摘要:本文整理自科杰科技大数据架构师张军,在 FFA 2022 数据集成专场的分享。本篇内容主要分为四个部分:
功能概述
架构设计
技术挑战
生产实践
Tips:点击「阅读原文」查看原文视频&演讲 ppt
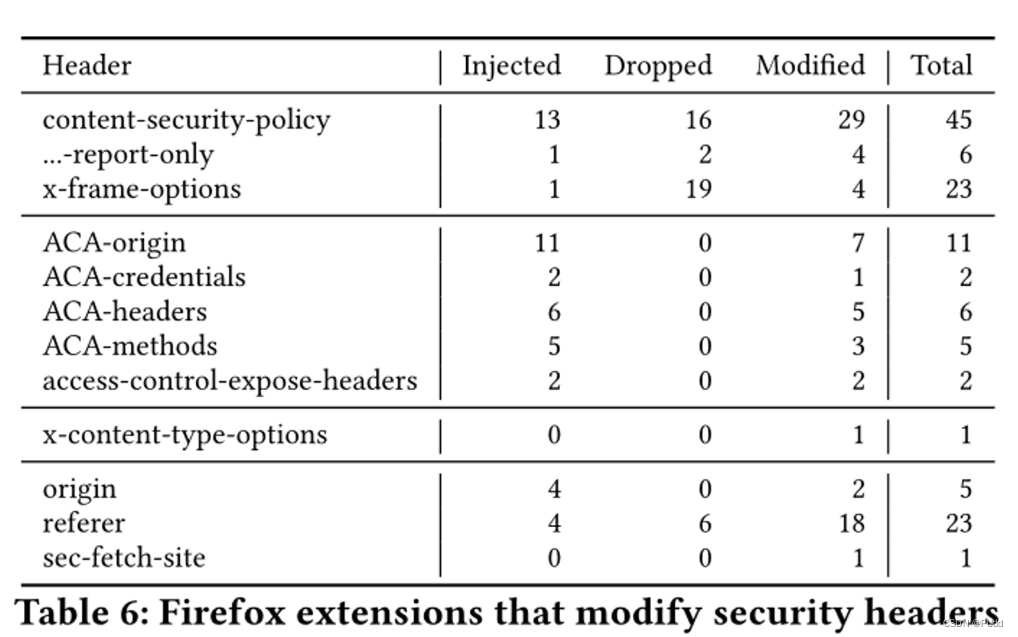
科杰科技是专门做大数据服务的供应商,目前的客户包括能源、金融、证券等各个行业。科杰科技产品的底层是基于湖仓一体的基础数据平台,在数据平台之上有离线、实时、机器学习等各种系统。我主要负责基于 Flink、Iceberg、K8s 的底层基础设施建设。今天将主要和大家分享,上图中框出来的子系统,即基于 Flink CDC 的实时数据同步系统。
01
功能概述

我们系统的主要的功能有如下几个:
1. 可视化操作。我们做了后台的管理系统,是希望用户在不懂任何代码的情况下,通过点击鼠标就能配置出同步任务做数据同步。
2. 支持整库同步、多表同步。
3. DDL 支持:源端的 Schema 的变更也要同步到目标端。
4. 数据库、表、字段映射。
5. 丰富的数据源支持。目前输入端支持四种常见的关系型数据库,MySQL、Postgre、SQL Server、Oracle,输出端除了这四个数据库之外,还包含 Kafka 和 Iceberg。
6. 丰富的数据类型支持。对输入端的四种关系型数据库,我们常用的所有数据类型都会支持,包括二进制类型。
