集成学习(Ensemble Learning)
1概念
集成学习就是将多个弱学习器组合在一起,从而得到一个更好更全面的强监督学习器模型。其中集成学习被分为3大类:bagging(袋装法)不存在强依赖关系,其中基学习器保持并行关系学习。boosting(提升法)存在强依赖关系,其中基学习器存在串行的方式学习。stacking(模型融合)通过组合模型,来提高预测精度。
Ensemble Learning的第一个问题是如何得到若干个个体学习器。这里有两种选择。
- 1——第一种就是所有的学习器都是同质的,比如所有的学习器都是神经网络,决策树。
- 2——第二种就是学习器不是同质的,如训练的时候使用随机森林,SVM,决策树等,然后再根据结合策略来确定选择分类器强的。
目前来说,同质个体学习器的应用是最广泛的,一般我们常说的集成学习的方法都是指的同质个体学习器。而同质个体学习器使用最多的模型是CART决策树和神经网络。
想要获得良好的集成性能,基分类器需要满足两个条件
1———基学习器要一定的性能,并且基学习器的性能不差于随机猜测,且准确率要在50%之上
2———基学习器之间要由差异性,具有多样性,不能基学习器都相同。
2结合策略
学习器的结合策略主要细分为3总。我们假定得到T个弱学习器{h1,h2,,,,ht}
2.1平均法
对于回归问题来讲,通常使用的是平均法,对若干个学习器的结果进行求平均。
2.2投票法
通常对于分类问题来讲,使用的是投票法。分为三种,相对多数投票法,即少数服从多数;绝对多数投票法,不仅仅要求票数最多,而且还需要要求票数过半;加权投票法,每个弱学习器的分类树乘上一个权重,最后各个类别的加权票数求和,选择最大的。
2.3学习法
将不会对弱学习器的结果做逻辑处理,而是再次之上再加上一层学习器。将训练集弱学习器的学习结果作为输入,训练集的输出作为输出,重新训练一个学习器来得到最终的结果。简而言之,再弱学习器之上再进行一次学习。
3Bagging
3.1概念
Bagging是并行式集成学习的最著名代表,名字是由Bootstrap AGGregatING缩写而来,看到Bootstrap我们就会联想到boostrap的随机模拟法和它对应的样本获取方式,它是基于自助采样法(Boostrap sampleing),Bagging也是同理.给定包含m个样本的数据集,先随机抽取一个样本放入采样集中,再把该样本放回,使得下次采样时该样本仍有机会被选中,这样经过m次采样,我们便从原始是数据集中抽取样本得到一个数据量同为m的数据集.说简单一点就是统计里的有放回抽样,且每个样本被抽取的概率相同,均为总样本数分之一。Bagging可以用于多分类,回归的任务.
3.2一般过程
bagging的算法过程如下:
- 1——从原始样本集中使用Bootstraping 方法随机抽取n个训练样本,共进行k轮抽取,得到k个训练集(k个训练集之间相互独立,元素可以有重复)。
- 2——对于n个训练集,我们训练k个模型,(这个模型可以根据具体的情况而定,可以是决策树,knn等)
- 3——对于分类问题:由投票表决定产生的分类结果。对于回归问题,有所选定的k个模型结果的均值来作为最后的预测结果。
3.3典型代表
3.3.1随机森立(决策树)
Ⅰ.概念
随机森林-介绍
Ⅱ.代码练习sklearn
4Boosting
4.1概念
Boosting由于各个基学习器处于串行的关系,各个基学习器存在强依赖关系,所以Boosting的学习是一个迭代的过程。
Boosting的学习机制为:先从基学习器当中训练出来一个基学习器,再根据基学习器对数据集的表现进行操作(将训练错误的数据的权重增大,训练正确的数据的权重减少。)基于调整后的数据集来训练下一个基学习器。如此重复,在基学习器达到设定的数量的时候,然后将这N个基学习器的结果进行加权求平均操作。Boosting中主要为Adaboost,XGBoost。
从偏差-方差的角度来看,Boosting主要关注降低偏差。从而说明Boosting是一个过拟合的模型。
偏差(variance)和方差(bias)
偏差(bias):预测值和真实值之间的误差。
方差(variance):预测值之间的离散程度,距离其期望值的距离。方差越大,数据的离散程度就会分散。
对于偏差(bais):偏差过高是由于模型的复杂度不够,泛化能力不够,应该通过增加模型复杂度来降低偏差(bais)。
对于方差(variance):方差过高是由于模型的泛化能能力过强,导致了过拟合,应该通过降低模型复杂度来实现。
比如加入正则化来限制模型的学习。
4.2 一般过程
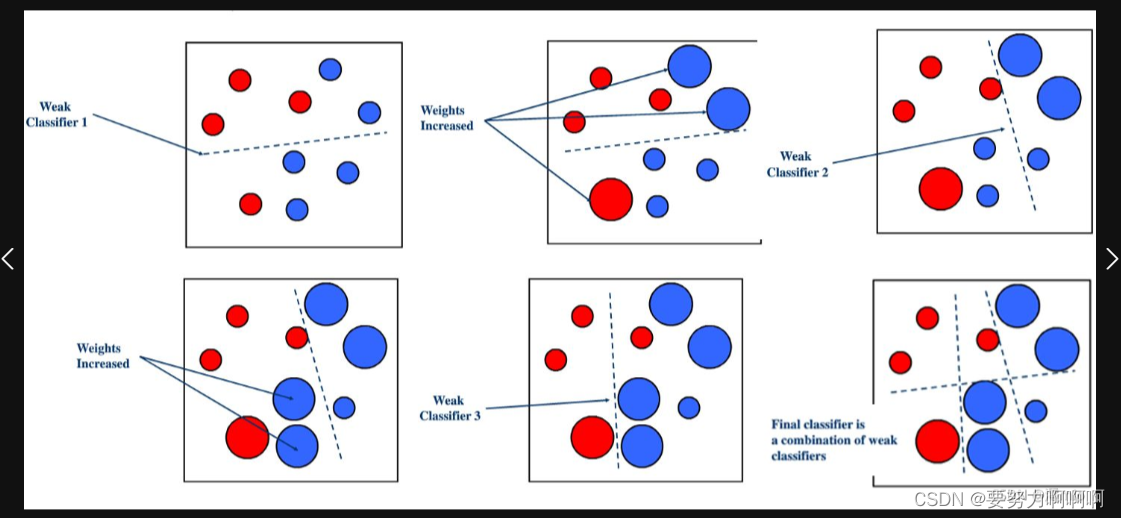
- ——1 Weak Classifier 1首先对数据集进行分类,这是一个弱分类器。其中可以得出分错了三个数据信息,然后使用Weights Increased对分类错误的数据进行权重增加。
- ——2 继而使用Weak Classifier 2对处理过后的数据进行再次分类。可以得出分错了3个数据,然后再次使用Weights Increased对分类错误的数据进行权重增加。
