目录
1、从本质理解服务治理思想
2、为什么选择Spring Cloud服务治理组件
3、Spring Cloud Eureka服务发现
3.1 Eureka的优势
3.2 Eureka架构组成
3.3 搭建Eureka Server 实战
3.3.1 添加依赖
3.3.2 开启服务注册
3.3.3 添加YML配置
3.3.4 访问服务
3.4 搭建Eureka Client实战
3.4.1 添加依赖
3.4.2 开启服务注册
3.4.3 添加YML配置
3.4.4 访问服务
4、什么是自我保护模式
4.1 自我保护原理
4.2 自我保护触发条件
4.2.1 触发条件
4.2.2 Renews threshold
4.2.3 Renews
4.2.4 如何解决
1、从本质理解服务治理思想
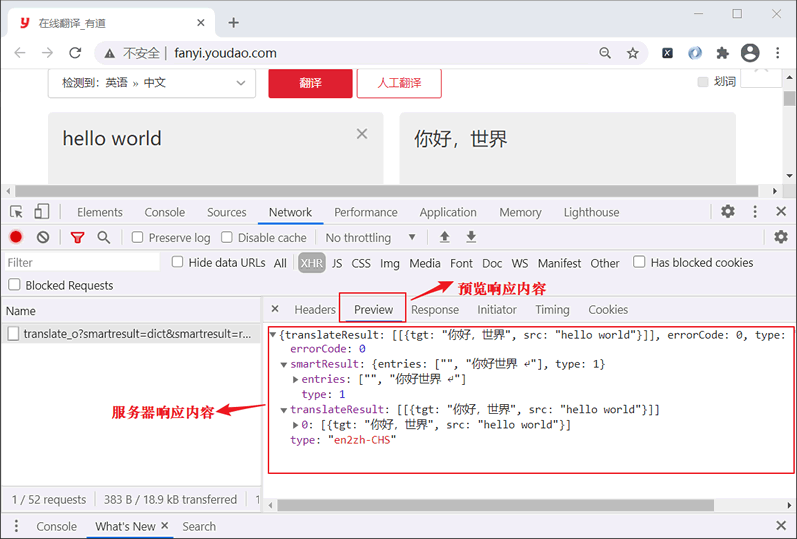
我们经常听到的一个词就是“服务治理”。很多文章似乎竭力用技术层面的架构在解释什么是服务治理。很少有人能用通俗易懂的语言来阐述。今天老王试着从通俗易懂角度给大家解释一下。
那怎么理解“服务治理”呢?
首先,要理解什么是“服务”。服务源于应用,而又高于应用。什么意思呢?
从字面意思理解,服务就是一个一个应用。但与“治理”建立联系后,那就上升到了服务与服务之间的通讯,交互,监控等管理。所以,服务治理,更多的是从服务和服务之间的可能存在什么问题,而服务治理就是需要去解决这个问题。如果是以前传统单体应用,也就不存这个问题。而当下分布式系统盛行,所以,我们需要各种组件来保障分布式系统之间能保持高稳定、高可用性等。
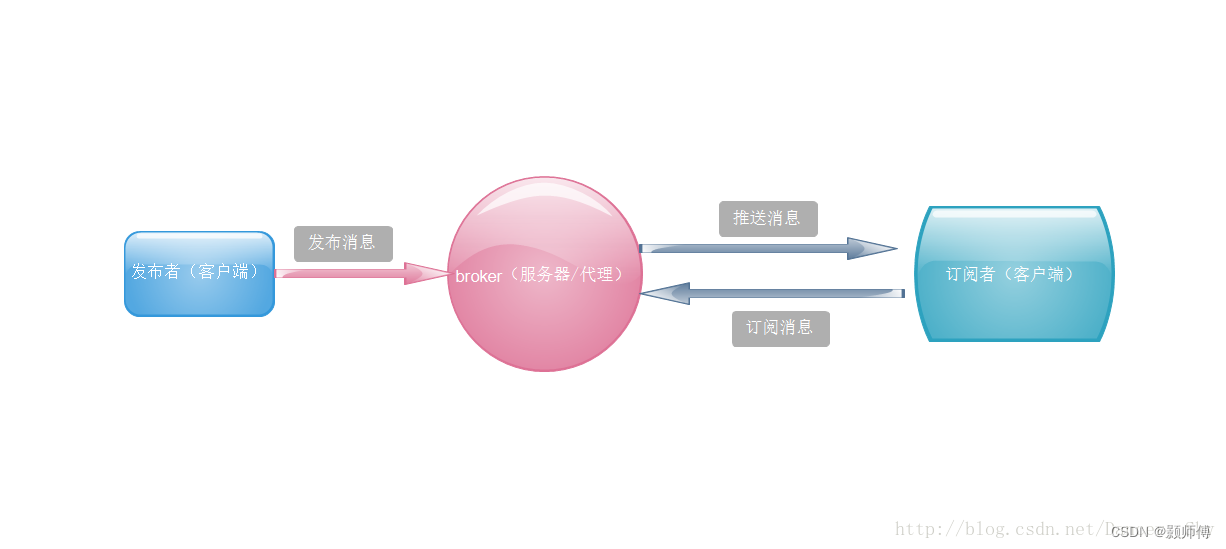
基于这样的目的,也就有了像Eureka、Consul和Zookeeper这类中间件的出现。
