一、安装locust
pip install locust -- 安装(在pycharm里面安装或cmd命令行安装都可)
locust -V -- 查看版本,显示了就证明安装成功了
或者直接在Pycharm中安装locust:
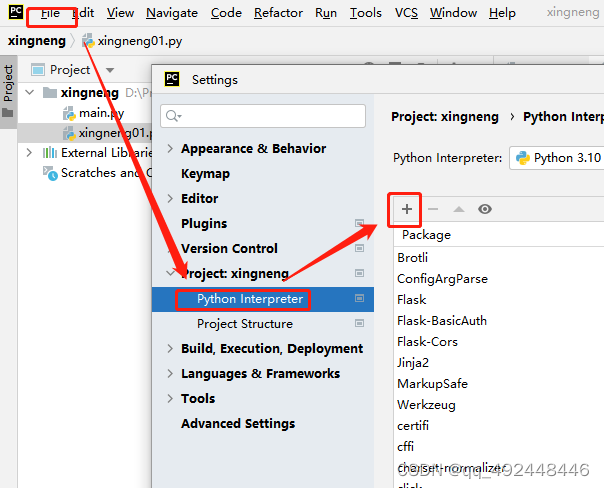
搜索locust并点击安装,其他的第三方包也可以通过这种方式

二、locust介绍
Locust 是一种易于使用、可编写脚本且可扩展的性能测试工具。并且有一个用户友好的 Web 界面,可以实时显示测试进度。甚至可以在测试运行时更改负载。它也可以在没有 UI 的情况下运行,使其易于用于 CI/CD 测试。
Locust 使运行分布在多台机器上的负载测试变得容易。Locust 基于事件(gevent),因此可以在一台计算机上支持数千个并发用户。与许多其他基于事件的应用程序相比,它不使用回调。相反,它通过gevent使用轻量级进程。并发访问站点的每个Locust(蝗虫)实际上都在其自己的进程中运行(Greenlet)。这使用户可以在Python中编写非常有表现力的场景,而不必使用回调或其他机制。
三、脚本
1.方式一(直接在HttpUser中定义任务)
from locust import HttpUser, task, constant
class FlashUser(HttpUser):
host = 'http://127.0.0.1:8080/'
wait_time = constant(1)
@task
def login_test(self):
url = '/api/user/login'
data = {"userName":"xuyang@test.ai","password":"xy123456"}
headers = {"Content-Type": "application/json"}
self.client.request(method='POST', url=url, data=data, headers=headers, name='login登录')
HttpUser:控制用户发请求的频率、用户的思考时间、设置主机的IP地址、也可以定义任务
@task:@task用来标记哪个方法是任务,什么任务,我要做性能测试执行哪个接口
host:被测系统,你要发送请求到哪个服务器
wait_time:每次请求的间隔、停顿时间、思考时间
constant:为固定的思考时间,这里可以简单理解为固定定时器(只是wait_time的其中一种等待时间的方式,其它的可以自己研究一下)
描述:
1.创建一个User类FalshUser, 继承HttpUser,然后定义主机IP地址、思考时间;
2.在类下面编写一个测试接口,跟我们使用request类似,有个别区别;
3.用@task的方式进行定义任务,这个为什么要用task上面解释说了
4.接口方法内需要注意的点:
1)url只需要写路径即可,请求时自动拼接host;
2)发送请求的时候要用self.client.request去请求,并且增加method,和name两个入参,method就是请求方法、name就是接口名称;
3)self.client.request 它的发送请求跟我们常用的接口测试的request库非常类似,因为底层封装的就是request库;
运行描述:
打开你的Terminal,然后cd到你写的测试文件目录下,.py的文件;
运行命令:locust -f 测试文件.py;
回车运行,之后如果出现第一张图显示的那样,就证明运行成功了;
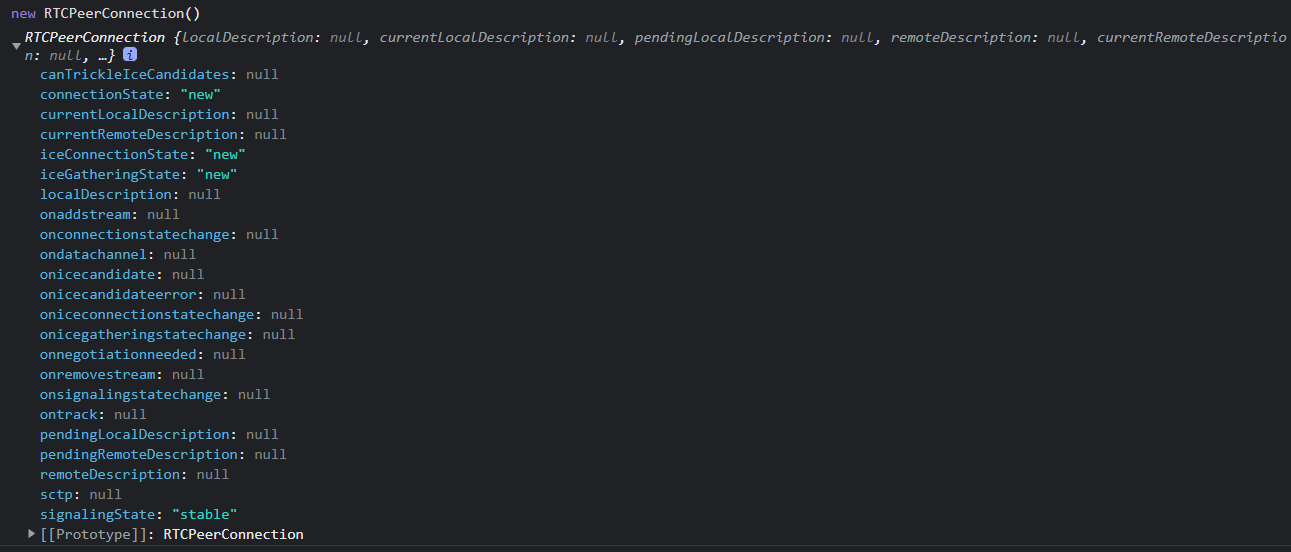
打开你的浏览器输入http://localhost:8089,回车就会打开第二张图显示的GUI的locust页面

locust页面字段解释:
Number of users to simulate:设置模拟的用户总数;
Hatch rate (users spawned/second):每秒启动的虚拟用户数;
