实现高可用方案
- 首先了解一下高可用集群
- 高可用:透明切换,故障切换,连接管理器/集群管理器
- pgpool-Ⅱ:连接池、复制、负载均衡功能
- Patroni
- Corosync+pacemaker高可用解决方案
- Corosync
- pacemaker
- corosync+pacemaker架构协作
- 资源分配:设置资源倾向性(实现负载均衡功能)
系列文章
keepalived学习记录:对其vip漂移过程采用gdb跟踪
Keepalived与HaProxy的协调合作原理分析
Oracle实现高可用性的工具(负载均衡/故障切换)
达梦实现高可用性的实现(failover功能/负载均衡/虚拟ip透明切换)
PG数据库实现高可用方案(包括通用型方案Corosync+pacemaker协作)
首先了解一下高可用集群
在传统Linux集群种类,主要分了三类,
一类是LB集群,这类集群主要作用是对用户的流量做负载均衡,让其后端每个server都能均衡的处理一部分请求;这类集群有一个特点就是前端调度器通常是单点,后端server有很多台,即便某一台后端server挂掉,也不影响用户的请求;
其次就是HA集群,所谓ha集群就是高可用集群,这类集群的主要作用是对集群中的单点做高可用,所谓高可用就是在发生故障时,能够及时的将故障转移,从而使故障修复时间最小;这类集群的特点是在多台节点上,各空闲节点会一直盯着工作节点,工作节点也会基于多播或广播的方式把自己的心跳信息发送给其他空闲节点,一旦工作节点的心跳信息在一定时间内空闲节点没有收到,那么此时就会触发资源抢占,先抢到资源的成为新的工作节点,而其他节点又会一直盯着新的工作节点,直到它挂掉,然后再次触发资源抢占;这类集群的特点就是一个节点工作,其他节点看着它工作,一旦工作节点挂了,立刻会有其他节点上来顶替它的工作;
