🔥 本文由 程序喵正在路上 原创,CSDN首发!
💖 系列专栏:数据结构与算法
🌠 首发时间:2022年11月7日
🦋 欢迎关注🖱点赞👍收藏🌟留言🐾
🌟 一以贯之的努力 不得懈怠的人生
阅读指南
- 树的存储结构
- 双亲表示法(顺序存储)
- 孩子表示法(顺序+链式存储)
- 孩子兄弟表示法(链式存储)
- 森林和二叉树的转换
- 树和森林的遍历
- 树的先根遍历
- 树的后根遍历
- 树的层次遍历
- 森林的先序遍历
- 森林的中序遍历
- 二叉排序树
- 定义
- 二叉排序树的查找
- 二叉排序树的插入
- 二叉排序树的构造
- 二叉排序树的删除
- 查找效率分析
- 平衡二叉树
- 定义
- 平衡二叉树的插入
- 调整最小不平衡子树
- 查找效率分析
- 哈夫曼树
- 带权路径长度
- 哈夫曼树
- 哈夫曼树的构造
- 哈夫曼编码
树的存储结构
双亲表示法(顺序存储)
双亲表示法:每个结点中保存指向双亲的 “指针”,根节点固定存储在 0 0 0, − 1 -1 −1 表示没有双亲
#define MAX_TREE_SIZE 100 //树中最多结点数
//树的结点定义
typedef struct{
ElemType data; //数据元素
int parent; //双亲位置域
}PTNode;
//树的类型定义
typedef struct{
PTNode nodes[MAX_TREE_SIZE]; //双亲表示
int n; //结点数
}PTree;
优点:查找指定结点的双亲很方便
缺点:查找指定结点的孩子只能从头遍历
孩子表示法(顺序+链式存储)
孩子表示法:顺序存储每个节点,每个结点中保存孩子链表头指针
struct CTNode{
int child; //孩子结点在数组中的位置
struct CTNode *next; //下一个孩子
};
typedef struct{
ElemType data;
