文章目录
- 📯小哔哔
- ✏️注册有道智云
- ✏️咋滴调用?
- ✏️使用前的小操作
- ✏️源代码
| 专栏 |
|---|
| Python零基础入门篇🔥 |
| Python网络蜘蛛🔥 |
| Python数据分析 |
| Django基础入门宝典🔥 |
| 小玩意儿🔥 |
| Web前端学习 |
| tkinter学习笔记 |
| Excel自动化处理 |
📯小哔哔
各位久等了吧《小玩意儿》专栏它!@#¥%……&更新啦❗️❗️❗️
好久没更新《小玩意儿》专栏里的文章了,今天俺又回来啦💨
今天带给大家的是什么呢?没错,就是❗️❗️❗️什么呢?

开个小玩笑啦!今天带来的当然就是人人用了都说好的实用办公小脚本咯:批量将图片内容识别并写入Excel表格中❗️
具体咋用?咱们废话不多说,请各位看官往下look look👀
✏️注册有道智云
当然,咱们还没有写出将图片转为Excel表格的代码的实力,但是❗️❗️❗️,咱们可以调用API接口呀,你说这,有现成的咱就不费那个劲儿了,调用API接口就咔咔完事儿了~
- 我们需要调用有道智云平台上的API接口,注册好后进入即可看到如下页面👇

- 将鼠标移动到上方的产品服务,然后选择表格识别并点击
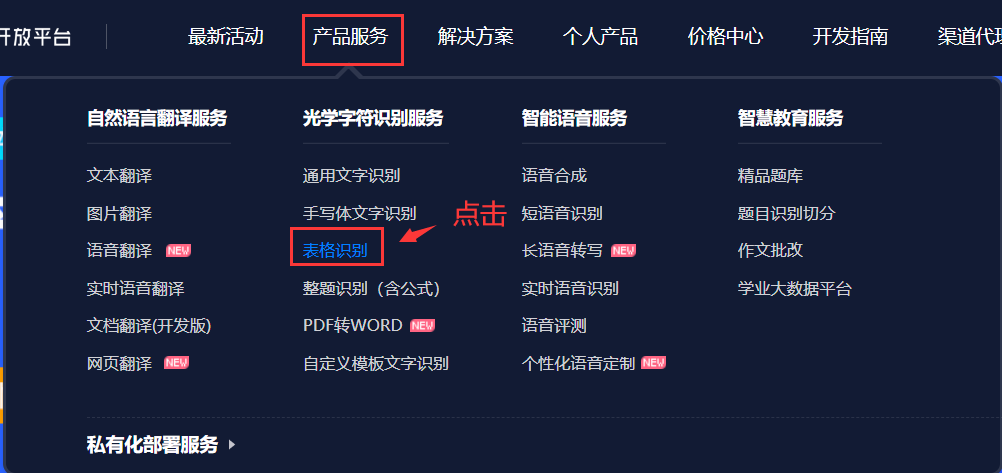
- 这时会跳到另一个界面,这时你可能不知所措,不过没关系,接着点击立即使用就好了😝
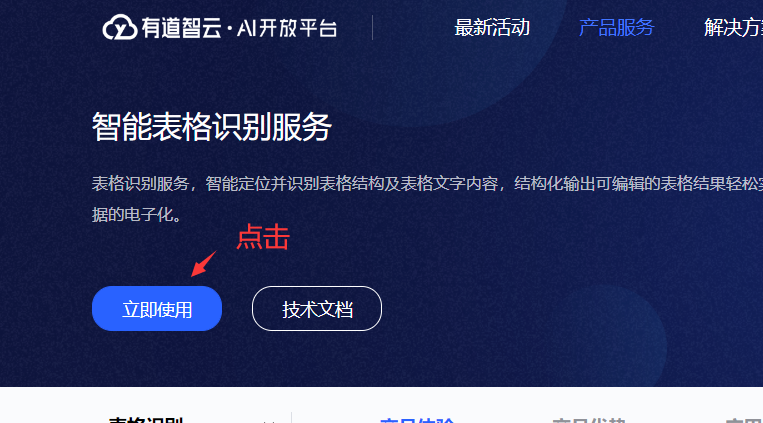
- 接下来就是一个浅浅的三步走战略,具体如下图所示👌
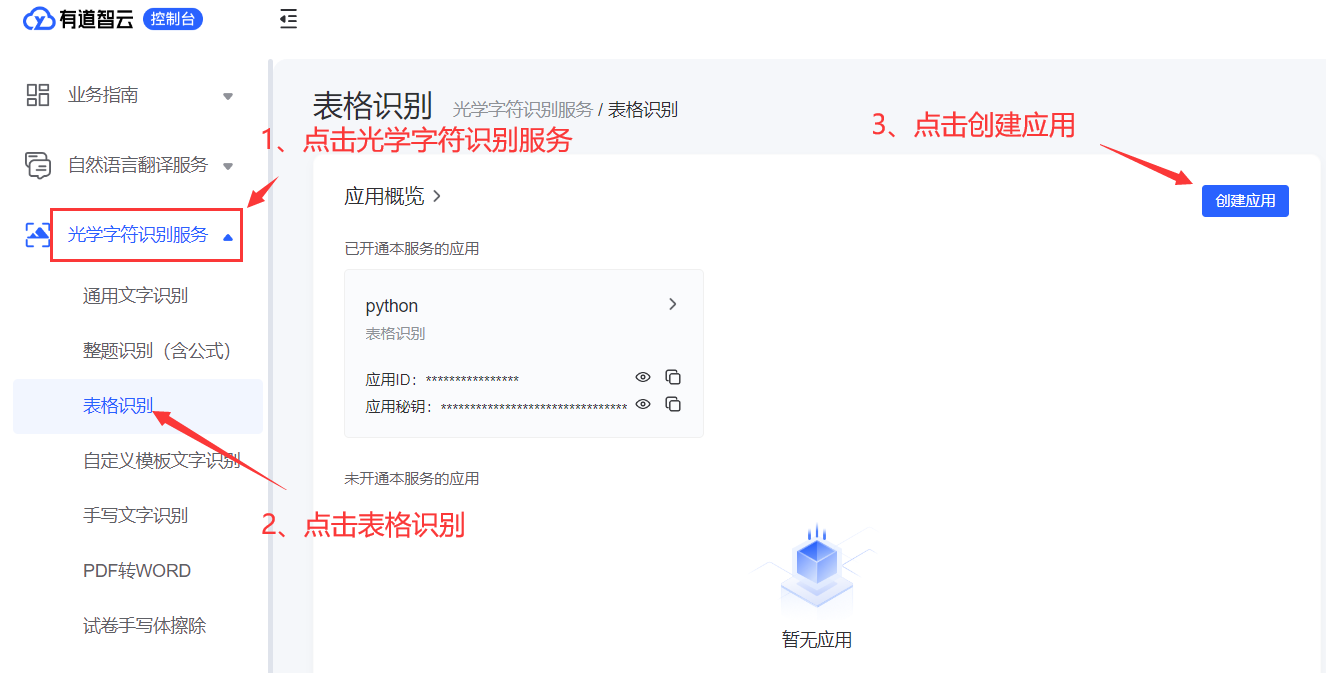
- 这时候按照网页给的提示,咔咔操作就完事儿了,最后点击一个小确定就O了,注意:服务器IP可以不写
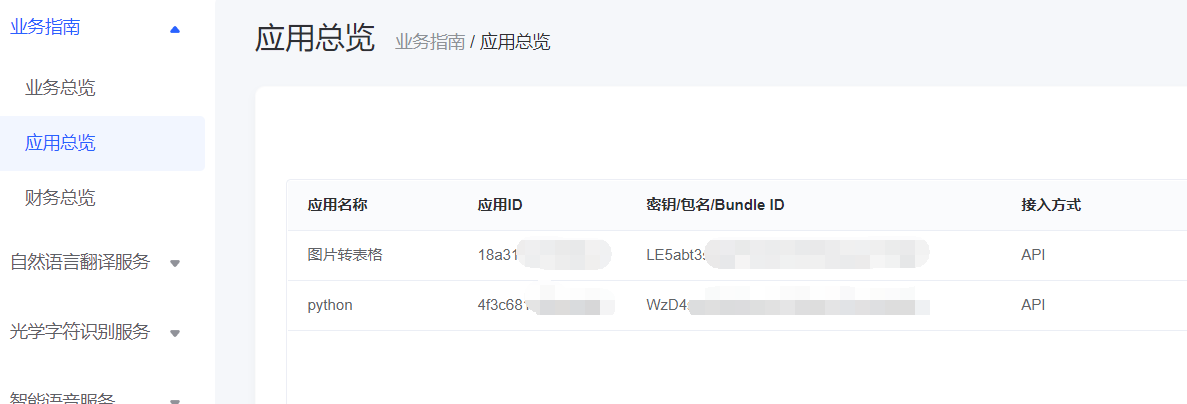
- 最后在业务总览上,即可看到你所创建的应用,上面有两个重要的信息:应用ID和密匙
✏️咋滴调用?