2、为什么选择Spring Cloud服务治理组件
在理解了什么是“服务治理”后,接下来,我们进入今天要讲解的主角:Eureka。
首先,我们要知道为什么选择Spring Cloud的服务治理框架。
前面我们提到,当下基本90%的业务系统属于分布式部署,而分布式系统之间大多都采用RPC(Remote Procedure Call,远程过程调用)的方式通信,那在PRC调用过程中,如何解决多样化的服务注册中,来监控服务是否可用,不可用情况下该怎么办?中断业务还是通过其他方式快速恢复业务等等。 那这些问题就需要通过“服务注册与发现”组件来解决。
那在服务注册组件中,我们之所以选择Spring Cloud,主要是由于Spring Cloud为服务治理做了一层抽象接口,所以在Spring Cloud应用,中可以支持多种不同的服务治理框架。
比如:Netflix Eureka、Consul、Zookeeper。在Spring Cloud服务治理抽象层的作用下,我们可以无缝地切换服务治理实现,并且不影响任何其他的服务注册、服务发现、服务调用等逻辑。
3、Spring Cloud Eureka服务发现
Spring Cloud Eureka是Spring Cloud Netflix项目下的服务治理模块。而Spring Cloud Netflix项目是Spring Cloud的子项目之一,主要内容是对Netflix公司一系列开源产品的包装,它为Spring Boot应用提供了自配置的Netflix OSS整合。通过一些简单的注解,开发者就可以快速的在应用中配置一下常用模块并构建庞大的分布式系统。它主要提供的模块包括:服务发现(Eureka),断路器(Hystrix),智能路由(Zuul),客户端负载均衡(Ribbon)等。
那在众多服务发现组件中,我们为什么选择Eureka呢?