最后就是HP集群,HP集群主要用于在复杂计算中场景中,把多台server的算力综合一起,对复杂计算要求比较高的环境中使用;
在生产环境中常见的LB和HA集群较多。
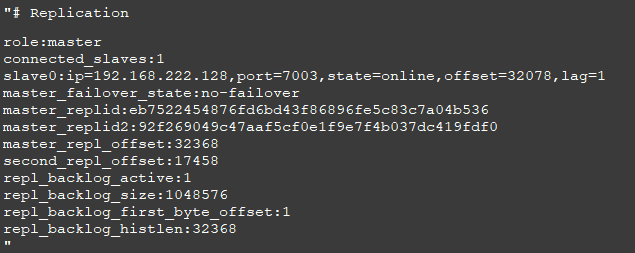
高可用:透明切换,故障切换,连接管理器/集群管理器
connect manager/cluster manager
pgpool-Ⅱ:连接池、复制、负载均衡功能
位于数据库服务器与客户端的中间层(中间件)
连接池:pgpool 提供连接池功能,降低建立连接带来的开销,同时增加系统的吞吐量
负载均衡:它的负载均衡适用于只读场景。
当数据库运行在复制模式或主备模式下,SELECT语句运行在集群中任何一个节点都能返回一致的结果,pgpool能将查询语句分发到集群的各个数据库中,从而提升系统的吞吐量。
高可用:当集群中的主库不可用时,pgpool 能够探测到并且激活备库,实现故障转移。
限制超过限度的连接:PostgreSQL支持限制当前最大的连接数,拒绝新连接。pgpool-Ⅱ也支持限制最大连接数,它将超过限制的连接放入队列而不是立即返回一个错误。
客户端连接到pgpool-Ⅱ上,就于连接到数据库上完全一样。pgpool-Ⅱ的复制是同步的,即如果客户端发送一个DML语句,将并发地在后端所有数据库上执行,保证所有数据库的一致性。
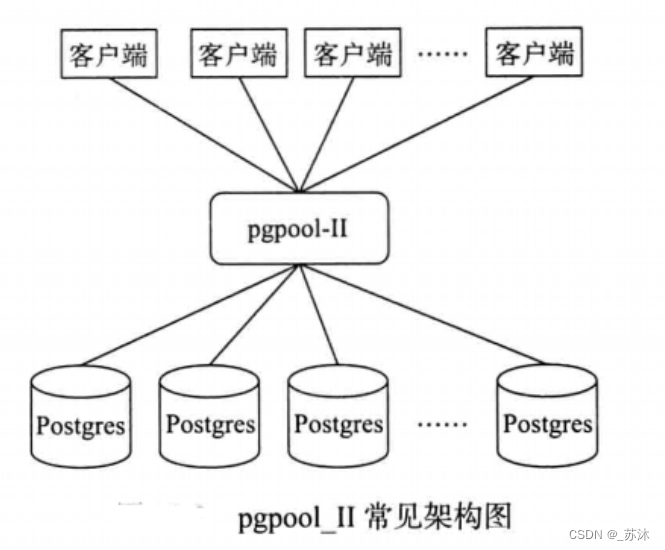
pgpool-Ⅱ包括对于pg数据库的健康检查功能。整个架构属于多进程架构。
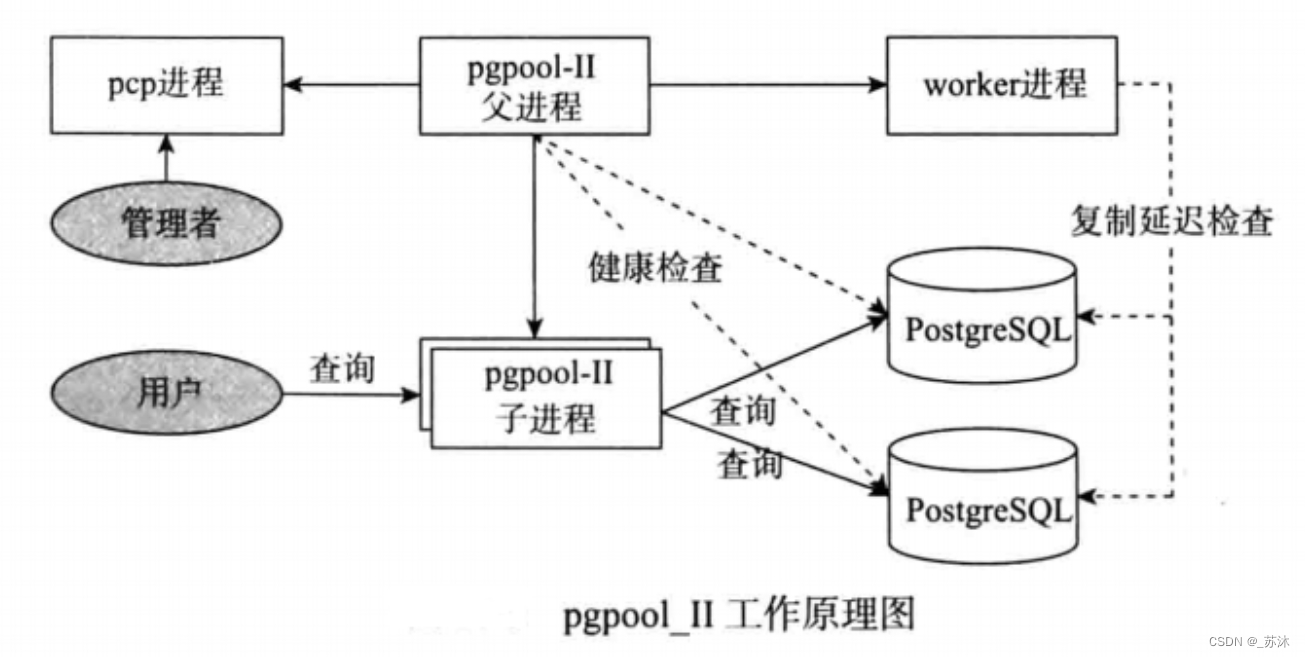
pcp进程:pcp是一个管理工具,向pgpool-Ⅱ发送管理命令
pgpool-Ⅱ父进程:负责检查各个底层数据库的健康状态
pgpool-Ⅱ子进程:负责接收用户发送过来的SQL请求,然后根据规则发送到底层数据库上,实现的是负载均衡作用
