多线程冲突了怎么办?
-
由于多线程执行操作共享变量可能会导致竞争状态,因此我们将此段代码称为临界区(*critical section*),它是访问共享资源的代码片段,一定不能给多线程同时执行。
我们希望这段代码是互斥(*mutualexclusion*)的,也就说保证一个线程在临界区执行时,其他线程应该被阻止进入临界区,说白了,就是这段代码执行过程中,最多只能出现一个线程。
-
所谓同步,就是并发进程/线程在一些关键点上可能需要互相等待与互通消息,这种相互制约的等待与互通信息称为进程/线程同步。
-
锁机制
使用加锁操作和解锁操作可以解决并发线程/进程的互斥问题。任何想进入临界区的线程,必须先执行加锁操作。若加锁操作顺利通过,则线程可进入临界区;在完成对临界资源的访问后再执行解锁操作,以释放该临界资源。
-
自旋锁
-
CPU 体系结构提供的特殊原子操作指令 —— 测试和置位(*Test-and-Set*)指令。原子操作就是,要么全部执行,要么都不执行,不能出现执行到一半的中间状态。
-
可以用Test-and-Set实现忙等待锁/自旋锁,这是最简单的一种锁,一直自旋,利用 CPU 周期,直到锁可用。在单处理器上,需要抢占式的调度器(即不断通过时钟中断一个线程,运行其他线程)。否则,自旋锁在单 CPU 上无法使用,因为一个自旋的线程永远不会放弃 CPU。
-
-
无等待锁
无等待锁顾明思义就是获取不到锁的时候,不用自旋。既然不想自旋,那当没获取到锁的时候,就把当前线程放入到锁的等待队列,然后执行调度程序,把 CPU 让给其他线程执行。
-
信号量
通常信号量表示资源的数量,对应的变量是一个整型(
sem)变量。另外,还有两个原子操作的系统调用函数来控制信号量的,分别是:
- P 操作:将 sem 减 1,相减后,如果
sem < 0,则进程/线程进入阻塞等待,否则继续,表明 P 操作可能会阻塞; - V 操作:将 sem 加 1,相加后,如果
sem <= 0,唤醒一个等待中的进程/线程,表明 V 操作不会阻塞;
PV 操作的函数是由操作系统管理和实现的,所以操作系统已经使得执行 PV 函数时是具有原子性的。
- P 操作:将 sem 减 1,相减后,如果
-
生产者-消费者问题
- 生产者在生成数据后,放在一个缓冲区中;
- 消费者从缓冲区取出数据处理;
- 任何时刻,只能有一个生产者或消费者可以访问缓冲区;
对问题分析可以得出:
-
任何时刻只能有一个线程操作缓冲区,说明操作缓冲区是临界代码,需要互斥;
-
缓冲区空时,消费者必须等待生产者生成数据;缓冲区满时,生产者必须等待消费者取出数据。说明生产者和消费者需要同步。
使用三个信号量,就可以实现同步和互斥。
-
互斥信号量
mutex:用于互斥访问缓冲区,初始化值为 1;(保证两个线程互斥) -
资源信号量
fullBuffers:用于消费者询问缓冲区是否有数据,有数据则读取数据,初始化值为 0(表明缓冲区一开始为空); -
资源信号量
emptyBuffers:用于生产者询问缓冲区是否有空位,有空位则生成数据,初始化值为 n (缓冲区大小);

-
两个经典同步的问题
-
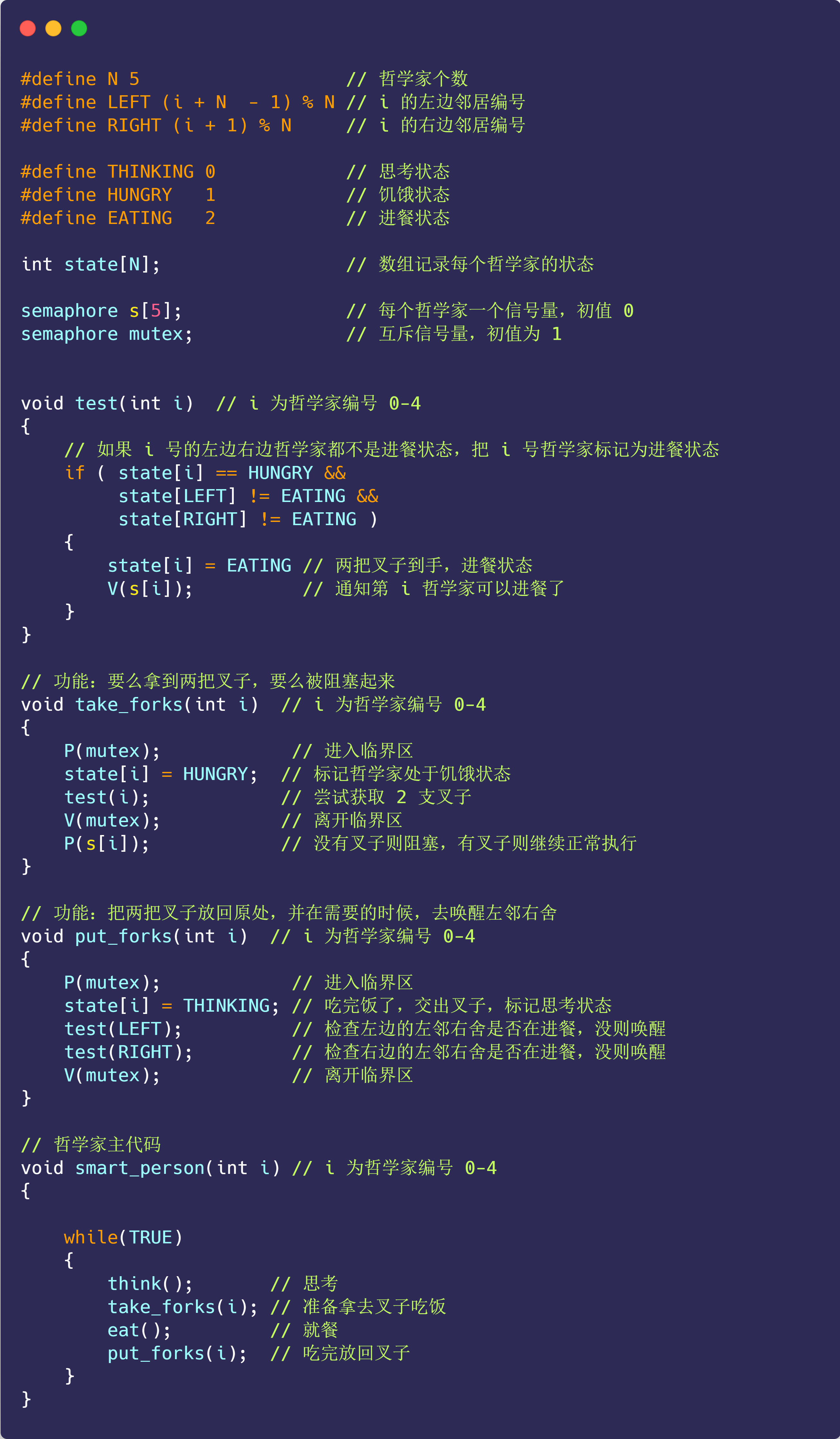
哲学家就餐问题
5个老大哥哲学家,闲着没事做,围绕着一张圆桌吃面;- 巧就巧在,这个桌子只有
5支叉子,每两个哲学家之间放一支叉子; - 哲学家围在一起先思考,思考中途饿了就会想进餐;
- 奇葩的是,这些哲学家要两支叉子才愿意吃面,也就是需要拿到左右两边的叉子才进餐;
- 吃完后,会把两支叉子放回原处,继续思考;
使用互斥信号量mutex,初始值为1,要么拿到两把叉子或放回两把叉子的过程是互斥的。拿叉子时不能尝试返回叉子。
s[i]信号量,来表示第i个哲学家是否可以进餐。
我们还用一个数组 state 来记录每一位哲学家的三个状态,分别是在进餐状态、思考状态、饥饿状态(正在试图拿叉子)。
那么,一个哲学家只有在两个邻居都没有进餐时,才可以进入进餐状态。
第
i个哲学家的左邻右舍,则由宏LEFT和RIGHT定义:比如 i 为 2,则LEFT为 1,RIGHT为 3。
具体代码实现如下:
-
读者-写者问题
前面的「哲学家进餐问题」对于互斥访问有限的竞争问题(如 I/O 设备)一类的建模过程十分有用。
另外,还有个著名的问题是「读者-写者」,它为数据库访问建立了一个模型。
读者只会读取数据,不会修改数据,而写者即可以读也可以修改数据。
读者-写者的问题描述:
- 「读-读」允许:同一时刻,允许多个读者同时读
- 「读-写」互斥:没有写者时读者才能读,没有读者时写者才能写
- 「写-写」互斥:没有其他写者时,写者才能写
公平策略:
-
优先级相同;
-
写者、读者互斥访问;
-
只能一个写者访问临界区;
-
可以有多个读者同时访问临界资源;
怎么避免死锁?
