目录
简介
主要功能
日志收集
数据处理
工作原理
Flume架构
安装
拷贝压缩包
解压
改名
修改配置文件
安装nc(netcat)
安装telnet协议
应用
应用一:实时监听
新建netcat-logger.conf文件
开启端口监听方式一
访问主机
开启端口监听方式二
访问主机
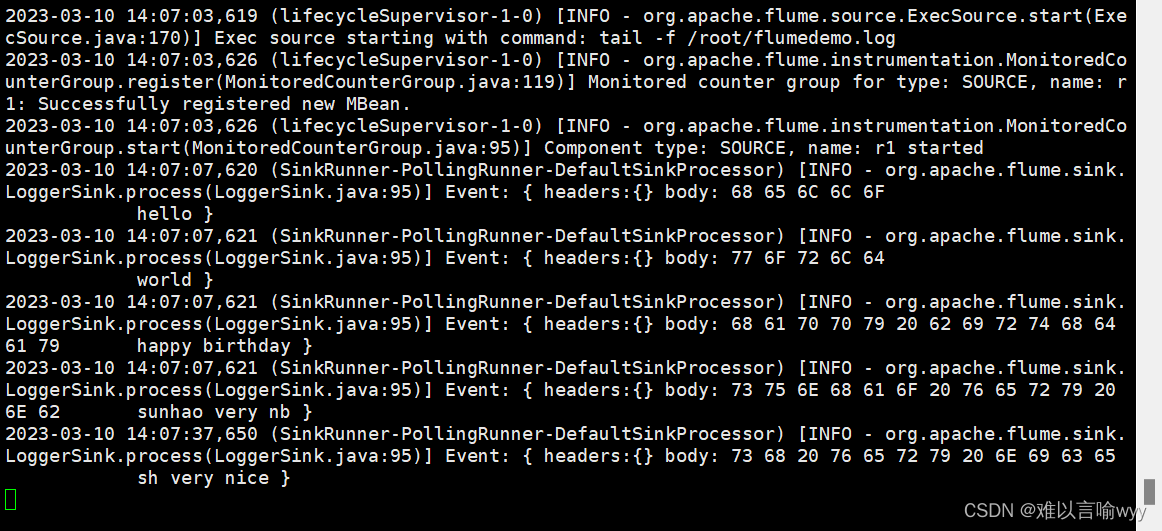
tail命令
应用二:读取文件内容输出到控制台
新建ile-flume-logger.conf文件
开启端口监听
应用三:将文件内容输出到控制台
新建events-flume-logger.conf文件
启动监听
修改文件名符合规则
简介
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。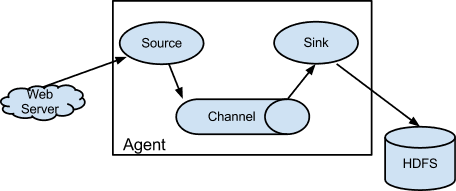
主要功能
日志收集
Flume最早是Cloudera提供的日志收集系统,目前是Apache下的一个孵化项目,Flume支持在日志系统中定制各类数据发送方,用于收集数据。
数据处理
Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力 Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。
工作原理
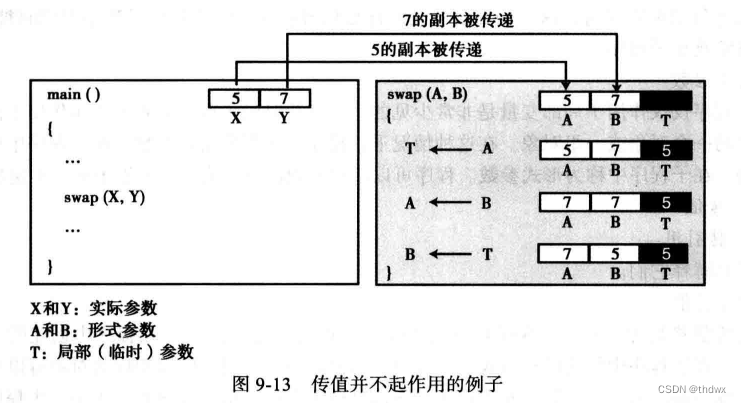
flume的核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。
为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume在删除自己缓存的数据。
在整个数据的传输的过程中,流动的是event,即事务保证是在event级别进行的。
那么什么是event呢?
