2023年的深度学习入门指南(3) - 动手写第一个语言模型
上一篇我们介绍了openai的API,其实也就是给openai的API写前端。在其它各家的大模型跟gpt4还有代差的情况下,prompt工程是目前使用大模型的最好方式。
不过,很多编程出身的同学还是对于prompt工程不以为然,认为编程实现才是王道。认为编程才能更好地理解原理,才能发掘出大模型的真正潜力。还有同学希望能用有限的算力希望挖掘出模型的潜力。
这当然不是坏事,缩放定律和现有模型的结构也并非是金科玉律,也还有不少不尽如人意的地方,比如:
- 作为大模型基础单元的自注意力模型,复杂度是 O ( n 2 ) O(n^2) O(n2),是否有更好的结构?
- 这些单元之间,除了堆更多层之外,是否还有更有效的结构?
- 有什么方法可以优化大模型推理时所需的算力?
- 大模型的原理是个黑盒,有没有更白盒一些的方法,提升模型的可解释性?
这些问题构成我们后面讲解编程的主线:
- Transformer结构的基本单元是什么,如何编程实现
- Transformer结构如何优化
- 如何用Transformer的编码器和解码器搭建预训练模型
- 如何通过剪枝、量化、蒸馏等方法让大模型的推理在小算力下跑起来
- 如何用可解释的方法搭建大模型
有了这些积累之后,我们再看一些主流的大模型是如何实现的。
有志于用更少算力实现更多大模型能力的同学,我们还得学习下相关加速器件的编程,比如GPGPU和XLA编程。
这还只是模型,还有数据。
我们还要深入了解下目前大模型存在的幻觉问题,有毒有偏见数据的研究成果。
最后,RLHF还涉及强化学习的知识,我们还得讲下强化学习,以及在Atari游戏和NLP中的用法。
上面编程的结束后,我们再重新系统研究下prompt工程。
现在我们回到故事的起点,从Transformer模型的基础:自注意力机制说起。
自注意力机制
这一部分值得有志于算法工作的同学好好学习下,因为这应该是算法同学面试必问的问题。不过,2017年的时候我们因为用的经验少,所以只能照本宣科地讲《Attention Is All you need》中的内容。现在因为大模型的热门,我们对基础模块的研究也越来越深入了,没准儿你可以讲出点老一点的面试官也不知道的东西了。
注意力是我们日常常用的词。人类的注意力就是从海量的信息中抓住重点。在人工神经网络中,为了模仿人类的机制,当前的词与其他每个词的关系,我们都设置一个值,这就构成了算法中的注意力机制。
有了注意力机制之后,我们通过训练,就可以让跟当前词相关的词的权重变高,而不相关的词的权重变低。
比如在机器翻译中,我们可以通过注意力机制,让源语言与目标语言中相对应的词的注意力权重变高。常见的有加法注意力和乘法注意力等实现方式。
如果我们不管与别的语句的注意力,只关注一句话或一段话中某个词与其他词之间的注意力关系,这被称为自注意力。
我们看一个例子:
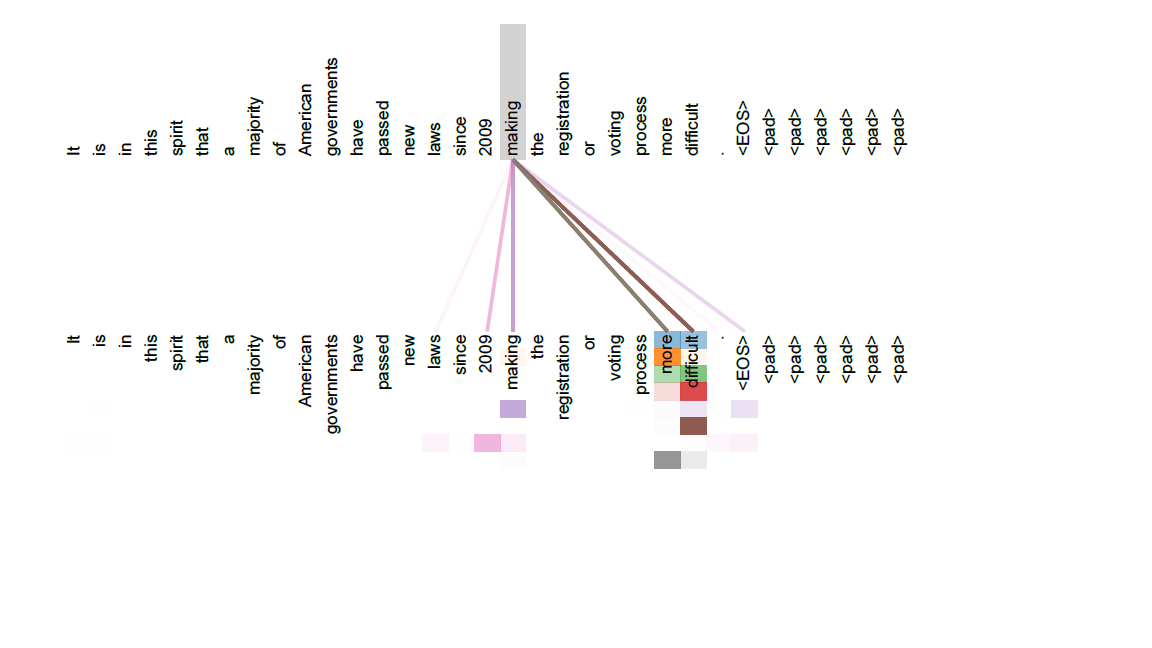
通过训练,我们发现,句子中的making一词,跟后面的more和difficult之间的关系更紧密,所以它们之间的权重更高。
那么,如何去实现句子中的自注意力呢?
为了减少计算量,我们采用点积做为主要的算法,这种结构叫做缩放点积注意力模块:

如图所示,我们把一个词变换成三种东西:Q, K, V. 其中Q代表Query查询,K代表Key键,它们先进行矩阵乘,然后进行缩放,再进行Softmask,所取得的结果再与V既Value之间再进行矩阵乘。
对于矩阵乘和Softmax不了解的同学不用急,我在后面会补充基础知识,大家先理解自注意力模块的实现逻辑。
我们用PyTorch可以这样写:
# 计算注意力权重,使用缩放点积注意力
A = torch.matmul(Q, K) / np.sqrt(self.head_dim) # (batch_size, num_heads, seq_len_q ,seq_len_k)
A = torch.softmax(A ,dim=-1) # (batch_size,num_heads ,seq_len_q ,seq_len_k)
# 计算注意力输出
O = torch.matmul(A ,V) # (batch_size,num_heads ,seq_len_q ,head_dim)