struct CTNode *firstChild; //第一个孩子
}CTBox;
typedef struct{
CTBox nodes[MAX_TREE_SIZE];
int n, r; //结点数和根的位置
}CTree;
孩子兄弟表示法(链式存储)
//孩子兄弟表示法
typedef struct CSNode{
ElemType data; //数据域
struct CSNode *firstchild, *nextsibling; //第一个孩子和右兄弟指针
}CSNode, *CSTree;
森林和二叉树的转换
森林是 m ( m ≥ 0 ) m (m\geq0) m(m≥0) 棵互不相交的树的集合
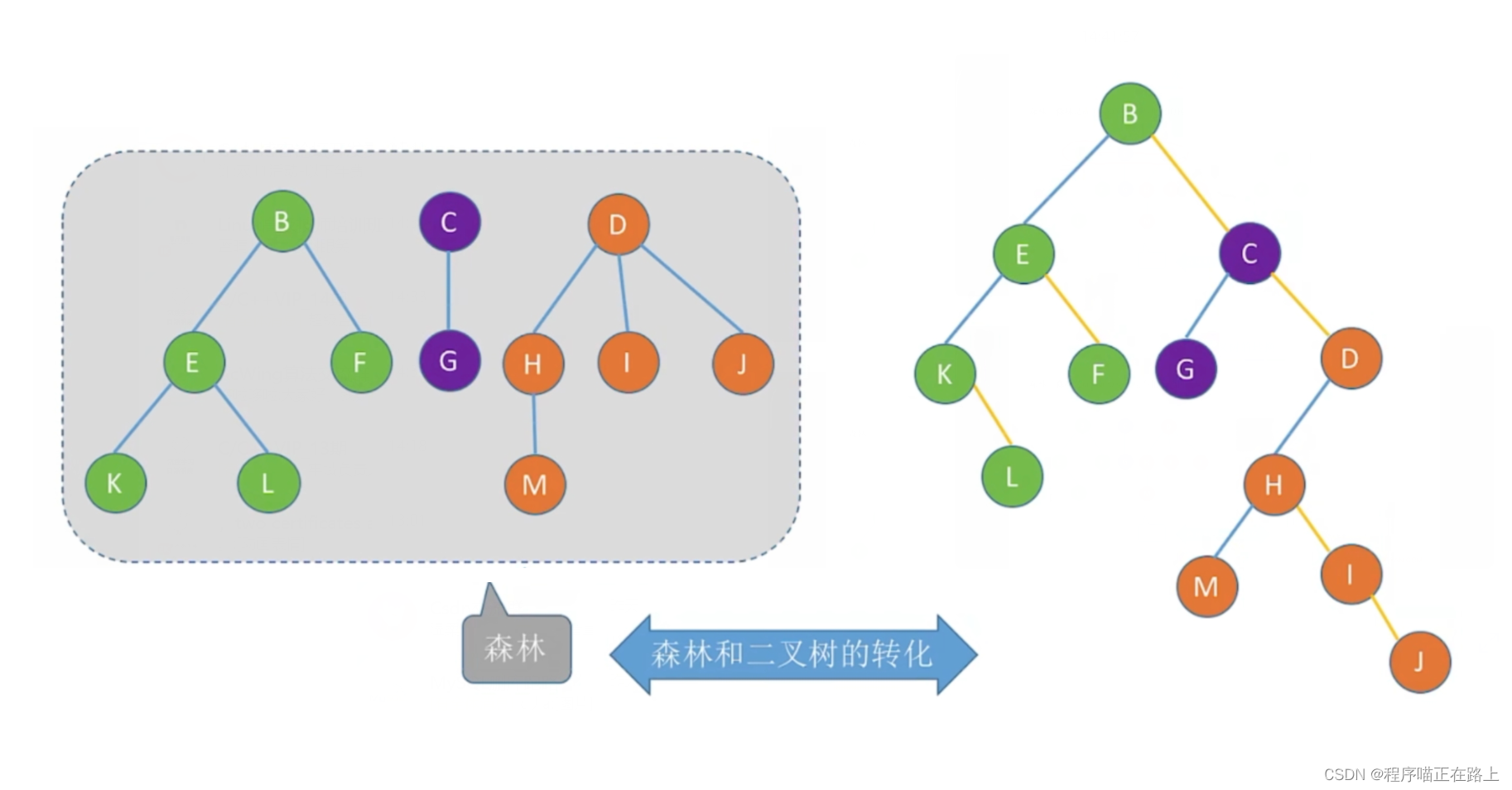
本质:用二叉链表存储森林,左孩子右兄弟
树和森林的遍历
树的先根遍历
若树非空,先访问根结点,再依次对每棵子树进行先根遍历
//树的先根遍历
void PreOrder(TreeNode *R) {
if (R) {
visit(R); //访问根结点
while(R还有下一个子树T)
PreOrder(T); //先根遍历下一棵子树
}
}
树的后根遍历
若树非空,先依次对每棵子树进行后根遍历,最后再访问根结点
//树的后根遍历
void PostOrder(TreeNode *R) {
if (R) {
while(R还有下一个子树T)
PostOrder(T); //后根遍历下一棵子树
visit(R); //访问根结点
}
}
树的后根遍历与这棵树相应二叉树的中序序列相同
树的层次遍历
步骤:
- 若树非空,则根结点入队
- 若队列非空,队头元素出队并访问,同时将该元素的孩子依次入队
- 重复第 2 2 2 步直到队列为空
树的层次遍历也可以称为广度优先遍历,树的先根和后根遍历也可以称为深度优先遍历
森林的先序遍历
