博主简介
博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c++,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,如果有错误之处,大家可以指正。
专栏简介: 本专栏主要研究计算机视觉,涉及算法,案例实践,网络模型等知识。包括一些常用的数据处理算法,也会介绍很多的Python第三方库。如果需要,点击这里订阅专栏 。
给大家分享一个我很喜欢的一句话:“每天多努力一点,不为别的,只为日后,能够多一些选择,选择舒心的日子,选择自己喜欢的人!”

目录
![]() 前言
前言
![]() TensorFlow的起源
TensorFlow的起源
![]() TensorFlow基础知识
TensorFlow基础知识
![]() 安装
安装
![]() 图计算
图计算
![]() TensorFlow 2.0
TensorFlow 2.0
![]() 张量
张量
![]() tf.data
tf.data
![]() 模型存取
模型存取
![]() Keras接口
Keras接口
![]() 神经网络搭建
神经网络搭建
![]() 代码实战:手写数字
代码实战:手写数字
 前言
前言
对于程序员来说一种好的语言无疑是非常重要的,在深度学习中,就有一门语言:TensorFlow,集成了大量的深度学习常用函数,使得我们可以快速的部署模型,以及进行训练。所以,下面我们就开始了解以下TensorFlow中的各个函数的用法。
 TensorFlow的起源
TensorFlow的起源
TensorFlow是一个基于数据编程的符号数学系统,被广泛用于割裂机器学习算法的编程实现,那么TensorFlow是谁构建的?它的前身是谷歌的DistBelief神经网络库。从2015年11月9日起,TensorFlow阿帕奇授权协议开放源代码。
据小道消息,我们现在用的TensorFlow只是一小部分,其真身还是在谷歌的内部,所以说,我们的和国外的差距还是很大的,需要各位读者努力学习,缩短差距。
 TensorFlow基础知识
TensorFlow基础知识
 安装
安装
python用户安装,只需要使用pip install tensorflow命令行即可.
如果需要GPU加速,则输入:
pip install tensorflow-gpu
安装完后,可以使用以下命令查看版本:
import tensorflow as tf
tf.__version__
 图计算
图计算
对于深度学习框架,图计算是基础中的基础。前面讲了深度学习中的正向传播和反向传播,图计算就是将 深度学习中的正向传播和反向求导顺序构建成一张图,之后计算的时候只要更具图中的顺序更新参数即可。
图计算分为两大类:静态图和动态图。静态图就是先定义一整张图片,在进行计算,优点是再次运行的时候不需要重新构建计算图;而对于动态图,每次计算都会重建一个新的计算图,优点是随时可以解决缺陷(bug),不需要等到整张图构建完才可以解决bug。
TensorFlow应该使用哪一种?版本不同,使用的也不同,在版本1.x中,默认使用静态图,需要先创建图(graph),之后才能在会话中(session)进行计算,但是也可以通过快速执行(eager)模式,进行动态图计算。而在最新的2.x版本中,默认为动态图模式。
 TensorFlow 2.0
TensorFlow 2.0
相比之前的版本,2.0版本的TensorFlow具有了很多的优点:
(1)大量简化API。
(2)快速执行。
(3)不需要再创建会话。
(4)不再使用全局变量跟踪。
(5)统一保存模式。
TensorFlow的确是非常便于学习和使用的,让我们可以把更多的精力放在研究方向上。
 张量
张量
TensorFlow和PyTorch中的数据模型很多都是用张量的形式来存储,所谓张量,就是一个高维的矩阵。在TensorFlow中,使用tf.Tensor类表示张量,一个张量的参数有编号(id)、形状(shape=())、数据类型(dtype)、值(value)、所在计算图(graph)、张量名称(name)。
张量中最常用的就是常量和变量,常量用tf.constant,而变量用tf.Variable类,参数为名称(name)、形状(shape)、数据类型(dtype)、数值(value)。
张量的数据类型:
tf.float32 32 位浮点数
tf.float64 64 位浮点数
tf.int64 64 位有符号整型
tf.int32 32 位有符号整型
tf.int16 16 位有符号整型
tf.int8 8 位有符号整型
tf.uint8 8 位无符号整型
tf.string 可变长度的字节数组.每一个张量元素都是一个字节数组
tf.bool 布尔型
tf.complex64 由两个32位浮点数组成的复数:实数和虚数
tf.qint32 用于量化Ops的32位有符号整型
tf.qint8 用于量化Ops的8位有符号整型
tf.quint8 用于量化Ops的8位无符号整型
下面用代码来展示一下:
import tensorflow as tf
a=tf.constant(2,name='a')
b=tf.constant(3,name='b')
#计算a+b
x=tf.add(a,b)
print(x)
print(a+b)
#得到a的形状
a.get_shape()
#得到a的值
a.numpy()
#变量
s=tf.Variable(2,name='scaler')
n=tf.Variable([[0,1],[2,3]],name='matrix')
w=tf.Variable(tf.zeros([784,10]))
#将变量s赋值为3
s.assign(3)
#将变量的值加3
s.assign_add(3)
s.numpy()tf.Tensor(5, shape=(), dtype=int32) tf.Tensor(5, shape=(), dtype=int32)
6
 tf.data
tf.data
在构建数据流的时候,我们可以创建数据集,创建数据集的作用就是提高速度,效率,那么为什么会有如此的作用喃?