我们再用TensorFlow.js来看看如何写:
// 计算注意力分数
const scores = tf.matMul(qHeads, kHeads, false, true).div(tf.sqrt(this.depth));
// 应用softmax函数进行归一化
const attentionWeights = tf.softmax(scores, -1);
// 计算加权的Value向量
const weightedValues = tf.matMul(attentionWeights, vHeads);
缩放点积注意力只是一个词对另一个词的注意力,要计算每一个词,我们还得将其组合起来,变成一个更大的自注意力模块:多头自注意力模块。

所谓多头,就是有h个缩放点积注意力最终拼接在一起。
下面我们用PyTorch来实现这个多头的拼接模块:
# 定义自注意力模型类
class SelfAttention(nn.Module):
def __init__(self, input_dim, output_dim, num_heads):
super(SelfAttention, self).__init__()
# 参数检查
assert output_dim % num_heads == 0, "output_dim must be divisible by num_heads"
# 定义线性变换层
self.W_q = nn.Linear(input_dim, output_dim)
self.W_k = nn.Linear(input_dim, output_dim)
self.W_v = nn.Linear(input_dim, output_dim)
# 定义输出层
self.W_o = nn.Linear(output_dim, output_dim)
# 定义头数和头部维度
self.num_heads = num_heads
self.head_dim = output_dim // num_heads
def forward(self, x):
# x: (batch_size, seq_len, input_dim)
# 计算Q,K,V
Q = self.W_q(x) # (batch_size, seq_len, output_dim)
K = self.W_k(x) # (batch_size, seq_len, output_dim)
V = self.W_v(x) # (batch_size, seq_len, output_dim)
# 将Q,K,V分割成多个头部
Q = Q.view(Q.shape[0], Q.shape[1], self.num_heads, self.head_dim) # (batch_size, seq_len, num_heads, head_dim)
K = K.view(K.shape[0], K.shape[1], self.num_heads, self.head_dim) # (batch_size, seq_len, num_heads, head_dim)
V = V.view(V.shape[0], V.shape[1], self.num_heads, self.head_dim) # (batch_size, seq_len, num_heads, head_dim)
# 调整维度顺序,便于计算注意力权重
Q = Q.permute(0, 2, 1, 3) # (batch_size, num_heads, seq_len, head_dim)
K = K.permute(0, 2, 3, 1) # (batch_size, num_heads, head_dim, seq_len)
V = V.permute(0, 2, 1, 3) # (batch_size, num_heads, seq_len, head_dim)
# 计算注意力权重,使用缩放点积注意力
A = torch.matmul(Q, K) / np.sqrt(self.head_dim) # (batch_size, num_heads, seq_len_q ,seq_len_k)
A = torch.softmax(A ,dim=-1) # (batch_size,num_heads ,seq_len_q ,seq_len_k)