森林是 m ( m ≥ 0 ) m (m\geq0) m(m≥0) 棵互不相交的树的集合。每棵树去掉根结点后,其各个子树又组成森林
若森林非空,则按照如下规则进行遍历:
- 访问森林中第一棵树的根结点
- 先序遍历第一个棵树中根结点的子树森林
- 先序遍历除去第一棵树之后剩余的树构成的森林
森林的先序遍历效果等同于依次对每个树进行先根遍历
如果我们先将森林转换为二叉树,那森林的先序遍历也等同于对应二叉树的先序遍历
森林的中序遍历
若森林非空,则按照如下规则进行遍历:
- 中序遍历第一个棵树中根结点的子树森林
- 访问森林中第一棵树的根结点
- 中序遍历除去第一棵树之后剩余的树构成的森林
森林的中序遍历效果等同于依次对每个树进行后根遍历
如果我们先将森林转换为二叉树,那森林的中序遍历也等同于对应二叉树的中序遍历
二叉排序树
定义
二叉排序树,又称为二叉查找树( B S T BST BST, B i n a r y S e a r c h T r e e Binary \ Search \;Tree Binary SearchTree)
一棵二叉树或者是空二叉树,或者是具有如下性质的二叉树:
- 左子树上所有结点的关键字均小于根结点的关键字
- 右子树上所有结点的关键字均大于根结点的关键字
- 左子树和右子树又各是一棵二叉排序树
我们可以发现,左子树结点值 < 根结点值 < 右子树结点值;同时,如果我们对一棵二叉排序树进行中序遍历,就可以得到一个递增的有序序列
二叉排序树的查找
若树非空,目标值与根结点的值比较:
- 如果相等,则查找成功
- 如果小于根结点,则在左子树上查找,否则在右子树上查找
- 查找成功,返回结点指针;查找失败则返回 N U L L NULL NULL
//二叉排序树结点
typedef struct BSTNode{
int key;
struct BSTNode *lchild, *rchild;
}BSTNode, *BSTree;