- ——3 继而使用Weak Classifier 3对处理过后的数据进行再次分类。然后最后汇总所有的分类结果信息。
4.3典型代表
4.3.1.AdaBoost算法
Ⅰ.概念
AdaBoost既可以做回归也可以做分类.理论上任何学习器都可以用于Adaboost.但一般来说,使用最广泛的Adaboost弱学习器是决策树和神经网络。对于决策树,Adaboost分类用了CART分类树,而Adaboost回归用了CART回归树。
优缺点总结:
优点总结
- 1——作为分类器时,分类精度很高。
- 2——可以使用任何回归分类模型来构建弱学习器
- 3——二分类器时,构造简单
- 4——不容易发生过拟合
缺点总结 - 1——对异常值比较敏感
Ⅱ.理论总结
暂时省略。。。。
Ⅲ.代码练习sklearn
from numpy import *
import matplotlib.pyplot as plt
import random
from sklearn import tree
def loadDataSet(filename):
numFeat = len(open(filename).readline().split('\t'))
dataMat = []
labelMat = []
fr = open(filename)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')#line.strip()首先清除掉一些空格,然后按照'\t'进行划分
for i in range(numFeat - 1):#添加数据
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))#添加数据对应标签
return dataMat,labelMat
#自助法采样
def rand_train(dataMat,labelMat):
len_train = len(labelMat)
train_data = []
train_label = []
#抽取样本的次数为样本的数目
for i in range(len_train):
index = random.randint(0,len_train-1)
train_data.append(dataMat[index])
train_label.append(labelMat[index])
return train_data,train_label
#决策树学习
#默认并行生成十个基学习器
def bagging_by_tree(dataMat,labelMat,t=10):
test_data,test_label = loadDataSet('E:/ZGW/PycharmProjects1/pythonProject1/scikit-learn/ensemble_learning/HorseColicData/horseColicTest.txt')
predict_list = []
for i in range(t):
train_data,train_label = rand_train(dataMat,labelMat)
clf = tree.DecisionTreeClassifier()#初始化决策树模型
clf.fit(train_data,train_label)#训练模型
total = []
y_predicted = clf.predict(test_data)#预测数据
total.append(y_predicted)
predict_list.append(total)#结果添加到预测列表当中
return predict_list,test_label
#计算错误率
def calc_error(predict_list,test_label):
m,n,k = shape(predict_list)
#分类问题就使用投票数,投票数占比最多的一个类别。
predict_label = sum(predict_list,axis=0)
predict_label = sign(predict_label)#取数字符号(数字前的正负号).如果为负号就说明类别数为-1,如果为正号就说明类别数为+1.
for i in range(len(predict_label[0])):
if predict_label[0][i] == 0:
tip = random.randint(0,1)
if tip == 0:
predict_label[0][i] = 1
else:
predict_label[0][i] = -1
error_count = 0
for i in range(k):
if predict_label[0][i] != test_label[i]:
error_count += 1
error_rate = error_count / k
return error_rate