3.1 Eureka的优势
1)提供完整的服务注册和服务发现实现机制
首先,Eureka提供了完整的服务注册和服务发现的实现机制,并且也经受住了Netflix自己的生产环境考验,稳定性方面相对使用起来会比较放心。
2)与SpirngCloud无缝集成
我们的项目本身就使用了Spring Cloud和Spring Boot,同时Spring Cloud还有一套非常完善的开源代码来整合Eureka,所以使用起来非常方便。另外,Eureka还支持在我们应用自身的容器中启动,也就是说我们的应用启动完之后,既充当了Eureka的角色,同时也是服务的提供者。这样就极大的提高了服务的可用性。
3)CAP采用AP而非CP
这个是经典的CAP理论。
我们知道,CAP原则指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance),但是CAP 原则指示3个要素最多只能同时实现两点,不可能三者兼顾,由于网络硬件肯定会出现延迟丢包等问题,但是在分布式系统中,我们必须保证部分网络通信问题不会导致整个服务器集群瘫痪,另外即使分成了多个区,当网络故障消除的时候,我们依然可以保证数据一致性,所以我们必须保证分区容错性。
而Eureka,Eureka是Netflix开发的服务发现框架,本身是一个基于REST的服务,主要用于定位运行在AWS域中的中间层服务,以达到负载均衡和中间层服务故障转移的目的。在部署AWS的背景下,其设计者认为,在云端,特别是大规模部署情况下面,失败是不可以避免的,可能是因为Eureka自身部署失败或者网络分区等情况导致服务不可用,这些问题是不可以避免的,要解决这个问题就需要Eureka在网络分区的时候,还能够正常提供服务,因此Eureka选择满足Availability这个特性。
在生产实践中,服务注册及发现中保留可用以及过期的数据总比丢失可用的数据好。因此,
eureka选择了A也就必须放弃C,也就是说在eureka中采用最终一致性的方式来保证数据的一致性问题,因此实例的注册信息在集群的所有节点之间的数据都不是强一性的,需要客户端能支持负载均衡算法及失败重试等机制。(这也是Eureka被病垢的主要原因,但优点多余缺点,可以通过重试等补偿机制来完善。)
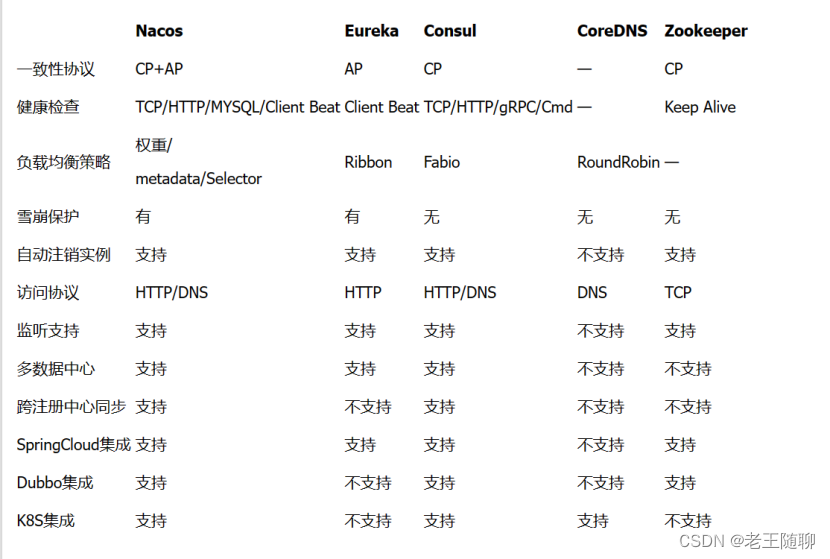
综上,我们可以看到,每个注册中心组件都有其优缺点。我们在实际开发过程当中需要结合实际情况来做技术选型。
4)组件开源
代码是开源的,而且也是由Java语言开发。所以非常便于我们了解它的实现原理和排查问题。需要的话还可以在上面进行二次开发。
3.2 Eureka架构组成
Eureka主要包含Eureka Server和 Eureka Client两部分。其架构设计图如下,
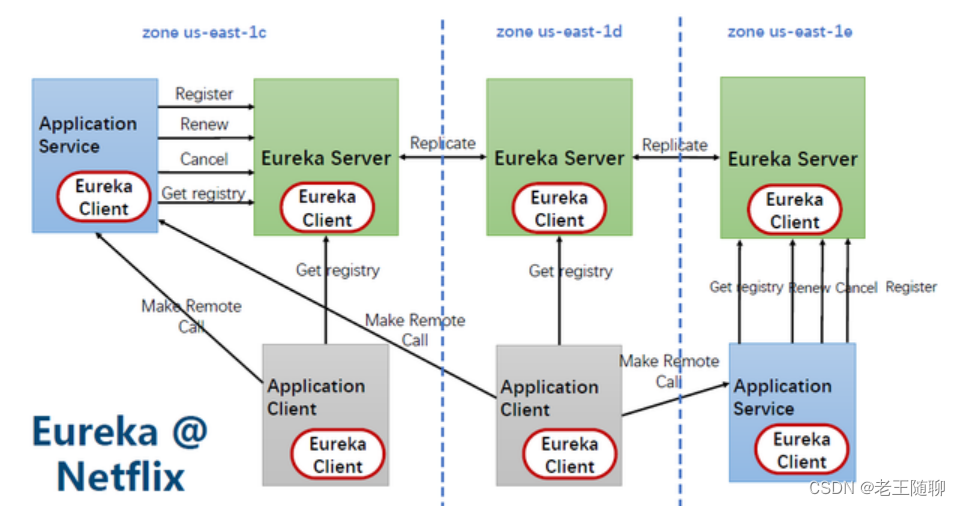
其中,Eureka Server提供服务注册服务,各个节点启动后,会在Eureka Server中进行注册,这样EurekaServer中的服务注册表中将会存储所有可用服务节点的信息,服务节点的信息可以在界面中直观的看到。
而Eureka Client是一个java客户端,用于简化与Eureka Server的交互,客户端同时也就是一个内置的、使用轮询(round-robin)负载算法的负载均衡器。
