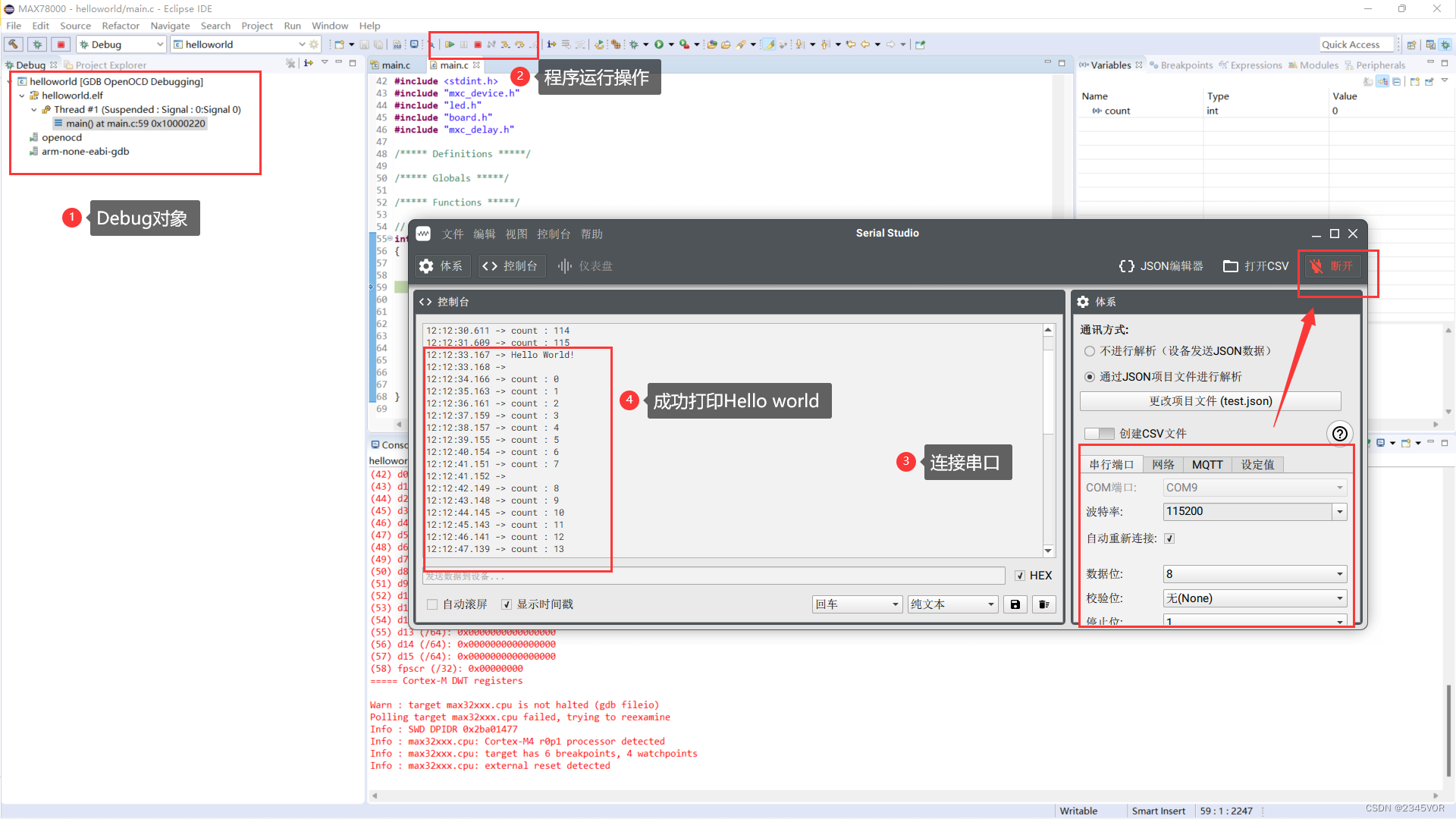
本文是对 http://gameprogrammingpatterns.com/object-pool.html 的原创翻译。部分地方使用意译,不准确的地方请各位指证。
一、对象池的意义
通过重新使用固定的池式结构中的对象,来代替单独分配和释放对象,可以提高程序的性能和内存使用。
二、应用场景
比如给游戏制作视觉效果:当某位英雄施放法术时,画面上要出现闪烁的火花(弹幕),这就需要一个可以生成小而闪亮的图像的粒子系统。因为一挥魔杖就要能产生数百个粒子,所以这个系统需要能够非常迅速地产生它们。更重要的是,要确保创建和销毁这些粒子不会导致内存碎片。

(附上游戏:东方Project 的配图,看到这么多的弹幕粒子,这下你们懂了吧?嘿嘿)
三、内存碎片
从很多方面来看,游戏主机或移动端的编程跟嵌入式相近,内存稀缺,但用户希望游戏运行稳定。在这种场合下,传统PC上有效的压缩内存管理器会无法使用,导致致命的内存碎片问题。
内存碎片化意味着堆中的空闲空间被分解成更小的内存块,而不是一个大的开放块。可用的总内存可能很大,但最大的连续区域可能非常小。假设我们有14个字节可用,但它被分成两个7字节的片段,中间有一块正在使用的内存。如果我们试图分配一个12字节的对象,就会失败,导致用户屏幕上无法再出现闪光的粒子。

即使碎片化并不频繁,它也会逐渐将堆变成无法使用的空洞和裂缝,最终彻底摧毁正在运行的游戏,导致崩溃。
四、两全其美的解决方法
因为碎片化和内存分配会导致游戏运行变慢,所以游戏开发会非常注意内存管理。一个简单的解决方案——在游戏运行开始时获取一大块内存,直到游戏结束才释放它,从而解决需要在游戏运行时创建和摧毁对象的痛点。
对象池为我们提供了两全其美的解决方法。对于内存管理,我们只是预先分配了一大块内存,而不是在游戏运行时释放它。对于池的使用者,我们可以根据自己的需求自由分配和释放对象。
五、对象池设计模式
定义一个维护可重用对象集合的池式结构。每个对象都支持被查询是否正在“使用中”,来判断它当前是否“存活”。当对象池初始化时,它预先创建整个对象集合(通常在单个连续分配内存中),并将它们全部初始化为“未使用”状态。
当使用者需要一个新对象时,向对象池请求。它会找到一个可用的对象,初始化它为“在使用中”状态,然后返回它。当不再需要该对象时,它将被设置回“不使用”状态。通过这种方式,可以自由地创建和销毁对象,而不需要分配内存或其他资源。
六、什么时候使用对象池设计模式
该设计模式在游戏中被广泛用于需要产生视觉效果的地方,但它也用于其它场合,可以在以下情况使用对象池:
需要经常创建和销毁对象。
对象大小相似。
在堆上分配对象耗时久,或者可能导致内存碎片的情况。
每个对象都封装了一个资源,如数据库或网络连接,创建成本高,但可以复用的情况。
七、注意:
程序员通常依赖垃圾回收机制或new和delete来处理管理内存。我们需要了解对象池的限制和不足:
1、对象池可能会在不需要的对象上浪费内存
对象池的大小需要根据程序的需要进行调整。在调优时,当对象池设置得太小通常会很明显(会导致程序崩溃)。但也要注意对象池不要设置得太大。使用较小的内存池释放的内存可以用于程序的其它方面。
2、在任何时候只有固定数量的对象可以被激活
在某些情况下,这是一件好事。将内存划分到不同类型对象的独立池中可以确保,比如:游戏中爆炸产生大量的粒子对象不会导致粒子系统消耗掉所有可用的内存,从而导致无法生成新的敌人对象。

尽管如此,也可能存在重新使用对象池中的对象失败的情况,因为它们都在使用中。这里有一些常见的策略来处理这个问题:
(1)彻底阻止它(阻止重新使用对象池中的对象失败的情况)。这是最常见的“修复”方法:调优对象池大小,使用户无论做什么都不会导致程序内存溢出。对于敌人或游戏道具等重要对象,这通常是正确的解决方法。当玩家到达关卡末尾时,可能没有“正确”的方法来处理无法创造boss的机会,所以明智的做法是确保这种情况永远不会发生。
缺点是,这可能会迫使占用大量内存用于对象槽,而这些对象槽只在一些罕见的边缘情况下才需要。正因为如此,单一固定的池大小可能并不适合所有游戏状态。例如,有些关卡可能突出效果,而有些则专注于声音。在这种情况下,考虑对每个场景进行不同的对象池大小调优。
(2)不要创建对象。这听起来很苛刻,但它对粒子系统这样的情况是有意义的。如果所有的粒子都在使用中,那么屏幕上可能满是闪烁的图形。用户不会注意到下一个爆炸并不像当前爆炸那样令人印象深刻。
(3)强行删除现有对象。想一想用来播放当前声音的对象池的场景,假设您想要开始一个新的声音,但对象池已满。你并不想简单地忽略新的声音——用户会注意到游戏中他们的魔法魔杖有时剧烈地嗖嗖作响,有时却顽固地保持沉默。一个更好的解决方案是找到已经播放的最安静的声音,并用我们的新声音替换它。新的声音将掩盖之前的声音。
一般来说,如果现有对象的消失比新对象的消失更不引人注意,那么这可能是正确的选择。
(4)增加对象池的大小。如果你的游戏允许你更灵活地使用内存,你可以在运行时增加池的大小或创建第二个溢出池。如果您确实通过这两种方式获取更多的内存,请考虑当不再需要额外的容量时,池是否应该收缩到以前的大小。
3、每个对象的内存大小都是固定的
大多数对象池实现是将对象存储在一个“就地”(不允许进行移动,或者称作原位操作,即不允许使用临时变量)对象数组中。如果所有对象的类型都相同,则没问题。但是,如果希望在池中存储不同类型的对象,或者可能添加字段的子类实例,则需要确保池中的每个槽都有足够的内存来存储最大的可能对象。否则,一个出乎意料的大对象将踩下一个对象并破坏内存。
同时,当对象的大小不同时,会浪费内存。每个槽需要足够大,以容纳最大的对象。如果很少对象这么大,那么每次在插槽中放入较小的对象时,就会浪费内存。这就像通过机场安检,用一个巨大的随身行李托盘来装你的钥匙和钱包。
当你发现自己用这种方式消耗了大量的内存时,考虑将池划分为不同大小的对象的独立池——大托盘放行李,小托盘放口袋里的东西。