那么,当两个线程为了保护两个不同的共享资源而使用了两个互斥锁,那么这两个互斥锁应用不当的时候,可能会造成两个线程都在等待对方释放锁,在没有外力的作用下,这些线程会一直相互等待,就没办法继续运行,这种情况就是发生了死锁。
-
死锁只有同时满足以下四个条件才会发生:
-
互斥条件;
- 互斥条件是指多个线程不能同时使用同一个资源。
-
持有并等待条件;
- 当线程 A 已经持有了资源 1,又想申请资源 2,而资源 2 已经被线程 C 持有了,所以线程 A 就会处于等待状态,但是线程 A 在等待资源 2 的同时并不会释放自己已经持有的资源 1。
-
不可剥夺条件;
- 不可剥夺条件是指,当线程已经持有了资源 ,在自己使用完之前不能被其他线程获取,线程 B 如果也想使用此资源,则只能在线程 A 使用完并释放后才能获取。
-
环路等待条件;
- 环路等待条件指的是,在死锁发生的时候,两个线程获取资源的顺序构成了环形链。比如,线程 A 已经持有资源 2,而想请求资源 1, 线程 B 已经获取了资源 1,而想请求资源 2,这就形成资源请求等待的环形图。
-
-
避免死锁问题的发生
所以要避免死锁问题,就是要破坏其中一个条件即可,最常见的并且可行的就是使用资源有序分配法,来破环环路等待条件。
什么是悲观锁、乐观锁?
-
互斥锁与自旋锁
最底层的两种就是会「互斥锁和自旋锁」,有很多高级的锁都是基于它们实现的。
当已经有一个线程加锁后,其他线程加锁则就会失败,互斥锁和自旋锁对于加锁失败后的处理方式是不一样的:
-
互斥锁加锁失败后,线程会释放 CPU ,给其他线程;
- 互斥锁是一种「独占锁」,比如当线程 A 加锁成功后,此时互斥锁已经被线程 A 独占了,只要线程 A 没有释放手中的锁,线程 B 加锁就会失败,于是就会释放 CPU 让给其他线程,既然线程 B 释放掉了 CPU,自然线程 B 加锁的代码就会被阻塞。
-
自旋锁加锁失败后,线程会忙等待,直到它拿到锁;
- 使用自旋锁的时候,当发生多线程竞争锁的情况,加锁失败的线程会「忙等待」,直到它拿到锁。这里的「忙等待」可以用
while循环等待实现,不过最好是使用 CPU 提供的PAUSE指令来实现「忙等待」,因为可以减少循环等待时的耗电量。
- 使用自旋锁的时候,当发生多线程竞争锁的情况,加锁失败的线程会「忙等待」,直到它拿到锁。这里的「忙等待」可以用
-
-
自旋锁or互斥锁?
