文章目录
- 基础篇
- 执行一条select语句,期间发生了什么?
- MySQL一行记录是怎么存储的?
- 索引篇
- 索引常见面试题
- 什么是索引?
- 索引的分类?
- 小结
- 从数据页的角度看B+树
- 为什么MySQL采用B+树作为索引?
- MySQL单表不要超过2000W行,靠谱吗?
- 事务篇
- 锁篇
- 内存篇
参考文档
基础篇
执行一条select语句,期间发生了什么?
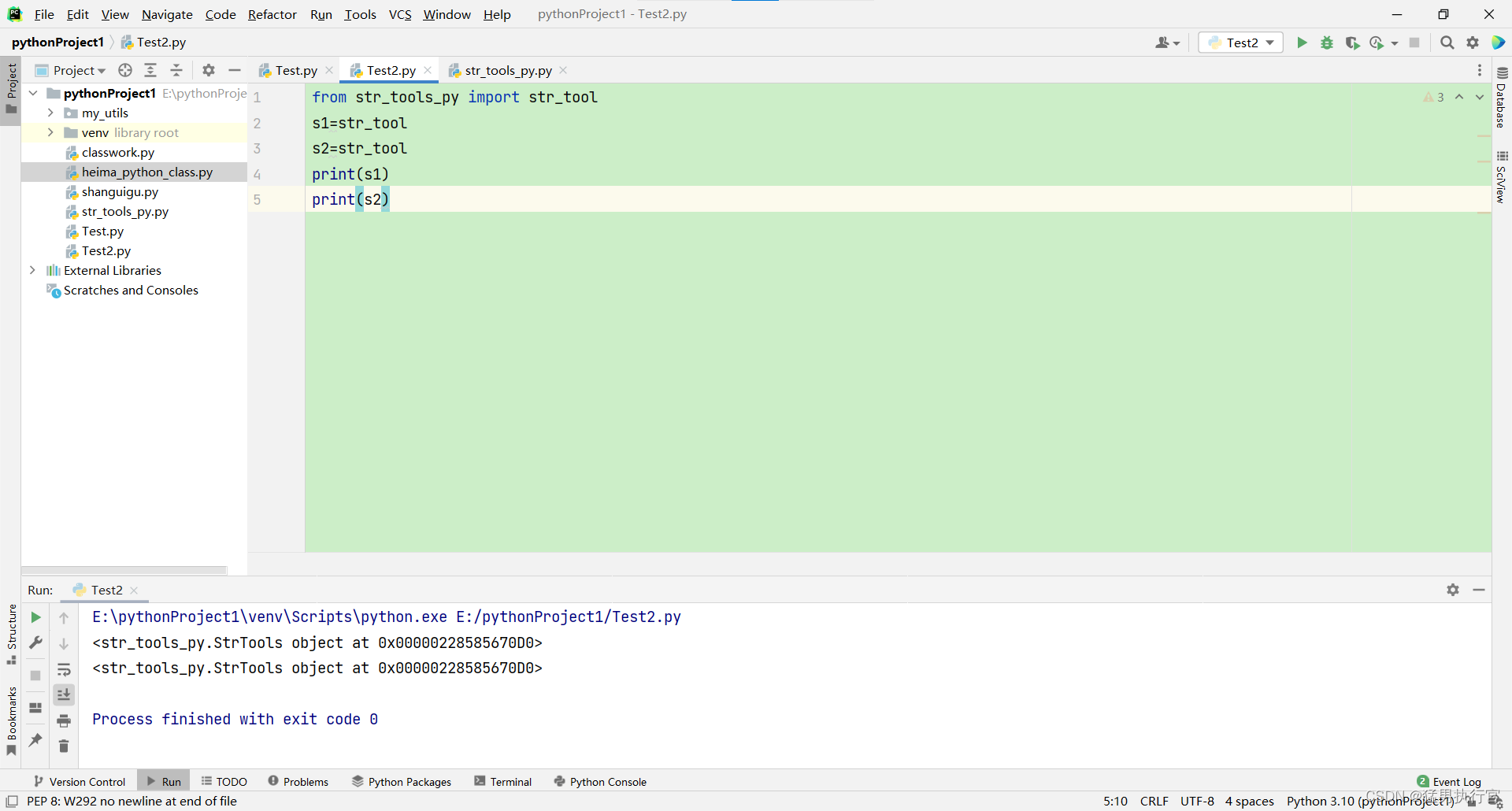
# 输出这条SQL语句的执行计划,然后key表示执行过程中使用了哪个索引
explain select * from order where id =1;