4、重用的对象不会自动清除
大多数内存管理器都有一个调试特性,可以将新分配或释放的内存清除为一些特别的值,如0xdeadbeef。这可以帮助您查找由于未初始化变量或在释放内存后使用内存而导致的错误。
由于对象池在重用对象时不再经过内存管理器,因此我们失去了这个保障措施。更糟糕的是,用于“新”对象的内存以前保存着完全相同类型的对象。这使得几乎不可能知道在创建新对象时是否忘记初始化了什么:存储对象的内存可能已经包含了它过去生命周期中几乎正确的数据。
因此,要特别注意,初始化池中新对象的代码必须完全初始化该对象。甚至值得花一点时间添加一个调试特性,以便在对象被回收时为对象槽清除内
5、未使用的对象将保留在内存中
对象池在支持垃圾收集的系统中不太常见,因为内存管理器通常会为您处理碎片。但是池在避免分配和回收内存方面仍然很有用,特别是在具有较慢的cpu和更简单的垃圾收集器的移动设备上。
如果您确实将对象池与垃圾收集器一起使用,请注意潜在的冲突。因为当对象不再使用时,池实际上不会释放它们,它们会保留在内存中。如果它们包含对其他对象的引用,它将阻止收集器也回收这些对象。为了避免这种情况,当池对象不再使用时,清除它对其他对象的任何引用。
八、简单的示例代码
现实世界中的粒子系统通常会模拟重力、风、摩擦和其他物理效应。我们的简单例子将只在一定帧数的直线上移动粒子,然后销毁粒子。可以说明如何使用对象池。
我们将从最简单的实现开始。首先是粒子类:
class Particle
{
public:
Particle()
: framesLeft_(0)
{}
void init(double x, double y,
double xVel, double yVel, int lifetime)
{
x_ = x; y_ = y;
xVel_ = xVel; yVel_ = yVel;
framesLeft_ = lifetime;
}
void animate()
{
if (!inUse()) return;
framesLeft_--;
x_ += xVel_;
y_ += yVel_;
}
bool inUse() const { return framesLeft_ > 0; }
private:
int framesLeft_;
double x_, y_;
double xVel_, yVel_;
};默认构造函数将粒子初始化为“未使用”状态。然后调用init()函数将粒子初始化为“活动”状态。随着时间的推移使用animate()函数对粒子进行动画处理,该函数应该每帧调用一次。
对象池需要知道哪些粒子可以重用。它从粒子的inUse()函数中获取是否重用,该函数利用了粒子生命周期有限的特征,并使用framesLeft_变量来查找哪些粒子正在使用,而不必存储单独的标志。
池类也很简单:
class ParticlePool
{
public:
void create(double x, double y,