-
互斥锁会存在两次线程上下文切换的成本
- 当线程加锁失败时,内核会把线程的状态从「运行」状态设置为「睡眠」状态,然后把 CPU 切换给其他线程运行;
- 接着,当锁被释放时,之前**「睡眠」状态的线程会变为「就绪」状态**,然后内核会在合适的时间,把 CPU 切换给该线程运行。
-
如果锁住的代码执行时间比较短,那可能上下文切换的时间可能比锁住代码执行时间更长。所以,如果你能确定被锁住的代码执行时间很短,就不应该用互斥锁,而应该选用自旋锁,否则使用互斥锁。
-
自旋锁是通过 CPU 提供的
CAS函数(Compare And Swap),在「用户态」完成加锁和解锁操作,不会主动产生线程上下文切换,所以相比互斥锁来说,会快一些,开销也小一些。 -
自旋锁与互斥锁使用层面比较相似,但实现层面上完全不同:当加锁失败时,互斥锁用「线程切换」来应对,自旋锁则用「忙等待」来应对。
-
需要注意,在单核 CPU 上,需要抢占式的调度器(即不断通过时钟中断一个线程,运行其他线程)。否则,自旋锁在单 CPU 上无法使用,因为一个自旋的线程永远不会放弃 CPU。
-
-
读写锁
读写锁从字面意思我们也可以知道,它由「读锁」和「写锁」两部分构成,如果只读取共享资源用「读锁」加锁,如果要修改共享资源则用「写锁」加锁。所以,读写锁适用于能明确区分读操作和写操作的场景。
-
读写锁的工作原理是:
-
**读锁是共享锁。**当「写锁」没有被线程持有时,多个线程能够并发地持有读锁,这大大提高了共享资源的访问效率,因为「读锁」是用于读取共享资源的场景,所以多个线程同时持有读锁也不会破坏共享资源的数据。
-
**写锁是独占锁。**一旦「写锁」被线程持有后,读线程的获取读锁的操作会被阻塞,而且其他写线程的获取写锁的操作也会被阻塞。
读写锁在读多写少的场景,能发挥出优势。
-
-
根据实现的不同,读写锁可以分为「读优先锁」和「写优先锁」。
-
读优先锁期望的是,读锁能被更多的线程持有,以便提高读线程的并发性。当读线程 A 先持有了读锁,写线程 B 在获取写锁的时候,会被阻塞,并且在阻塞过程中,后续来的读线程 C 仍然可以成功获取读锁,最后直到读线程 A 和 C 释放读锁后,写线程 B 才可以成功获取写锁。
-
而「写优先锁」是优先服务写线程。当读线程 A 先持有了读锁,写线程 B 在获取写锁的时候,会被阻塞,并且在阻塞过程中,后续来的读线程 C 获取读锁时会失败,于是读线程 C 将被阻塞在获取读锁的操作,这样只要读线程 A 释放读锁后,写线程 B 就可以成功获取写锁。
公平读写锁比较简单的一种方式是:用队列把获取锁的线程排队,不管是写线程还是读线程都按照先进先出的原则加锁即可,这样读线程仍然可以并发,也不会出现「饥饿」的现象。
-
-
悲观锁
悲观锁做事比较悲观,它认为多线程同时修改共享资源的概率比较高,于是很容易出现冲突,所以访问共享资源前,先要上锁。
那相反的,如果多线程同时修改共享资源的概率比较低,就可以采用乐观锁。
-
乐观锁
乐观锁做事比较乐观,它假定冲突的概率很低,它的工作方式是:先修改完共享资源,再验证这段时间内有没有发生冲突,如果没有其他线程在修改资源,那么操作完成,如果发现有其他线程已经修改过这个资源,就放弃本次操作。
可见,乐观锁的心态是,不管三七二十一,先改了资源再说。另外,你会发现乐观锁全程并没有加锁,所以它也叫无锁编程。
乐观锁虽然去除了加锁解锁的操作,但是一旦发生冲突,重试的成本非常高,所以只有在冲突概率非常低,且加锁成本非常高的场景时,才考虑使用乐观锁。
不管使用的哪种锁,我们的加锁的代码范围应该尽可能的小,也就是加锁的粒度要小,这样执行速度会比较快。再来,使用上了合适的锁,就会快上加快了。
一个进程最多可以创建多少个线程?