在应用启动后,将会向Eureka Server发送心跳,默认周期为30秒,如果Eureka Server在多个心跳周期内没有接收到某个节点的心跳,Eureka Server将会从服务注册表中把这个服务节点移除(默认90秒)。
Eureka Server之间通过复制的方式完成数据的同步,Eureka还提供了客户端缓存机制,即使所有的Eureka Server都挂掉,客户端依然可以利用缓存中的信息消费其他服务的API。综上,Eureka通过心跳检查、客户端缓存等机制,确保了系统的高可用性、灵活性和可伸缩性。
Eureka Server 处理过程:
Eureka Server 也可以运行多个实例来构建集群,解决单点问题,但不同于 ZooKeeper 的选举 leader 的过程,Eureka Server 采用的是Peer to Peer 对等通信。这是一种去中心化的架构,无 master/slave 之分,每一个 Peer 都是对等的。
在这种架构风格中,节点通过彼此互相注册来提高可用性,每个节点需要添加一个或多个有效的 serviceUrl 指向其他节点。每个节点都可被视为其他节点的副本。
在集群环境中如果某台 Eureka Server 宕机,Eureka Client 的请求会自动切换到新的 Eureka Server 节点上,当宕机的服务器重新恢复后,Eureka 会再次将其纳入到服务器集群管理之中。当节点开始接受客户端请求时,所有的操作都会在节点间进行复制(replicate To Peer)操作,将请求复制到该 Eureka Server 当前所知的其它所有节点中。
当一个新的 Eureka Server 节点启动后,会首先尝试从邻近节点获取所有注册列表信息,并完成初始化。Eureka Server 通过 getEurekaServiceUrls() 方法获取所有的节点,并且会通过心跳契约的方式定期更新。
默认情况下,如果 Eureka Server 在一定时间内没有接收到某个服务实例的心跳(默认周期为30秒),Eureka Server 将会注销该实例(默认为90秒, eureka.instance.lease-expiration-duration-in-seconds 进行自定义配置)。
当 Eureka Server 节点在短时间内丢失过多的心跳时,那么这个节点就会进入自我保护模式。
Eureka的集群中,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。除此之外,Eureka还有一种自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
Eureka不再从注册表中移除因为长时间没有收到心跳而过期的服务;
Eureka仍然能够接受新服务注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用);
当网络稳定时,当前实例新注册的信息会被同步到其它节点中;
因此,Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使得整个注册服务瘫痪。
3.3 搭建Eureka Server 实战
说明:实战部分可以接着我们昨天讲的例子来继续编写。我这里为了在代码结构上能更加清晰,将Eureka Server和Eureka Client拆分成了两个独立的module。
