋大大的疑惑:能不能一次性的把需要的东西说完呀!!!
8.2 什么是文件缓冲区
CPU也会抱怨:能不能不要这么折磨,先把需要操作的数据统一放在一个地方,让我抽个时间一并IO不香吗?
为了满足CPU的夙愿,对于每个正在使用的文件,我们会额外在内存中开辟一块空间,无论是从内存向磁盘输出数据还是从磁盘向内存输出数据,都会先送到这块空间,当这块空间充满后再一起送到磁盘或者程序数据区(程序变量)。这块空间就是所谓的文件缓存区。缓冲区的大小是根据C编译系统决定的。
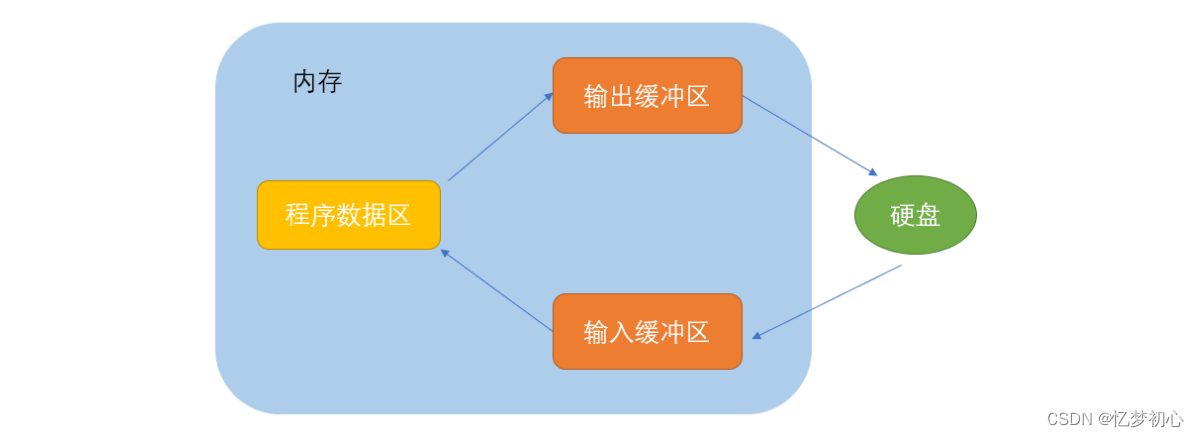
看到文件缓冲区的出现,CPU仰天长笑:哈哈,俺终于解放了,俺自由了,于是就迈着自信的步伐去其他地方放光发热去了。
8.3 感受文件缓冲区的存在
我们可以通过一下程序验证一下文件缓冲区的存在:
#include <stdio.h>
#include <windows.h>
//windows VS2022测试环境
int main()
{
FILE* pf = fopen("test4.txt", "w");
fputs("abcdef", pf);//先将代码放在输出缓冲区
printf("睡眠10秒-已经写数据了,打开test4.txt文件,发现文件没有内容\n");
Sleep(10000);
printf("刷新缓冲区\n");
fflush(pf);//刷新缓冲区时,才将输出缓冲区的数据写到文件(磁盘)
//注:fflush 在高版本的VS上不能使用了
printf("再睡眠10秒-此时,再次打开test4.txt文件,文件有内容了\n");
Sleep(10000);
fclose(pf);
//注:fclose在关闭文件的时候,也会刷新缓冲区
pf = NULL;
return 0;
}此时运行程序,进入睡眠。由于文件缓冲区的存在,我们写入的数据实际上还在文件缓冲区,这时如果我们打开文件,不会显示任何信息:
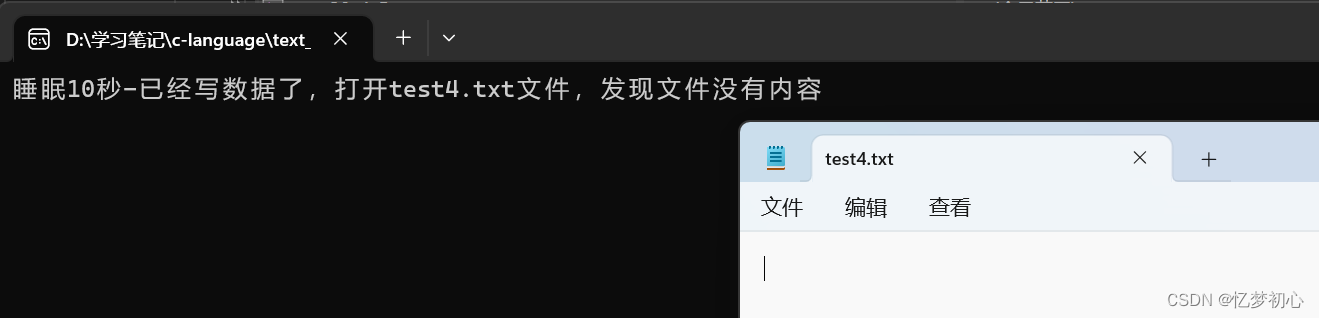
等待10s之后,调用fflush()函数刷新缓冲区,此时缓冲区的数据被送到磁盘文件当中,这是我们打开文件,我们写入的数据将显示出来:
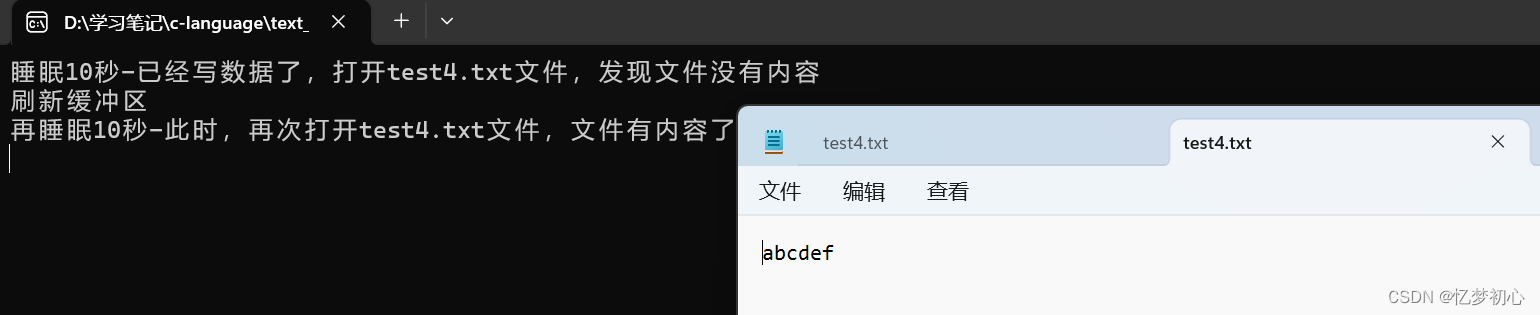
这里,我们还可以得出一个结论:
因为有文件缓冲区的存在,C语言在操作文件的时候,需要做刷新缓冲区或者在文件操作结束的时候关闭文件,这样才会将我们的数据从缓冲区中送到相应的位置。如果不做,可能导致读写文件的问题。