这时候可能就有小伙伴问了:诶呀,做了这么多,到底咋滴调用呀呀呀呀……?
别急,哥手把脚教你,来,看下面的操作👇
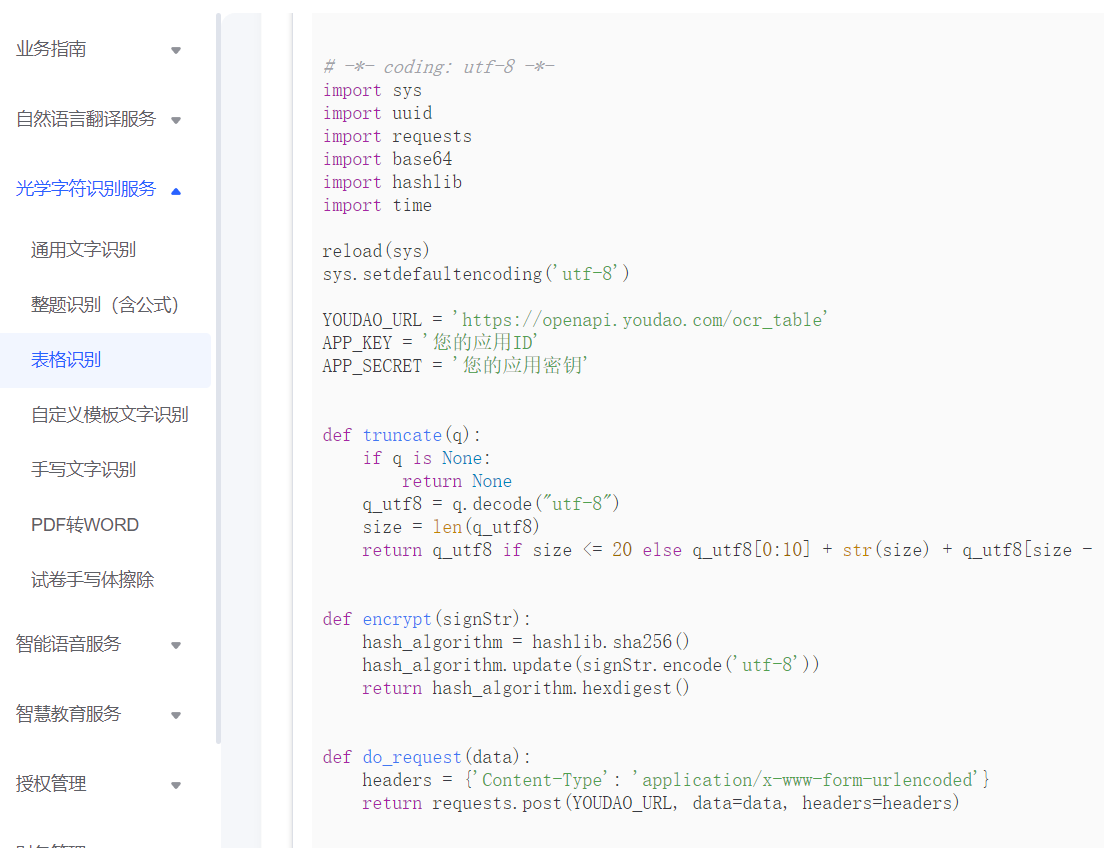
- 重新点击光学字符识别服务——>表格识别,这时细心的小伙伴就会发现在右下方提供Java、Python、C#、PHP语言调用API接收的示例

- 我们这里以Python为例,点击查看,即可看到Python调用接口的代码(这时应该听到耳鸣般的掌声👏),但是,到了这,先别啷个激动,这些代码需要修改的哈,具体怎么改?请继续往下看
✏️使用前的小操作
想知道咋修改吗?就不告诉你,就不告诉你~略略略略~

咱们不用费这个劲儿去想,本小小博主👴已经为兄弟姐妹们改好啦,还做了一点小小的升级er(那就是批量)
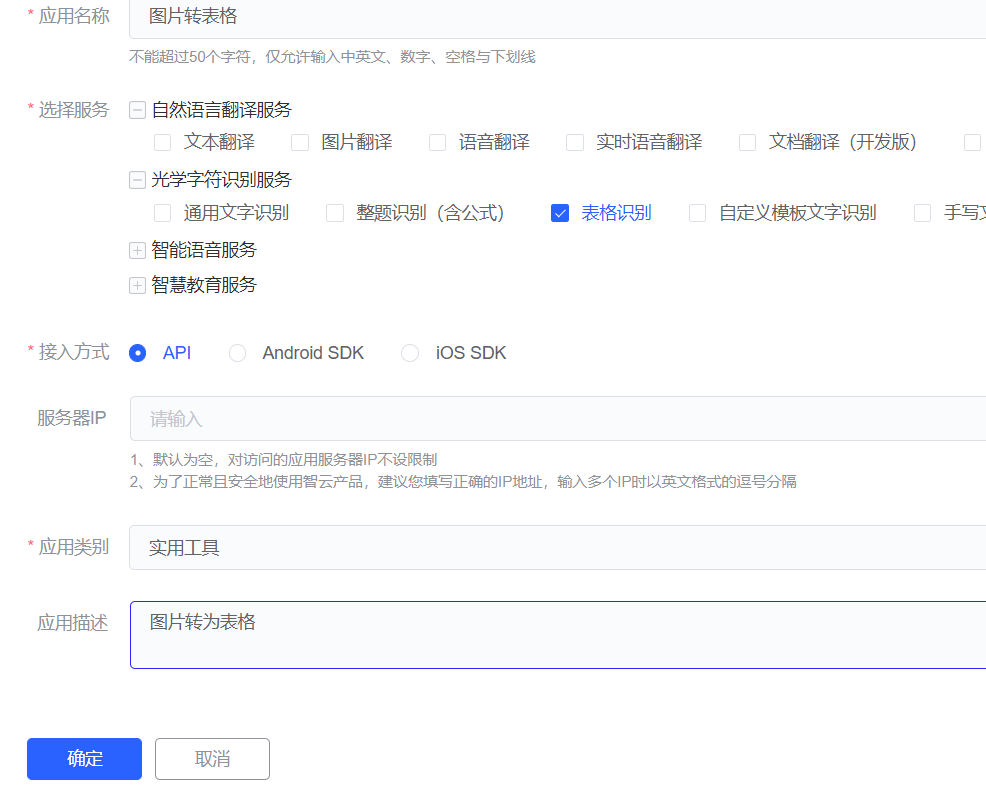
- 首先,先练习一下快速Ctrl C和Ctrl V,将创建好的应用中给出的应用ID和密匙复制,粘贴到代码中
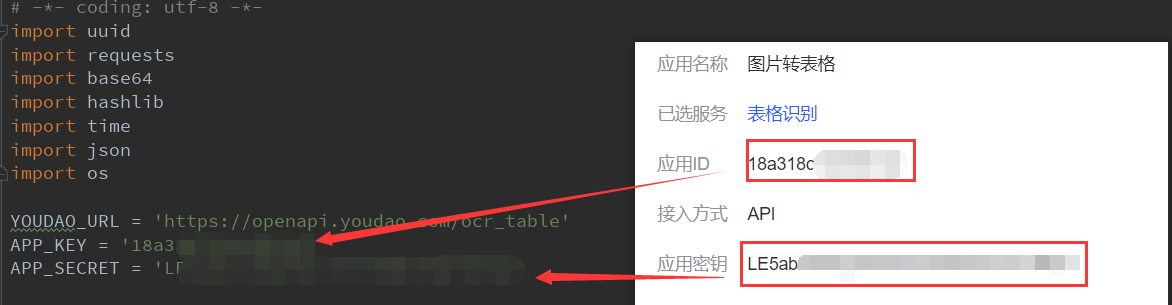
- 然后,将咱们的目标图片,放到同一个文件夹之中,修改path的路径为图片存放的文件夹路径
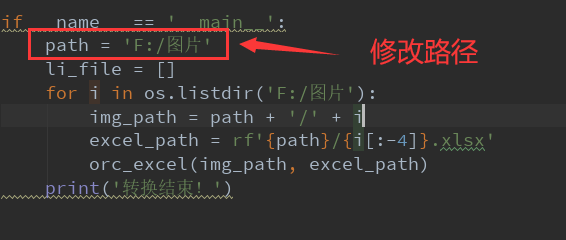
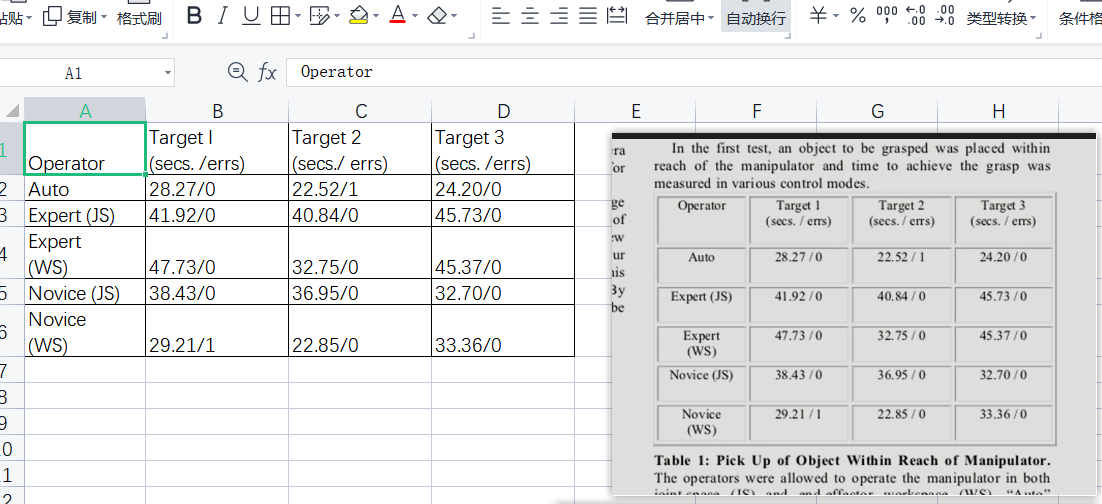
- 最后,运行一波,你会发现目标文件夹下的图片统统都被Excel了,而这些Excel表格文件的名字就是对应图片的名字。