def bagging_by_Onetree(dataMat,labelMat,t=10):
test_data,test_label = loadDataSet('E:/ZGW/PycharmProjects1/pythonProject1/scikit-learn/ensemble_learning/HorseColicData/horseColicTest.txt')
train_data,train_label = rand_train(dataMat,labelMat)
clf = tree.DecisionTreeClassifier()
clf.fit(train_data,train_label)
y_predicted = clf.predict(test_data)
error_count = 0
for i in range(67):
if y_predicted[i] != test_label[i]:
error_count += 1
return error_count/67
if __name__ == "__main__":
fileName = 'E:/ZGW/PycharmProjects1/pythonProject1/scikit-learn/ensemble_learning/HorseColicData/horseColicTraining.txt'
dataMat,labelMat = loadDataSet(fileName)
train_data,train_label = rand_train(dataMat,labelMat)
predict_list , test_label = bagging_by_tree(dataMat,labelMat)
print('单一错误率:',bagging_by_Onetree(dataMat,labelMat))
print("Bagging错误率:",calc_error(predict_list,test_label))
AdaBoost-参数
- 1——base_estimator:基分类器,默认是决策树,在该分类器基础上进行boosting,理论上可以是任意一个分类器,但是如果是其他分类器时需要指明样本权重。
- 2——n_estimators:基分类器提升(循环)次数,默认是50次,这个值过大,模型容易过拟合;值过小,模型容易欠拟合。
- 3——learning_rate:学习率,表示梯度收敛速度,默认为1,如果过大,容易错过最优值,如果过小,则收敛速度会很慢;该值需要和n_estimators进行一个权衡,当分类器迭代次数较少时,学习率可以小一些,当迭代次数较多时,学习率可以适当放大。
- 4——algorithm:boosting算法,也就是模型提升准则,有两种方式SAMME, 和SAMME.R两种,默认是SAMME.R,两者的区别主要是弱学习器权重的度量,前者是对样本集预测错误的概率进行划分的,后者是对样本集的预测错误的比例,即错分率进行划分的,默认是用的SAMME.R。
- 5——随机种子设置。
AdaBoost-方法
- 1——decision_function(X):返回决策函数值(比如svm中的决策距离)
- 2——fit(X,Y):在数据集(X,Y)上训练模型。
- 3——get_parms():获取模型参数
- 4——predict(X):预测数据集X的结果。
- 5——predict_log_proba(X):预测数据集X的对数概率。
- 6——predict_proba(X):预测数据集X的概率值。
- 7——score(X,Y):输出数据集(X,Y)在模型上的准确率。返回的R方。
- 8——staged_decision_function(X):返回每个基分类器的决策函数值
- 9——staged_predict(X):返回每个基分类器的预测数据集X的结果。
- 10—— staged_predict_proba(X):返回每个基分类器的预测数据集X的概率结果。
- 11——staged_score(X, Y):返回每个基分类器的预测准确率。
分类
from sklearn.ensemble import AdaBoostClassifier,RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline#连续处理操作
from sklearn.preprocessing import StandardScaler#标准化
from sklearn.datasets import make_moons,make_circles,make_classification#数据多样化的建立
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier#需要注意的是版本的对应,这个玩意需要scikit-learn。1.1以上的版本,需要保证python的版本3.9.
