文章目录
- 1.编码和解码的介绍
- 2.相关继承
- 3.解码器分析
- 3.1 ByteToMessageDecoder基类
- 3.2 FixedLengthFrameDecoder
- 3.3 LineBasedFrameDecoder
- 3.4 DelimiterBasedFrameDecoder
- 3.5 LengthFieldBasedFrameDecoder
- 4.编码器分析
- 4.1 解码过程分析
- 4.2 writeAndFlush方法分析
- 4.3 MessageToByteEncoder抽象类
1.编码和解码的介绍
- 解码器:负责将消息从字节或其他序列形式转成指定的消息对象。数据流 IO转为ByteBuf转为业务逻辑
- 编码器:将消息对象转成字节或其他序列形式在网络上传输。对象转为数据流
- Netty里面的编解码: 解码器:负责处理“入站 InboundHandler”数据。 编码器:负责“出站OutboundHandler” 数据。
Netty 的编(解)码器实现了 ChannelHandlerAdapter,也是一种特殊的 ChannelHandler,所以依赖于 ChannelPipeline,可以将多个编(解)码器链接在一起,以实现复杂的转换逻辑。
2.相关继承
解码器(Decoder)
解码器负责 解码“入站”数据从一种格式到另一种格式,解码器处理入站数据是抽象ChannelInboundHandler的实现。需要将解码器放在ChannelPipeline中。对于解码器,Netty中主要提供了抽象基类ByteToMessageDecoder和MessageToMessageDecoder

- ByteToMessageDecoder: 用于将字节转为消息,需要检查缓冲区是否有足够的字节
- MessageToMessageDecoder: 用于从一种消息解码为另外一种消息(例如POJO到POJO)
decode(ChannelHandlerContext ctx, ByteBuf msg, List<Object> out)
编码器(Encoder)
Netty提供了对应的编码器实现MessageToByteEncoder和MessageToMessageEncoder,二者都实现ChannelOutboundHandler接口。

- MessageToByteEncoder: 将消息转化成字节
- MessageToMessageEncoder: 用于从一种消息编码为另外一种消息(例如POJO到POJO)
encode(ChannelHandlerContext ctx, String msg, List<Object> out)
编码解码器Codec
同时具有编码与解码功能,特点同时实现了ChannelInboundHandler和ChannelOutboundHandler接口,因此在数据输入和输出时都能进行处理。

Netty提供提供了一个ChannelDuplexHandler适配器类,编码解码器的抽象基类ByteToMessageCodec ,MessageToMessageCodec都继承与此类。
3.解码器分析
ByteToMessageDecoder相关类

- ByteToMessageDecoder: 基类
- FixedLengthFrameDecoder: 基于固定长度解码器
- LineBasedFrameDecoder: 基于行解码器
- DelimiterBasedFrameDecoder: 基于分隔符解码器
- LengthFieldBasedFrameDecoder: 基于长度域解码器
3.1 ByteToMessageDecoder基类
- 累加字节流
- 调用子类的decode方法解析
- 解析的ByteBuf向下传播
//1,读信息
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//如果msg为ByteBuf,则进行解码,否则直接透传
if (msg instanceof ByteBuf) {
RecyclableArrayList out = RecyclableArrayList.newInstance();
try {
ByteBuf data = (ByteBuf) msg;
//判断cumulation是否为空,来判断是否缓存了半包消息。
first = cumulation == null;
if (first) {
//为空则是没有半包消息,直接复制
cumulation = data;
} else {
//有半包消息,则需要将data复制进行,进行组合。
cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);
}
// 子类进行不同的解码
callDecode(ctx, cumulation, out);
} catch (DecoderException e) {
throw e;
} catch (Throwable t) {
throw new DecoderException(t);
} finally {
if (cumulation != null && !cumulation.isReadable()) {
cumulation.release();
cumulation = null;
}
int size = out.size();
for (int i = 0; i < size; i ++) {
// 传播ByteBuf
ctx.fireChannelRead(out.get(i));
}
// 回收对象
out.recycle();
}
} else {
// 传播ByteBuf
ctx.fireChannelRead(msg);
}
}
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
try {
while (in.isReadable()) {
int outSize = out.size();
int oldInputLength = in.readableBytes();
//调用用户实现的decode方法
decode(ctx, in, out);
if (ctx.isRemoved()) {
break;
}
//1,如果用户解码器没有消费ByteBuf,则说明是半包消息,需要继续读取后续的数据,直接退出循环;2,如果用户解码器消费了ByteBuf,说明可以继续进行;
if (outSize == out.size()) {
if (oldInputLength == in.readableBytes()) {
break;
} else {
continue;
}
}
//3,如果用户解码器没有消费ByteBuf,但是却多解码出一个或多个对象,则为异常
if (oldInputLength == in.readableBytes()) {
throw new DecoderException(
StringUtil.simpleClassName(getClass()) +
".decode() did not read anything but decoded a message.");
}
//4,如果是单条消息解码器,第一次解码完成之后直接退出循环。
if (isSingleDecode()) {
break;
}
}
} catch (DecoderException e) {
throw e;
} catch (Throwable cause) {
throw new DecoderException(cause);
}
}
callDecode(ctx, cumulation, out)
调用子类的decode解析