worker进程:负责检查底层数据库之间的复制延迟
pgpool-Ⅱ存在多种工作模式。
- 原始模式:只有faliober功能。对于后端多个数据库进行故障切换。此时的数据库同步功能由用户负责。
- 连接池模式:实现连接池的功能和原始模式的故障切换功能。
- 内置复制模式:这种模式下pgpool负责后端数据库数据同步,pgpool节点上的写操作需等待所有后端数据库将数据写入后才向客户端返回成功,是强同步复制方式,实现负载均衡功能。
- 主备模式:中间件层使用pgpool-Ⅱ,pgpool提供高可用和连接池的功能。
配合流复制的主备模式:使用PostgreSQL流复制方式,PostgreSQL流复制负责pgpool后端数据库数据同步,对应的配置文件为$prefix/etc/pgpool.conf.sample-stream,这种模式支持负载均衡。pgpool+pg复制实现高可用解决方案 - 并行模式:实现查询的并行执行。并行模式不能与主备模式同时使用。
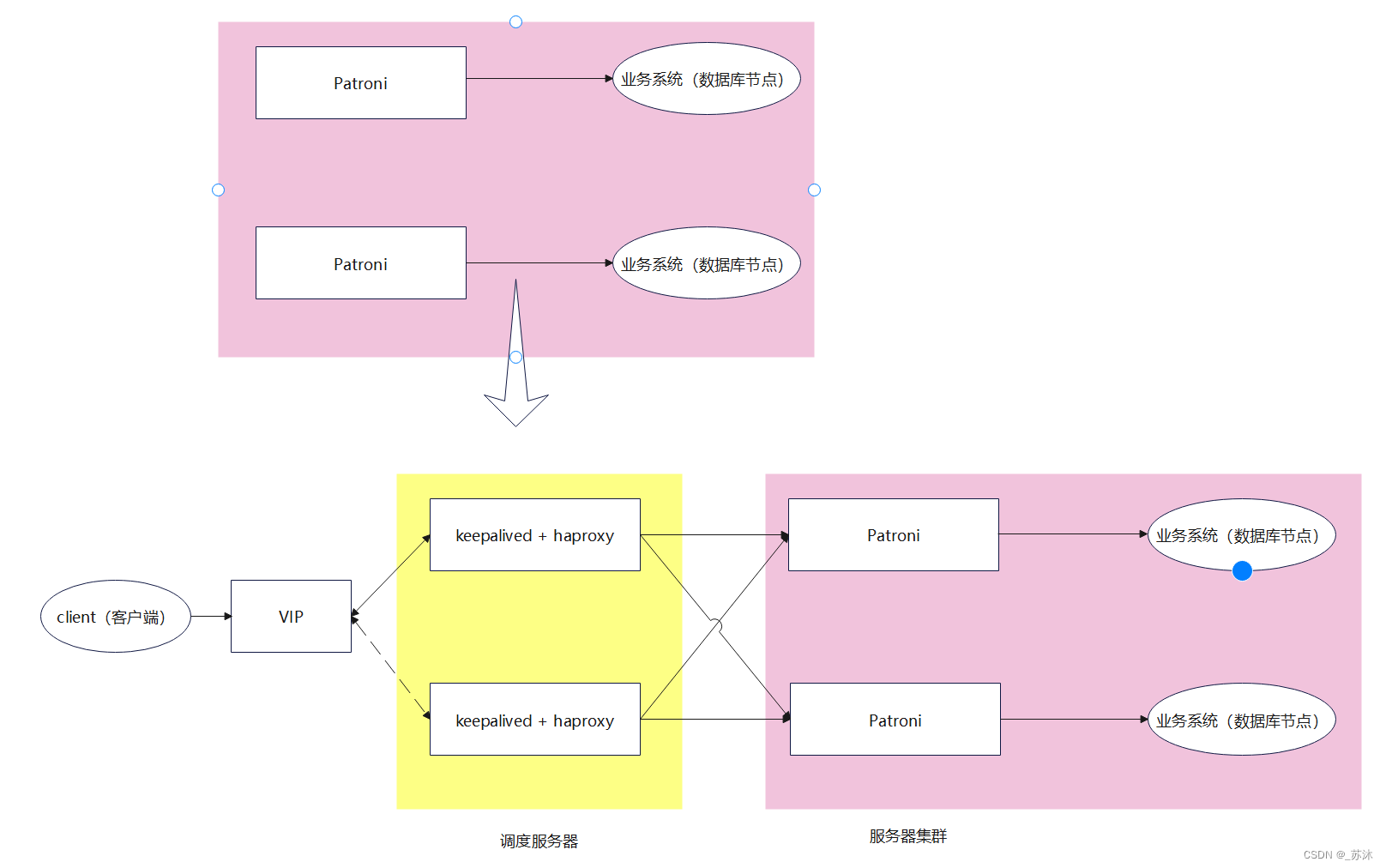
对于pgpool这个中间件,要考虑它坏掉之后对于客户端连接数据库的影响,可以引入多个pgpool,基于vip进行切换。
上面提到的这个方案是传统的方案,读写分离时性能会折损30%。
Patroni
基于vip切换时,是将vip主切换成vip从,域名为客户端 有缓存 切换后不能立即生效。
整体架构如下: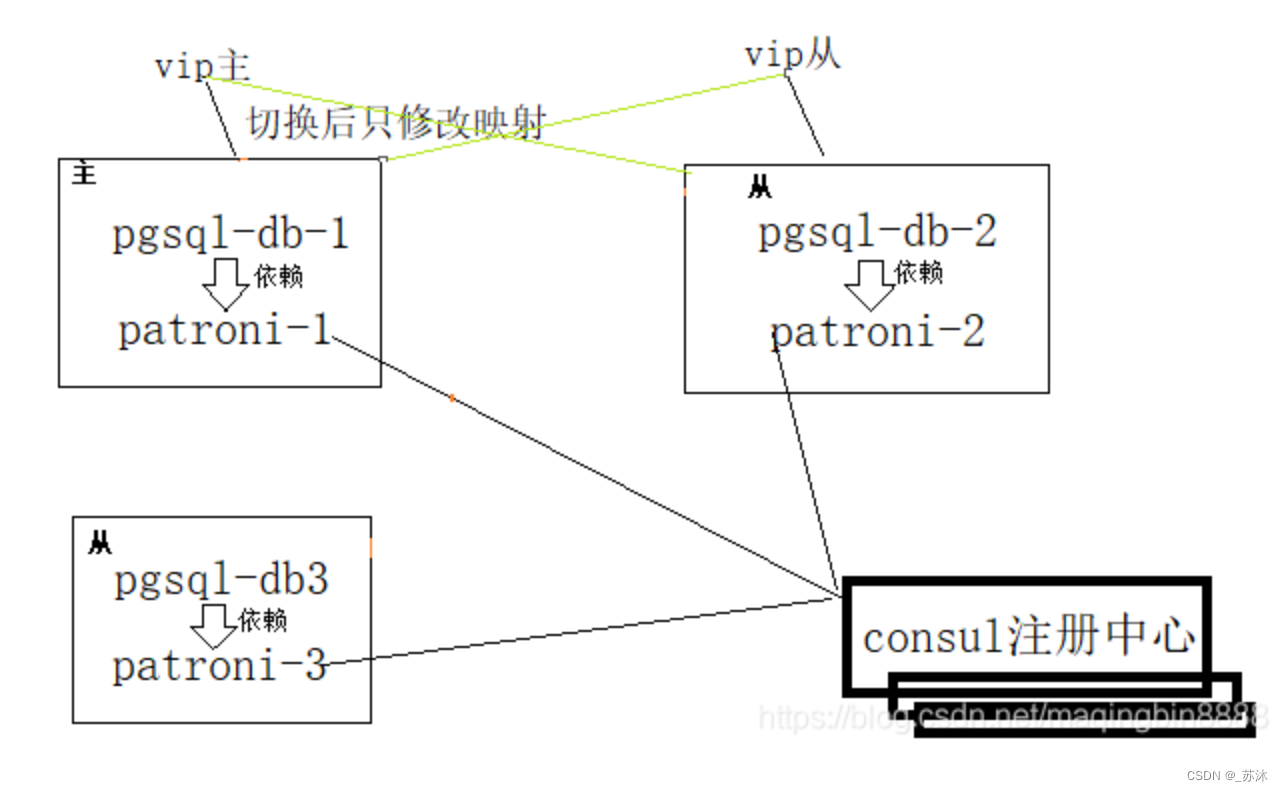
基于前面博客中提到的keepalived+haproxy架构,可以解决当前架构中跨网段和域名缓存的问题。又加入一层。
引入consul注册中心 每台机器上部署patroni-agent
patroni特性:
- 每一个patroni都会管理pg的信息拉起集群并将注册到consul中。 (起到的是集群管理作用)