host:就是你脚本内写的被测系统地址,打开页面后自动填入的;
Start swarming:开始运行性能测试;
输入模拟的用户总数、输入每秒启动的虚拟用户数,点击Start swarming即可运行
运行结果:


大概就是这样,可以看类似jmeter聚合报告一样的表格,和tps监测、IO监测、可以导出各种类型的测试报告
2.方式二(写在模块内
from locust import HttpUser, task, constant
@task
def my_self_api(user):
url = '/api/user/login'
data = {"userName":"xuyang@test.ai","password":"xy123456"}
headers = {"Content-Type": "application/json"}
# 可以通过user.去调用client
user.client.request(method='POST', url=url, data=data, headers=headers, name='login登录')
class FlashUser(HttpUser):
host = 'http://127.0.0.1:8080/' # 被测系统的地址
wait_time = constant(1) # 每次请求的间隔、停顿时间、LR里面叫做思考时间(constant为固定的思考时间)
tasks = [my_self_api]
描述:
跟方式一代码类似,把User类和任务方法剥离,单独写开,用户操作用FlashUser管理,方法单独管理;
其中任务类剥离后,需要传入一个user字段,我们需要在任务函数里面来通过HttpUser传入的实例self->user来进行调用请求,需要注意我们任务函数传入的这个user,这个user就是FlashUser对象本身,就是FlashUser的一个实例,user指的就是self,这个时候我们就可以通过user.client来请求接口;
tasks解释:定义测试的范围,而测试方法的定义,可以放在测试类的外部,也就说可以用包去管理测试的方法,而真正要测试的时候,引入业务包,然后配置tasks即可,所以[ ]内我传了我写的任务名称,就是说我要执行这个任务,不然User不知道执行谁;
运行方式参考方式一GUI模式运行
3.方式三(把任务写在任务集里面)
from locust import HttpUser, constant, task, TaskSet
class TaskApi(TaskSet):
@task(1)
def login1(self):
url = '/api/user/login'
data = {"userName": "xuyang@test.ai", "password": "xy123456"}
headers = {"Content-Type": "application/json"}
self.client.request(method='POST', url=url, json=data, headers=headers, name='login-登录接口1')
@task(2)
def login2(self):
url = '/api/user/login'
data = {"userName": "xuyang@test.ai", "password": "xy123456"}
headers = {"Content-Type": "application/json"}
self.client.request(method='POST', url=url, json=data, headers=headers, name='login-登录接口2')
class FlashUser(HttpUser):
host = 'http://127.0.0.1:8080/'
wait_time = constant(2)
tasks = [TaskApi]