根据子类不同的实现去实现decode解析数据。
3.2 FixedLengthFrameDecoder
基于固定长度解码器

如果基于3的长度去解析的话, 那么 A|BC|DEFG|HI 解析为 ABC|DEF|GHI
protected Object decode(
@SuppressWarnings("UnusedParameters") ChannelHandlerContext ctx, ByteBuf in) throws Exception {
if (in.readableBytes() < frameLength) {
return null;
} else {
return in.readRetainedSlice(frameLength);
}
}
3.3 LineBasedFrameDecoder
行解析器: 看行是否有 \n 和 \r 的换行符号, 如果全部有的话看 \r
是否是丢弃模式, discarding = true, 为丢失模式, 为false表示不可以丢失
private boolean discarding;
// 找到行的最后的位置: \n结尾 或是 \r\n结尾
private int findEndOfLine(final ByteBuf buffer) {
int totalLength = buffer.readableBytes();
int i = buffer.forEachByte(buffer.readerIndex() + offset, totalLength - offset, new IndexOfProcessor((byte) '\n'));
if (i >= 0) {
offset = 0;
if (i > 0 && buffer.getByte(i - 1) == '\r') {
i--;
}
} else {
offset = totalLength;
}
return i;
}
protected Object decode(ChannelHandlerContext ctx, ByteBuf buffer) throws Exception {
final int eol = findEndOfLine(buffer);
// 判断如果当前是非丢弃模式
if (!discarding) {
// 非丢弃模式下的找到换行符, 当前存在 \n 或 \r\n
if (eol >= 0) {
final ByteBuf frame;
final int length = eol - buffer.readerIndex();
final int delimLength = buffer.getByte(eol) == '\r'? 2 : 1;
// 如果解析的长度大于最大长度, 报错
if (length > maxLength) {
buffer.readerIndex(eol + delimLength);
fail(ctx, length);
return null;
}
// 是否将分隔符也加入到数据包中
if (stripDelimiter) {
frame = buffer.readRetainedSlice(length);
buffer.skipBytes(delimLength);
} else {
frame = buffer.readRetainedSlice(length + delimLength);
}
return frame;
} else {
// 非丢弃模式下的没有分隔符的情况
final int length = buffer.readableBytes();
if (length > maxLength) {
discardedBytes = length;
buffer.readerIndex(buffer.writerIndex());
discarding = true;
offset = 0;
if (failFast) {
fail(ctx, "over " + discardedBytes);
}
}
return null;
}
// 丢弃模式
} else {
// 丢弃模式下的找到换行符
if (eol >= 0) {
final int length = discardedBytes + eol - buffer.readerIndex();
final int delimLength = buffer.getByte(eol) == '\r'? 2 : 1;
buffer.readerIndex(eol + delimLength);
discardedBytes = 0;
discarding = false;
if (!failFast) {
fail(ctx, length);
}
// 丢弃模式下的没有找到修饰符
} else {
discardedBytes += buffer.readableBytes();
buffer.readerIndex(buffer.writerIndex());
// We skip everything in the buffer, we need to set the offset to 0 again.
offset = 0;
}
return null;
}
}
非丢弃模式下的找到换行符情况

