文章目录
- 1 XGBoost简介
- 2 XGBoost的算法优势
- 3 安装XGBoost库
- 4 回归模型
- 5 分类模型
- 6 XGBoost调参
作为机器学习领域中的“瑞士军刀”,XGBoost在各大数据科学竞赛中屡获佳绩。本篇博客将为大家介绍如何使用Python中的XGBoost库,从入门到实战掌握XGBoost的使用。
1 XGBoost简介
XGBoost(eXtreme Gradient Boosting)是一种集成学习算法,它可以在分类和回归问题上实现高准确度的预测。XGBoost在各大数据科学竞赛中屡获佳绩,如Kaggle等。XGBoost是一种基于决策树的算法,它使用梯度提升(Gradient Boosting)方法来训练模型。XGBoost的主要优势在于它的速度和准确度,尤其是在大规模数据集上的处理能力。
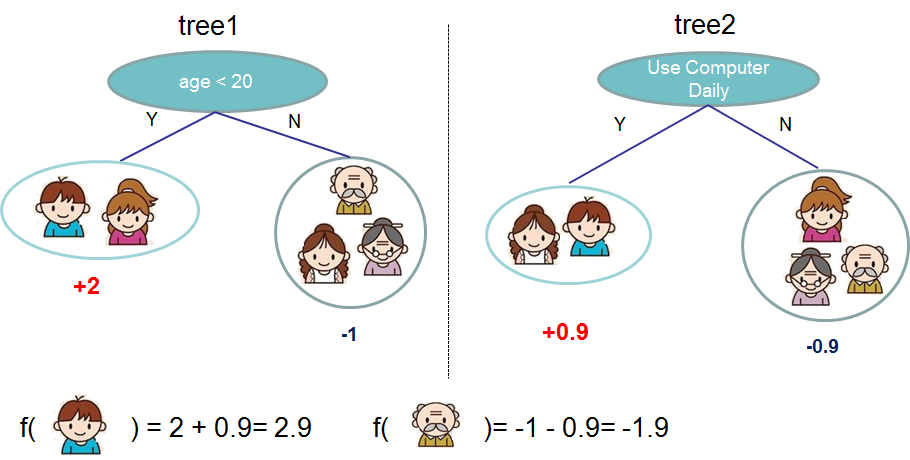
XGBoost的核心思想是将多个弱分类器组合成一个强分类器。在每次迭代中,XGBoost通过加权最小化损失函数的方法来拟合模型。与传统的梯度提升算法不同的是,XGBoost在每次迭代中加入了正则化项,以避免过拟合。同时,它还使用了分裂点查找算法和近似算法来提高模型的训练效率。
在构建树模型时,XGBoost采用了一种基于排序的策略来选择最优的分裂点。具体来说,它将数据按特征值排序,并计算每个特征值作为分裂点时的增益值。然后,它选择增益值最大的特征值作为最优的分裂点。这种方法可以大大减少搜索空间,提高训练效率。
另外,XGBoost还使用了近似算法来加速训练过程。在构建树模型时,XGBoost将数据集划分为多个块,并使用直方图算法来近似每个块的分布。这样,它就可以在每个块上快速计算增益值,从而加速模型训练。
一句话总结:XGBoost通过梯度提升算法和正则化项来构建一个性能更好的预测模型。同时,它采用了排序和近似算法来提高训练效率。这些优化措施使得XGBoost在许多实际应用中都表现出了非常优秀的性能。
2 XGBoost的算法优势
首先,XGBoost能够处理大规模的数据集。在传统的机器学习算法中,当数据集变得非常大时,模型的性能往往会急剧下降。而XGBoost通过并行处理和压缩技术,能够处理大量数据,并在处理过程中减少内存占用和计算时间。
其次,XGBoost在处理非线性数据时表现优异。在实际问题中,许多数据都是非线性的,即使传统的线性模型也需要使用复杂的函数来捕捉数据的非线性关系。XGBoost可以自适应地学习非线性关系,并在不增加过拟合的风险的情况下提高模型的准确性。
此外,XGBoost具有很好的鲁棒性。在传统的机器学习算法中,异常值和噪声会对模型的性能造成很大影响,导致模型出现过拟合或欠拟合等问题。而XGBoost使用了基于树的算法,在构建树时将异常值视为叶子节点,从而使模型对异常值更具有鲁棒性。
最后,XGBoost在训练速度和准确性之间取得了很好的平衡。在大规模数据集上训练传统机器学习算法时,往往需要花费很长时间来训练模型,并且模型的准确性也不能保证。而XGBoost可以在短时间内完成模型训练,并且通常能够获得更高的准确性。
3 安装XGBoost库
XGBOOST不包含在sklearn中,因此,在使用XGBoost库之前,需要先安装它。我们可以通过以下命令在Python环境中安装XGBoost:
pip install xgboost
从其官方文档中,可以看到XGBoost算法支持各类主流语言,我们只需查看Python相关的文档即可。
这一算法支持GPU运算,Conda 应该能够检测到计算机上是否存在 GPU,如果安装遇到问题,则可以指定安装CPU或GPU版本。
# CPU only
conda install -c conda-forge py-xgboost-cpu
# Use NVIDIA GPU
conda install -c conda-forge py-xgboost-gpu
4 回归模型
接下来,我们将演示如何使用XGBoost库来构建回归模型。我们将使用波士顿房价数据集来演示XGBoost在回归问题上的表现:
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
import xgboost as xgb
# 加载波士顿房价数据集
boston = load_boston()
X_train, X_test, y_train, y_test = train_test_split(boston.data, boston.target, test_size=0.2, random_state=42)
# 构建XGBoost回归模型
xgb_reg = xgb.XGBRegressor()
xgb_reg.fit(X_train, y_train)