描述:
TaskSet解释:任务集,所谓的任务集,我理解的就是我有很多的性能测试任务/接口,那么我可以把这些接口写在一个类里面,和User类剥离出来,用User类来控制用户数和条件去进行执行;
方式三我把任务方法做了升级,写了一个TaskApi类,通过继承TaskSet来管理我的任务,这个类我主要写一些测试任务,每个需要执行性能测试的任务用@task标记;
那么代码怎么知道哪个是任务集呢?用TaskSet,需要作为任务集的类TaskApi,继承TaskSet,这样User类就知道,这个是任务集的类;
@task(1)、@task(2)里面的数字是什么意思?@task用来标记哪个方法是任务,括号里面的数字,我理解的是任务权重,比如:1、2,那么可以理解为如果用户有9个,那么@task(1)执行3个,@task(2)执行6个;
关于self.client:当我们在任务集的类中去写发送请求的时候,会发现self.后会出现user,这个user就是User类的实例,也就是说User类让哪个任务去执行,它就会把它自己的对象传给任务本身,当然你可以不写self.user, 直接self.client,当我们写了self.client后,ctrl+鼠标左键点击client,进去client底层方法会发现,它底层封装的是self.user.client;
注意:以上三种方式在执行性能测试的任务的时候,凡是带@task的标签的任务都是是并行运行的、是无序的,而不是按照代码逻辑从上往下执行
4.方式四(SequentialTaskSet)
SequentialTaskSet:如果需要有序的,我们可以继承该方法来进行创建任务
"""按顺序运行"""
class SeqSupTech(SequentialTaskSet):
url = '/api/user/login'
data = {"userName": "xuyang@test.ai", "password": "xy123456"}
headers = {"Content-Type": "application/json"}
@task(1)
def login1(self):
self.client.request(method="POST", url=self.url, json=self.data, headers=self.headers, name='登录接口1')
@task(5)
def login2(self):
self.client.request(method="POST", url=self.url, json=self.data, headers=self.headers, name='登录接口2')
class RequestUser(HttpUser):
host = 'http://127.0.0.1:8080/'
wait_time = constant(2)
tasks = [SeqSupTech]
描述:
只需要在创建任务集的类的时候继承SequentialTaskSet,那么这个任务集在运行的时候就会按照上下组合的顺序根据权重进行执行,比如上面这段代码的@task(1)和@task(5),代表先执行login1,再执行login2,循环执行;
四、非GUI模式运行并生成Html报告
命令:
locust -f denom_chain_query.py --headless -u 1 -r 1 -t 1m --html locust_report.html
-f locust_test.py //代表执行哪一个压测脚本
--headless //代表无界面执行
-u 100 //模拟100个用户操作
-r 100 //每秒用户增长数
-t 10m //压测10分钟
--html report.html //html结果输出的文件路径名称,无需提前创建,自动生成
运行:
Html报告:


最后建议接口传参的name用英文的,不要汉字,容易乱码,这个问题有解决的,可以在评论区讲下,我也学习一下