# 计算注意力输出
O = torch.matmul(A ,V) # (batch_size,num_heads ,seq_len_q ,head_dim)
# 调整维度顺序,便于拼接头部
O = O.permute(0 ,2 ,1 ,3) # (batch_size ,seq_len_q ,num_heads ,head_dim)
# 拼接头部,得到最终输出
O = O.reshape(O.shape[0] ,O.shape[1] ,-1) # (batch_size ,seq_len_q ,output_dim)
O = self.W_o(O) # (batch_size ,seq_len_q ,output_dim)
return O
我们可以写一段测试代码来跑一下:
# 测试代码
input_dim = 8
output_dim = 16
num_heads = 8
seq_len = 3
batch_size = 2
x = torch.randn(batch_size ,seq_len ,input_dim)
model = SelfAttention(input_dim ,output_dim ,num_heads)
y = model(x)
print(y.shape)
输出为:
torch.Size([2 ,3 ,16])
我们再看看用TensorFlow.js如何实现:
// 导入TensorFlow.js库
import * as tf from '@tensorflow/tfjs';
class SelfAttention {
constructor(dModel, numHeads) {
this.dModel = dModel;
this.numHeads = numHeads;
this.depth = dModel / numHeads;
// 定义Q, K, V线性层的权重矩阵
this.wq = tf.variable(tf.randomNormal([dModel, dModel]));
this.wk = tf.variable(tf.randomNormal([dModel, dModel]));
this.wv = tf.variable(tf.randomNormal([dModel, dModel]));
// 定义输出线性层的权重矩阵
this.wo = tf.variable(tf.randomNormal([dModel, dModel]));
}
// 自注意力计算过程
async call(inputs) {
const q = tf.matMul(inputs, this.wq);
const k = tf.matMul(inputs, this.wk);
const v = tf.matMul(inputs, this.wv);
const batchSize = inputs.shape[0];
const seqLen = inputs.shape[1];
// 将Q, K, V分成多个头
const qHeads = this.splitHeads(q, batchSize);
const kHeads = this.splitHeads(k, batchSize);
const vHeads = this.splitHeads(v, batchSize);
// 计算注意力分数
const scores = tf.matMul(qHeads, kHeads, false, true).div(tf.sqrt(this.depth));
// 应用softmax函数进行归一化
const attentionWeights = tf.softmax(scores, -1);
// 计算加权的Value向量
const weightedValues = tf.matMul(attentionWeights, vHeads);
// 将多个头的输出重新组合
const output = this.combineHeads(weightedValues, batchSize);
// 应用输出线性层
return tf.matMul(output, this.wo);
}
// 将张量分割为多个头
