好久不见,我叫阿Q,是CPU一号车间的员工。我所在的CPU有8个车间,也就是8个核心,咱们每个核心都可以同时执行两个线程,就是8核16线程,那速度杠杠滴。
我所在的一号车间,除了负责执行指令的我,还有负责读取指令的小A,负责指令译码的小胖和负责结果回写的老K,我们几个各司其职,一起完成执行程序的工作。
一个简单的循环
那天,我们遇到了一段代码:
void array_add(int data[], int len) {
for (int i = 0; i < len; i++) {
data[i] += 1;
}
}循环了好几百次之后,才把这段代码执行完成,每次循环都是做简单又重复的工作,把我累得够呛。
一旁负责结果回写的老K也是累的满头大汗,吐槽道:“每次都是取出来加1又写回去,要是能一次多取几个数,批量处理就好了”
老K的话让我眼前一亮,对啊,能不能批量操作呢?
心里一边想着,一边继续干活了。
繁忙的一天很快结束了,转眼又到了晚上,计算机关机后,我把大家召集了起来。
“兄弟们,还记得咱们白天遇到的那个循环吗?”
“你说哪个循环,咱们这一天可执行了不少循环呢”,小A说到。
“就是那个把整数数组每个元素都加1的那个循环”
“我想起来了,那循环怎么了?有什么问题吗?”
我看了老K一眼,说道:“我在想今天老K的话,像这种循环,每次都是取出来加1又写回去,一次操作一个数,效率太低了,咱们要是升级改造一下,支持一次取出多个数,批量加1,这样岂不是快很多?”
老K一听来了兴趣,“这敢情好,你打算怎么做?”
“这我还没想好,大家有什么建议吗?”
一旁负责指令译码的小胖说道:“可以新增一条指令,专门用来一次取出多个数据来加1”
“不行不行,不能限的这么死,今天是加1,万一下次是加2呢?指令里面不能限制为1”
“那如果每个数据要加的是不一样的怎么办?”
“你这么一说,那万一不是加法,是减法,乘法怎么办?”
“还有啊,···”
大家开始七嘴八舌讨论了起来,没想到一个小小的加法循环,一下子引出了这么多问题来,这是我们没想到的。
并行计算
随着讨论的深入,我觉得已经超出了咱们一号车间能把控的范围,需要上报给领导,组织八个车间代表一起来商讨。
领导一听说有提高性能的新技术,马上来了兴趣,很快便开会组织大家一起来商讨方案。

“都到齐了是吧,阿Q你给大家说一下这个会议的目的”,领导说到。
我站了起来,开始把我们遇到的问题和想法跟大家讲了一遍。
“是这样的,我们一号车间那天遇到了一段循环代码,循环体的内容很简单,就是给数组中的每一个元素加1。我们执行的时候,就是不断取出每一个元素,然后将其执行加法计算后,再写回去。这样一个一个来加1,我们感觉太慢了, 要是可以一次多取几个,并行加1,那一定比一个一个加快上不少。”
我刚说完,大家都开始小声议论起来。
“我看出来了,这其实就是并行计算!”,二号车间小虎一语道出了关键。
六号车间小六问道:”阿Q,你们已经有方案了吗?“
“还没有,这正是今天开会的目的,因为情况有点复杂,还需要大家一起来出出主意”
“好像并不复杂嘛”
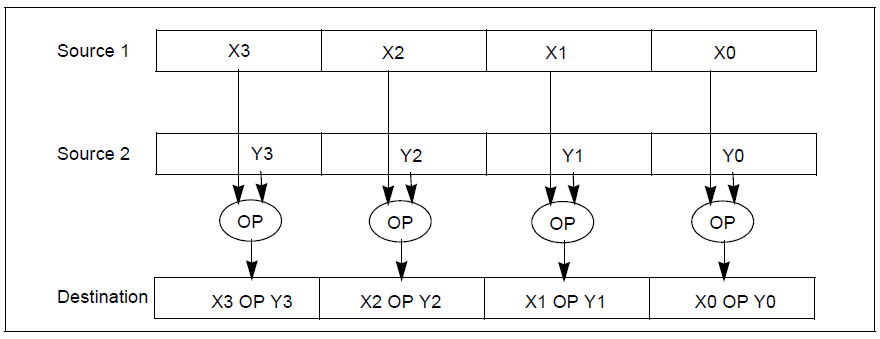