from sklearn.naive_bayes import GaussianNB
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
from matplotlib.colors import ListedColormap
from sklearn.inspection import DecisionBoundaryDisplay
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#分类器名称
names = [
'Nearest Neighbors',
'Linear SVM',
'RBF SVN',
'Decision Tree',
'Random Forest',
'Neural Net',
'AdaBoost',
'Native Bayes',
]
#分类器实例化
classifier = [
KNeighborsClassifier(3),
SVC(kernel='linear',C=0.025),
SVC(gamma=2,C=1),
DecisionTreeClassifier(max_depth=5),
RandomForestClassifier(max_depth=5,n_estimators=10,max_features=1),
MLPClassifier(alpha=1,max_iter=1000),#float,可选,默认为0.0001。L2惩罚(正则化项)参数。
AdaBoostClassifier(),
GaussianNB(),
]
#数据的建立
X,y = make_classification(n_features=2,n_redundant=0,n_informative=2,random_state=1, n_clusters_per_class=1)
rng = np.random.RandomState(2)#设置随机变量,以重复多次实验。
X = X + 2*rng.uniform(size=X.shape)#在原有的数据基础之上加上一些噪音。
linearly_separable = (X,y)
datasets = [
make_moons(noise=0.3,random_state=0),
make_circles(noise=0.2,factor=0.5,random_state=1),
linearly_separable,
]
plt.figure(figsize=(27,9))
i = 1
for ds_cnt,ds in enumerate(datasets):
X,y = ds
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.4,random_state=42)
x_min,x_max = X[:,0].min() - 0.5,X[:,0].max() + 0.5
y_min,y_max = X[:,1].min() - 0.5,X[:,1].max() + 0.5
#just plot the dataset first
cm = plt.cm.RdBu#颜色图
cm_bright = ListedColormap(["#FF0000", "#0000FF"])
ax = plt.subplot(len(datasets),len(classifier)+1,i)
if ds_cnt == 0:
ax.set_title('Input data')
#Plot the training points
ax.scatter(X_train[:,0],X_train[:,1],c=y_train,cmap = cm_bright,edgecolors = 'k')
#Plot the testing points
ax.scatter(X_test[:,0],X_test[:,1],cmap = cm_bright,edgecolors = 'k',c=y_test,alpha=0.6)
ax.set_xlim(x_min,x_max)
ax.set_ylim(y_min,y_max)
ax.set_xticks(())
ax.set_yticks(())
i = i + 1
#iterate over classifier
for name,clf in zip(names,classifier):
ax = plt.subplot(len(datasets),len(classifier) + 1,i)
clf = make_pipeline(StandardScaler(),clf)
clf.fit(X_train,y_train)
score = clf.score(X_test,y_test)
DecisionBoundaryDisplay.from_estimator(
clf, X, cmap=cm, alpha=0.8, ax=ax, eps=0.5
)
#Plot the training points
ax.scatter(X_train[:,0],X_train[:,1],c=y_train,cmap=cm_bright,edgecolors='k')
#Plot the testing points
ax.scatter(X_test[:,0],X_test[:,1],c=y_test,cmap=cm_bright,edgecolors='k',alpha=0.6)
ax.set_xlim(x_min,x_max)
ax.set_ylim(y_min,y_max)
ax.set_xticks(())