//在二叉排序树中查找值为 key 的结点
BSTNode *BST_Search(BSTree T, int key) {
while (T && key != T->key) { //若树空或等于根结点值,则结束循环
if (key < T->key) T = T->lchild; //小于,则在左子树上查找
else T = T->rchild; //大于,则在右子树上查找
}
return T;
}
非递归:最坏空间复杂度 O ( 1 ) O(1) O(1)
//在二叉排序树中查找值为 key 的结点(递归实现)
BSTNode *BST_Search(BSTree T, int key) {
if (!T) return NULL; //查找失败
if (key == T->key) return T; //查找成功
else if (key < T->key) return BST_Search(T->lchild, key);
else return BST_Search(T->rchild, key);
}
递归:最坏空间复杂度 O ( h ) O(h) O(h), h h h 为树的高度
二叉排序树的插入
若原二叉排序树为空,则直接插入结点;否则,若关键字 k k k 小于根结点值,则插入到左子树中;若关键字 k k k 大于根结点值,则插入到右子树中
//在二叉排序树插入关键字为 k 的新结点(递归实现)
int BST_Insert(BSTree &T, int k) {
if (!T) { //原树为空
T = (BSTree)malloc(sizeof(BSTNode));
T->key = k;
T->lchild = T->rchild = NULL;
return 1; //返回 1, 插入成功
} else if (k == T->key) { //树中存在相同关键字的结点, 插入失败
return 0;