7. UDF 函数、过滤条件。UDF 函数是指我们在同步过程中,做一些数据转换。过滤条件是指我们会在同步的过程中,加一些过滤条件,只同步想要的数据。
8. 选取字段、添加变量字段。选取字段是指用户可以选择想要的字段进行同步。添加变量是指在同步的过程中,可以手工添加一些字段,比如时间戳或者表名等。
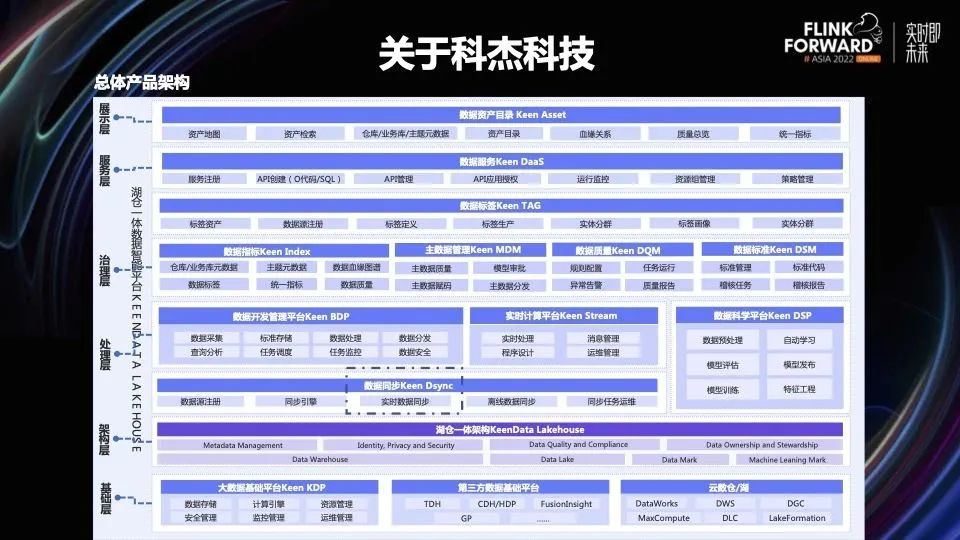
市面上有很多实时同步的系统,最终我们选用了 Flink CDC 做实时同步系统的底层技术架构。主要是因为 Flink CDC 有一些独有的优势,包括全量同步、增量同步、全量+增量同步,还有底层基于 Flink 做的分布式计算引擎。
通过 Flink CDC 这套架构,想实现我们现有产品的需求,目前来看还有一些不足。
1. DDL 的支持:PostgreSQL、Oracle 数据库无法获取 Schema 变更的事件,无法捕获相应的 DDL 操作。
2. 整库同步:通过 Flink CDC 的 API 可以捕获表结构的变更信息,但是现有的 Flink Connector 无法将新增的表、字段写入目标端。
3. 需要预知 Schema:Flink 任务需要提前知道表结构的 Schema,然后构建任务,无法实现不重启的情况下动态处理新增表或者字段。
02
架构设计
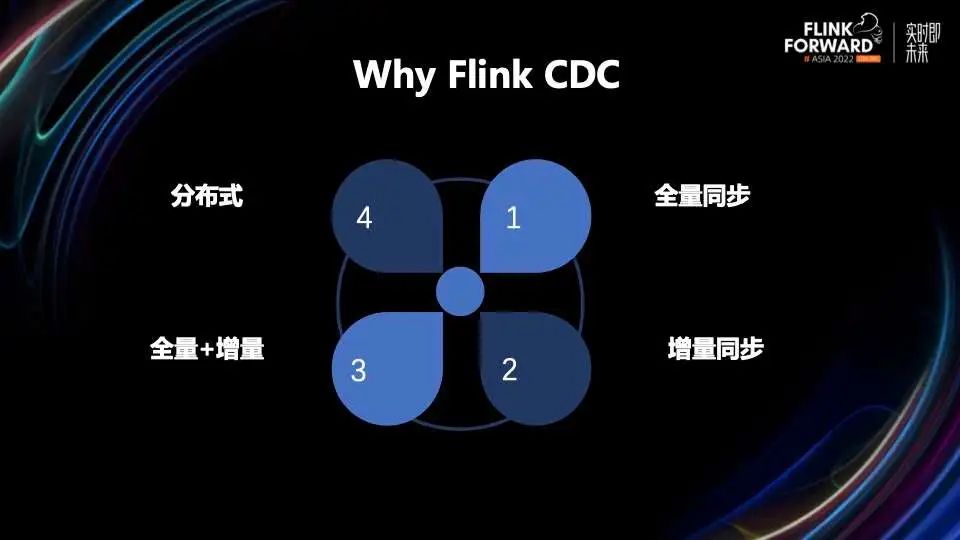
接下来从技术角度给大家分享一下我们系统的设计架构,从上图中可以看到,一共分为三层。