-
这个问题跟两个东西有关系:
-
进程的虚拟内存空间上限,因为创建一个线程,操作系统需要为其分配一个栈空间,如果线程数量越多,所需的栈空间就要越大,那么虚拟内存就会占用的越多。
-
系统参数限制,虽然 Linux 并没有内核参数来控制单个进程创建的最大线程个数,但是有系统级别的参数来控制整个系统的最大线程个数。
-
-
实践:
-
我们可以执行 ulimit -a 这条命令,查看进程创建线程时默认分配的栈空间大小。在前面我们知道,在 32 位 Linux 系统里,一个进程的虚拟空间是 4G,内核分走了1G,留给用户用的只有 3G。那么假设创建一个线程需要占用 10M 虚拟内存,总共有 3G 虚拟内存可以使用。于是我们可以算出,最多可以创建差不多 300 个(3G/10M)左右的线程。
-
下面这三个内核参数的大小,都会影响创建线程的上限:
-
/proc/sys/kernel/threads-max,表示系统支持的最大线程数,默认值是
14553; -
/proc/sys/kernel/pid_max,表示系统全局的 PID 号数值的限制,每一个进程或线程都有 ID,ID 的值超过这个数,进程或线程就会创建失败,默认值是
32768; -
/proc/sys/vm/max_map_count,表示限制一个进程可以拥有的VMA(虚拟内存区域)的数量,如果它的值很小,也会导致创建线程失败,默认值是
65530。
-
-
-
总结:
-
32 位系统,用户态的虚拟空间只有 3G,如果创建线程时分配的栈空间是 10M,那么一个进程最多只能创建 300 个左右的线程。
-
64 位系统,用户态的虚拟空间大到有 128T,理论上不会受虚拟内存大小的限制,而会受系统的
-
线程崩溃了,进程也会崩溃吗?
-
如果线程是因为非法访问内存引起的崩溃,那么进程肯定会崩溃,为什么系统要让进程崩溃呢,这主要是因为在进程中,各个线程的地址空间是共享的,既然是共享,那么某个线程对地址的非法访问就会导致内存的不确定性,进而可能会影响到其他线程,这种操作是危险的,操作系统会认为这很可能导致一系列严重的后果,于是干脆让整个进程崩溃。
-
非法访问的情况:对只读内存进行写入、访问进程没有权限访问的地址(比如内核空间)、访问不存在的内存。
-
进程是如何崩溃的?
操作系统使用信号来让进程崩溃。
背后的机制如下:
- CPU 执行正常的进程指令
- 调用 kill 系统调用向进程发送信号
- 进程收到操作系统发的信号,CPU 暂停当前程序运行,并将控制权转交给操作系统
- 调用 kill 系统调用向进程发送信号(假设为 11,即 SIGSEGV,一般非法访问内存报的都是这个错误)
- 操作系统根据情况执行相应的信号处理程序(函数),一般执行完信号处理程序逻辑后会让进程退出。
-
为什么线程崩溃不会导致JVM进程崩溃?