- patroni与pg捆绑强依赖,两个属于一台服务器,且信息配置在pg上,宕机时两个服务一起宕机。
- patroni通过心跳与consul保持连接以达到掉线后故障发现,(节点间通信)
- leader定时到期后重新选主,如果你已经是主始终在线下次选主优先
主从切换过程:(集群管理部分)
patroni确定它连接的库故障时,避免产生脑裂,会通过kill命令杀死pg进程。
如果杀不掉,通过linux,watch dog直接重启,干掉主(这里不理解)
然后通过查看资料,看到:这里面将主干掉,就是避免出现脑裂的情况。对于ABC三台机器,发生了网络分区,a挂了(有可能仅是网络故障),bc当前认为a挂了,会将vip抢过来,而a认为自己没有挂,会来回争抢,造成集群的不稳定性。所以当bc都投票觉得a挂的时候,会将a干掉,即使a是存活状态,避免产生脑裂。
选出回放最快的从库 通过对比lsn的坐标谁最大谁就是新的主库。
Corosync+pacemaker高可用解决方案
Corosync
实现HA心跳信息传输的功能就是Corosync。
Coreosync在传递信息的时候可以通过一个简单的配置文件来定义信息传递的方式和协议等。
pacemaker
pacemaker是一个开源的高可用资源管理器(CRM),位于HA集群架构中资源管理、资源代理(RA)这个层次,它不能提供底层心跳信息传递的功能,要想与对方节点通信需要借助底层的心跳传递服务。
corosync+pacemaker架构协作
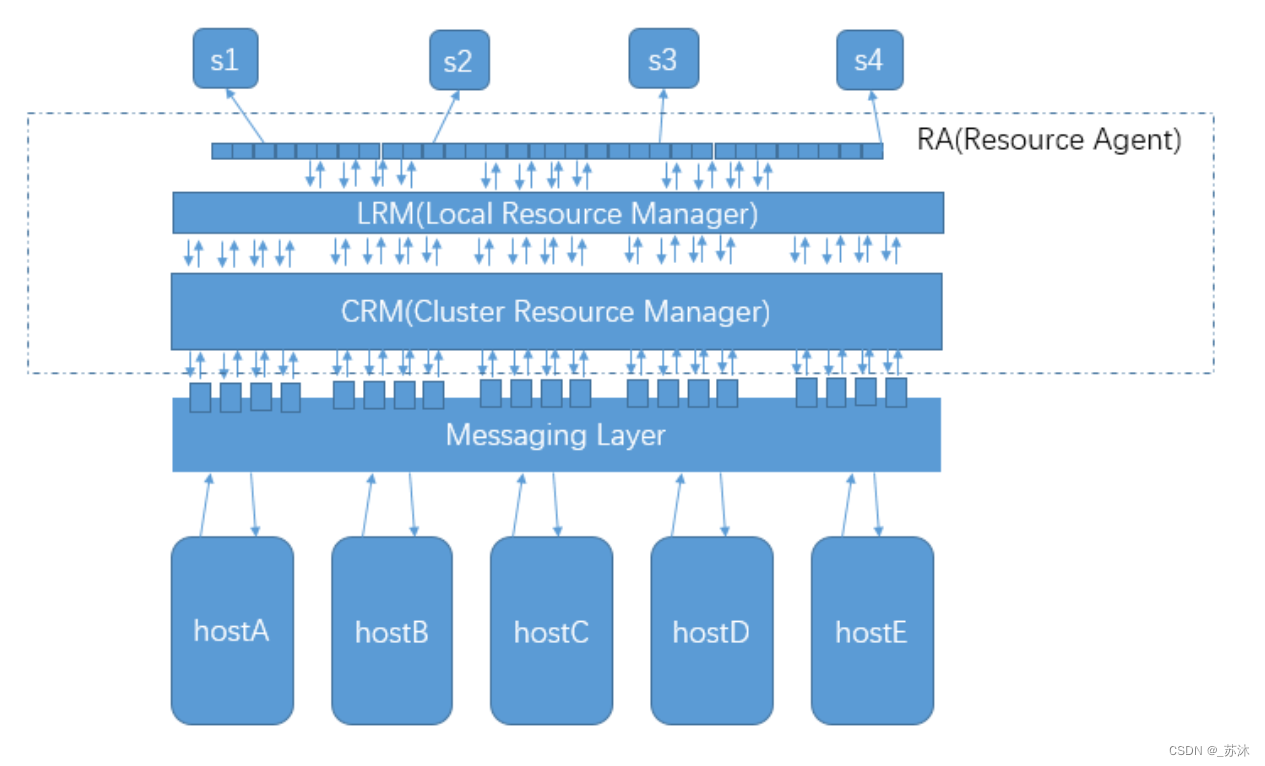
corosync的主要作用是提供messaging Layer,这个消息传递层的主要作用是,把个主机间的各状态信息,空闲信息等等一系列信息通过消息传递层互相传递,使得托管在corosync上的服务能够根据底层各主机传递的消息来决定,该服务该运行到那台主机上,一旦运行服务的主机发生故障时,它们又能够根据消息传递层的消息,来判断该把服务迁移到那台主机上运行;这样一来托管在corosync上的服务,就实现了高可用;