最上面一层是输入端。基于 Flink CDC API 的方式读数据库进行数据抽取,然后把这些数据和 Schema 的信息发到中间的 Kafka,Kafka 是我们的中间缓冲层。最下面一层是输出端,会从 Kafka 读取输入端输入的数据。
在输出端这一层可以看到,首先进行过滤,常用的 SQL 表达式都可以做过滤条件。过滤后对字段应用一些 UDF,比如数据脱敏、加密等等。接下来根据 DB 和 Table 对数据进行 Keyby 分组,然后使用 KeyedProcessFunction 函数对每个表的数据进行一些处理,比如创建表、添加或者修改字段、插入数据等等。
当配置完任务之后,最后我们分别把 Source 和 Sink 的任务提交到运维中心,运维中心会对任务进行启动、停止、查看统计指标、查看任务状态等一系列操作。最后我们的任务支持在 Yarn 和 K8s 上运行,用户可以根据自己的情况进行选择。
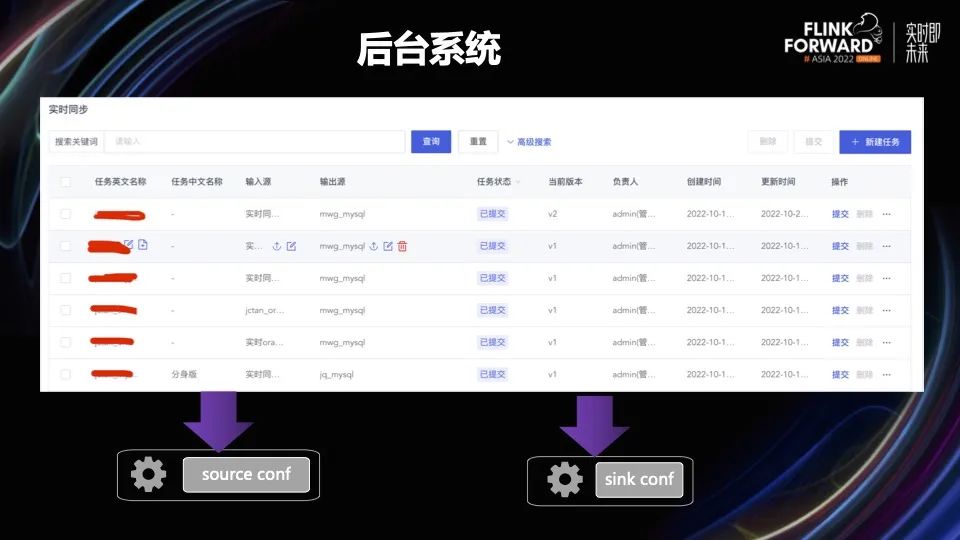
在后台管理系统,用户可以通过配置输入端和输出端,配置需要同步的任务。任务会生成两个配置文件,分别是输入端的配置文件和输出端的配置文件,然后这两个配置文件会分别作为输入端和输出端的启动参数传给两个 Flink 任务。
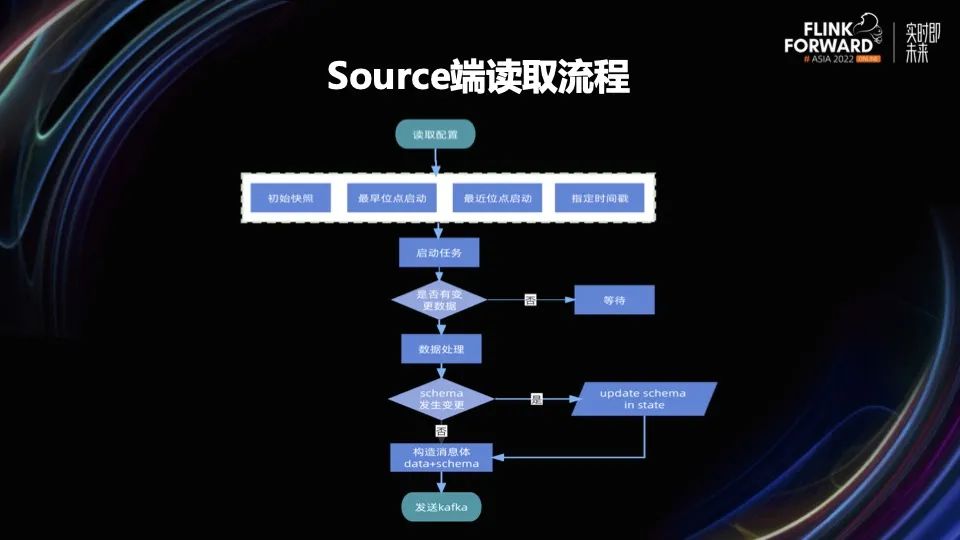
这部分主要是想分享下,对于无法获取 DDL 事件的情况我们该如何处理呢?