- 特别注意⚠️我们在有道智云注册之后会发现有50💰,当然,这不是你的生活费,这是只能在平台上消费,而每转一张图片会话0.5💰,所以,大家合理使用哈❗️❗️❗️
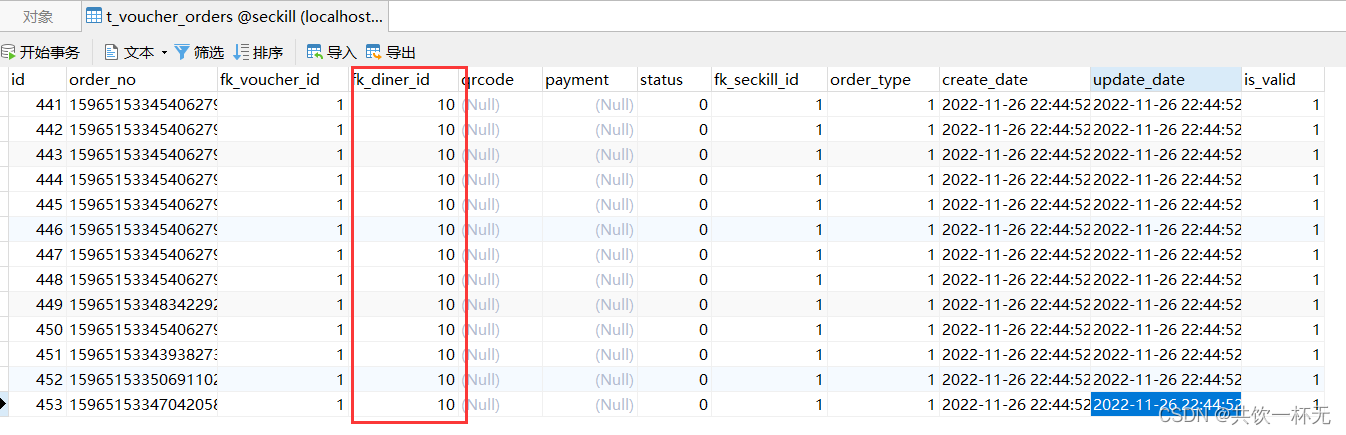
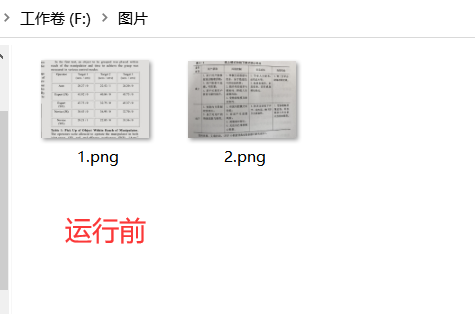
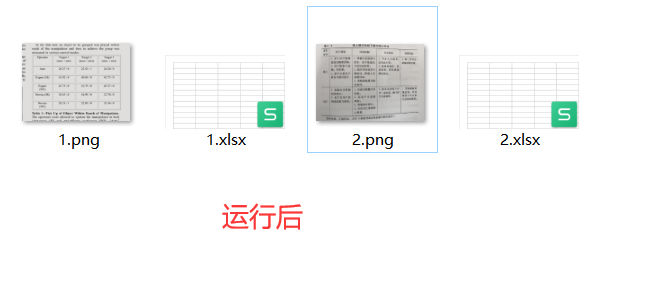
- 具体运行结果看下图👇
✏️源代码
小说明:有一些复杂的表格图片可能会识别有误哦~😊
# -*- coding: utf-8 -*-
import uuid
import requests
import base64
import hashlib
import time
import json
import os
YOUDAO_URL = 'https://openapi.youdao.com/ocr_table'
APP_KEY = ''
APP_SECRET = ''
def truncate(q):
if q is None:
return None
q_utf8 = q.decode("utf-8")
size = len(q_utf8)
return q_utf8 if size <= 20 else q_utf8[0:10] + str(size) + q_utf8[size - 10:size]
def encrypt(signStr):
hash_algorithm = hashlib.sha256()
hash_algorithm.update(signStr.encode('utf-8'))