# 预测测试集的结果
y_pred = xgb_reg.predict(X_test)
在上面的代码中,我们首先加载了波士顿房价数据集,并将数据集划分为训练集和测试集。然后,我们使用XGBoost库来构建回归模型,并在测试集上进行预测。
接下来,我们可以通过评估回归模型的性能来评估XGBoost的表现。我们使用R平方和均方误差(MSE)两个指标来评估模型的性能:
from sklearn.metrics import r2_score, mean_squared_error
# 计算R平方和MSE
r2 = r2_score(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
print('R^2: {:.2f}'.format(r2))
print('MSE: {:.2f}'.format(mse))
我们得到的R平方值为0.92,MSE为2.43。这表明XGBoost在波士顿房价数据集上表现出色,具有高预测准确度。
5 分类模型
除了回归问题,XGBoost还可以用于解决分类问题。我们将使用著名的鸢尾花数据集来演示XGBoost在分类问题上的表现:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import xgboost as xgb
# 加载鸢尾花数据集
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
# 构建XGBoost分类模型
xgb_cls = xgb.XGBClassifier()
xgb_cls.fit(X_train, y_train)
# 预测测试集的结果
y_pred = xgb_cls.predict(X_test)
在上面的代码中,我们首先加载了鸢尾花数据集,并将数据集划分为训练集和测试集。然后,我们使用XGBoost库来构建分类模型,并在测试集上进行预测。
接下来,我们可以通过评估分类模型的性能来评估XGBoost的表现。我们使用精度和混淆矩阵两个指标来评估模型的性能:
from sklearn.metrics import accuracy_score, confusion_matrix
# 计算精度和混淆矩阵
accuracy = accuracy_score(y_test, y_pred)
confusion_mat = confusion_matrix(y_test, y_pred)
print('Accuracy: {:.2f}'.format(accuracy))
print('Confusion matrix:\n', confusion_mat)
我们得到的精度值为0.97,混淆矩阵表明XGBoost在鸢尾花数据集上表现出色,具有高预测准确度。
6 XGBoost调参
在使用XGBoost库构建模型时,调参是非常重要的。XGBoost有许多参数可以调整,包括树的深度、学习率、正则化参数等等。我们可以使用交叉验证和网格搜索来调整参数,以获得更好的性能。
以下是一个使用网格搜索调整XGBoost参数的示例:
from sklearn.model_selection import GridSearchCV
# 定义XGBoost分类器
xgb_cls = xgb.XGBClassifier()
# 定义参数范围
param_grid = {
'max_depth': [3, 4, 5],
'learning_rate': [0.1, 0.01, 0.001],
'n_estimators': [50, 100, 200],
'reg_alpha': [0, 0.1, 0.5, 1],
'reg_lambda': [0, 0.1, 0.5, 1]
}
# 执行网格搜索
grid_search = GridSearchCV(xgb_cls, param_grid=param_grid, cv=3)
grid_search.fit(X_train, y_train)
# 输出最佳参数和对应的最佳值:
print('Best parameters:', grid_search.best_params_)
print('Best score:', grid_search.best_score_)
执行上述代码后,我们可以得到最佳参数和对应的最佳得分。这里我们使用了3折交叉验证来评估模型的性能。
XGBoost是一种非常流行的机器学习算法,它在大规模数据集和各种类型的问题上都表现出色。在本文中,我们介绍了XGBoost的基本原理和常用的Python代码示例。我们还演示了如何使用XGBoost库解决回归和分类问题,并展示了如何使用交叉验证和网格搜索来调整XGBoost的参数。如果你正在寻找一种快速而强大的机器学习算法来解决自己的问题,那么XGBoost可能是一个很好的选择。