非丢弃模式下的没有找到换行符

丢弃模式下, 找到换行符: 需要丢弃一些数据, 然后变为非丢弃模式的逻辑

丢弃模式下, 没有找到换行符: 需要先丢弃数据, 然后变为非丢弃模式的逻辑
3.4 DelimiterBasedFrameDecoder
DelimiterBasedFrameDecoder, 基于分隔符的解码器
-
判断是否是行解码器: 分隔符为换行符

-
找到最小分隔符

-
如果找到最小分隔符的话
int minDelimLength = minDelim.capacity();
ByteBuf frame;
// 如果是丢弃模式的话, 先丢弃数据
if (discardingTooLongFrame) {
// We've just finished discarding a very large frame.
// Go back to the initial state.
discardingTooLongFrame = false;
buffer.skipBytes(minFrameLength + minDelimLength);
int tooLongFrameLength = this.tooLongFrameLength;
this.tooLongFrameLength = 0;
if (!failFast) {
fail(tooLongFrameLength);
}
return null;
}
// 非丢弃模式, 判断数据的长度和最大长度, 报错
if (minFrameLength > maxFrameLength) {
// Discard read frame.
buffer.skipBytes(minFrameLength + minDelimLength);
fail(minFrameLength);
return null;
}
// 是否将分隔符也加入到数据包中
if (stripDelimiter) {
frame = buffer.readRetainedSlice(minFrameLength);
buffer.skipBytes(minDelimLength);
} else {
frame = buffer.readRetainedSlice(minFrameLength + minDelimLength);
}
return frame;
- 如果没有找到最小分隔符的话
if (!discardingTooLongFrame) {
if (buffer.readableBytes() > maxFrameLength) {
// Discard the content of the buffer until a delimiter is found.
tooLongFrameLength = buffer.readableBytes();
buffer.skipBytes(buffer.readableBytes());
discardingTooLongFrame = true;
if (failFast) {
fail(tooLongFrameLength);
}
}
} else {
// 丢弃模式
tooLongFrameLength += buffer.readableBytes();
buffer.skipBytes(buffer.readableBytes());
}
return null;
判断是否是行解码器: 分隔符为换行符

拿到最小分隔符的信息

最新分隔符为A
3.5 LengthFieldBasedFrameDecoder
LengthFieldBasedFrameDecoder 为基于长度域的解码器
- lengthFieldOffset: 读取的标记开始
- lengthFieldLength: 读取的长度
- lengthAdjustment: 读取长度的加减数据
- initialBytesToStrip: 从哪里开始读取


