引言
无论是One Stage中的YOLO还是Two-Stage中的Faster-RCNN,其虽然都在目标检测领域有着一席之地,但无一例外都是基于Anchor的模型算法,这就导致其在输出结果时不可避免的进行一些如非极大值抑制等操作来进一步选择最优解,这会带来额外的工作量。而随着ViT的出现,伴随着无数研究者前仆后继夜以继日的研究,Transformer敲开了CV领域的大门,作为NLP领域的中流砥柱,依旧能够在CV领域取得如此瞩目的成果属实令人惊叹,随后DETR模型横空出世,在目标检测领域掀起一阵狂潮。今天我们就来进行该算法的学习,探究其能够在众多的目标检测算法中脱颖而出的奥秘。
模型结构
主要思想
DETR的基本思想是首先使用CNN得到各个patch作为输入,在套用Transformer做编码与解码操作。
其中编码方式基本与VIT一致,重点在于解码器的变化,DETR做出了先验假设,认为一张图片中可能存在几个乃至几十个目标,因此,其设置解码器直接预测100个坐标框。
这个值可以根据我们的实际任务做出调整。此外与先前Transformer在NLP中的预测不同,解码器中后一个向量需要依赖于前一个向量的输出结果,是一种串行结构,而在这里则为并行结构,一次性直接预测100个框。
执行流程
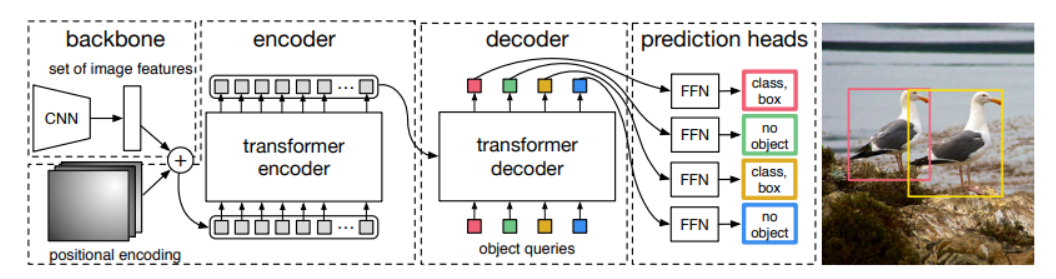
下图为DETR模型的结构图
首先通过backbone来提取特征,随后将特征信息加上位置编码送入encoder,这里的encoder进行特征构造。
在decoder中会首先初始化100个向量(object queries),这些向量会利用encoder构造的特征来进行重构,(即要学习的便是这100个向量,当这100个向量学好后,每个向量便能够较好的输出一个分类值cls与回归值bounding box)
要想理解Transformer,最重要的便是要理解Attention,其核心即为 K,Q,V。
Attention的本质就是加权,以找女朋友为例,Q代表我想要的女生类型,即一些条件,K与V则是一种键值对的表示,K为属性,如女生的相貌,身材等,而V则是对应属性的相应值,即女生的真实特征,那么一个女生越符合标准的我们预设的条件,就会被赋予更高的权重,特征占比也就越大。
那么按照Tranfomer的思想来解释,在encoder中提供的是 K 与 V ,decoder中的每个Q并行去询问encoder中的K与V,如果确定是自己需要负责的部分,那么便会根据这块的特征进行学习,最后连接一个全连接层,输出4个坐标值与一个分类值。至此也就完成了目标检测过程。
可以看到,Encoder的作用是进行特征的提取,那么我么是否可以不要这个Encoder而直接使用一个CNN网络来直接连接Decoder呢?其实理论上也是可行的,但为何仍采用这种方式呢,论文中作者给出解释:
作者认为这种注意力的效果很好,通过self-attention获取到这些特征并加以突出,随后来供Decoder进行挑选。

位置信息初始化Query向量
输出层的结果就是100个object queries的预测结果。这100个向量其实都是想要去学习来做预测的。