} else if (k < T->key) { //小于, 插入到左子树
return BST_Insert(T->lchild, k);
} else { //大于, 插入到右子树
return BST_Insert(T->rchild, k);
}
}
最坏空间复杂度为 O ( h ) O(h) O(h)
二叉排序树的构造
//按照 str[] 中的关键字序列建立二叉排序树
void Creat_BST(BSTree &T, int str[], int n) {
T = NULL; //初始时为空树
int i = 0;
while (i < n) { //依次将每个关键字插入到二叉排序树中
BST_Insert(T, str[i]);
++i;
}
}
不同的关键字序列可能得到同款二叉排序树,也可能得到不同款二叉排序树
二叉排序树的删除
先搜索找到目标结点:
- 如果被删除结点 z z z 是叶子结点,则直接删除,不会破坏二叉排序树的性质
- 如果被删除结点 z z z 只有一棵左子树或右子树,则让 z z z 的子树成为 z z z 父结点的子树,替代 z z z 的位置
- 如果 z z z 有左、右两颗子树,则令 z z z 的直接后继(或直接前驱)替代 z z z ,然后从二叉排序树中删去这个直接后继(或直接前驱),这样就转换成了第一或第二种情况
第 3 3 3 种情况中的直接后继和直接前驱也就是 z z z 的中序后继和中序前驱, z z z 的后继为 z z z 的右子树中最左下的结点(该结点一定没有左子树), z z z 的前驱为 z z z 的左子树中最右下的结点(该结点一定没有右子树)
查找效率分析
查找长度 —— 在查找运算中,需要对比关键字的次数称之为查找长度,反映了查找操作的时间复杂度
若树高 h h h,找到最下层的一个结点需要对比 h h h 次