如下图,
在前一篇文章中,我们其实已经讲解了Eureka Server的搭建。这里就不再赘述,。直接上配置和代码(基于springcloud-eureka-server这个module)。
3.3.1 添加依赖
在项目 springcloud-eureka-server pom.xml文件中引入需要的依赖内容:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka-server</artifactId>
</dependency>3.3.2 开启服务注册
通过 @EnableEurekaServer 注解启动一个服务注册中心提供给其他应用进行对话,这个注解需要在springboot工程的启动SpringCloudEurekaServerApp类上加。代码如下,
package com.xintu.springcloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaServer //表示可以将项目作为SpringCloud中的注册中心。用于激活Eureka服务器相关配置EurekaServerAutoConfiguration的注释。
public class SpringCloudEurekaServerApp {
public static void main(String[] args) {
SpringApplication.run(SpringCloudEurekaServerApp.class, args);
}
}3.3.3 添加YML配置
在默认设置下,该服务注册中心也会将自己作为客户端来尝试注册它自己,所以我们需要禁用它的客户端注册行为,只需要在application.yml配置文件中增加如下信息:
#指定应用名称
spring:
application:
name: eureka-server
# 服务注册中心 (单节点)
server:
port: 8700
eureka:
instance:
hostname: localhost
client:
fetch-registry: false # 表示是否从Eureka Server获取注册信息,默认为true.因为这是一个单点的Eureka Server,不需要同步其他的Eureka Server节点的数据,这里设置为false
register-with-eureka: false # 表示是否将自己注册到Eureka Server,默认为true.由于当前应用就是Eureka Server,故而设置为false.
service-url:
# 设置与Eureka Server的地址,查询服务和注册服务都需要依赖这个地址.默认是http://localhost:8761/eureka/;多个地址可使用','风格.
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/3.3.4 访问服务
启动工程后,访问:http://localhost:8700/。可以看到下面的页面,其中还没有发现任何服务。
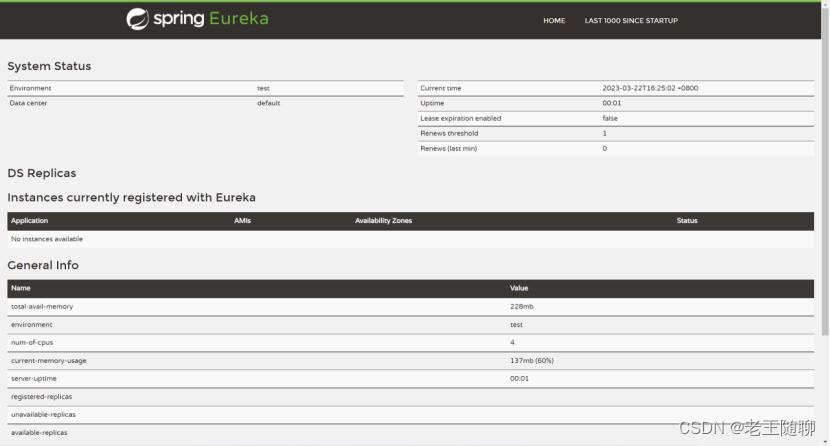
至此,Eureka Serve实战案例搭建完成。
3.4 搭建Eureka Client实战