其实就是将CPU的空闲时间缩短了,转为GPU空闲,利用率大幅上升。
import tensorflow as tf
a=tf.constant(2,name='a')
b=tf.constant(3,name='b')
#计算a+b
x=tf.add(a,b)
print(x)
print(a+b)
#得到a的形状
a.get_shape()
#得到a的值
a.numpy()
#变量
s=tf.Variable(2,name='scaler')
n=tf.Variable([[0,1],[2,3]],name='matrix')
w=tf.Variable(tf.zeros([784,10]))
#将变量s赋值为3
s.assign(3)
#将变量的值加3
s.assign_add(3)
s.numpy()
'''
#创建数据集方法(3种)
tf.data.Dataset.from_tensors((features,labels))
tf.data.Dataset.from_tensor_slices((freatures,labels))
tf.data.Dataset.from_generator(gen,output_types,output_shapes)
'''
#创建数据集方法的区别
dataset=tf.data.Dataset.from_tensors([1,2,3,4,5])
for element in dataset:
print(element.numpy())
it=iter(dataset)
print(next(it).numpy())
dataset=tf.data.Dataset.from_tensor_slices([1,2,3,4,5])
for element in dataset:
print(element.numpy())
it=iter(dataset)
print(next(it).numpy())
#读取数据集
#包含多个txt文件的行
tf.data.TextLineDataset(filename) #filename代表的是路径
#来自一个或多个二进制文件的固定长度记录的数据集
tf.data.FixedLengthRecordDataset(filename)
#包含多个TFRecord文件的记录
tf.data.TFRecordDataset(filename)
#合并数据集
features=tf.data.Dataset.from_tensors([1,2,3,4,5])
labels=tf.data.Dataset.from_tensor_slices([6,7,8,9,10])
dataset=tf.data.Dataset.zip((features,labels))
for element in dataset:
print(element)
#对数据取batch,注意batch(4)不是指取4个数据,而是将数据集中的数据打包为4个一组
inc_dataset=tf.data.Dataset.range(100)
dec_dataset=tf.data.Dataset.range(0,-100,-1)
dataset=tf.data.Dataset.zip((inc_dataset,dec_dataset))
batched_dataset=dataset.batch(4)
#读取数据集
for batch in batched_dataset.take(4):
print([arr.numpy() for arr in batch])
#对数据集进行随机打乱
shuffle_dataset=dataset.shuffle(buffer_size=10)
for element in shuffle_dataset:
print(element)
#使用常用的数据
tf.keras.datasets.xx.load_data()
 模型存取
模型存取
在TensorFlow种有两种保存模型的方式,第一种是只保存模型的权重,我们也称之为保存为检查点(checkpoint),使用函数model.save_weights('checkpoint'),由于只保存了权重,在读取模型的时候,我们必须重新搭建模型,之后使用model.restore(ckpt)即可。