因为 JVM 自定义了自己的信号处理函数,拦截了 SIGSEGV 信号,针对这两者不让它们崩溃。
在启动 JVM 的时候,也设置了信号处理函数,收到 SIGSEGV,SIGPIPE 等信号后最终会调用
JVM_handle_linux_signal这个自定义信号处理函数。恢复了线程的执行,并抛出 StackoverflowError 和 NPE,这就是为什么 JVM 不会崩溃且我们能捕获这两个错误/异常的原因。如果 JVM 不对信号做额外的处理,最后会自己退出并产生 crash 文件 hs_err_pid_xxx.log(可以通过 -XX:ErrorFile=/var/*log*/hs_err.log 这样的方式指定),这个文件记录了虚拟机崩溃的重要原因。
KMP
KMP的主要思想是当出现字符串不匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头再去做匹配了。
前缀:不包含最后一个字符的,所有以第一个字符开头的连续子串。
后缀:不包含第一个字符的,所有以最后一个字符结尾的连续子串。
前缀表的作用:记录了模式串与主串不匹配时,模式串从哪里开始匹配的问题(跳到之前已经匹配过的地方)
前缀表的原理:找到最长相等的前缀和后缀,失败的位置是后缀子串的后面,所以找当相同的前缀的后面重新匹配。
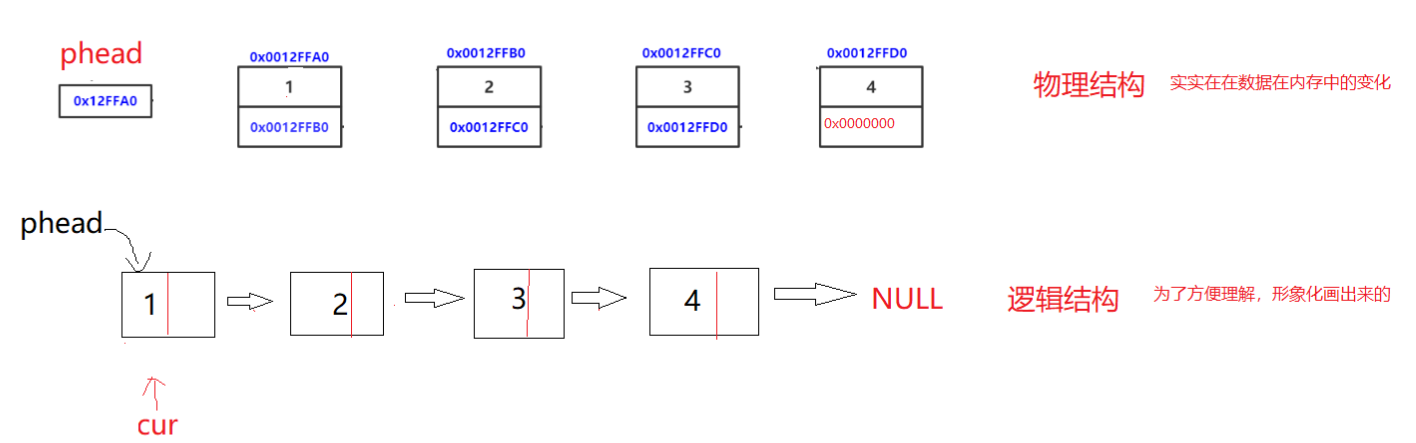
前缀表的实现:模式表与前缀表对应位置的数字表示:下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。
前缀表的使用:
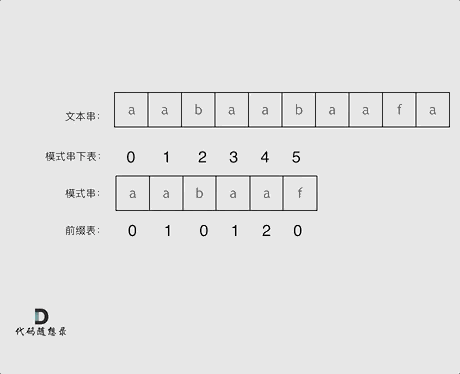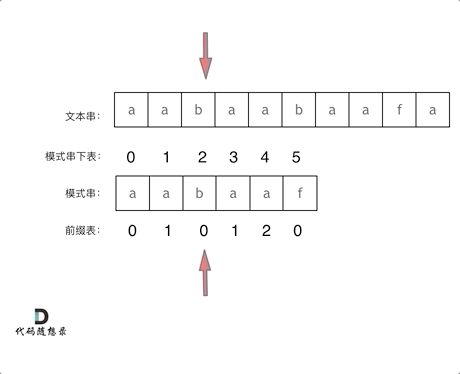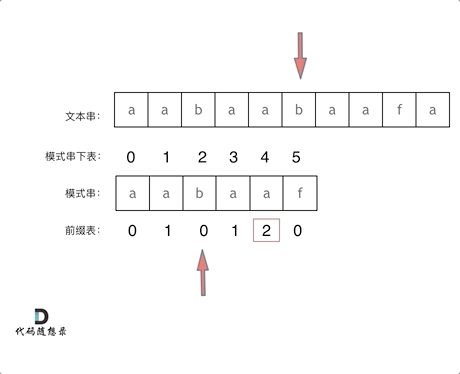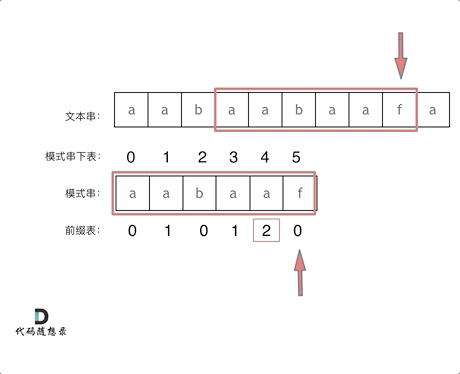
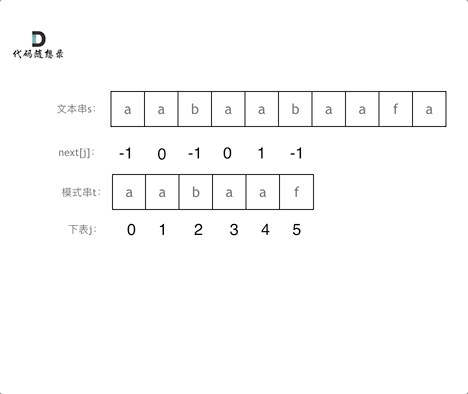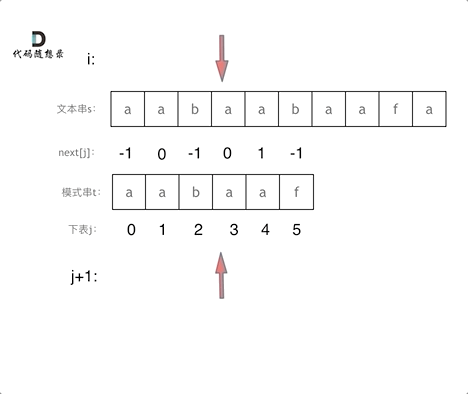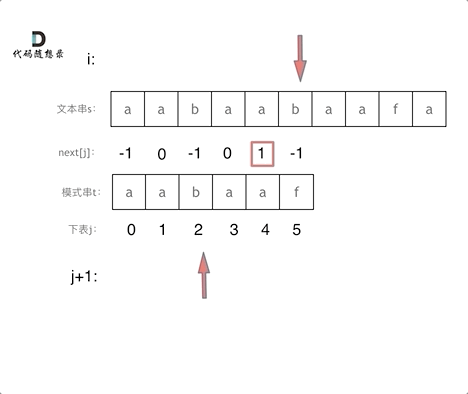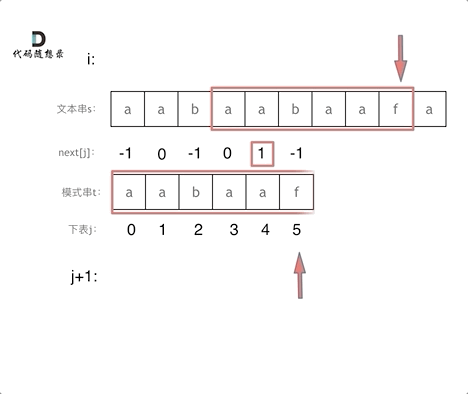
找到的不匹配的位置, 那么此时我们要看它的前一个字符的前缀表的数值是多少。
为什么要前一个字符的前缀表的数值呢,因为要找前面字符串的最长相同的前缀和后缀。
所以要看前一位的 前缀表的数值。
前一个字符的前缀表的数值是2, 所以把下标移动到下标2的位置继续比配。 可以再反复看一下上面的动画。
最后就在文本串中找到了和模式串匹配的子串了。
next数组:next数组既可以就是前缀表,也可以是前缀表统一减一(右移一位,初始位置为-1)。