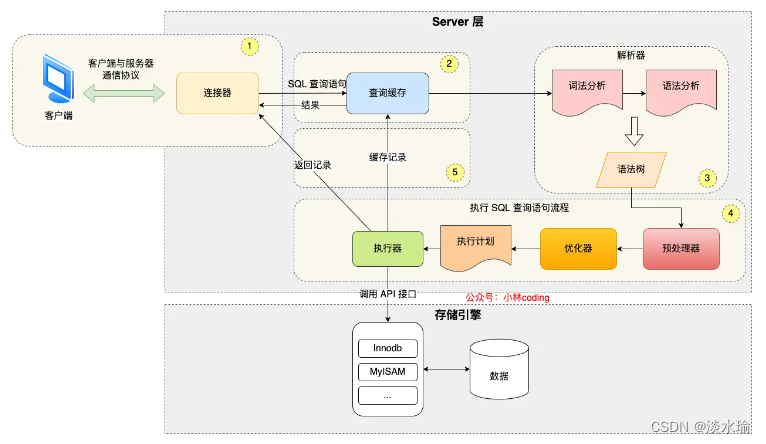
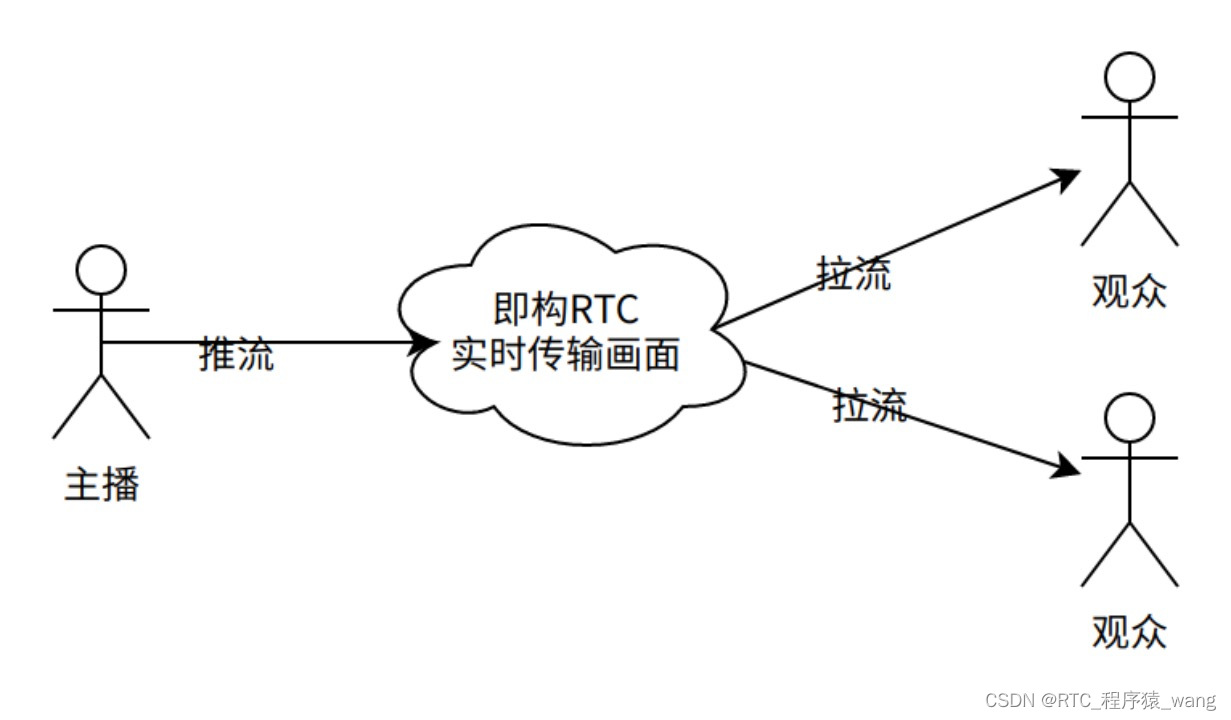
- 连接器:建立连接、管理连接、校验用户身份。
- 查询缓存:如果查询到缓存则直接返回,否则继续执行。MySQL8.0已删除模块。
- 解析SQL:词法分析、语法分析、构建语法树,方便后续读取表名、字段、语句类型。
- 执行SQL:
- 预处理阶段:检查表或字段是否存在;
- 优化阶段:基于查询成本的考虑,选择成本最小的查询执行计划;