Eureka Client也称为服务提供方,将自身服务注册到 Eureka 注册中心,从而使服务消费方能够找到。
3.4.1 添加依赖
在项目 spring-cloud-eureka-provider pom.xml中引入需要的依赖内容:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>3.4.2 开启服务注册
在应用启动SpringCloudEurekaClientApp中通过加上 @EnableEurekaClient,但只有Eureka 可用,你也可以使用@EnableDiscoveryClient。需要配置才能找到Eureka注册中心服务器。
package com.xintu.springcloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@SpringBootApplication
@EnableDiscoveryClient//代表自己是一个服务提供方
public class SpringCloudEurekaClientApp {
public static void main(String[] args) {
SpringApplication.run(SpringCloudEurekaClientApp.class, args);
}
}3.4.3 添加YML配置
需要配置才能找到Eureka服务器。配置如下,
#指定应用名称
spring:
application:
name: eureka-client
server:
port: 8701 # 服务提供方
# 指定当前eureka客户端的注册地址,
eureka:
instance:
hostname: localhost
client:
service-url:
defaultZone: http://${eureka.instance.hostname}:8700/eureka其中defaultZone是一个魔术字符串后备值,为任何不表示首选项的客户端提供服务URL(即它是有用的默认值)。 通过spring.application.name属性,我们可以指定微服务的名称后续在调用的时候只需要使用该名称就可以进行服务的访问。
3.4.4 访问服务
启动该工程后,再次访问启动工程后:http://localhost:8700/。可以如下图内容,我们定义的服务被成功注册了。
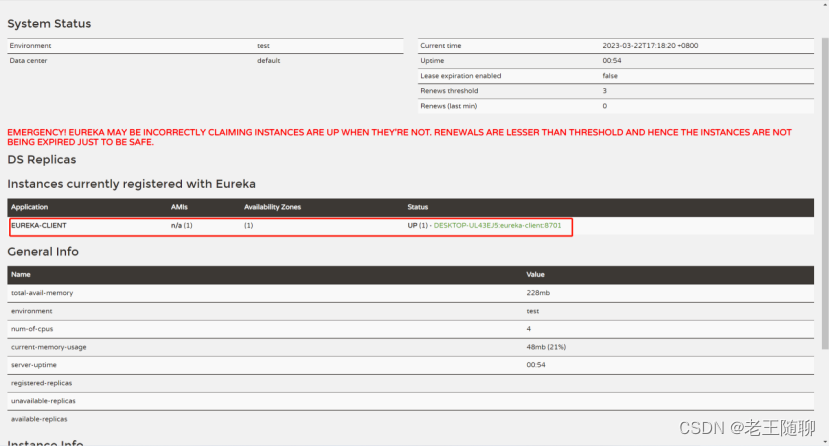
至此,Eureka Serve实战案例搭建完成。
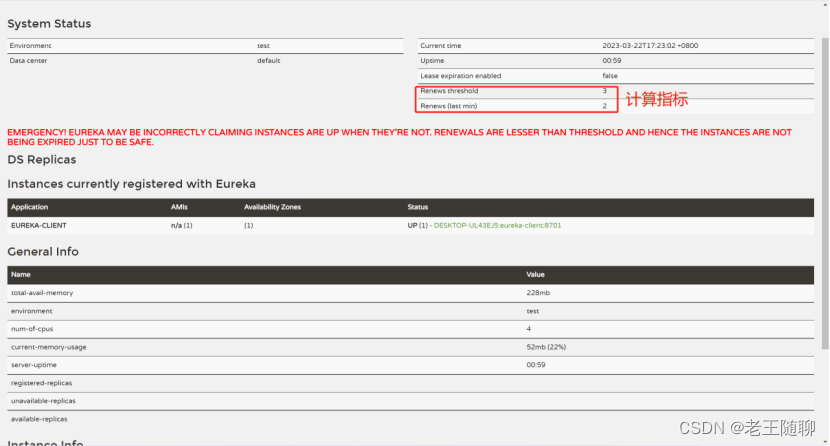
上面一行红色粗体内容引起我们的注意。
EMERGENCY! EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY'RE NOT. RENEWALS ARE LESSER THAN THRESHOLD AND HENCE THE INSTANCES ARE NOT BEING EXPIRED JUST TO BE SAFE.
意思:紧急!Eureka已经不能确认这些已经启动的实例是否可用,由于最近的续订次数小于续订阈值(续订期望值),为了安全起见(实例可用),当前这些实例不会删除。
这是为什么呢?