简单点讲,托管在corosync之上的服务对底层主机是不可见的,这也意味着托管在corosync上的服务是能够调用和理解Messaging Layer中的消息;这样一来托管在上面的服务就必须得提供接口来调用messaging Layer对外提供的接口,然后实现服务的迁移;
而对于大多数程序来讲,它根本就没有这样的接口,这样一来我们要使用corosync实现服务高可用就变得困难;为了解决托管在corosync的服务能够调用corosync提供的接口,我们需要开发一个中间件,让这个中间件能够向下理解和调用coroysnc提供的接口,向上能够托管服务;
这个中间层就是pacemaker;它的主要作用是通过调用corosync提供的接口,来判断把集群资源该怎么分配,服务该怎么迁移和运行;同时pacemaker还提供一个管理界面,能够让管理员来管理这些集群资源;
而对于pacemaker来讲,它主要有3个层次,其中CRM(cluster resource manager)的主要作用是通过调用messaging Layer提供的接口和各节点的状态信息来决策集群资源的管理;然后通过接口把决策信息传递给LRM(local resource manager);LRM的主要作用是对本地的资源做各种管理;而对于LRM来讲,它要怎么管理本地资源呢?它通常不会自己去管理本地资源,而是通过委派RA去管理,所谓RA(resource agent)就是资源代理;它会根据LRM发送的信息来对本地资源进行管理,而这种管理通常是基于各种服务提供的起停脚本来实现的;
资源分配:设置资源倾向性(实现负载均衡功能)
