基于K-最近邻算法构建鸢尾花分类模型
一 任务描述
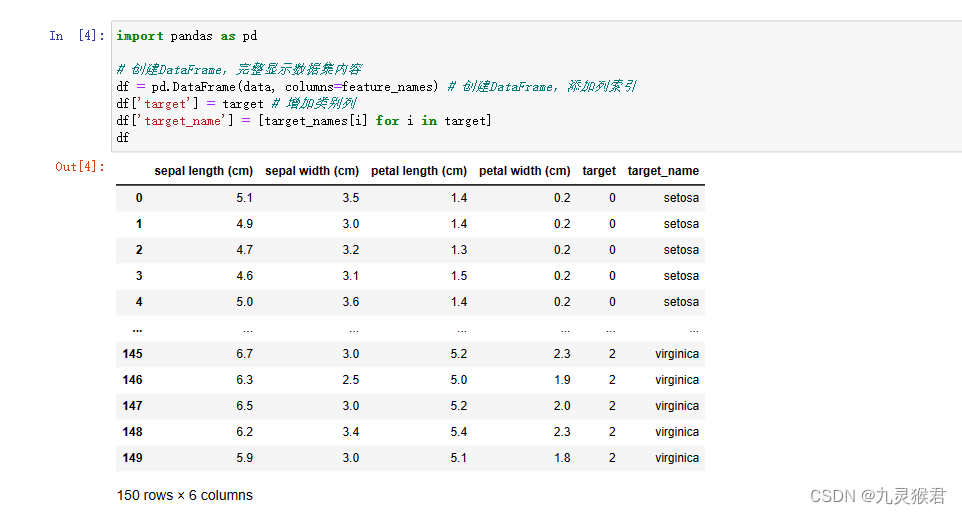
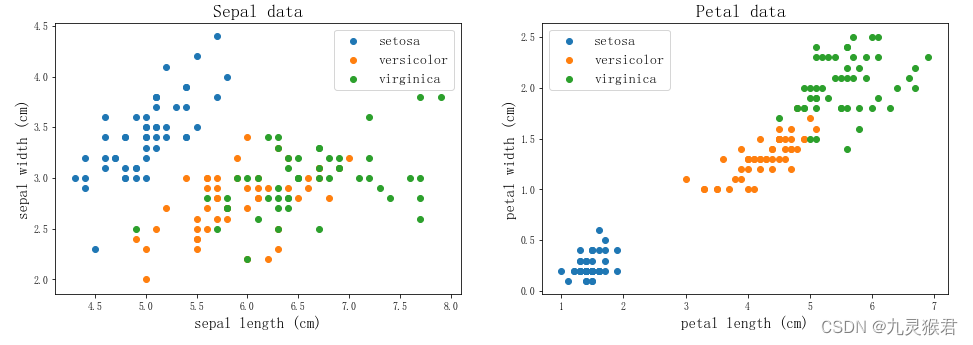
鸢尾花(Iris)数据集是机器学习中一个经典的数据集。假设有一名植物学爱好者收集了150朵鸢尾花的测量数据:花瓣的长度和宽度以及花萼的长度和宽度,这些花已经鉴定为属于Setosa、Versicolor和Virginica三个品种之一。
本任务的主要工作内容包括:
1、 使用 Pandas和Matplotlib可视化并观察数据;
2、 将数据集随机拆分为训练集(train set)和测试集(test set);
3、 构建一个机器学习分类模型(K-最近邻算法)并评估其准确性(Accuracy)。
资源包下载链接
二 任务目标
- 掌握机器学习的基本概念,如样本、特征、训练集和测试集、泛化能力、模型评估、模型的准确性(Accuacy)等。 重点
- 熟悉使用Scikit-learn构建机器学习模型的基本过程。 重点
- 熟悉K-最近邻算法(KNN算法)的思想。 重点
- 掌握数据集拆分函数、训练拟合函数、模型评估函数的使用。 重点
三 任务环境
-
操作系统:Windows 10、Ubuntu18.04
-
工具软件:Anaconda3 2019、Python3.7
-
硬件环境:无特殊要求
-
依赖库列表
matplotlib 3.3.4 numpy 1.19.5 pandas 1.1.5 scikit-learn 0.24.2
四 任务分析
因为学习数据中已知鸢尾花的品种(即数据的标签),所以这是一个监督学习,另外模型的用途是预测新的测量数据的品种,因此这是一个分类(Classification)问题。单个数据点(一朵鸢尾花的测量数据)的预期输出是这朵花的品种(标签)。
本任务涉及以下几个环节:
a)认识数据、观察数据(可视化)
b)将数据拆分为训练集与测试集
c)构建模型:K最近邻算法
d)训练模型
e)评估模型
五 资源介绍
5.1 资源截图

5.2 部分代码截图