“我上面举的例子只是一个简单的情况,并行计算还可能不是固定的数,可能是一个数组和另一个数组相加。还有可能不是整数相加,而是浮点数,甚至,还可能不是加法,而是减法或者乘法,再或者不是算术运算,而是逻辑运算”
我刚一说完,大家又开始窃窃私语交流起来。
“我琢磨着你说的这一系列东西,咱们是要新增一套专门用来并行计算的指令集啊”,小虎说道。
“这可是大工程啊”
“是啊···”
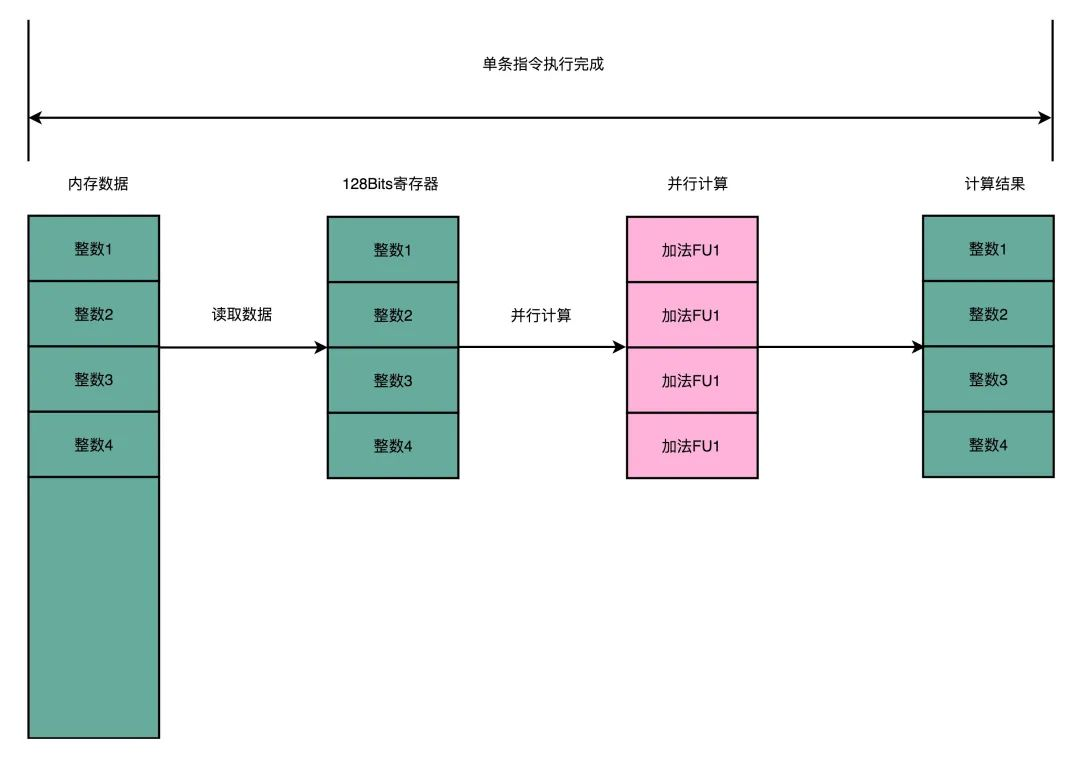
这时,小六又问道:“咱们的计算的时候,都是把数据读取到寄存器进行的,可这寄存器一次只能装一个数,怎么一次读取多个数据呢?”
“可能需要新增一些容量大一些的寄存器,比如128bit长度,可以同时容纳4个32位的整数”
“有这个必要吗?咱们是通用CPU,又不是专门做数学计算的芯片,搞这些东西干嘛?”,四号车间代表提出了质疑。
我也不甘示弱:“那可太有必要了,在图像、视频、音频处理等领域,有大量这样的计算需求,咱们得提升处理这些数据的能力”
见我们争执不下,领导拍了拍桌子,会场一下安静了下来。
“我觉得阿Q说的有道理,咱们确实需要提升处理这类数据运算的能力了。不过不用一下搞那么复杂,先支持整数并行运算就行了。新增寄存器这个也不用着急,可以先借用一下浮点数运算单元FPU的寄存器。这件事先这么定下来,具体的方案你们再继续讨论。”,说完便离开了会议室。
领导不愧是领导,几句话就把我们安排的明明白白。
SIMD
又经过一阵紧张的讨论,我们终于敲定了方案。
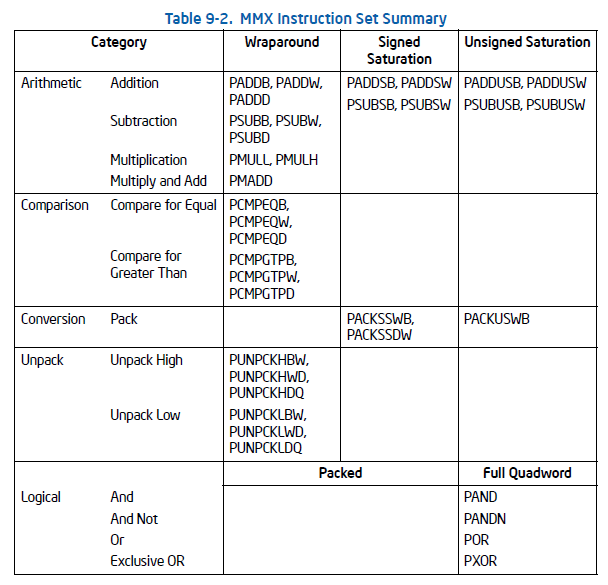
我们借用浮点数运算单元的寄存器,还给它们起了新的名字:MM0-MM7。因为是64位的寄存器,所以可以同时存储两个32位的整数或者4个16位整数或者8个8位的整数。
我们还新增了一套叫MMX的指令集,用来并行执行整数的运算。
我们把这种在一条指令中同时处理多个数据的技术叫做单指令多数据流(Single Instruction Multiple Data),简称SIMD。
有了这套指令集,咱们处理这类整数运算问题的速度快了不少。
不过渐渐地发现了两个很麻烦的问题:
第一个问题,因为是借用FPU的寄存器,所以当执行SIMD指令的时候,就不能用FPU计算单元,反过来也一样,同时使用的话就会出乱子,所以要经常在不同的模式之间切换,实在是有些麻烦。
另一个更重要的问题,咱们这套指令集只能处理整数的并行运算,可现在浮点数的并行运算越来越多,尤其是图像、视频还有深度学习的一些数据处理,浮点数情况越来越多,这时候都派不上用场。
我们把这些问题给领导做了汇报,看到我们已经做出的成绩,领导终于同意继续升级。
这一次,我们扩展了一套新的SSE指令集出来,新增了XMM0-XMM7总共8个128位的寄存器,再也不用跟FPU共享寄存器了。而且位宽加了一倍,能容纳的数据更多了,能同时处理的数据自然也变多了。
后来,我们又不断的修改升级,不仅支持了对浮点数并行处理,还推出了新一代的AVX指令集,把寄存器再一次扩大为256位,现在我们的SIMD技术更加先进,处理数据运算的能力越来越强了!