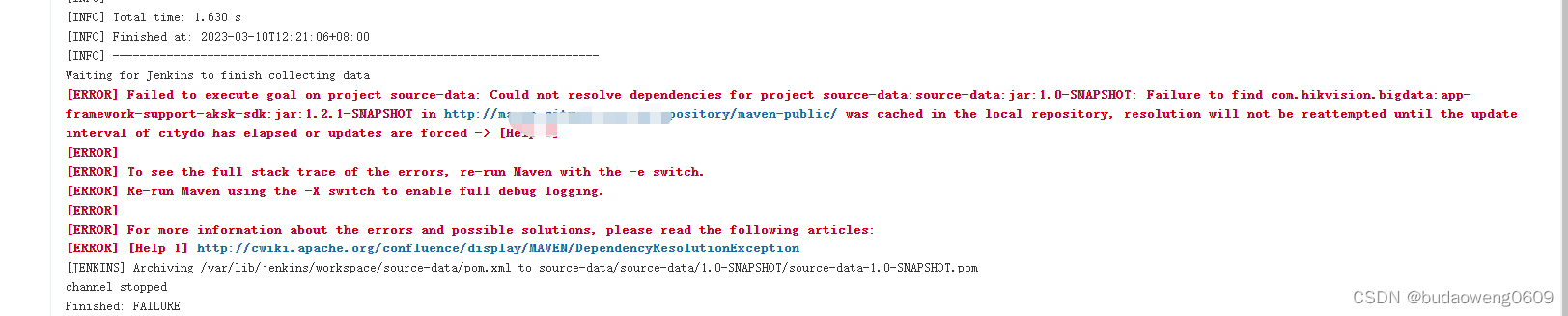
一、Spark RDD概念
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是,转换操作(如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改。因此,RDD比较适合对于数据集中元素执行相同操作的批处理式应用,而不适合用于需要异步、细粒度状态的应用,比如Web应用系统、增量式的网页爬虫等。正因为这样,这种粗粒度转换接口设计,会使人直觉上认为RDD的功能很受限、不够强大。但是,实际上RDD已经被实践证明可以很好地应用于许多并行计算应用中,可以具备很多现有计算框架(比如MapReduce、SQL、Pregel等)的表达能力,并且可以应用于这些框架处理不了的交互式数据挖掘应用。
二、Spark RDD特征
Spark一切都是基于RDD的,RDD就是Spark输入的数据,作为输入数据的每个RDD有五个特征,其中分区、一系列的依赖关系和函数是三个基本特征,优先位置和分区策略是可选特征。
1,内存计算
Spark RDD运算数据是在内存中进行的,在内存足够的情况下,不会把中间结果存储在磁盘,所以计算速度非常高效。
2,惰性求值
所有的转换操作都是惰性的,也就是说不会立即执行任务,只是把对数据的转换操作记录下来而已。只有碰到action操作需要返回数据给驱动程序(driver program)的时候,他们才会被真正的执行。
3,容错性
Spark RDD具备容错特性,在RDD失效或者数据丢失的时候,可以根据DAG从父RDD重新把数据集计算出来,以达到数据容错的效果。
4,不变性
RDD是进程安全的,因为RDD是不可修改的。它可以在任何时间点被创建和查询,使得缓存,共享,备份都非常简单。在计算过程中,是RDD的不可修改特性保证了数据的一致性。
5,分区
分区是Spark RDD并行计算的基础。每个分区是对数据集的逻辑划分。可以对已存在的分区做某些转换操作创建新分区。
6,持久化
可以调用cache或者persist函数,把RDD缓存在内存、磁盘,下次使用的时候不需要重新计算而是直接使用。
7,粗粒度操作