0 - 2字节为后面读的数据的长度, 为12个, 最后减少0个字节还是12个, 减少0个字节读起数据

0 - 2字节为后面读的数据的长度, 为12个, 最后减少0个字节是12个, 从减少2个字节读起数据

0 - 2字节为后面读的数据的长度, 为14个, 最后减少2个字节是12个, 从减少0个字节读起数据

2 - 5字节为后面读的数据的长度, 为12个, 最后减少0个字节是12个, 从减少0个字节读起数据

1 - 3字节为后面读的数据的长度, 为12个, 最后加上1个字节是13个, 从减少3个字节读起数据

1 - 3字节为后面读的数据的长度, 为16个, 最后减少3个字节是13个, 从减少3个字节读起数据
- 计算需要抽取的数据包长度
- 跳过字节逻辑处理
- 丢弃模式下的处理
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
// 丢弃模式下的处理
if (discardingTooLongFrame) {
discardingTooLongFrame(in);
}
if (in.readableBytes() < lengthFieldEndOffset) {
return null;
}
// 计算需要抽取的数据包长度
int actualLengthFieldOffset = in.readerIndex() + lengthFieldOffset;
long frameLength = getUnadjustedFrameLength(in, actualLengthFieldOffset, lengthFieldLength, byteOrder);
// 计算需要抽取的数据包长度
frameLength += lengthAdjustment + lengthFieldEndOffset;
int frameLengthInt = (int) frameLength;
if (in.readableBytes() < frameLengthInt) {
return null;
}
if (initialBytesToStrip > frameLengthInt) {
failOnFrameLengthLessThanInitialBytesToStrip(in, frameLength, initialBytesToStrip);
}
in.skipBytes(initialBytesToStrip);
// 跳过字节逻辑处理
int readerIndex = in.readerIndex();
int actualFrameLength = frameLengthInt - initialBytesToStrip;
ByteBuf frame = extractFrame(ctx, in, readerIndex, actualFrameLength);
in.readerIndex(readerIndex + actualFrameLength);
return frame;
}
// 计算需要抽取的数据包长度
protected long getUnadjustedFrameLength(ByteBuf buf, int offset, int length, ByteOrder order) {
buf = buf.order(order);
long frameLength;
switch (length) {
case 1:
frameLength = buf.getUnsignedByte(offset);
break;
case 2:
frameLength = buf.getUnsignedShort(offset);
break;
case 3:
frameLength = buf.getUnsignedMedium(offset);
break;
case 4:
frameLength = buf.getUnsignedInt(offset);
break;
case 8:
frameLength = buf.getLong(offset);
break;
default:
throw new DecoderException(
"unsupported lengthFieldLength: " + lengthFieldLength + " (expected: 1, 2, 3, 4, or 8)");
}
return frameLength;
}
4.编码器分析
4.1 解码过程分析


public class BizHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
User user = new User("1", 1);
ctx.channel().writeAndFlush(user);
}
}
public class Encoder extends MessageToByteEncoder<User> {
@Override
protected void encode(ChannelHandlerContext ctx, User msg, ByteBuf out) throws Exception {
byte[] bytes = msg.getName().getBytes();
out.writeInt(4 + bytes.length);
out.writeInt(msg.getAge());
out.writeBytes(bytes);
}
}
重写encode方法
4.2 writeAndFlush方法分析
- 从tail节点开始往前传播
- 逐个调用channelHandler的write方法
- 逐个调用channelHandler的flush方法





4.3 MessageToByteEncoder抽象类
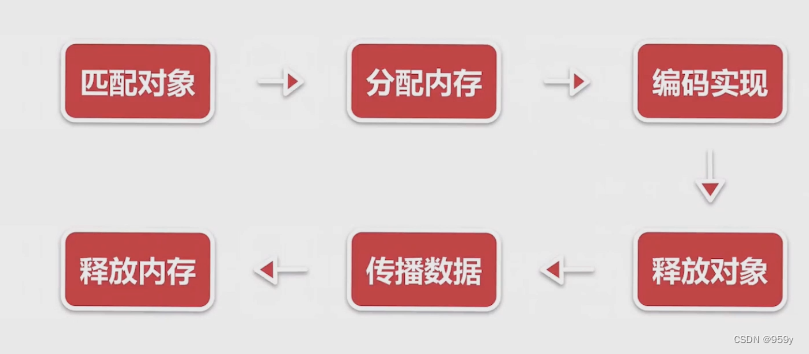
MessageToByteEncoder.write()
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
ByteBuf buf = null;
try {
// 匹配对象
if (acceptOutboundMessage(msg)) {
@SuppressWarnings("unchecked")
I cast = (I) msg;
// 分配内存
buf = allocateBuffer(ctx, cast, preferDirect);
try {
// 编码实现
encode(ctx, cast, buf);
} finally {
// 释放对象
ReferenceCountUtil.release(cast);
}
if (buf.isReadable()) {
// 传播数据
ctx.write(buf, promise);
} else {
buf.release();
// 传播数据
ctx.write(Unpooled.EMPTY_BUFFER, promise);
}
buf = null;
} else {
ctx.write(msg, promise);
}
} catch (EncoderException e) {
throw e;
} catch (Throwable e) {
throw new EncoderException(e);
} finally {
// 释放内存
if (buf != null) {
buf.release();
}
}
}