event将传输的数据进行封装,是flume传输数据的基本单位。如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。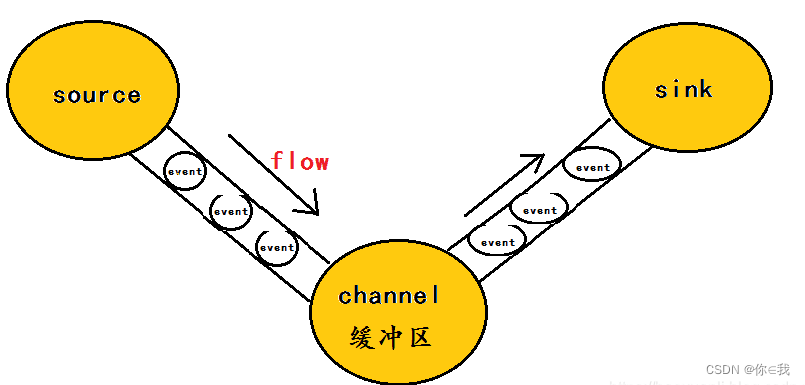
Flume架构
Flume使用agent来收集日志,agent包括三个组成部分:
Source(数据采集器):用于源数据的采集,然后将采集到的数据写人到Channel中并流向Sink;
Channel(缓冲通道): 底层是一个缓冲队列,对Source中的数据进行缓存,将数据高效、准确地写人Sink,待数据全部到达Sink后,Flume就会删除该缓存通道中的数据;
Sink(接收器):接收并汇集流向Sink的所有数据,根据需求,可以直接进行集中式存储(如上图,采用HDFS进行存储),也可以继续作为数据源传人其他远程服务器或者Source中。
在整个数据传输的过程中,Flume将流动的数据封装到一个event(事件)中,它是Flume内部数据传输的基本单元。一个完整的event包含headers和body,其中headers包含了一些标识信息,而body中就是Flume收集到的数据信息。
安装
拷贝压缩包
把压缩包拷贝到虚拟机的 /opt/install 里面
解压
[root@hadoop3 install]# tar -zxf ./apache-flume-1.9.0-bin.tar.gz -C ../soft/
改名
[root@hadoop3 install]# cd ../soft
[root@hadoop3 soft]# mv apache-flume-1.9.0-bin/ flume190
修改配置文件
[root@hadoop3 soft]# cd /opt/soft/flume190/conf
将临时配置文件拷贝为配置文件
[root@hadoop3 conf]# cp flume-env.sh.template flume-env.sh
[root@hadoop3 conf]# vim flume-env.sh
# Enviroment variables can be set here. export JAVA_HOME=/opt/soft/jdk180 # Give Flume more memory and pre-allocate, enable remote monitoring via JMX export JAVA_OPTS="-Xms500m -Xmx2000m -Dcom.sun.management.jmxremote"-Xms:初始Heap大小,使用的最小内存,cpu性能高时此值应设的大一些。
-Xmx:java heap最大值,使用的最大内存。
安装nc(netcat)
[root@hadoop3 conf]# yum install -y nc
安装telnet协议
先查看telnet
[root@hadoop3 ~]# yum list telnet*
安装telnet
[root@hadoop3 ~]# yum install telnet-server
[root@hadoop3 ~]# yum install telnet.*
telnet是teletype network的缩写,现在已成为一个专有名词,表示远程登录协议和方式,分为Telnet客户端和Telnet服务器程序. Telnet可以让用户在本地Telnet客户端上远端登录到远程Telnet服务器上。
应用
应用一:实时监听
新建netcat-logger.conf文件
[root@hadoop3 conf]# vim ./netcat-logger.conf
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=netcat
a1.sources.r1.bind=192.168.152.192
a1.sources.r1.port=8888
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sinks.k1.type=logger
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1理解图

开启端口监听方式一
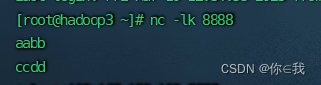
[root@hadoop3 ~]# nc -lk 8888
向访问机发送ccdd
虚拟机再起一个窗口或者从新开一台虚拟机(从开一台虚拟机也需要安装 nc 和 telnet)
访问主机
[root@hadoop3 conf]# telnet 192.168.152.192 8888
向主机发送aabb
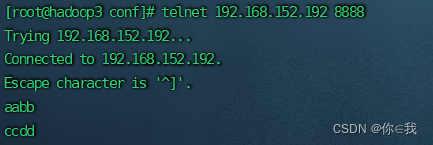
相互发消息接收到则为成功
开启端口监听方式二
[root@hadoop3 flume190]# ./bin/flume-ng agent --name a1 --conf ./conf --conf-file ./conf/netcat-logger.conf -Dflume.root.logger=INFO,console