通过使用map、filter、groupby等操作对RDD数据集进行集体操作。而不是只操作其中某些数据集元素。
8,数据本地化
Spark会把计算程序调度到尽可能离数据近的地方运行,即移动计算而不是移动数据。
三、Spark RDD 和 DSM
1,读写操作
RDD:RDD的读操作有粗粒度和细粒度两种,粗粒度操作针对的是RDD的整个数据集,相反,细粒度操作针对的是RDD数据集的个别元素。而写操作是粗粒度操作,即写的时候是整个数据集一起写,而不是只写其中的某个元素。
DSM:DSM的读写操作都是细粒度操作。
2,一致性
RDD: 一致性对于RDD来说没那么重要,因为它具有不可修改的特性,换句话说RDD是只读的。
DSM: DSM是强一致性的,如果开发者遵循开发协议,那么系统会保证数据的一致性,计算结果都是可预期的。
3,故障恢复机制
RDD : 如果RDD数据出现丢失情况,Spark RDD通过DAG很容易就可以从父RDD把丢失的数据重新计算出来。每一次进行转换操作生成的新RDD都是不可修改的,所以很容易对它进行重算并恢复数据。
DSM : DSM利用检查点技术达到数据恢复的效果,应用程序通过回滚到最近的检查点而不重新计算来达到数据恢复效果。
4,掉队问题缓解
有些节点的运算速度远远比其他节点慢,完成任务需要消耗更多的时间。发生这种情况的原因可能是负载不均衡,IO频繁,垃圾回收等等。
RDD - RDD通过备份task,即把task移到其他节点运行,来解决任务掉队问题。
DSM - 彻底解决掉队问题对于DSM来说比较困难。
5,内存不足的表现
如果没有足够的内存存储RDD,那么RDD会把数据转移到磁盘。
如果内存不够用,将会严重影响DSM的计算性能。它并不会把数据转移到磁盘。
四、Spark RDD的局限性
1,没有内置优化引擎
在处理结构化数据的时候,RDD并不能发挥Spark的高级优化器,比如catalyst优化器、钨丝执行引擎。开发者必须基于RDD的特征具体做优化。
2,处理结构化数据
RDD不能像DataFrame和数据集推断出数据的模型,必须开发者来指定。
3,性能局限性
作为内存里的JVM对象,随着数据量的增长,垃圾回收和Java序列化性能会越来越低,RDD的运算性能也会随之降低。
4,存储局限性
如果没有足够的内存存储RDD,Spark会把RDD溢写到磁盘,这样会导致计算性能低下。