return hash_algorithm.hexdigest()
def do_request(data):
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
return requests.post(YOUDAO_URL, data=data, headers=headers)
def connect(img_path):
f = open(img_path, 'rb') # 二进制方式打开图文件
q = base64.b64encode(f.read()) # 读取文件内容,转换为base64编码
f.close()
data = {}
data['type'] = '1'
data['q'] = q
data['docType'] = 'excel' # excel相关数据
data['signType'] = 'v3'
curtime = str(int(time.time()))
data['curtime'] = curtime
salt = str(uuid.uuid1())
signStr = APP_KEY + truncate(q) + salt + curtime + APP_SECRET
sign = encrypt(signStr)
data['appKey'] = APP_KEY
data['salt'] = salt
data['sign'] = sign
# 包含excel相关数据(base64字符串) json
response = do_request(data)
# json -- 字典
# 拿到的是包含excel的base64的json字符串
response_json = json.loads(response.text)
# 提取数据
excel_table_base64 = response_json.get('Result').get('tables')[0]
return excel_table_base64
def orc_excel(img_path, excel_path):
excel_table_base64 = connect(img_path)
# 将数据解码
decoded = base64.b64decode(excel_table_base64)
# 讲解码后的数据写入excel文件
with open(excel_path, 'wb') as f:
f.write(decoded)
print('保存成功')
if __name__ == '__main__':
path = ''
li_file = []
for i in os.listdir(path):
img_path = path + '/' + i
excel_path = rf'{path}/{i[:-4]}.xlsx'
orc_excel(img_path, excel_path)
print('转换结束!')











![[附源码]Python计算机毕业设计高校党建信息平台](https://img-blog.csdnimg.cn/179acc2bf93d4e9e98e3deab2314efc5.png)