什么叫资源倾向性呢?我们知道一个资源托管在corosync+pacemaker上,最终都会把资源落在某一个节点上运行,而我们怎么来限制这些资源在那个或那些各节点上运行呢?这个就需要我们配置资源对节点的倾向性了;所谓倾向性就是该资源更加倾向在那个节点运行或更加讨厌在那个节点上运行;在corosync+pacemaker集群上运行资源的方式有3中,N-1、N-M、N-N,其中N表示节点数量,M表示资源数量;N-1表示N个节点上运行1个资源;这也意味有N减1个节点是处于空闲待命状态,这对于服务器的资源利用率有点浪费;
所以对于corosync+pacemaker集群和keepalived来讲,keepalived更加轻量化;
这句话不是很理解,轻量化是什么意思?可能是更易于配置,按照,对其他的工具没有什么影响?但是与资源的关系是什么?
N-M表示N个节点上运行M个资源,通常M小于N;这意味着有N减M个节点冗余;N-N表示N个节点上运行N个资源,没有冗余节点,这意味着一旦一个资源挂掉,那么对应就会迁移至其他节点,对于其他节点只要提供的ip地址,进程,端口不冲突就不会有很大的问题,只不过相对压力要大一点;对于不同运行方式,冗余的节点数量也是不同的;而对于资源该运行到那个节点我们可以通过定义资源对节点的倾向性来决定;默认情况每个资源都能够在任意节点上运行;也就说默认情况当A资源挂掉以后,它的故障转移范围是其他任何一个集群节点,为了不让A服务运行到B节点,我们可以定义A资源对B节点的倾向性为负无穷,所谓负无穷就是只要有其他节点可运行就绝不在B节点上运行;通过定义资源对节点的倾向性,从而来限制资源在那些节点上进行转移;这种限制资源对节点的倾向性我们叫做定义资源的故障转移域;除了能够定义资源对节点的倾向性,我们还可以定义资源与资源的倾向性,其逻辑都是相似的;对于资源倾向性通常我们会用分数来表示,其取值范围是正无穷到负无穷;正无穷表示无限喜欢到某个节点或资源,只要对应节点正常存在就一定在该节点上,负无穷相反。