其实有一些数据库,比如 MySQL,是可以通过 Flink CDC 来获取 Schema 的变更信息的,但是为了代码的逻辑统一,同时适配 Flink CDC 拿不到 Schema 变更的数据库。我们做了代码统一的处理,用一套架构完成数据和 Schema 的抽取和封装。
我们通过 JDBC 的方式,从源数据库把 Schema 的信息查出来,放到 Flink 的 State 里。当下一条数据来的时候,跟 State 里面的 Schema 数据进行对比。相同就不做任何处理,不同就再次查询一下 Schema 的信息,更新到 Flink State 里。同时将从 Flink CDC 拿到的数据和这条数据对应的 Schema 信息,封装成消息体,发送给中间层的 Kafka。从 Schema 读取的信息包含数据的类型、长度、精度,是否是主键等等,格式和 debezium-json 差不多。
Kafka 缓冲层可以用来实现以下几个功能。
在解耦方面:将 Source 和 Sink 解耦; 多个输出端避免重复抽取。比如我想从 MySQL 抽取一些数据,把它同步到 Iceberg 做一些离线的分析。同时又同步到 Kafka,做一些实时的数据处理。这种情况就可以从源端只抽取一次,减少对源端数据库的压力;Sink 出现故障避免 Source 阻塞,类似 flume 的 channel 的功能。
在 DB 对应 Topic 方面:一个数据库里面的数据抽取到一个 Topic;每个 Topic 一个 Partition;单表重放顺序有保证。
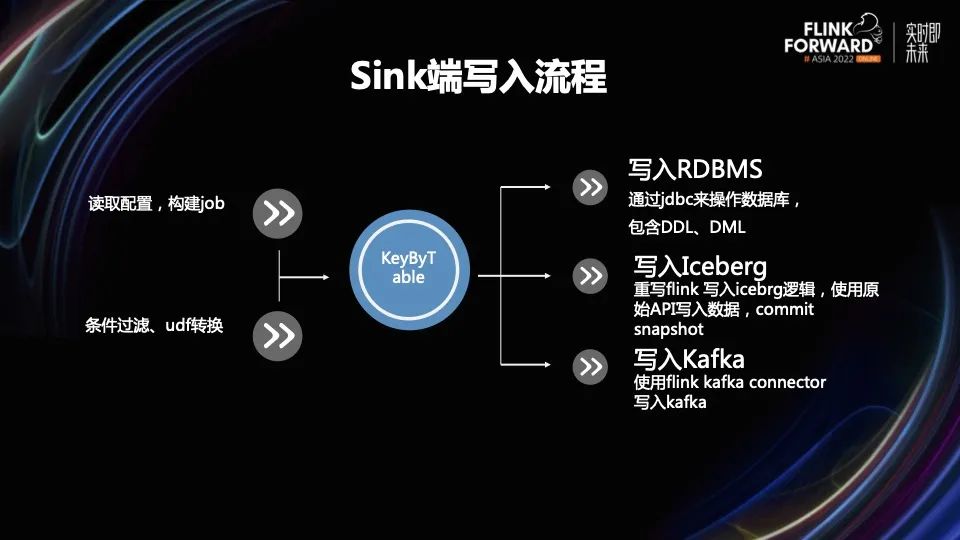
输出端和输入端一样,读取后端生成的配置文件作为它的参数,然后使用一些过滤条件,UDF 转换条件等等,从 Kafka 读取数据,进行数据处理。
在数据处理的时候,因为每个输出源的处理逻辑不一样,所以分成以下三类。