double xVel, double yVel, int lifetime);
void animate()
{
for (int i = 0; i < POOL_SIZE; i++)
{
particles_[i].animate();
}
}
private:
static const int POOL_SIZE = 100;
Particle particles_[POOL_SIZE];
};create()函数允许外部代码创建新的粒子。游戏每帧调用animate()函数一次,这反过来使池中的每个粒子都具有动画效果。
animate()方法是Update method设计模式的一个例子。
粒子本身简单地存储在类中一个固定大小的数组中。在这个示例实现中,池大小定义在类声明中,但可以通过使用给定大小的动态数组或使用值模板参数在外部定义池的大小。
创建一个新粒子很简单:
void ParticlePool::create(double x, double y,
double xVel, double yVel,
int lifetime)
{
// Find an available particle.
for (int i = 0; i < POOL_SIZE; i++)
{
if (!particles_[i].inUse())
{
particles_[i].init(x, y, xVel, yVel, lifetime);
return;
}
}
}遍历对象池寻找第一个可用粒子。当我们找到它时,初始化它,就完成了。注意,在这个实现中,如果没有任何可用的粒子,就不创建新的粒子。
这就是一个简单粒子系统的全部内容,当然,除了渲染粒子。我们现在可以创建一个对象池并使用它创建一些粒子。当粒子的寿命到期时,它们会自动失效。
这对于实现发行一款游戏来说已经足够了,但是我们敏锐的眼睛可能会注意到创造一个新粒子需要迭代整个集合,直到我们找到一个开放的插槽。如果池非常大且大部分都是满的,那么速度就会变慢。让我们看看如何改进它。
自由列表:
如果我们不想浪费时间寻找自由粒子,显然的答案是不要失去它们的地址。我们可以存储指向每个未使用粒子的单独指针列表。然后当我们需要创建一个粒子时,我们从列表中删除第一个指针,并重用它所指向的粒子。
不幸的是,这将要求我们维护一个完整的独立数组,它的指针与池中对象的数量一样多。毕竟,当我们第一次创建池时,所有粒子都是未使用的,因此列表最初会有一个指向池中每个对象的指针。
在不牺牲任何内存的情况下修复性能问题会很好。很方便的是,我们已经有了一些可用的内存——未使用粒子本身的数据。
当一个粒子不被使用时,它的大部分状态是不相关的。它的位置和速度没有被使用。它需要的唯一状态是判断它是否死亡所需的变量。在我们的例子中,这是framesLeft_成员。所有其他的比特都可以被重用。这是一个修改后的粒子:
class Particle
{
public:
// ...