ax.set_yticks(())
if ds_cnt == 0:
ax.set_title(name)
ax.text(x_max - 0.3,y_min + 0.3,('%.2f' % score).lstrip('0'),size=15,horizontalalignment='right')
i = i + 1
plt.tight_layout()
plt.show()
回归
import numpy as np
from sklearn.ensemble import AdaBoostRegressor
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
import seaborn as sns
rng = np.random.RandomState(1)
X = np.linspace(0,6,100).reshape(100,-1)
y = np.sin(X).ravel() + np.sin(6 * X).ravel() + rng.normal(0,0.1,X.shape[0])
regr_1 = DecisionTreeRegressor(max_depth=4)
regr_2 = AdaBoostRegressor(DecisionTreeRegressor(max_depth=4),n_estimators=300,random_state=rng)
regr_1.fit(X, y)
regr_2.fit(X, y)
y_1 = regr_1.predict(X)
y_2 = regr_2.predict(X)
colors = sns.color_palette('colorblind')
plt.figure()
plt.scatter(X,y,color=colors[0],label = 'trainning samples')#原始数据显示散点图
plt.plot(X,y_1,color = colors[1], label="n_estimators=300", linewidth=2)
plt.plot(X,y_2,color = colors[2], label="n_estimators=300", linewidth=2)
plt.xlabel('data')
plt.ylabel('target')
plt.title("Boosted Decision Tree Regression")
plt.legend()
plt.show()
4.3.2.GBDT(Gradient Boosting Decision Tree)梯度提升树
Ⅰ.概念
GBDT(Gradient Boosting Decision Tree)是由决策树(Decision Tree)构成的,所有决策树(Decision Tree)的结果累加起来就是GBDT(Gradient Boosting Decision Tree)的最终结果。无论是处理回归问题还是二分类以及多分类,GBDT使用的决策树通通都是都是CART回归树。目前GBDT的算法比较好的库是xgboost。当然scikit-learn也可以。
这里的“梯度”和“提升”没有直接关系:“梯度”被用来让损失函数快速下降,进而让模型效果“提升”。
优点总结
- 1——可以灵活处理各种类型的数据,包括连续值和离散值。
- 2——在相对少的调参时间情况下,预测的准确率也可以比较高。这个是相对SVM来说的。
- 3——二分类器时,构造简单
- 4——不容易发生过拟合
缺点总结 - 1——由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行。
Ⅱ.理论总结
暂时省略。。。。
Ⅲ.代码练习sklearn
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, ensemble
from sklearn.inspection import permutation_importance#特征重要性排列顺序
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
diabetes = datasets.load_diabetes()
X, y = diabetes.data, diabetes.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.1, random_state=13
)
params = {
"n_estimators": 500,
"max_depth": 4,
"min_samples_split": 5,
"learning_rate": 0.01,
#"loss": "squared_error",
}
reg = ensemble.GradientBoostingRegressor(**params)
reg.fit(X_train, y_train)
mse = mean_squared_error(y_test, reg.predict(X_test))
print("The mean squared error (MSE) on test set: {:.4f}".format(mse))
test_score = np.zeros((params["n_estimators"],), dtype=np.float64)
for i,y_pred in enumerate(reg.staged_predict(X_test)):#返回每个基分类器的预测数据集X的结果。