出现上面这种情况,其实是Eureka进入自我保护模式(SELF PRESERVATION MODE)。
4、什么是自我保护模式
4.1 自我保护原理
我们知道,当微服务客户端启动后,会把自身信息注册到Eureka注册中心,以供其他微服务进行调用。一般情况下,当某个服务不可用时(一段时间内没有检测到心跳或者连接超时等),那么Eureka注册中心就会将该服务从可用服务列表中剔除,但是在微服务架构中,因为服务数量众多,可能存在跨机房或者跨区域的情况,因此当某个服务心跳探测失败并不能完全说明其无法正常提供服务而将其剔除,并且服务一旦剔除后,再重新注册将会重新进行负载均衡等等一系列的操作,考虑到性能问题,eureka会将不可用的服务暂时断开,并期望能够在接下来一段时间内接收到心跳信号,而不是直接剔除,同时,新来的请求将不会分发给暂停服务的实例,这就是eureka的保护机制,它保护了因网络等问题造成的短暂的服务不可用的实例,避免频繁注册服务对整个系统造成影响。
4.2 自我保护触发条件
4.2.1 触发条件
进入自我保护模式的条件:如果最近一分钟实际接收到的心跳值Renews除以期望的心跳阈值 Renews threshold小于等于0.85,即 Renews/Renews threshold≤0.85。
我们这里 Renews/Renews = 2/3 = 0.7 ≤ 0.85,所以触发了以上自我保护提示提示。
下面我们来看下触发自我保护的具体的计算参数含义以及计算逻辑。
4.2.2 Renews threshold
Renews threshold:Eureka注册中心期望接收到的心跳值,计算方法:
服务注册中心不注册自己: (1+2*n)
服务注册中心注册自己: (1+2*(n+1)) 。
参数解析:
1) 数字1
这个是Eureka框架代码里面写时的最低阈值1,意味着没有任何客户端注册,阈值也有1。
2) 数字2
这个是最近一分钟接收到的心跳次数,Eureka客户端和注册中心心跳检测默认是30s一次,那么一分钟就是2次,可以通过下面的参数进行调整。
#定义每分钟发送到服务器的更新数 default is 30 也就是每30秒续订一次
eureka.instance.leaseRenewalIntervalInSeconds=30
3) 数字n
这个是客户端的数量个数,如果注册中心自己不注册,那么有几个客户端,n就是几,如果注册中心自己也要注册,那么就需要把注册中心也加上,这是因为在实际生产环境中,为了保证注册中心的高可用,往往注册中心会搭建集群,那么注册中心A,B,C相互之间也会注册,所以就相当于一个客户端。是否注册可以通过下面的代码进行设置。
#是否在Eureka Server中注册默认是true
eureka.client.registerWithEureka=false
4.2.3 Renews
Renews :注册中心实际接收到的心跳值,计算方法:
服务注册中心不注册自己: 2*n
服务注册中心注册自己: 2*(n+1)
参数解析:
1) 数字2
这个是最近一分钟接收到的心跳次数,Eureka客户端和注册中心心跳检测默认是30s一次,那么一分钟就是2次,可以通过下面的参数进行调整(设置代码同上)
2) 数字n
这个是客户端的数量个数,如果注册中心自己不注册,那么有几个客户端,n就是几,如果注册中心自己也要注册,那么就需要把注册中心也加上,这是因为在实际生产环境中,为了保证注册中心的高可用,往往注册中心会搭建集群,那么注册中心A,B,C相互之间也会注册,所以就相当于一个客户端。是否注册可以通过下面的代码进行设置(设置代码同上)。
3)0.85
0.85,这个参数是Eureka默认的一个比值参数,代表eureka-server最后一分钟收到的心跳次数小于等于总心跳次数的85%,可通过下面的代码进行调整
eureka.server.renewalPercentThreshold=0.85
4.2.4 如何解决
1)生成环境
在生产上可以开自注册,部署两个server 。
2)本地调试
在本机器上测试的时候,可以把比值调低,比如0.49。
eureka.server.renewalPercentThreshold=0.49
1)关闭自我保护
# 默认值是true
eureka.server.enable-self-preservation=false。
说明:如果关闭自我保护模式。 在网络/其他问题的情况下,这可能无法保护实例到期,可能提供不可用的服务给客户端调用。
以上!