目录
- 1、文章贡献
- 2、直方图算法Histogram(减少分裂点)
- 3、基于梯度的单边采样算法GOSS(减少样本量)
- 4、互斥特征捆绑算法EFB(减少特征)

在上篇中提到,XGBoost算法的局限是它在寻找最优分裂点算法中需要预排序以及遍历数据集,比较消耗内存和时间,而这篇中的LightGBM则是基于该局限的一种改进。
不熟悉XGBoost的小伙伴可以看看这篇笔记 论文解读14——XGBoost:A Scalable Tree Boosting System
1、文章贡献
提出了一个轻量级的梯度提升算法LightGBM,是GBDT算法的另一个实现,针对XGBoost的局限,在保持精确度的情况下对内存和效率上进行了优化。
LightGBM改进点:
- 采用直方图算法Histogram解决分裂点数过多的问题。
- 采用基于梯度的单边采样算法GOSS解决样本量过多的问题。
- 采用互斥特征捆绑算法EFB解决特征过多的问题。
总的来说:LightGBM = XGBoost + Histogram + EFB
2、直方图算法Histogram(减少分裂点)
对特征进行分桶操作,并计算每个桶中的特征数以及梯度求和,寻找最优分裂点。此时需要遍历的分裂点数等于桶数减1,相比分桶前遍历的点数少很多,减少了计算量,且占用更少的内存。

内存占用少:
- 直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用 8位整型存储就足够了,内存消耗可以降低为原来的1/8。也就是说XGBoost需要用 32位的浮点数去存储特征值,并用 32 位的整形去存储索引,而 LightGBM只需要用 8 位去存储直方图,内存相当于减少为 1/8。
计算代价小:
- 预排序算法XGBoost每遍历一个特征值就需要计算一次分裂的增益,而直方图算法LightGBM只需要计算 k 次,时间复杂度从O(#data * #feature)降低到O(k * #feature)
另一个优化是直方图作差加速
一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到,在速度上可以提升一倍。(在实际构建过程中,可以先计算直方图小的叶子节点,然后利用直方图做差来获得直方图大的叶子节点,以减少计算代价)

在叶子生长策略上
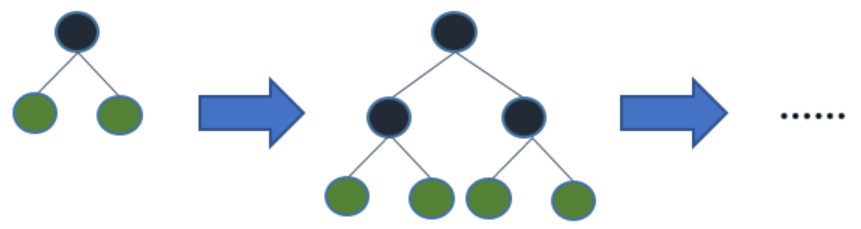
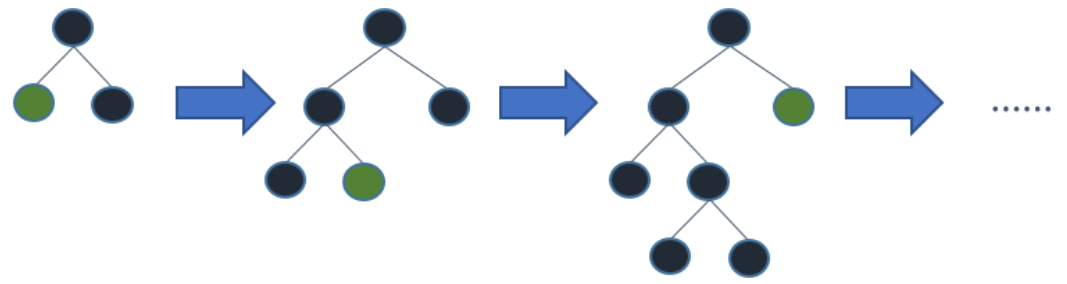
- XGBoost采用 Level-wise按层生长策略,即不管这个叶子分裂后增益怎么样,每一层叶子都会分裂过去,带来很多没必要的计算开销。
- LightGBM采用Leaf-wise按叶子生长的策略,每次在当前待分裂的所有叶子中找到增益最大的进行分裂,可以避免增益较低的叶子不必要的分裂,且增加了最大深度的限制,在提高效率的同时防止过拟合。
3、基于梯度的单边采样算法GOSS(减少样本量)
将样本梯度的绝对值按大小排序,对前 a% 梯度较大的样本以及后 (1-a)% 梯度较小的样本里随机选择的 b% 进行保留来有效计算增益,在减少数据量的同时保证了精度。
跟一般的随机下采样相比:
- GOSS算法考虑了样本的梯度信息对计算增益的影响,减少了梯度小的样本,且没有改变原始分布。

- 实际的方差增益:
- GOSS得到的方差增益:
其中A表示前 a% 个梯度大的样本集,B表示后 **(1-a)%**中随机 b% 个梯度小的样本集。
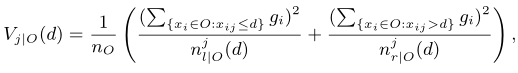
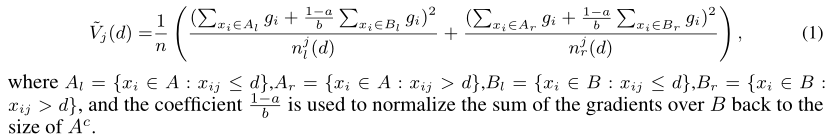
4、互斥特征捆绑算法EFB(减少特征)
通过将两两互斥(不同时为非零值)的特征捆绑在一起来减少特征数,有效避免零特征值不必要的计算,提高计算效率。