test_score[i] = mean_squared_error(y_test,y_pred)
fig = plt.figure(figsize=(6,6))
plt.subplot(1,1,1)
plt.title('Deviance')
plt.plot(np.arange(params['n_estimators']) + 1,reg.train_score_,'b-',label='Training Set Deviance')
plt.plot(np.arange(params['n_estimators']) + 1,test_score,'r-',label = 'Test Set Deviance')
plt.legend(loc='upper right')
plt.xlabel('Boosting Iterations')
plt.ylabel('Deviance')
plt.tight_layout()
plt.show()
feature_importance = reg.feature_importances_
sorted_idx = np.argsort(feature_importance)#返回的是索引列表
pos = np.arange(sorted_idx.shape[0]) + 0.5
fig = plt.figure(figsize=(12,6))
plt.subplot(1,2,1)
plt.barh(pos,feature_importance[sorted_idx],align='center')
plt.yticks(pos,np.array(diabetes.feature_names)[sorted_idx])
plt.title('Feature Importance (MDI)')
#n_repeats=10:排列特征的次数。置换特征的次数。个人理解可能是交换计算特征重要性的次数。
result = permutation_importance(reg, X_test, y_test, n_repeats=10, random_state=42, n_jobs=2)
sorted_idx = result.importances_mean.argsort()#获得到特征影响因素最大的下表索引,
abc = result.importances[sorted_idx].T
plt.subplot(1,2,2)
plt.boxplot(result.importances[sorted_idx].T,vert=False,labels=np.array(diabetes.feature_names)[sorted_idx])
plt.title('Permutation Importance (test set)')
plt.tight_layout()
plt.show()
print()
4.3.3.XGBoost
Ⅰ.概念
XGBoost(Extreme Gradient Boosting),即一种高效的梯度提升决策树算法。他在原有的GBDT基础上进行了改进,使得模型效果得到大大提升。作为一种前向加法模型,他的核心是采用集成思想——Boosting思想,将多个弱学习器通过一定的方法整合为一个强学习器。即用多棵树共同决策,并且用每棵树的结果都是目标值与之前所有树的预测结果之差 并将所有的结果累加即得到最终的结果,以此达到整个模型效果的提升。
XGBoost是由多棵CART(Classification And Regression Tree),即分类回归树组成,因此他可以处理分类回归等问题。
在数据科学方面,有大量的Kaggle选手选用XGBoost进行数据挖掘比赛,是各大数据科学比赛的必杀武器;在工业界大规模数据方面,XGBoost的分布式版本有广泛的可移植性,支持在Kubernetes、Hadoop、SGE、MPI、 Dask等各个分布式环境上运行,使得它可以很好地解决工业界大规模数据的问题。
Ⅱ.理论总结
暂时省略
Ⅲ.代码练习sklearn
代码在另一个文件当中存放.
4.3.4.LightGBM
Ⅰ.概念
GBDT在工业界应用广泛,通常被用于点击率预测,搜索排序等任务。LightGBM (Light Gradient Boosting Machine)是一个实现GBDT算法的框架,支持高效率的并行训练。
优点总结
- 1——更快的训练速度。
- 2——更低的内存消耗。
- 3——更好的准确率。
- 4——分布式支持,可以快速处理海量的数据。
缺点总结 - 1——由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行。
Ⅱ.理论总结
Ⅲ.代码练习sklearn
1.3Stacking(模型融合)
1.3.1概念
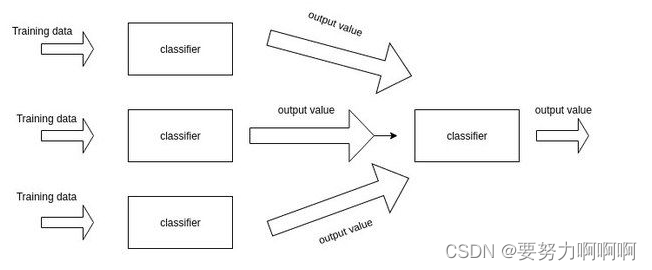
在stacking方法中,我们把个体学习器叫做初级学习器,用于结合的学习器叫做次级学习器或元学习器(meta-learner),次级学习器用于训练的数据叫做次级训练集。次级训练集是在训练集上用初级学习器得到的。
参考连接:
- 1——集成学习(Ensemble Learning)
- 2——集成学习(Ensemble Learning)简单入门
- 3——统计学总结之Bias(偏差),Error(误差),和Variance(方差)的区别
- 4——集成学习全面总结(boosting,bagging,stacking)
- 5——集成学习原理小结
- 6——Sklearn参数详解—Adaboost
- 7——集成学习-stacking算法