KMP时间复杂度分析:
其中n为文本串长度,m为模式串长度,因为在匹配的过程中,根据前缀表不断调整匹配的位置,可以看出匹配的过程是O(n),之前还要单独生成next数组,时间复杂度是O(m)。所以整个KMP算法的时间复杂度是O(n+m)的。
暴力的解法显而易见是O(n × m),所以KMP在字符串匹配中极大地提高了搜索的效率。
例题:28. 找出字符串中第一个匹配项的下标 - 力扣(LeetCode)
-
构造next数组
定义两个指针i和j,j指向前缀末尾位置,i指向后缀末尾位置。
next数组初始化
int j = -1; next[0] = j;处理前后缀不同的情况
for (int i = 1; i < s.size(); i++) { while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了 j = next[j]; // 向前回退 } }处理前后缀相同的情况
if (s[i] == s[j + 1]) { // 找到相同的前后缀 j++; } next[i] = j; -
使用next数组进行匹配
在文本串s里 找是否出现过模式串t。
定义两个下标,j 指向模式串起始位置,i 指向文本串起始位置。
那么j初始值依然为-1,为什么呢? 依然因为next数组里记录的起始位置为-1。
i就从0开始,遍历文本串,代码如下:
for (int i = 0; i < s.size(); i++)接下来就是 s[i] 与 t[j + 1] (因为j从-1开始的) 进行比较。
如果 s[i] 与 t[j + 1] 不相同,j就要从next数组里寻找下一个匹配的位置。
while(j >= 0 && s[i] != t[j + 1]) { j = next[j]; }如果 s[i] 与 t[j + 1] 相同,那么i 和 j 同时向后移动, 代码如下:
if (s[i] == t[j + 1]) { j++; // i的增加在for循环里 }如何判断在文本串s里出现了模式串t呢,如果j指向了模式串t的末尾,那么就说明模式串t完全匹配文本串s里的某个子串了。
本题要在文本串字符串中找出模式串出现的第一个位置 (从0开始),所以返回当前在文本串匹配模式串的位置i 减去 模式串的长度,就是文本串字符串中出现模式串的第一个位置。
代码如下:
if (j == (t.size() - 1) ) { return (i - t.size() + 1); }
class Solution {
int [] next = new int [10001];
public int strStr(String haystack, String needle) {
char c1 [] = haystack.toCharArray();
char c [] = needle.toCharArray();