最好情况: n n n 个结点的二叉树最小高度为 ⌊ l o g 2 n + 1 ⌋ \lfloor log_2{n} + 1 \rfloor ⌊log2n+1⌋,平均查找长度为 O ( l o g 2 n ) O(log_2{n}) O(log2n)
最坏情况:每个结点只有一个分支,树高 h h h 等于结点数 n n n,平均查找长度为 O ( n ) O(n) O(n)
查找成功的平均查找长度 A S L ASL ASL( A v e r a g e S e a r c h L e n g t h Average \ Search \ Length Average Search Length) 计算方式例子:
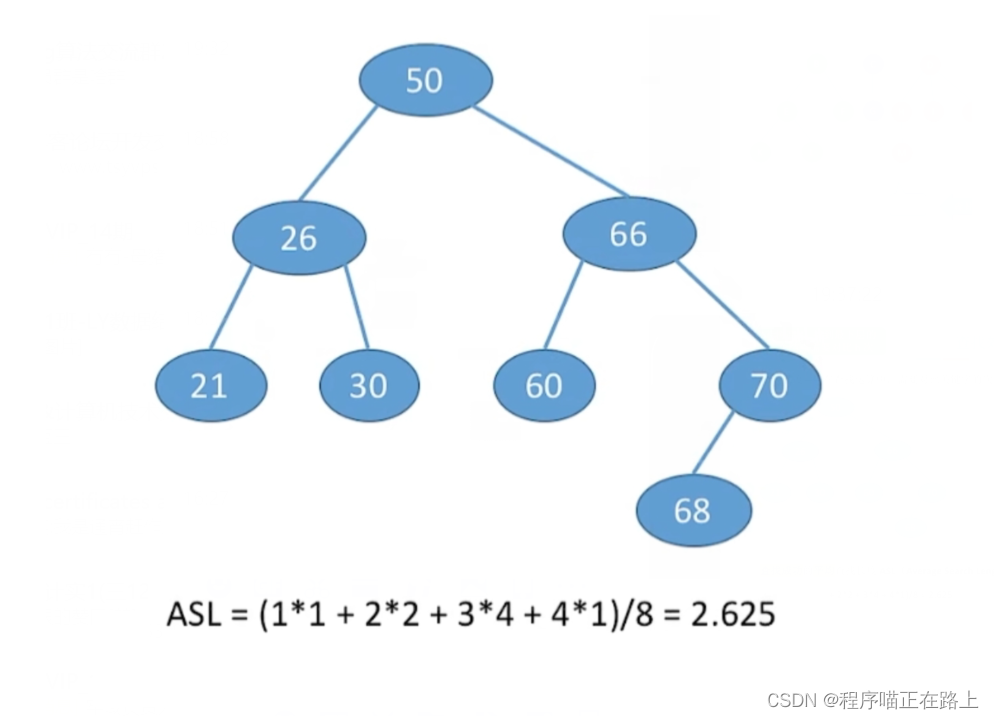
也就是( [ 每层结点数乘以每层结点查找长度 ] 之和)/ 总结点数
查找失败的平均查找长度 A S L ASL ASL( A v e r a g e S e a r c h L e n g t h Average \ Search \ Length Average Search Length) 计算方式:
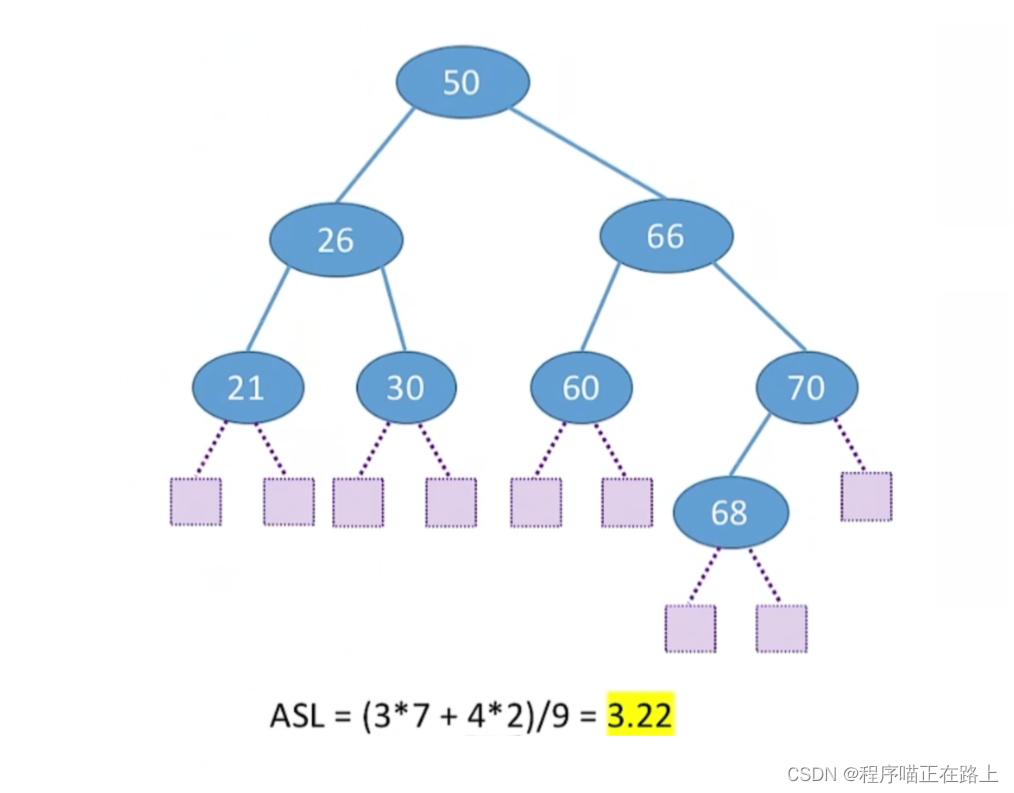
平衡二叉树
定义
平衡二叉树( B a l a n c e d B i n a r y T r e e Balanced \ Binary \ Tree Balanced Binary Tree),简称平衡树( A V L AVL AVL树)—— 树上任一结点的左子树和右子树的高度之差不超过 1 1 1
结点的平衡因子 = = = 左子树高 − - − 右子树高,平衡二叉树结点的平衡因子的值只可能是 − 1 、 0 -1、0 −1、0 或者 1 1 1,只要有任一结点的平衡因子的绝对值大于 1 1 1,就不是平衡二叉树
//平衡二叉树结点
typedef struct AVLNode{
int key; //数据域
int balance; //平衡因子