1. 写入 RDBMS。通过 JDBC 来操作数据库,包含 DDL、DML。
2. 写入 Iceberg。重写 Flink 写入 Icebrg 逻辑,使用原始 API 写入数据,Commit Snapshot。
3. 写入 Kafka。使用 Flink Kafka Connector 写入 Kafka。
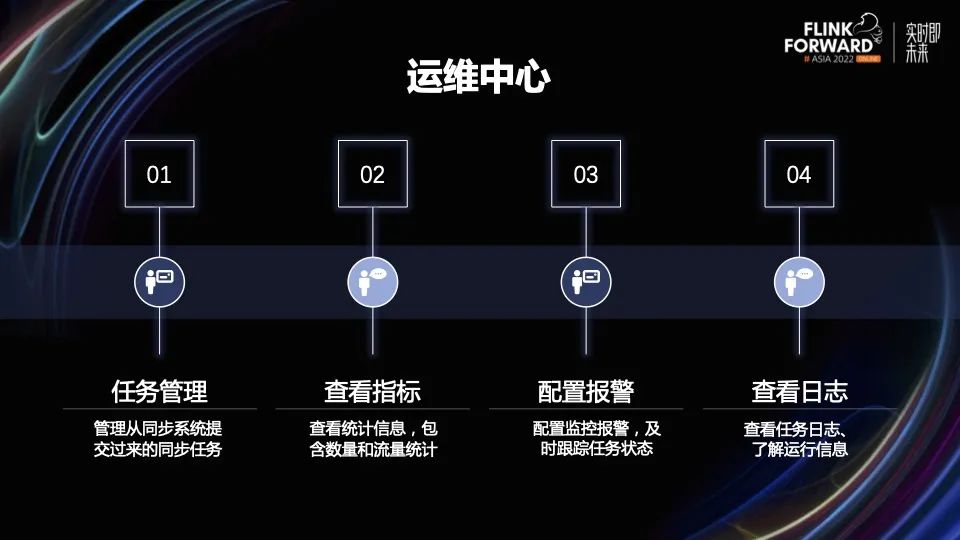
运维中心可以对数据进行如下处理:
1. 任务的管理:包含任务的启动、停止、暂停等等。
2. 查看指标:监控一些数据,包含同步任务的数据条数和数据大小。
3. 配置监控报警:同步任务发生故障时,发送报警,包括邮件、短信等等。
4. 查看日志:查看任务启动的日志、任务运行过程中的日志。
03
技术挑战
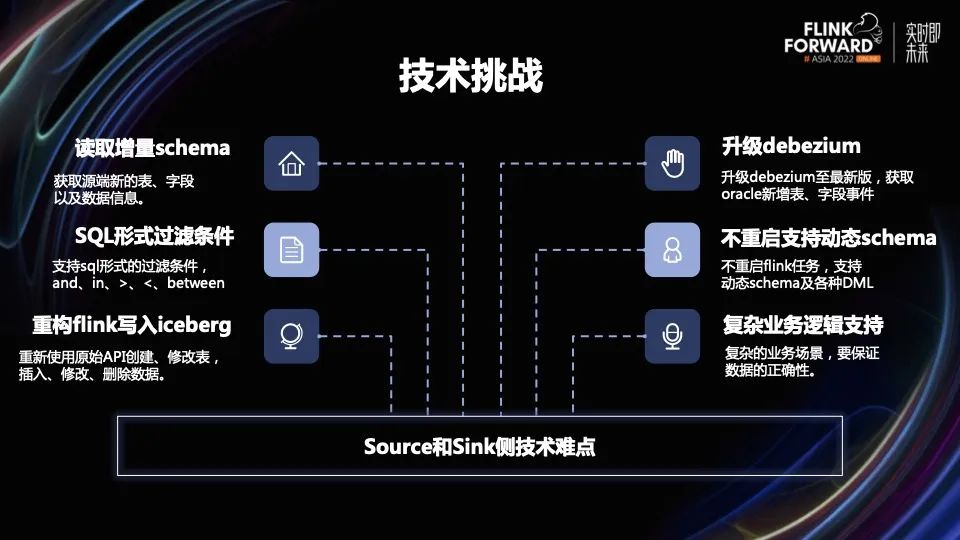
下面列举一些主要的技术挑战。
1. 读取增量 Schema:获取源端新增的表、字段以及数据信息(比如 Flink CDC 无法获取 PostgreSQL 数据库的 Schema 变更事件)。
2. 升级 debezium:修改 Flink CDC 源码, 升级 debezium 至最新版,获取 Oracle 新增表、字段事件。
3. SQL 形式过滤条件:支持 SQL 形式的过滤条件,and、or、in、>、<、between 等常用的表达式。
4. 不重启支持动态 Schema:不重启 Flink 任务,支持动态 Schema 及各种 DML 将数据写入目标端。
5. 重构 Flink 写入 Iceberg:没有使用现有的 Flink Datastream API 写入 Iceberg,重新使用 Iceberg 最底层 API 创建、修改表,插入、修改、删除数据。
6. 复杂业务逻辑:支持复杂的业务场景,要保证数据的正确性。