getNext(needle);
int j = - 1;
for(int i = 0 ; i < c1.length ; i ++){
while(j >= 0 && c1[i] != c[j + 1]){
j = next[j];
}
if(c1[i] == c[j + 1]){
j ++;
}
if(j == (c.length - 1)){
return i - c.length + 1;
}
}
return -1;
}
void getNext(String needle){
char ch [] = needle.toCharArray();
int j = - 1;
next[0] = j;
for(int i = 1 ; i < needle.length() ; i ++){
while(j >= 0 && ch[i] != ch[j + 1]){
j = next[j];
}
if(ch[i] == ch[j + 1]){
j ++;
}
next[i] = j;
}
}
}
-
459. 重复的子字符串 - 力扣(LeetCode)
解法一:KMP算法
一个字符串的内部由重复的子串组成,前面有相同的子串,后面有相同的子串,用 s + s,这样组成的字符串中,后面的子串做前串,前后的子串做后串,就一定还能组成一个s。
class Solution { public boolean repeatedSubstringPattern(String s) { String str = s + s; int [] next = getNum(s); int j = -1; //不从头尾开始查找,如果中间出现相同的字符串,就返回true。 for(int i = 1 ; i < str.length() - 1 ; i ++){ while(j >= 0 && str.charAt(i) != s.charAt(j + 1)){ j = next[j]; } if(str.charAt(i) == s.charAt(j + 1)){ j ++; } if(j == s.length() - 1){ return true; } } return false; } int [] getNum(String s){ char ch [] = s.toCharArray(); int [] next = new int [ch.length]; int j = -1; next[0] = j; for(int i = 1 ; i < ch.length ; i ++){ while(j >= 0 && ch[i] != ch[j + 1]){ j = next[j]; } if(ch[i] == ch[j + 1]){ j++; } next[i] = j; } return next; } }