五、Spark RDD依赖
Spark中RDD的数据结构里很重要的一个域是对父RDD的依赖,Spark中的依赖关系主要体现为两种形式,窄依赖(narrow dependency)和宽依赖(wide dependency)
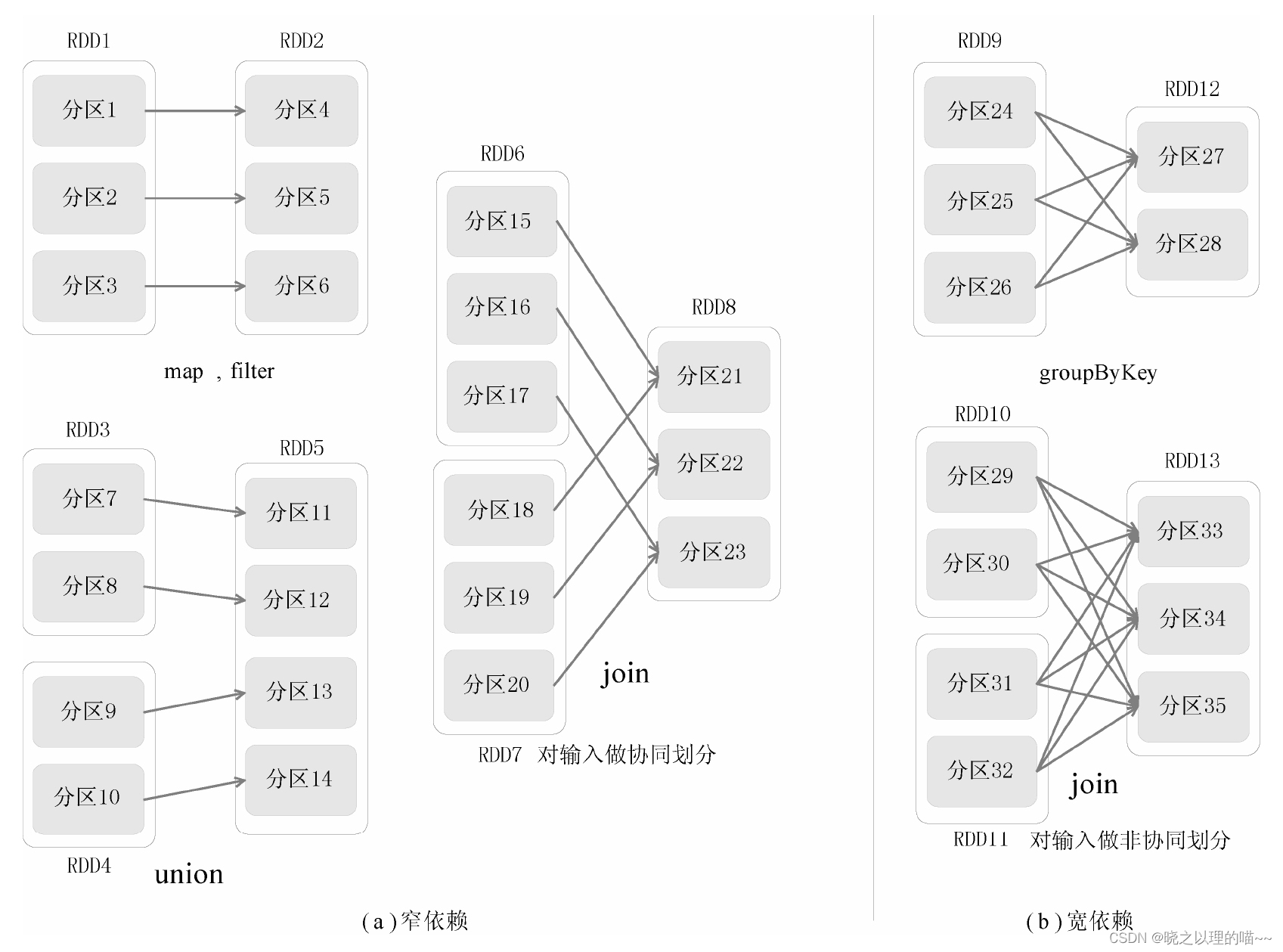
1,窄依赖
窄依赖表现为一个父RDD的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个子RDD的分区;上图中,RDD1是RDD2的父RDD,RDD2是子RDD,RDD1的分区1,对应于RDD2的一个分区(即分区4);再比如,RDD6和RDD7都是RDD8的父RDD,RDD6中的分区(分区15)和RDD7中的分区(分区18),两者都对应于RDD8中的一个分区(分区21)。
窄依赖是指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区(第一类),或多个父RDD的分区对应于一个子RDD的分区(第二类),也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区。
2,宽依赖
宽依赖表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。上图中,RDD9是RDD12的父RDD,RDD9中的分区24对应了RDD12中的两个分区(即分区27和分区28)。
宽依赖是指子RDD的每个分区都依赖于所有父RDD的所有分区或多个分区,也就是说存在一个父RDD的一个分区对应一个子RDD的多个分区。,
3,依赖之间的关系
RDD中不同的操作,会使得不同RDD分区之间产生不同的依赖关系。DAG调度器(DAGScheduler)根据RDD之间的依赖关系,把DAG图划分成若干个阶段。RDD中的依赖关系分为窄依赖(Narrow Dependency)与宽依赖(Wide Dependency),二者的主要区别在于是否包含Shuffle操作。