这是我们在开发过程中,输出端遇到的第一个问题,也就是 SQL 条件的过滤。大家可能乍一听觉得很简单,加一个 where 条件就行了,但 Flink 任务在做数据同步时,它要求输入端和输出端的 Schema 需要预先提前知道,且它是固定不变的,但是我们的情况有一些不同,比如对于整库同步的过程中,用户新增了一些表,或者在表同步的过程中,新增了一些字段,Flink 现有的 collector 无法识别这些新增的信息,无法在未知的字段上添加 where 条件。那么我们要如何解决这个问题呢?
我们发送到中间 Kafka 缓冲层的数据格式和 debezium-json 的格式差不多,数据主要存储在 payload.after 和 payload.before 里面,这里面的数据的格式是 map 类型,它的 key 是字符串,value 是 object 类型的数据,但是这个格式我们无法把它映射成 Flink SQL,因为 object 类型在 Flink CDC 里面没有对应的类型,所以我们把 object 类型映射成了 string 类型,并对 SQL 进行了一些转换。使用 Flink SQL 解析器把 where 条件进行解析,然后重新生成新的过滤条件。
比如我们原始的过滤 SQL 是这样的:id between 1 and 3.5
经过我们的重构,变成了下面这个形式:cast(payload.after['id'] as DECIMAL(2,1)) BETWEEN ASYMMETRIC 1 AND 3.5
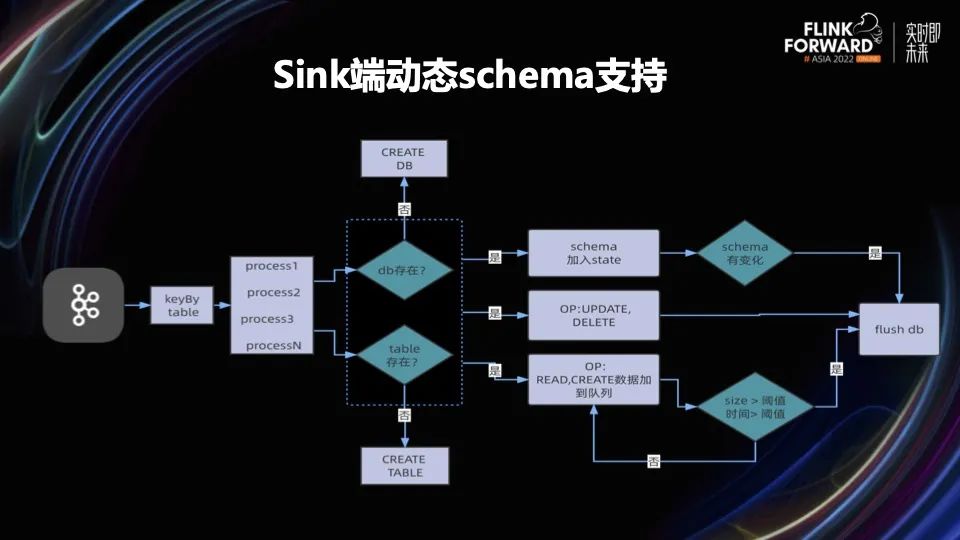