第二种是保存整个模型,使用model.save('my_model.h5'),读取的时候就不需要重新搭建模型了,直接使用model=load_model('my_model.h5')。
 Keras接口
Keras接口
为了方便我们进行函数的使用,TensorFlow中给出了一个接口,这个接口中包含了很多的函数,我们直接使用这个接口就可以了。下面来介绍介绍这个接口的神奇之处。
一、全连接层:tf.keras.layers.Dense,此函数的参数为神经元数量units,激活函数activation、是否使用偏置参数use_bias,初始化参数initialializer、正则化参数regularizer。
二、卷积层:tf.keras.layers.Conv1D、2D、3D,共三种不同维度的卷积层,分别对应输入为词向量、图片和视频。此函数的参数为卷积核数量filters、卷积尺寸核kernel_size、滑动步长strides、填充方式padding、激活函数activation、是否使用偏置参数use_bias初始化参数initializer、正则化参数regularizer。
三、池化层:池化层非常多,分为平均池化层tf.keras.layers.AveragePooling2D()、最大池化层tf.keras.layers.MaxPool2D()、全局平均池化层tf.keras.layers.GlobalAveragePooling2D()和全局最大池化层tf.keras.layers.GlobalMaxPool2D。所谓全局池化层,就是对某一维度进行平均,例如输入为28x28的图片,输出为28x1的向量。函数的参数为池化大小为pool_size、滑动步长strides、填充方式padding。
Dropout层:tf.keras.layers.Dropout
BatchNorm层:tf.keras.layers.BatchNormalization
RNN单元:tf.keras.layers.RNN
LSTM单元:tf.keras.layers.LSTM
GRU单元:tf.keras.layers.GRU
最后,常用的优化器:tf.keras.optimizers.Adagrad、Adagrad、tf.keras.optimizers.Adam,以及tf.keras.optimizers.SGD。
 神经网络搭建
神经网络搭建
model=tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(128,activation='relu',bias=False,trainable=False),
tf.keras.layers.Dense(10,activation='softmax')
])
#卷积神经网络
model1=tf.keras.Sequential()
model1.add(tf.keras.layers.Conv2D(32,(3,3),activation='relu',input_shape=(28,28,1)))
model1.add(tf.keras.layers.MaxPooling2D((2,2)))
model1.add(tf.keras.layers.Conv2D(64,(3,3),activation='relu',input_shape=(28,28,1)))
model1.add(tf.keras.layers.MaxPooling2D((2,2)))
model1.add(tf.keras.layers.Conv2D(64,(3,3),activation='relu',input_shape=(28,28,1)))
model1.add(tf.keras.layers.Flatten())
model1.add(tf.keras.layers.Dense(256,activation='relu'))
model1.add(tf.keras.layers.Dense(10,activation='softmax'))
#RNN网络
model2=tf.keras.Sequential()
model2.add(tf.keras.layers.LSTM(128,input_shape=(None,28)))
model2.add(tf.keras.layers.Dense(10,activation='softmax'))