Spark中的一些操作会触发Shuffle过程,这个过程涉及数据的重新分发,因此,会产生大量的磁盘I/O和网络开销。这里以reduceByKey(func)操作为例介绍Shuffle过程。在reduceByKey(func)操作中,对于所有(key,value)形式的RDD元素,所有具有相同key的RDD元素的value会被归并,得到(key,value-list)的形式,然后,对这个value-list使用函数func计算得到聚合值,比如,(“hadoop”,1)、(“hadoop”,1)和(“hadoop”,1)这3个键值对,会被归并成(“hadoop”,(1,1,1))的形式,如果func是一个求和函数,可以计算得到汇总结果(“hadoop”,3)。

Shuffle过程不仅会产生大量网络传输开销,也会带来大量的磁盘I/O开销。Spark经常被认为是基于内存的计算框架,为什么也会产生磁盘I/O开销呢?对于这个问题,这里有必要做一个解释。
在Hadoop MapReduce框架中,Shuffle是连接Map和Reduce之间的桥梁,Map的输出结果需要经过Shuffle过程以后,也就是经过数据分类以后再交给Reduce处理,因此,Shuffle的性能高低直接影响了整个程序的性能和吞吐量。所谓Shuffle,是指对Map输出结果进行分区、排序、合并等处理并交给Reduce的过程。因此,MapReduce的Shuffle过程分为Map端的操作和Reduce端的操作。

(1)在Map端的Shuffle过程。Map的输出结果首先被写入缓存,当缓存满时,就启动溢写操作,把缓存中的数据写入磁盘文件,并清空缓存。当启动溢写操作时,首先需要把缓存中的数据进行分区,不同分区的数据发送给不同的Reduce任务进行处理,然后对每个分区的数据进行排序(Sort)和合并(Combine),之后再写入磁盘文件。每次溢写操作会生成一个新的磁盘文件,随着Map任务的执行,磁盘中就会生成多个溢写文件。在Map任务全部结束之前,这些溢写文件会被归并(Merge)成一个大的磁盘文件,然后,通知相应的Reduce任务来领取属于自己处理的那个分区数据。
(2)在Reduce端的Shuffle过程。Reduce任务从Map端的不同Map机器领回属于自己处理的那部分数据,然后,对数据进行归并(Merge)后交给Reduce处理。Spark作为MapReduce框架的一种改进,自然也实现了Shuffle的逻辑。
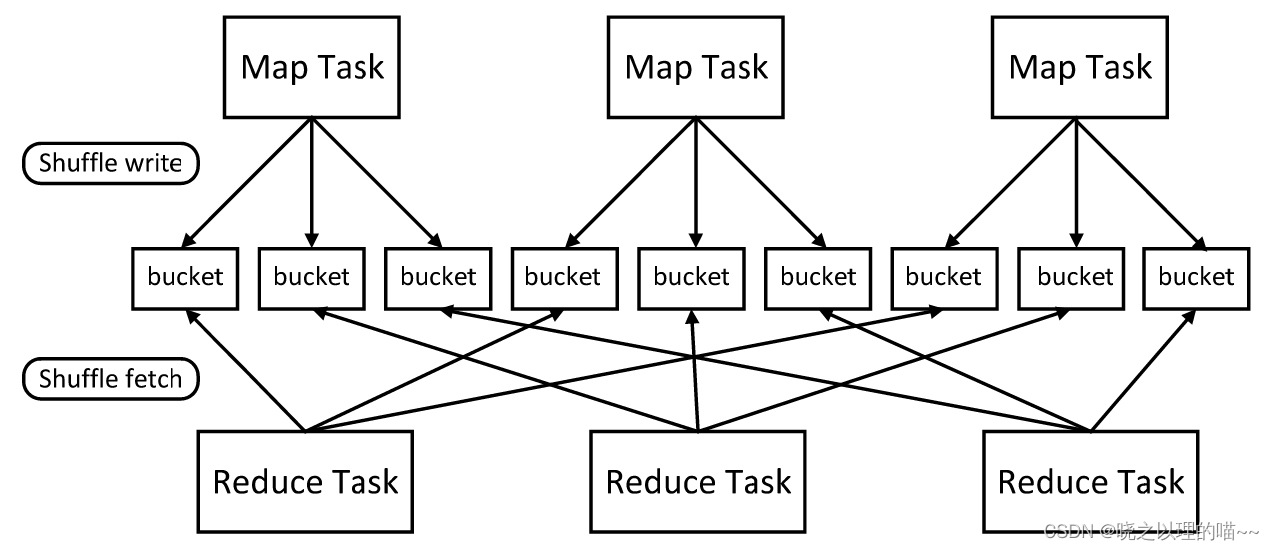