数据经过 where 条件的过滤之后,并且经过 UDF 函数转换进入 KeyedProcessFunction 函数进行处理。第一步先判断输出端的目标库和目标表是否已经存在。在没有存在的情况下,用纯 JDBC 的方式拼接 SQL 执行 DDL,创建数据库和表。然后进行数据处理,为了提高性能。我们把数据放到队列里,当队列达到一定的阈值后,进行 flush 操作,把数据批量写入数据库。
在这个同步过程中,对于 Schema 的处理和 Source 端一样,把获取的 Schema 信息放到 State 里,每来一条数据进行一次 Schema 对比。如果发生了变更,就能证明数据发生了 DDL 的操作。这个时候要刷数据,把队列里的数据 flush 到数据库,然后执行 DDL,执行完 DDL 之后重新拼接一个 INSERT INTO 的 SQL 执行新插入的数据。通过这种方式实现不重启 Flink 任务的情况下,同时支持 DDL(create、alter)和 DML(insert、update、delete)等一系列操作。
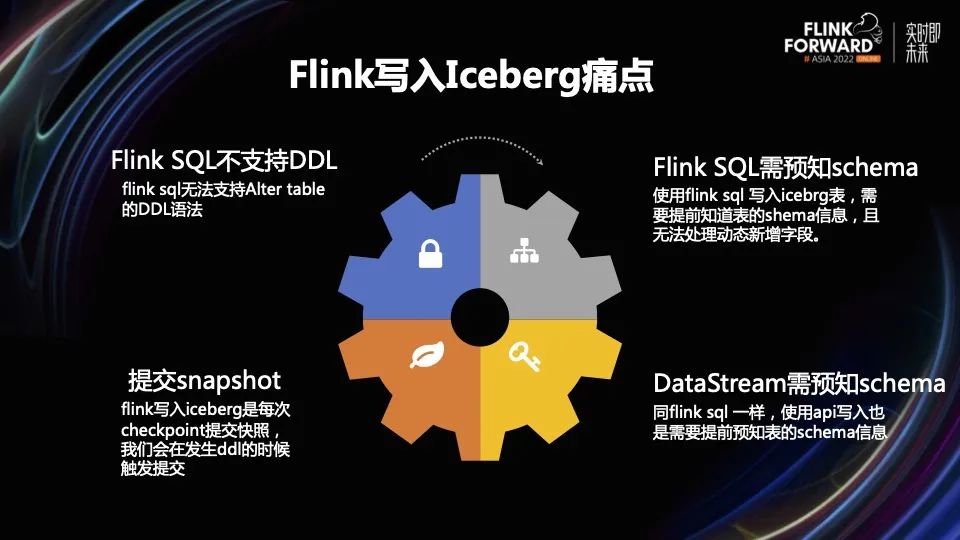
因为 Iceberg 无法用纯 JDBC 的方式写入,所以它无法跟关系型数据结合到一起。因此 Flink 写入 Iceberg 会遇到以下的一些问题。
1. Flink SQL 不支持 DDL。比如 Flink SQL 无法支持 Alter Table 的 DDL 语法。
2. Flink SQL 需预知 Schema。使用 Flink SQL 写入 Iceberg 表,需要提前知道表的 Schema 信息,且无法处理新增字段。
3. DataStream 需预知 Schema。如果使用 API 写入,也会和 Flink SQL 一样遇到同样的问题,写入也是需要提前预知表的 Schema 信息。
4. 提交 Snapshot。Flink 写入 Iceberg 是每次 Checkpoint 提交快照,但是我们需要自己控制,需要在发生 DDL 的时候触发提交。