- 执行阶段:执行SQL语句,从存储引擎读取记录,返回给客户端;
MySQL一行记录是怎么存储的?
数据库文件位置:C:\ProgramData\MySQL\MySQL Server 8.0\Data
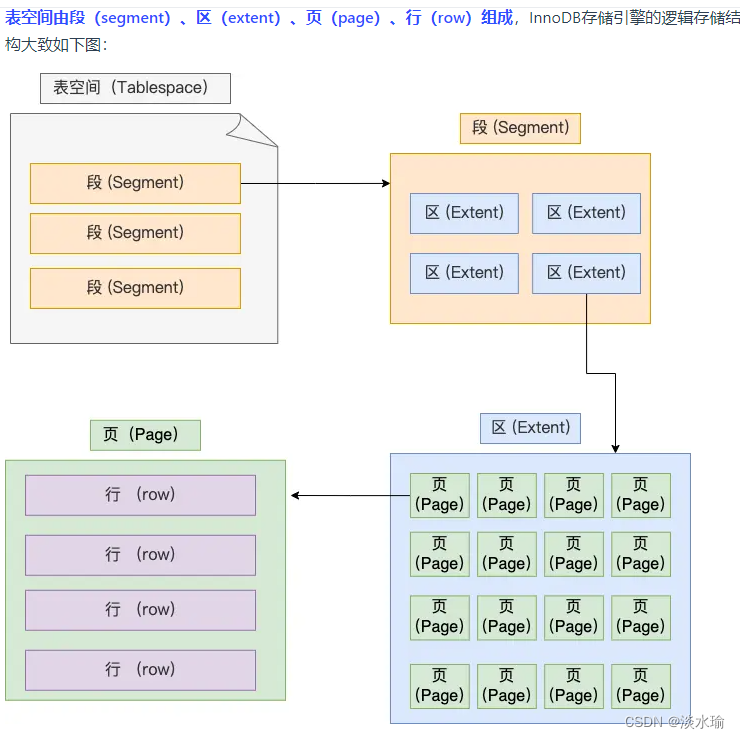
表空间:段、区、页、行。
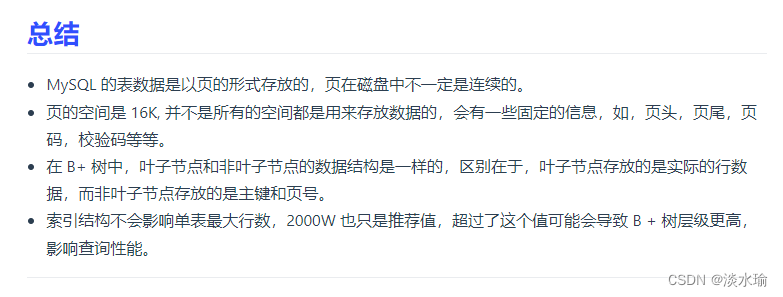
InnoDB的数据是按照[页]为单位来读写的。每个页默认为16kb。