Particle* getNext() const { return state_.next; }
void setNext(Particle* next) { state_.next = next; }
private:
int framesLeft_;
union
{
// State when it's in use.
struct
{
double x, y;
double xVel, yVel;
} live;
// State when it's available.
Particle* next;
} state_;
};我们已经将除了framesLeft_之外的所有成员变量移动到state_ union中的活动结构中。这个结构体在粒子被动画化时保存它的状态。当粒子未使用时,使用并集的另一种情况,即下一个成员。它保存着一个指针,指向这个粒子之后的下一个可用粒子。
大家对共用体的使用频率似乎不高,因此您可能对其语法不熟悉。如果你在一个游戏团队中,你可能会有一个“内存专家”,当游戏不可避免地超出内存预算时,他的工作就是提出解决方案。问问他们。他们会讲述所有关于它们和其他有趣的比特打包技巧。
我们可以使用这些指针来构建一个链表,将池中每个未使用的粒子链接在一起。我们有我们需要的可用粒子的列表,但我们不需要使用任何额外的内存。相反,我们蚕食死粒子本身的内存来存储列表。
这种巧妙的技术被称为自由列表。为了使其工作,我们需要确保指针被正确初始化,并在粒子被创建和销毁时得到维护。当然,我们需要跟踪列表的头部:
class ParticlePool
{
// ...
private:
Particle* firstAvailable_;
};当第一次创建一个对象池时,所有的粒子都是可用的,因此我们的空闲列表应该贯穿整个池。池构造函数设置为:
ParticlePool::ParticlePool()
{
// The first one is available.
firstAvailable_ = &particles_[0];
// Each particle points to the next.
for (int i = 0; i < POOL_SIZE - 1; i++)
{
particles_[i].setNext(&particles_[i + 1]);
}
// The last one terminates the list.
particles_[POOL_SIZE - 1].setNext(NULL);
}现在要创建一个新粒子,我们直接跳到第一个可用粒子:
void ParticlePool::create(double x, double y,
double xVel, double yVel,
int lifetime)
{
// Make sure the pool isn't full.
assert(firstAvailable_ != NULL);
// Remove it from the available list.
Particle* newParticle = firstAvailable_;
firstAvailable_ = newParticle->getNext();
newParticle->init(x, y, xVel, yVel, lifetime);
}
我们需要知道粒子何时销毁,以便将其添加回自由列表,因此我们修改animate()函数,如果之前的活粒子在该帧中放弃了还原,则返回true:
bool Particle::animate()
{
if (!inUse()) return false;
framesLeft_--;
x_ += xVel_;
y_ += yVel_;
return framesLeft_ == 0;
}
当发生这种情况时,我们简单地将它重新装入到列表中:
void ParticlePool::animate()
{
for (int i = 0; i < POOL_SIZE; i++)
{
if (particles_[i].animate())
{
// Add this particle to the front of the list.
particles_[i].setNext(firstAvailable_);
firstAvailable_ = &particles_[i];
}
}
}到这里我们完成了一个具有恒定的创建和删除时间的小对象池了。
九、设计需要考虑的东西
正如您所看到的,最简单的对象池实现是很简易的:创建对象数组并根据需要重新初始化它们。有几种方法可以在此基础上进行扩展,使池更通用、使用更安全、更容易维护。当你在程序中使用池时,你需要回答以下问题:
1、对象是否与池耦合?