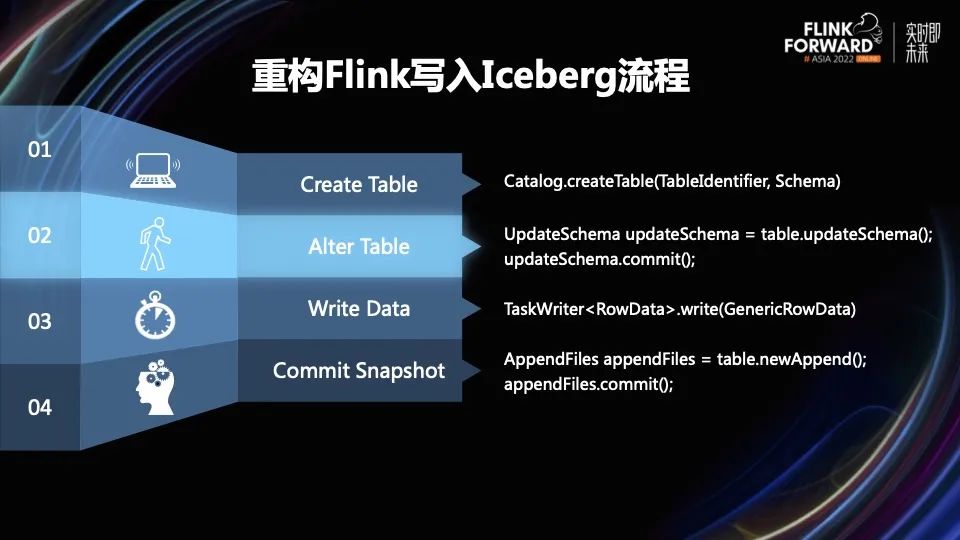
我们发现 Flink 不管用 SQL 还是 API 的方式,都无法完成我们的需求,所以我们从更底层的角度来考虑实现方法,最后使用 Iceberg 很底层的 API 来实现我们所需要的功能。
比如 Create Table 就是使用 Iceberg 里的 Catalog 来创建 Table 的,包含一些主键和 Schema。其他的操作,包括修改表的 Schema、写入数据、提交快照等都是用纯 Iceberg 的底层 API 来实现,没有使用现有的 Flink Iceberg API 来做,这样实现起来更加灵活。
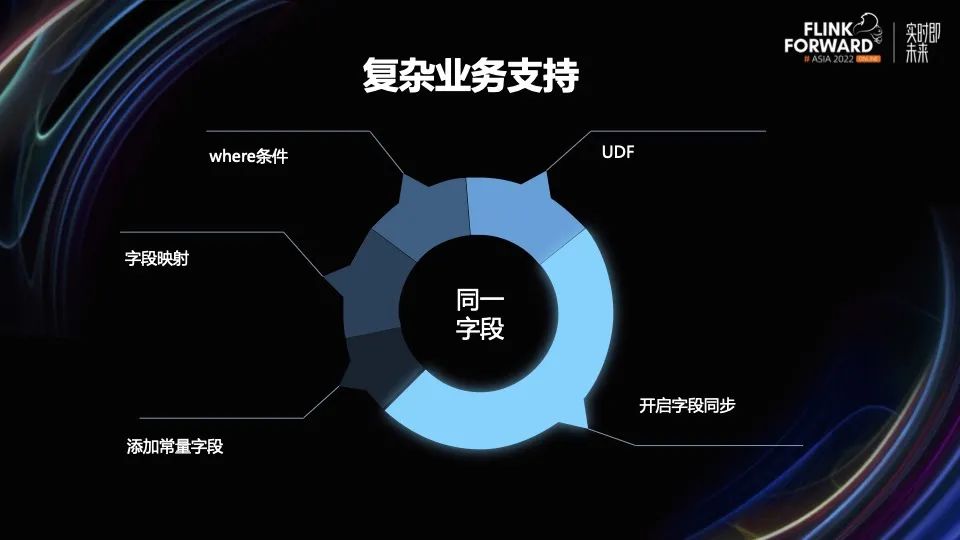
在业务上,我们也会面临很多复杂的业务场景,比如对同一字段,我们会有很多种操作。比如需要支持 UDF;对字段加过滤条件;字段的映射;添加常量字段;开启字段同步等等。所以我们在写逻辑的时候,要考虑各种各样复杂的条件。因为可能改了其中某一个功能进而就影响了其他功能。
04
生产实践
我们系统上线后,目前已经服务于十几个客户,涉及到金融、能源等各个行业。支持的数据源包括 MySQL、PostgreSQL、Oracle、SQL Server 等。数据规模方面,目前客户用于同步的任务从几个到几十个库不等,每秒同步数千条数据。

未来我们将在以下三方面进行提升:
第一,做一些性能提升。做一些压测,从各个角度提高系统的吞吐率和性能。
第二,希望有更多参数配置。比如 Kafka Sink 的各种 Topic 配置、Iceberg 的分区配置等等。
第三,希望有更多数据源的支持。
往期精选





▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」,查看更多赛事信息~
点击「阅读原文」,查看更多赛事信息~