1)在Map端的Shuffle写入(Shuffle Write)方面。每一个Map任务会根据Reduce任务的数量创建出相应的桶(Bucket),因此,桶的数量是m×r,其中,m是Map任务的个数,r是Reduce任务的个数。Map任务产生的结果会根据设置的分区(partition)算法填充到每个桶中去。分区算法可以自定义,也可以采用系统默认的算法;默认的算法是根据每个键值对(key,value)的key,把键值对哈希到不同的桶中去。当Reduce任务启动时,它会根据自己任务的id和所依赖的Map任务的id,从远端或是本地取得相应的桶,作为Reduce任务的输入进行处理。
2)在Reduce端的Shuffle读取(Shuffle Fetch)方面。在Hadoop MapReduce的Shuffle过程中,在Reduce端,Reduce任务会到各个Map任务那里把数据自己要处理的数据都拉到本地,并对拉过来的数据进行归并(Merge)和排序(Sort),使得相同key的不同value按序归并到一起,供Reduce任务使用。这个归并和排序的过程,在Spark中是如何实现的呢?虽然Spark属于MapReduce体系,但是对传统的MapReduce算法进行了一定的改进。Spark假定在大多数应用场景中,Shuffle数据的排序操作不是必须的,比如在进行词频统计时,如果强制地进行排序,只会使性能变差,因此,Spark并不在Reduce端做归并和排序,而是采用了称为Aggregator的机制。Aggregator本质上是一个HashMap,里面的每个元素是<K,V>形式。以词频统计为例,它会将从Map端拉取到的每一个(key,value),更新或是插入HashMap中,若在HashMap中没有查找到这个key,则把这个(key,value)插入其中,若查找到这个key,则把value的值累加到V上去。这样就不需要预先把所有的(key,value)进行归并和排序,而是来一个处理一个,避免了外部排序这一步骤。但同时需要注意的是,Reduce任务所拥有的内存,必须足以存放属于自己处理的所有key和value值,否则就会产生内存溢出问题。因此,Spark文档中建议用户涉及这类操作的时候尽量增加分区的数量,也就是增加Map和Reduce任务的数量。