访问主机
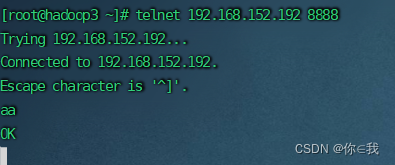
[root@hadoop3 ~]# telnet 192.168.152.192 8888
输入aa,主机收到aa则为成功(见方式二图片)
tail命令
tail 命令可用于查看文件的内容,有一个常用的参数 -f 常用于查阅正在改变的日志文件。
tail -f filename 会把 filename 文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要 filename 更新就可以看到最新的文件内容。
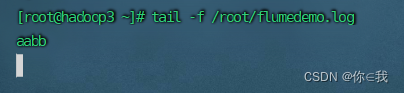
在flumedemo.log里面追加一个aacc
>表示覆盖
>>表示追加

[root@hadoop3 ~]# tail -f /root/flumedemo.log
应用二:读取文件内容输出到控制台
新建ile-flume-logger.conf文件
[root@hadoop3 flume190]# vim ./conf/file-flume-logger.conf
#将指定文件中的内容输出到控制台
a2.sources=r1
a2.sinks=k1
a2.channels=c1
a2.sources.r1.type=exec
a2.sources.r1.command=tail -f /root/flumedemo.log
a2.channels.c1.type=memory
a2.channels.c1.capacity=1000
a2.channels.c1.transactionCapacity=100
a2.sinks.k1.type=logger
a2.sources.r1.channels=c1
a2.sinks.k1.channel=c1
开启端口监听
[root@hadoop3 flume190]# ./bin/flume-ng agent --name a2 --conf ./conf/ --conf-file ./conf/file-flume-logger.conf -Dflume.root.logger=INFO,console
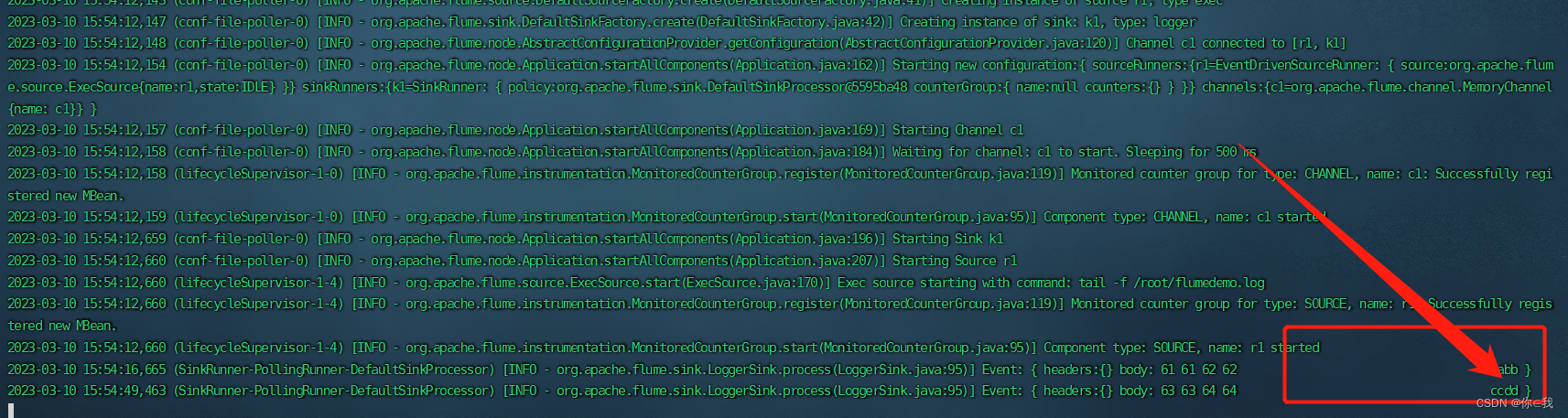
追加信息
[root@hadoop3 ~]# echo 'ccdd' >> ./flumedemo.log
应用三:将文件内容输出到控制台
将events.csv拷贝到虚拟机里面

新建events-flume-logger.conf文件
[root@hadoop3 flume190]# vim ./conf/events-flume-logger.conf
events.sources=eventsSource
events.channels=eventsChannel
events.sinks=eventsSink
events.sources.eventsSource.type=spooldir
events.sources.eventsSource.spoolDir=/opt/flumelogfile/events
events.sources.eventsSource.deserializer=LINE
#最大列数
events.sources.eventsSource.deserializer.maxLineLength=32000
#正则匹配
events.sources.eventsSource.includePattern=events_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
events.channels.eventsChannel.type=file
events.channels.eventsChannel.checkpointDir=/opt/flumelogfile/checkpoint/events
events.channels.eventsChannel.dataDir=/opt/flumelogfile/data/events
events.sinks.eventsSink.type=logger
events.sources.eventsSource.channels=eventsChannel
events.sinks.eventsSink.channel=eventsChannel
启动监听
[root@hadoop3 flume190]# ./bin/flume-ng agent --name events --conf ./conf/ --conf-file ./conf/events-flume-logger.conf -Dflume.root.logger=INFO,console
启动监听后没有动静,因为文件名不对,匹配不上正则表达式,改个名字就好了
改个名字就跑起来了,因为文件很大,跑的时间比较长
修改文件名符合规则
[root@hadoop3 flume190]# mv /opt/flumelogfile/events/events.csv /opt/flumelogfile/events/events_2023-03-08.csv