记录的额外信息:
3个部分:变长字段长度列表、NULL值列表、记录头信息。

记录的真实数据:
定义的真实字段,还有三个隐藏字段,分别是row_id、trx_id、roll_pointer。

MySQL的NULL值是怎么存放的?
NULL值并不会储存在行格式中的真实数据部分。
NULL值列表会占用1个字节空间。
MySQL怎么知道varchar(n)实际占用数据的大小?
会用变长字段长度列表,存储变长字段实际占用的数据大小。
varchar(n)中的n最大取值多少?
一行记录最大能存储65535字节的数据,但是这个包含了变长字段和NULL值占用的字节。
行溢出后,MySQL是怎么处理的?
InnoDB存储疫情会自动将溢出的数据存放到[溢出页]中。
索引篇
索引常见面试题
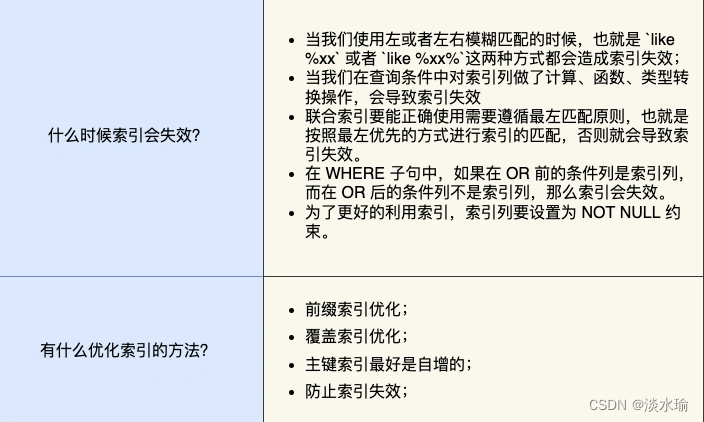
什么是索引?
书的目录,就充当索引的角色。
索引 是数据的目录。
索引的分类?

小结
InnoDB是在MySQL5.5之后默认的存储引擎,B+Tree索引类型也是MySQL存储引擎采用最多的索引类型。
B+Tree 相比于 B 树和二叉树来说,最大的优势在于查询效率很高,因为即使在数据量很大的情况,查询一个数据的磁盘 I/O 依然维持在 3-4次。



从数据页的角度看B+树
InnoDB的数据是按数据页为单位来读写的,默认数据页大小是16KB。
每个数据页面之间通过双向链表的形式组织起来,物理上不连续,但是逻辑上连续。
数据页内包含用户记录,每个记录之间用单向链表的方式组织起来,为了加快在数据页内高效查询记录,设计了一个页目录,页目录存储各个槽(分组),且主键值是有序的,于是可以通过二分查找法的方式进行检索从而提高效率。
为了高效查询记录所在的数据页,InnoDB 采用== b+ 树作为索引,每个节点都是一个数据页==。
在使用二级索引进行查找数据时,如果查询的数据能在二级索引找到,那么就是索引覆盖操作,如果查询的数据不在二级索引里,就需要先在二级索引找到主键值,需要去聚簇索引中获得数据行,这个过程就叫作回表。
为什么MySQL采用B+树作为索引?
磁盘读写的最小单位是扇区,扇区的大小只有== 512B== 大小,操作系统一次会读写多个扇区,所以操作系统的最小读写单位是块(Block)。
Linux 中的块大小为 4KB,也就是一次磁盘 I/O 操作会直接读写 8 个扇区。

MySQL单表不要超过2000W行,靠谱吗?
事务篇
事务是在MySQL引擎层实现的,我们常见的InnoDB引擎是支持事务的,事务的四大特性是原子性、一致性、隔离性、持久性,我们这次主要讲的是隔离性。
当多个事务并发执行的时候,会引发脏读、不可重复读、幻读 这些问题。为了避免这些问题,SQL提出了四种隔离级别,分别是读未提交、可重复度、串行化,从左往右隔离级别顺序递增,隔离级别越高,一位置性能越差,InnoDB引擎的默认隔离级别是可重复读。

锁篇
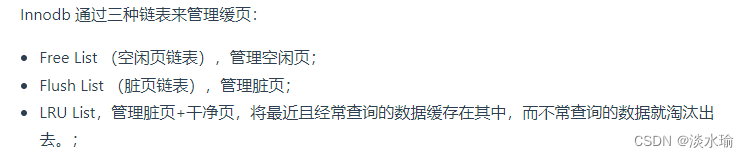
内存篇
Innodb存储引擎设计了一个缓冲池Buffer Pool,来提高数据库读写性能。
Buffer Pool以页未单位缓冲数据,可以通过innodb_buffer_pool_size参数调整缓冲池的大小,默认是128M。