那么这100个object queries是如何得到的呢?这里论文中给出的答案是全部初始化为0
同时还要加上位置编码。即初始化的queries为0+位置编码,其相当于用位置编码来做初始化。
为何要使用这种位置编码作为初始化呢?论文中并未给出对应的解释,但按照一位大神的解释:在encoder构造的向量中,其实有用的特征可能就那么几块,其余的都是背景,而在encoder中,这100个向量都是想去学习这些特征的,那么如果是这样的话,基本上这100个向量都会被那几块特征较好的吸引过去,这就造成其多样性变差。而加入了位置编码后,就相当于告诉每一个向量,你不要太离谱,只负责你这一区域的特征学习即可。
注意力机制的作用方法
需要注意的是,在decoder的第一层其实做的是自注意力机制,即每个向量都有自己的Q,K,V,其先进行一下内部分配,最终我们需要的是得到的Q,而K,V值只是一些中间数据,无用也就被丢弃了。
随后便是使用encoder中的K,V来与decoder的Q送入多头注意力机制来重构Q,最终通过连接两个全连接层,分别输出class与bounding box。
即Q首先是随机初始化的(0+位置编码),然后内部进行自注意力机制进行分配,最后与encoder中的K,V作用来完成重构。
按照图中模型可以看到:Encoder共有N层,Decoder有M层,而在模型的训练过程中,使用M层的每层损失,这样做的好处是防止只用最后一层损失而造成一些意外情况。
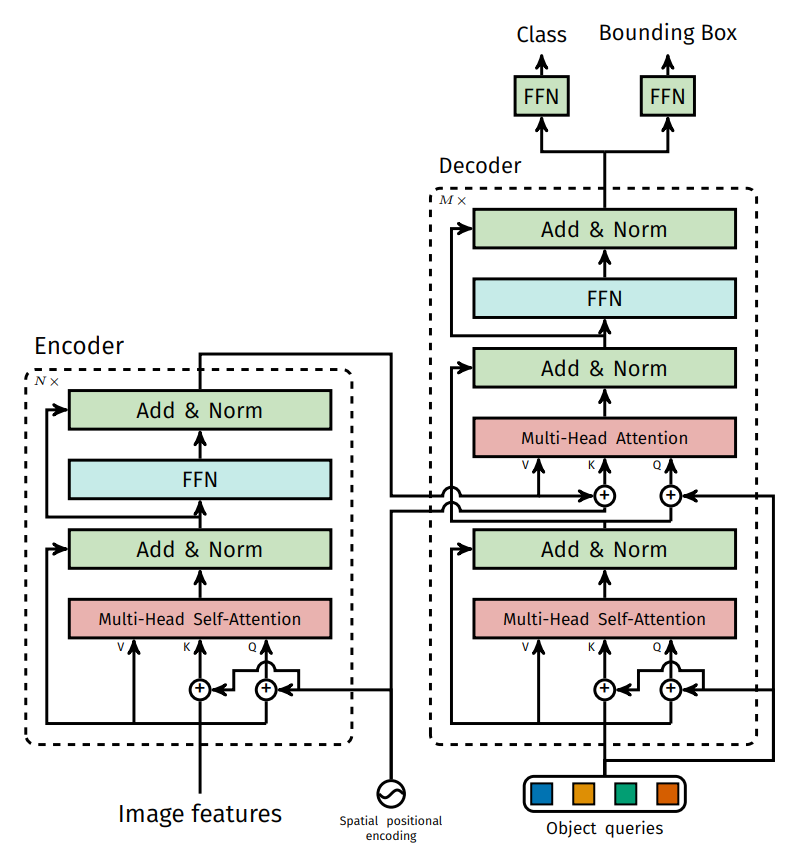
需要注意的是,在Transformer的传统模型做文本预测时,设计了一个mask机制,即后面的都是需要被掩藏不可见的。而在这里,其是并行的,也就不需要设置mask机制了。
训练过程的策略
GT只有两个,但预测恒为100个,该如何匹配呢?
这里使用的是匈牙利匹配算法,按照loss最小的方法,剩余的98个全部为背景。该算法在目标追踪领域较为火爆。即在训练时计算损失最小即可。
启示
在论文中,作者提到,注意力机制的引入能够很好的解决物体被遮挡问题。如下图:即使面对很严重的遮挡问题,注意力机制都可以很好的解决。

DETR模型的环境配置与调试
DETR模型的调试运行是相对简单的,数据集使用的是COCO2017数据集。具体配置可以参考博主这篇博客:
DETR调试记录
需要注意的是该模型在8xV100 GPU上训练 300 epochs的时间大概为6天,可以说是非常的吃配置了,而且模型在训练时所占用的显存较大,具体大家可以自行实验。
当然在我们实验时,DETR的效果与当前的一些主流目标检测算法相比还是稍逊一筹的,但这并不影响我们学习他们,因为这些基于CNN的模型在CV领域经过长期的耕耘,其已经非常成熟了。可以说基本没有什么再去改进的空间了。而Transformer作为后起之秀,在初涉该领域便取得如此效果已实属不易,而且博主也相信,随着Transformer模型在CV领域继续深耕,其一定最终能取得较好的效果。
代码解析
数据处理与dataloader
在DETR模型中,其使用的标注数据集格式为COCO,我们在运行自己的数据集时只需要将其转换为COCO格式即可。