在编写对象池时,您会遇到的第一个问题是对象本身是否知道它们在池中。大多数情况下都是这样,但是在编写可以保存任意对象的泛型池类时就没有这种不常有的优势了。
(1)如果对象与池耦合:
实现更简单。您可以简单地在池对象中放置一个表示“正在使用”的标志或函数,然后就可以处理它了。必须确保对象只能由池创建。在c++中,一种简单的方法是使池类成为对象类的友类(有元函数),然后设置对象的构造函数为私有。
class Particle
{
friend class ParticlePool;
private:
Particle()
: inUse_(false)
{}
bool inUse_;
};
class ParticlePool
{
Particle pool_[100];
};这种关系记录了使用类的预期方式,并确保使用者不会创建没有被池跟踪的对象。
您可能能够避免存储显式的“使用中”标志。许多对象已经保留了一些状态,可以用来判断它是否处于活动状态。例如,如果粒子的当前位置在屏幕外,则可以重用它。如果对象类知道它可能在池中使用,它可以提供inUse()方法来查询该状态。这使池不必消耗一些额外的内存来存储一堆“正在使用”的标志。
(2)如果对象没有耦合到池:
任何类型的对象都可以被池化。这是最大的优势。通过将对象与池解耦,您可以实现一个通用的可重用池类。
“in use”状态必须在对象外部跟踪。最简单的方法是创建一个单独的位域:
template <class TObject>
class GenericPool
{
private:
static const int POOL_SIZE = 100;
TObject pool_[POOL_SIZE];
bool inUse_[POOL_SIZE];
};.
2、什么负责初始化重用的对象?
为了重用现有的对象,必须用新的状态重新初始化它。这里的一个关键问题是,是在池类内部还是在池类外部重新初始化对象。
(1)如果在池内部重新初始化:
池可以完全封装它的对象。根据对象需要的其他功能,您可以将它们完全保持在池内部。这确保了其他代码不会维护对可能被意外重用的对象的引用。
池与对象的初始化方式相关。一个池对象可以提供多个函数来初始化它。如果池管理初始化,它的接口需要支持所有这些,并将它们转发给对象。
class Particle
{
// Multiple ways to initialize.
void init(double x, double y);
void init(double x, double y, double angle);
void init(double x, double y, double xVel, double yVel);
};
class ParticlePool
{
public:
void create(double x, double y)
{
// Forward to Particle...
}
void create(double x, double y, double angle)
{
// Forward to Particle...
}
void create(double x, double y, double xVel, double yVel)
{
// Forward to Particle...
}
};
(2)如果是外部代码初始化对象:
池的接口可以更简单。与其提供多个函数来覆盖对象的每种初始化方式,池可以简单地返回对新对象的引用:
class Particle
{
public:
// Multiple ways to initialize.
void init(double x, double y);
void init(double x, double y, double angle);
void init(double x, double y, double xVel, double yVel);
};
class ParticlePool
{
public:
Particle* create()
{
// Return reference to available particle...
}
private:
Particle pool_[100];
};调用者可以通过调用对象公开的任何方法来初始化对象:
ParticlePool pool;
pool.create()->init(1, 2);
pool.create()->init(1, 2, 0.3);
pool.create()->init(1, 2, 3.3, 4.4);外部代码可能需要处理创建新对象的失败。前面的例子假设create()函数总是会成功返回指向对象的指针。但是,如果池已满,则可能返回NULL。为了安全起见,你需要在初始化对象之前进行检查:
Particle* particle = pool.create();
if (particle != NULL) particle->init(1, 2);十、另外请参考
这看起来很像享元模式。两者都维护可重用对象的集合。区别在于“重用”的含义。享元对象通过在多个所有者之间同时共享同一个实例来重用。享元模式通过在多个上下文中使用相同的对象来避免重复的内存使用。
池中的对象也会被重用,但只是随着时间的推移。在对象池的上下文中,“重用”意味着在原始所有者使用完对象之后回收对象的内存。在对象池中,不需要在对象的生命周期内共享对象。
在内存中打包一堆相同类型的对象有助于在游戏迭代这些对象时保持CPU缓存满。数据位置模式就是这样的。









![[附源码]java毕业设计作业自动评阅系统](https://img-blog.csdnimg.cn/3fa0fd418fec4c8aaa2e4e594d2c4231.png)