增加Map和Reduce任务的数量虽然可以减小分区的大小,使得内存可以容纳这个分区。但是,在Shuffle写入环节,桶的数量是由Map和Reduce任务的数量决定的,任务越多,桶的数量就越多,就需要更多的缓冲区(Buffer),带来更多的内存消耗。因此,在内存使用方面,我们会陷入一个两难的境地,一方面,为了减少内存的使用,需要采取增加Map和Reduce任务数量的策略,另一方面,Map和Reduce任务数量的增多,又会带来内存开销更大的问题。最终,为了减少内存的使用,只能将Aggregator的操作从内存移到磁盘上进行。也就是说,尽管Spark经常被称为“基于内存的分布式计算框架”,但是,它的Shuffle过程依然需要把数据写入磁盘。
Spark的这种依赖关系设计,使其具有了天生的容错性,大大加快了Spark的执行速度。因为,RDD数据集通过“血缘关系”记住了它是如何从其他RDD中演变过来的,血缘关系记录的是粗颗粒度的转换操作行为,当这个RDD的部分分区数据丢失时,它可以通过血缘关系获取足够的信息来重新运算和恢复丢失的数据分区,由此带来了性能的提升。相对而言,在两种依赖关系中,窄依赖的失败恢复更为高效,它只需要根据父RDD分区重新计算丢失的分区即可(不需要重新计算所有分区),而且可以并行地在不同节点进行重新计算。而对于宽依赖而言,单个节点失效通常意味着重新计算过程会涉及多个父RDD分区,开销较大。此外,Spark还提供了数据检查点和记录日志,用于持久化中间RDD,从而使得在进行失败恢复时不需要追溯到最开始的阶段。在进行故障恢复时,Spark会对数据检查点开销和重新计算RDD分区的开销进行比较,从而自动选择最优的恢复策略。
六、Spark RDD运行过程
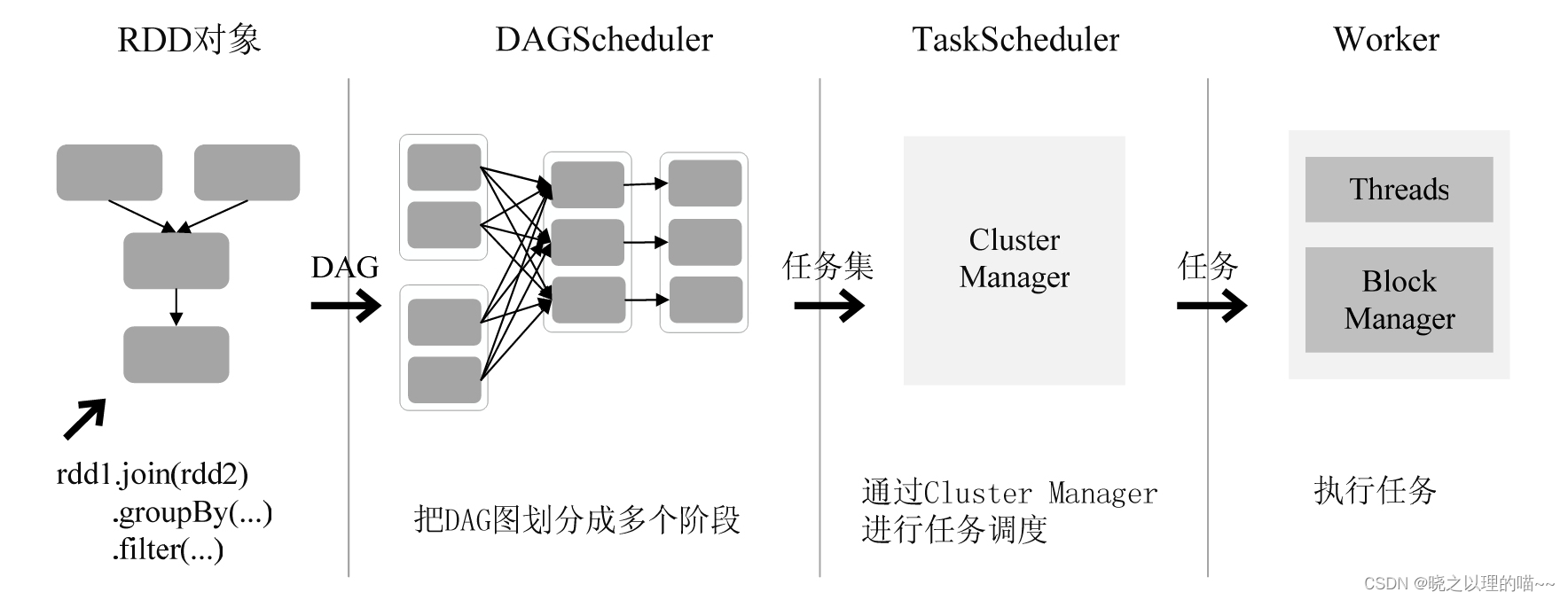
RDD在Spark架构中的运行过程:
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个阶段,每个阶段中包含了多个任务,每个任务会被任务调度器分发给各个工作节点(Worker Node)上的Executor去执行。
文章来源:《Spark编程基础》 作者:林子雨
文章内容仅供学习交流,如有侵犯,联系删除哦!