splitHeads(tensor, batchSize) {
return tensor.reshape([batchSize, -1, this.numHeads, this.depth]).transpose([0, 2, 1, 3]);
}
// 将多个头的输出重新组合
combineHeads(tensor, batchSize) {
return tensor.transpose([0, 2, 1, 3]).reshape([batchSize, -1, this.dModel]);
}
}
来段调用让其跑起来:
// 使用示例
(async () => {
const dModel = 64;
const numHeads = 8;
const inputShape = [1, 10, dModel]; // 假设输入序列有10个词,每个词的向量维度是64
const inputs = tf.randomNormal(inputShape);
const selfAttention = new SelfAttention(dModel, numHeads);
const outputs = await selfAttention.call(inputs);
outputs.print();
})();
Transformer
有了多头注意力模块,剩下就是搭积木的工作了,我们看下面的图:
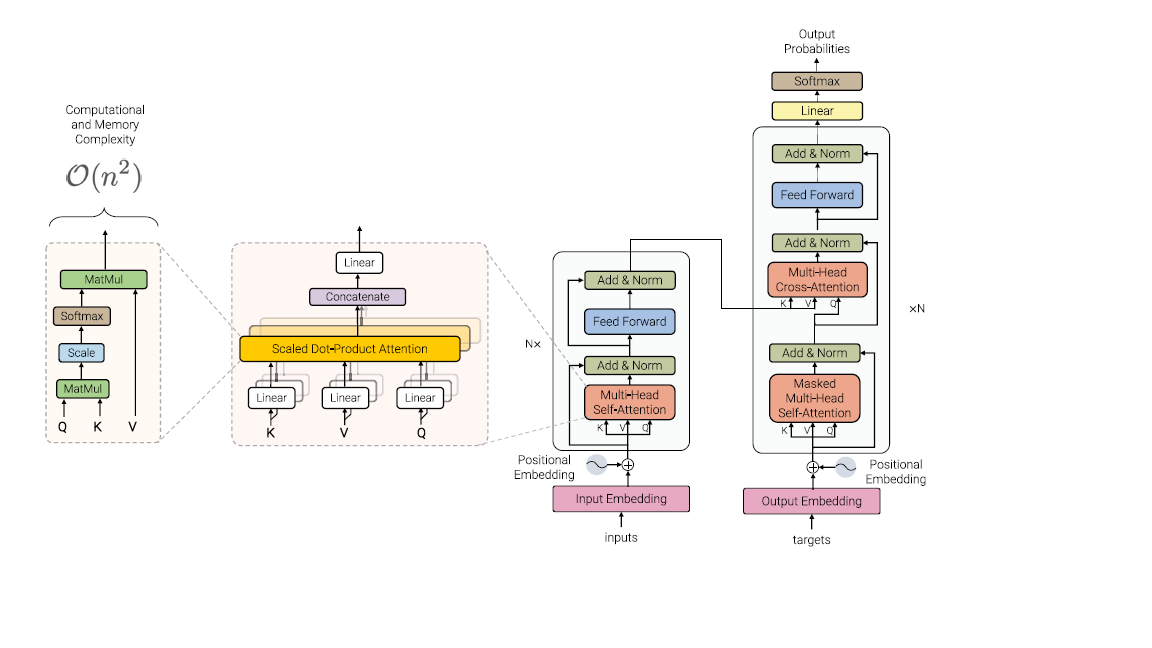
input上面是编码器,target上面的是解码器。可以两个一起用,也可以只用编码器或者只用解码器。
图中有一个新增的模块,就是位置嵌入层。因为自注意力机制只跟相关性有关,而跟位置远近无关。所以我们需要一个另外的机制将位置信息编码进去。
对于偶数位,我们使用sin函数来编码位置。对于奇数位,我们采用cos函数来编码位置。
下面是用PyTorch的实现:
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
position = torch.arange(max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))
pe = torch.zeros(max_len, 1, d_model)
pe[:, 0, 0::2] = torch.sin(position * div_term)
pe[:, 0, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
我们再来看下TensorFlow.js的实现:
class PositionalEncoding {
constructor(dModel) {
this.dModel = dModel;
}
call(x) {
const pos = tf.range(0, x.shape[1]).reshape([-1, 1]);
const divTerm = tf.range(0, this.dModel, 2).mul(-Math.log(10000) / this.dModel).exp();
const pe = tf.zeros([x.shape[1], this.dModel]);
const sinPos = tf.sin(pos.matMul(divTerm));
const cosPos = tf.cos(pos.matMul(divTerm));
const updatedPE = pe.bufferSync();
for (let i = 0; i < pe.shape[1]; i += 2) {
updatedPE.set(sinPos.dataSync()[Math.floor(i / 2)], 0, i);
updatedPE.set(cosPos.dataSync()[Math.floor(i / 2)], 0, i + 1);
}
return x.add(updatedPE.toTensor());
}
}
PyTorch为我们封装好了Transformer的编码器和解码器的模块,我们构成多层编码器和解码器组成的Transformers模型,就用封装好的模块就可以了,不需要再像上面一样自己手工写了.