 代码实战:手写数字
代码实战:手写数字
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
#读取模型
fashion_mnist=tf.keras.datasets.fashion_mnist
(train_images,train_labels),(test_images,test_labels)=fashion_mnist.load_data() #下载数据模型
#获得图片大小
train_images.shape
#打印图例
def plotImages(images_arr):
fig,axes=plt.subplots(1,5,figsize=(10,10))
axes=axes.flatten()
for img,ax in zip(images_arr,axes):
ax.imshow(img)
ax.axis('off')
plt.tight_layout()
plt.show()
plotImages(train_images[:5])
#归一化
train_images=train_images/255.0
test_images=test_images/255.0
#全连接层模型
model=tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(128,activation='relu',trainable=False),
tf.keras.layers.Dense(10,activation='softmax')
])
#模型总结
model.summary()
#编译
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',metrics=['accuracy'])
#训练
model.fit(train_images,train_labels,epochs=10,validation_data=(test_images,test_labels))
#模型权重
model.variables
#保存权重
model.save_weights('./fashion_mnist/my_checkpoint')
#恢复权重
model.load_weights('./fashion_mnist/my_checkpoint')
#预测
loss,acc=model.evaluate(test_images,test_labels,verbose=2)
print('Restored model,accuracy:{:5.2f}%'.format(100*acc))
#保存整个模型
model.save('my_model.h5')
new_model=tf.keras.models.load_model('my_model.h5')
loss,acc=new_model.evaluate(test_images,test_labels,verbose=2)
print('Restored model,accuracy:{:5.2f}%'.format(100*acc))
#在文件中名中包含epoch(使用'str.format')
checkpoint_path='fashion_mnist_1/cp-{epoch:04d}.ckpt'
#创建一个回调,每个epoch保存模型的权重
cp_callback=tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_path,
save_weights_only=True,
period=1
)
#使用checkpoint_path格式保存权重
model.save_weights(checkpoint_path.format(epoch=0))
#实用新的回调训练模型
model.fit(train_images,
train_labels,epochs=5,
callbacks=[cp_callback],
validation_data=(test_images,test_labels))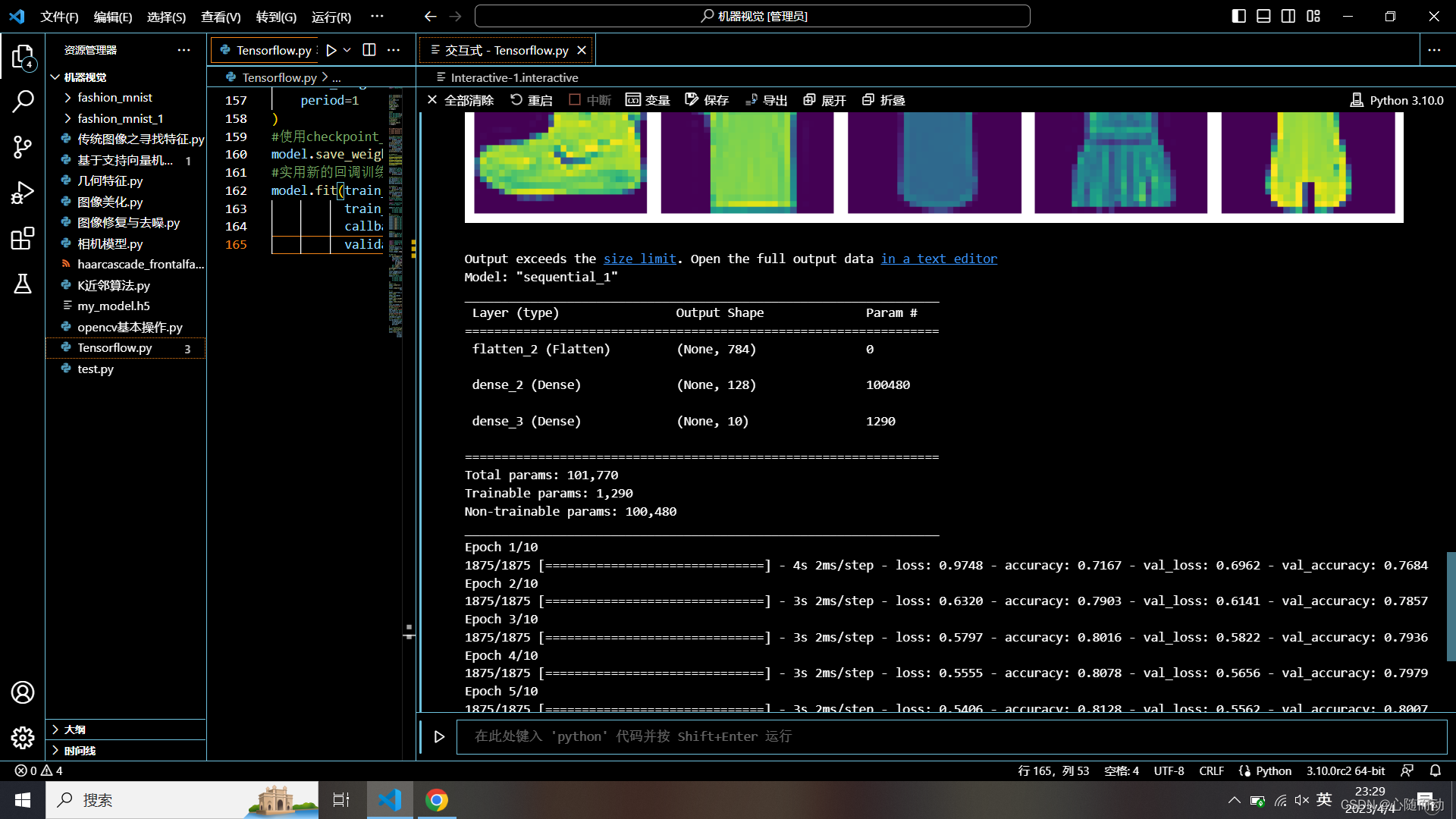
这就是训练成功的数据集。好了,本节内容就到此结束了,拜拜了你嘞!