struct AVLNode *lchild, *rchild;
}AVLNode, *AVLTree;
平衡二叉树的插入
在二叉排序树中插入新结点后,该如何保持平衡?
查找路径上的所有结点都有可能受到影响,所以我们从插入点往回找到第一个不平衡的结点,调整以该结点为根的子树,每次调整的对象都是 “最小不平衡子树”
在插入操作中,我们只需要将最小不平衡子树调整平衡,则其他祖先结点都会恢复平衡
调整最小不平衡子树
- L L LL LL:在 A A A 的左孩子的左子树中插入导致不平衡
- R R RR RR:在 A A A 的右孩子的右子树中插入导致不平衡
- L R LR LR:在 A A A 的左孩子的右子树中插入导致不平衡
- R L RL RL:在 A A A 的右孩子的左子树中插入导致不平衡
调整最小不平衡子树 —— LL:
假设最小不平衡子树如下图:
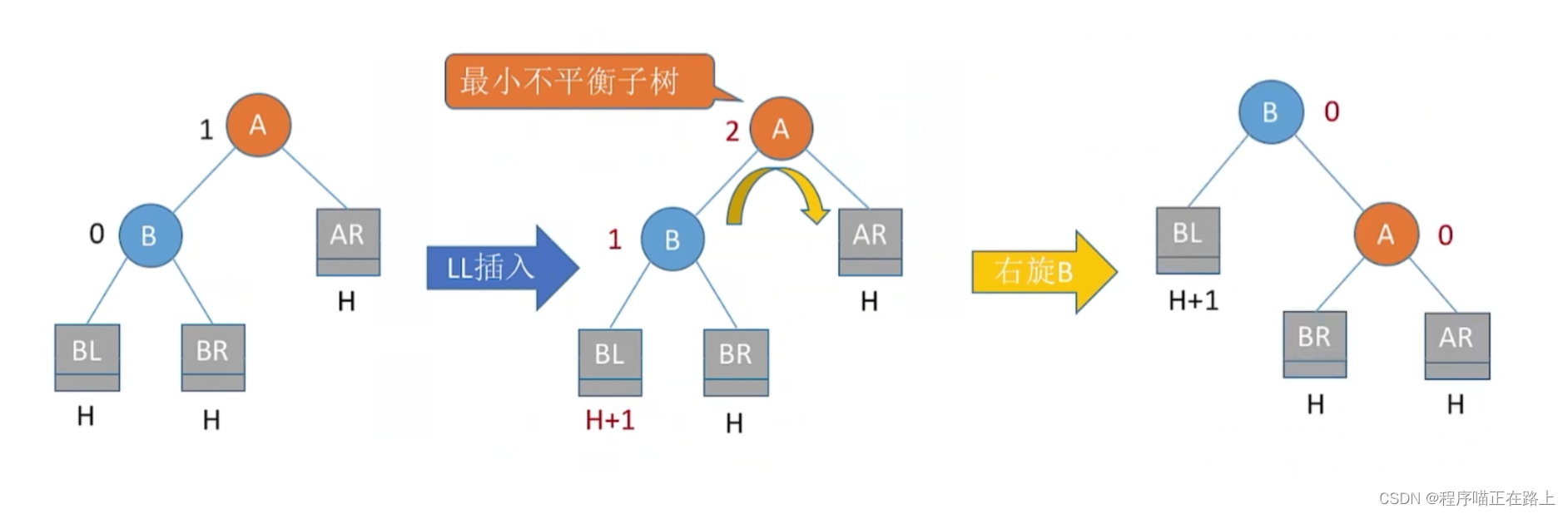
L L LL LL 平衡旋转(右单旋转)。由于在结点 A A A 的左孩子 ( L L L)的左子树( L L L)上插入了新结点, A A A 的平衡因子由 1 1 1 增至 2 2 2,导致以 A A A 为根的子树失去平衡,需要一次向右的旋转操作。将 A A A 的左孩子 B B B 向右上旋转代替 A A A 成为根结点,将 A A A 结点向右下旋转成为 B B B 的右子树的根结点,而 B B B 的原右子树则作为 A A A 结点的左子树
调整最小不平衡子树 —— RR:
R R RR RR 平衡旋转(右单旋转)。由于在结点 A A A 的右孩子 ( R R R)的右子树( R R R)上插入了新结点, A A A 的平衡因子由 − 1 -1 −1 增至 − 2 -2 −2,导致以 A A A 为根的子树失去平衡,需要一次向左的旋转操作。将 A A A 的右孩子 B B B 向左上旋转代替 A A A 成为根结点,将 A A A 结点向左下旋转成为 B B B 的左子树的根结点,而 B B B 的原左子树则作为 A A A 结点的右子树