其中,编码器是nn.TransformerEncoder,它可以由多层nn.TransformerEncoderLayer拼装成。
同样,解码器是nn.TransformerDecoder,可以由一层或多层nn.TransformerDecoderLayer组成。
我们来看个例子:
import torch
import torch.nn as nn
class TransformerModel(nn.Module):
def __init__(self, vocab_size, d_model, nhead, num_layers, dim_feedforward):
super(TransformerModel, self).__init__()
# 词嵌入层
self.embedding = nn.Embedding(vocab_size, d_model)
# 位置编码层
self.pos_encoder = PositionalEncoding(d_model)
# Transformer编码器层
encoder_layer = nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers)
# Transformer解码器层
decoder_layer = nn.TransformerDecoderLayer(d_model, nhead, dim_feedforward)
self.transformer_decoder = nn.TransformerDecoder(decoder_layer, num_layers)
# 输出层
self.linear = nn.Linear(d_model, vocab_size)
def forward(self, src, tgt, src_mask=None, tgt_mask=None, memory_mask=None):
# 输入嵌入
src = self.embedding(src)
tgt = self.embedding(tgt)
# 位置编码
src = self.pos_encoder(src)
tgt = self.pos_encoder(tgt)
# 通过Transformer编码器
memory = self.transformer_encoder(src, src_mask)
# 通过Transformer解码器
output = self.transformer_decoder(tgt, memory, tgt_mask, memory_mask)
# 输出层
output = self.linear(output)
return output
Torch.nn.Transformer默认是包含了6层编码器和6层解码器的结构,其中输入是512维,头有8个
torch.nn.Transformer(d_model=512, nhead=8, num_encoder_layers=6, num_decoder_layers=6, dim_feedforward=2048, dropout=0.1, activation=<function relu>, custom_encoder=None, custom_decoder=None, layer_norm_eps=1e-05, batch_first=False, norm_first=False, device=None, dtype=None)
我们再看下用TensorFlow.js来实现Transformer.
这次用我们使用封装的tf.layers.multiHeadAttention来构建编码器:
class EncoderLayer {
constructor(dModel, nhead, ffDim) {
this.multiHeadAttention = tf.layers.multiHeadAttention({headSize: nhead, numHeads: dModel / nhead, outputDim: dModel});
this.ffn = tf.sequential();
this.ffn.add(tf.layers.dense({units: ffDim, activation: 'relu'}));
this.ffn.add(tf.layers.dense({units: dModel}));
this.norm1 = tf.layers.layerNormalization();
this.norm2 = tf.layers.layerNormalization();
}
call(x) {
const attention = this.multiHeadAttention.apply([x, x, x]);
const norm1 = this.norm1.apply(x.add(attention));
const ffn = this.ffn.apply(norm1);
const norm2 = this.norm2.apply(norm1.add(ffn));
return norm2;
}
}
解码器要复杂一点,因为还要有编码器的输入:
class DecoderLayer {
constructor(dModel, nhead, ffDim) {
this.multiHeadAttention1 = tf.layers.multiHeadAttention({headSize: nhead, numHeads: dModel / nhead, outputDim: dModel});
this.multiHeadAttention2 = tf.layers.multiHeadAttention({headSize: nhead, numHeads: dModel / nhead, outputDim: dModel});
this.ffn = tf.sequential();
this.ffn.add(tf.layers.dense({units: ffDim, activation: 'relu'}));
this.ffn.add(tf.layers.dense({units: dModel}));
this.norm1 = tf.layers.layerNormalization();
this.norm2 = tf.layers.layerNormalization();
this.norm3 = tf.layers.layerNormalization();
}
call(inputs) {
const [x, encOutput] = inputs;
const attention1 = this.multiHeadAttention1.apply([x, x, x]);
const norm1 = this.norm1.apply(x.add(attention1));
const attention2 = this.multiHeadAttention2.apply([norm1, encOutput, encOutput]);
const norm2 = this.norm2.apply(norm1.add(attention2));
const ffn = this.ffn.apply(norm2);
const norm3 = this.norm3.apply(norm2.add(ffn));
return norm3;
}
}
最后,我们把位置嵌入、编码器、解码器都整合在一起:
class TransformerModel {
constructor(vocabSize, dModel, nhead, numLayers, ffDim) {
this.embedding = tf.layers.embedding({inputDim: vocabSize, outputDim: dModel});
this.posEncoder = new PositionalEncoding(dModel);
this.encoderLayer = new Array(numLayers).fill(null).map(() => new EncoderLayer(dModel, nhead, ffDim));
this.decoderLayer = new Array(numLayers).fill(null).map(() => new DecoderLayer(dModel, nhead, ffDim));
this.finalLayer = tf.layers.dense({units: vocabSize});
}
async call(src, tgt) {
const srcEmbedding = this.embedding.apply(src);
const tgtEmbedding = this.embedding.apply(tgt);
const srcPos = this.posEncoder.call(srcEmbedding);
const tgtPos = this.posEncoder.call(tgtEmbedding);
let encOutput = srcPos;
this.encoderLayer.forEach(layer => {
encOutput = layer.call(encOutput);
});
let decOutput = tgtPos;
this.decoderLayer.forEach(layer => {
decOutput = layer.call([decOutput, encOutput]);
});
const finalOutput = this.finalLayer.apply(decOutput);
return finalOutput;
}
}
我们的第一个语言模型
下面我们来一个真实的用Transformer来学习wiki文本,然后根据学习的语言模型让它来生成胡说八道的句子的例子。
我们使用PyTorch官方的例子,因为它为我们准备好了数据和脚本。blog也没有稿费,我们不水这么多代码了。
下载方法:
git clone https://github.com/pytorch/examples
然后进入word_language_model目录,运行下面的命令:
python main.py --cuda --epochs 6 --model Transformer --lr 5
如果你没有GPU,就把–cuda去掉。
学习的数据在word_language_model\data\wikitext-2目录下面,训练数据都是从wiki里面提取的,开始是战场女武神3游戏的词条。
训练好之后,我们就可以利用我们刚才训练的语言模型来由AI生成语句啦。
命令为:
python .\generate.py --cuda --outf g2.txt
打开g2.txt,我们就能看到我们自己的小语言模型的效果啦。
我来几句话:
to every year was stabilized . From ( 1964 , it had undergone a viable against criminal @-@ architectural scholar
as Main Online , which was moved into Webster were contacted ;
跟现在虽然经常胡说八道的gpt4相比,我们的小小语言模型还处于人话都说不明白的阶段。
虽然非常非常小,但是我们用的思想、原理和技术,跟gpt4是一样的。
我们堆很多很多的文本,训练很大参数的模型,我们也一样可以做成跟某些厂商水平差不多的大模型来。不过就算比gpt4的参数还多,文本用的还好,跟chatgpt还是比不了的。还有好多的其他知识我们需要学习的。
现在我们回来看看这个能生成基本上词还算是正确的语言模型的源码,我们先看它的位置嵌入层的:https://github.com/pytorch/examples/blob/main/word_language_model/model.py
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
大家看看是不是跟我上面写的基本一样?那就对了,我就基本上照这个抄的 :)
我们再看下它的TransformerModel的代码,我把mask部分删掉了,大家看下是不是它就只用了TransformerEncoder,解码器用的是全连接网络:
class TransformerModel(nn.Module):
def __init__(self, ntoken, ninp, nhead, nhid, nlayers, dropout=0.5):
super(TransformerModel, self).__init__()
self.model_type = 'Transformer'
self.src_mask = None
self.pos_encoder = PositionalEncoding(ninp, dropout)
encoder_layers = TransformerEncoderLayer(ninp, nhead, nhid, dropout)
self.transformer_encoder = TransformerEncoder(encoder_layers, nlayers)
self.encoder = nn.Embedding(ntoken, ninp)
self.ninp = ninp
self.decoder = nn.Linear(ninp, ntoken)
self.init_weights()
def init_weights(self):
initrange = 0.1
nn.init.uniform_(self.encoder.weight, -initrange, initrange)
nn.init.zeros_(self.decoder.bias)
nn.init.uniform_(self.decoder.weight, -initrange, initrange)
def forward(self, src, has_mask=True):
src = self.encoder(src) * math.sqrt(self.ninp)
src = self.pos_encoder(src)
output = self.transformer_encoder(src, self.src_mask)
output = self.decoder(output)
return F.log_softmax(output, dim=-1)
我们最后再学习下调用语言模型生成文本的代码,这部分会了我们就掌握了推理的能力:
with open(args.checkpoint, 'rb') as f:
model = torch.load(f, map_location=device)
model.eval()
corpus = data.Corpus(args.data)
ntokens = len(corpus.dictionary)
input = torch.randint(ntokens, (1, 1), dtype=torch.long).to(device)
with open(args.outf, 'w') as outf:
with torch.no_grad(): # no tracking history
for i in range(args.words):
output = model(input, False)
word_weights = output[-1].squeeze().div(args.temperature).exp().cpu()
word_idx = torch.multinomial(word_weights, 1)[0]
word_tensor = torch.Tensor([[word_idx]]).long().to(device)
input = torch.cat([input, word_tensor], 0)
word = corpus.dictionary.idx2word[word_idx]
outf.write(word + ('\n' if i % 20 == 19 else ' '))
if i % args.log_interval == 0:
print('| Generated {}/{} words'.format(i, args.words))
基本原理就是根据当前情况下的最大概率值来生成文本。
改进Transformer
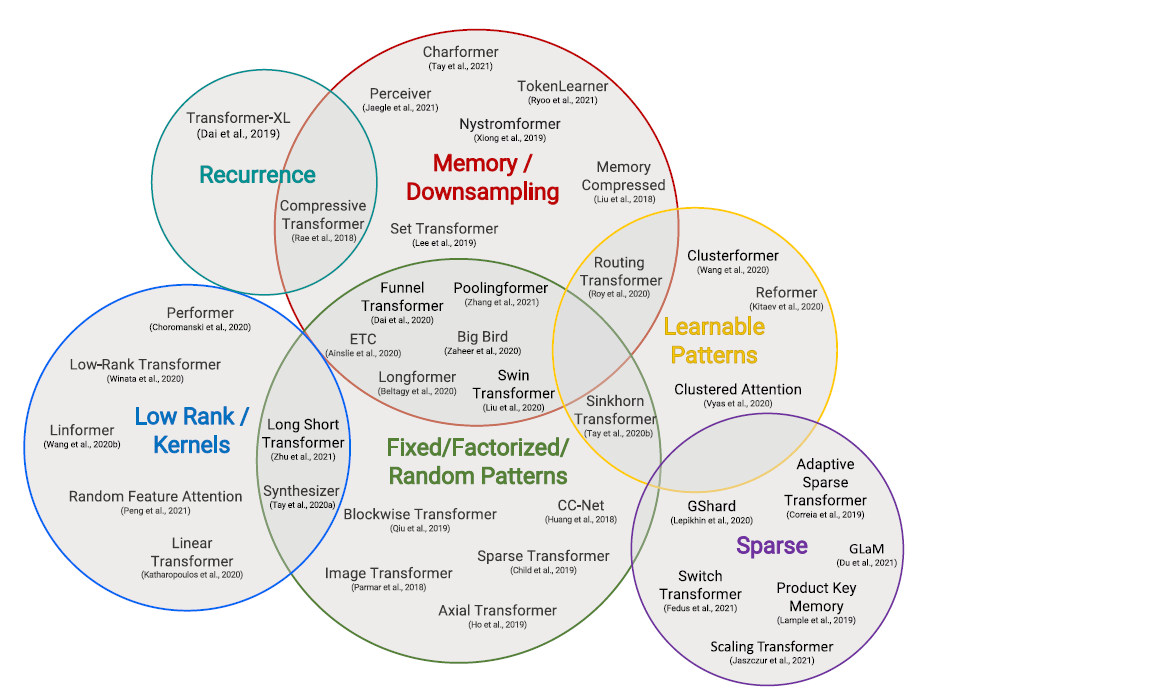
刚刚入门就讲Transformer的变体实在是有点烧脑,但是我们要知道,Transformer并不只有这一种方式,虽然主流编程库就支持上面的这一种。
我们从下面的图可以看到,Transformer这么基本的模块,研究者们动了各种脑筋试图去优化它。
小结
不管大规模预训练模型有多大,其基本原理跟我们本节所学的语言模型是一样的。我们都是堆Transformer,然后基于大量的文本进行训练,然后用训练好的语言模型进行生成。