右旋和左旋代码思路:
右旋:假设指针 f f f 指向最小不平衡子树的根, p p p 指向根的左子树,那么 f f f 向右下旋转, p p p 向右上旋转,其中 f f f 是爹, p p p 为左孩子, g f gf gf 为 f f f 的爹
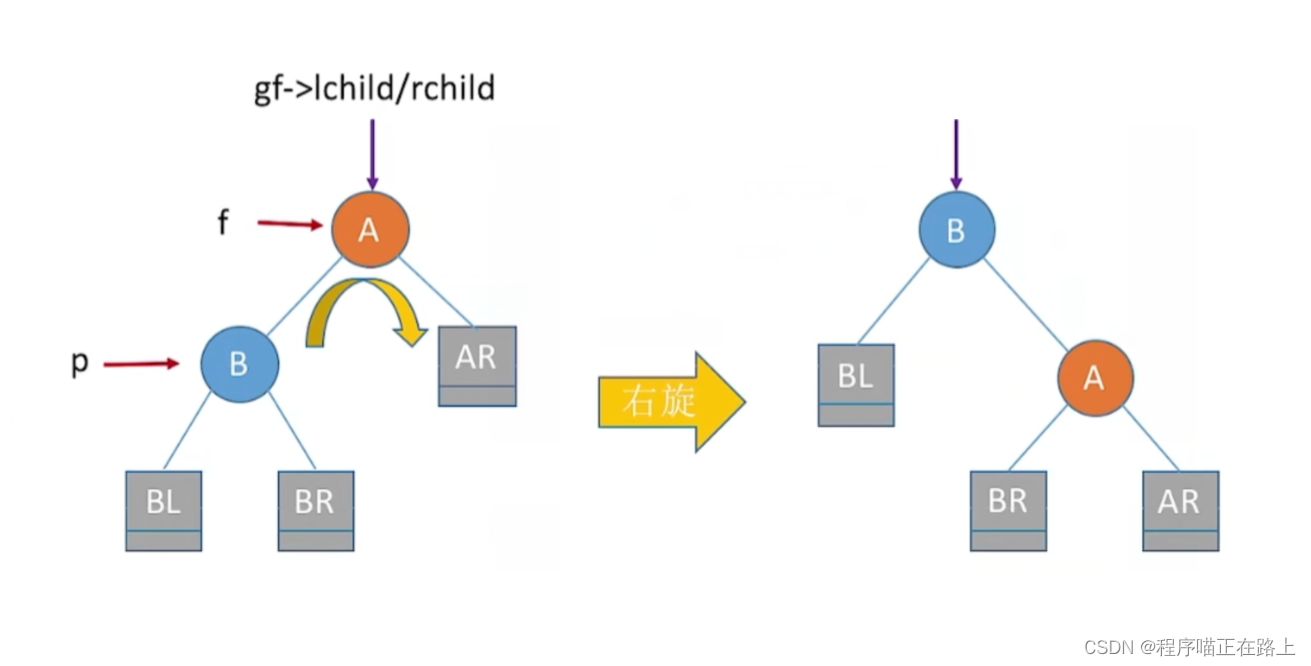
f->lchild = p->rchild;
p->rchild = f;
gf->lchild/rchild = p;
左旋:假设指针 f f f 指向最小不平衡子树的根, p p p 指向根的右子树,那么 f f f 向左下旋转, p p p 向左上旋转,其中 f f f 是爹, p p p 为左孩子, g f gf gf 为 f f f 的爹
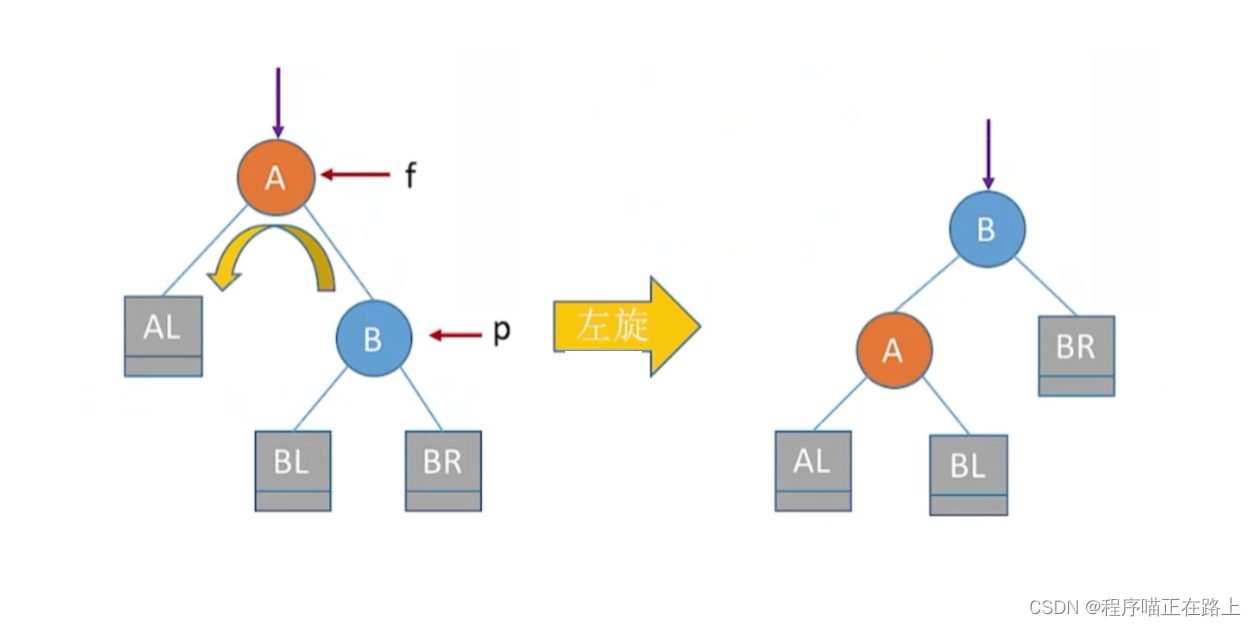
f->rchild = p->lchild;
p->lchild = f;
gf->lchild/rchild = p;
调整最小不平衡子树 —— LR:
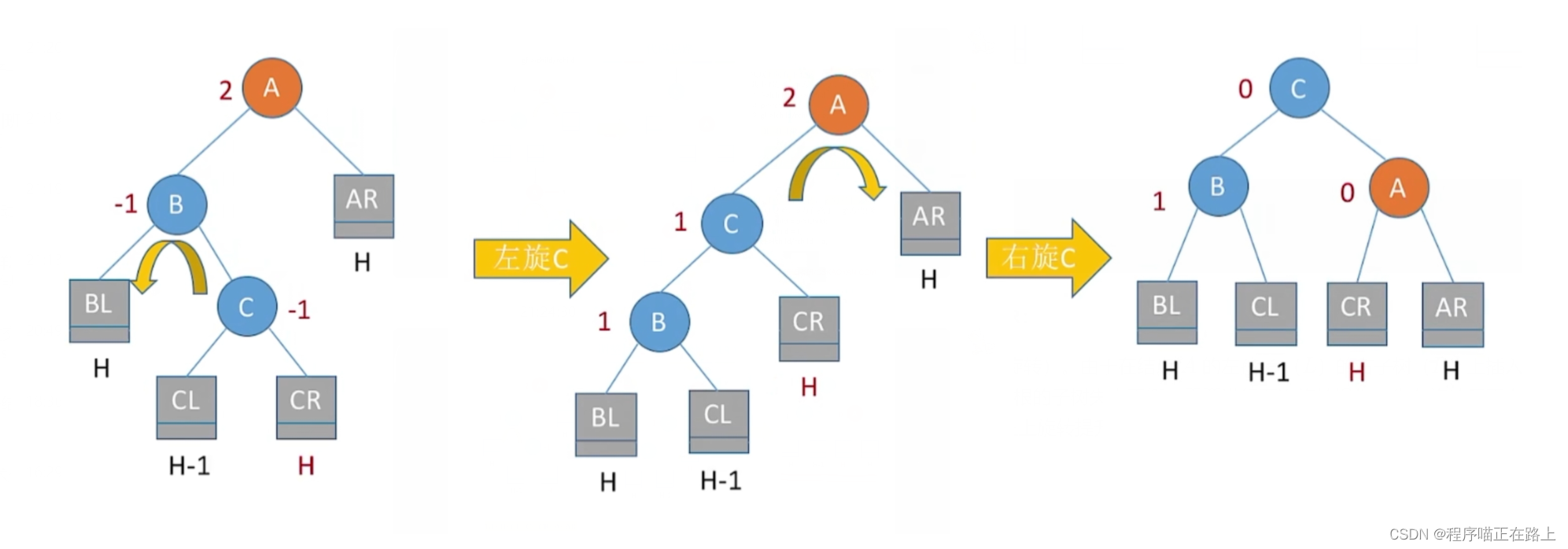
L R LR LR 平衡旋转(先左后右双旋转)。由于在结点 A A A 的左孩子 ( L L L)的右子树( R R R)上插入了新结点, A A A 的平衡因子由 1 1 1 增至 2 2 2,导致以 A A A 为根的子树失去平衡,需要进行两次旋转操作,先左旋转后再右旋转。先将 A A A 的左孩子 B B B 的右子树的根结点 C C C 向左上旋转提升到 B B B 结点的位置,然后再把该 C C C 结点向右上旋转提升到 A A A 结点的位置
调整最小不平衡子树 —— RL:
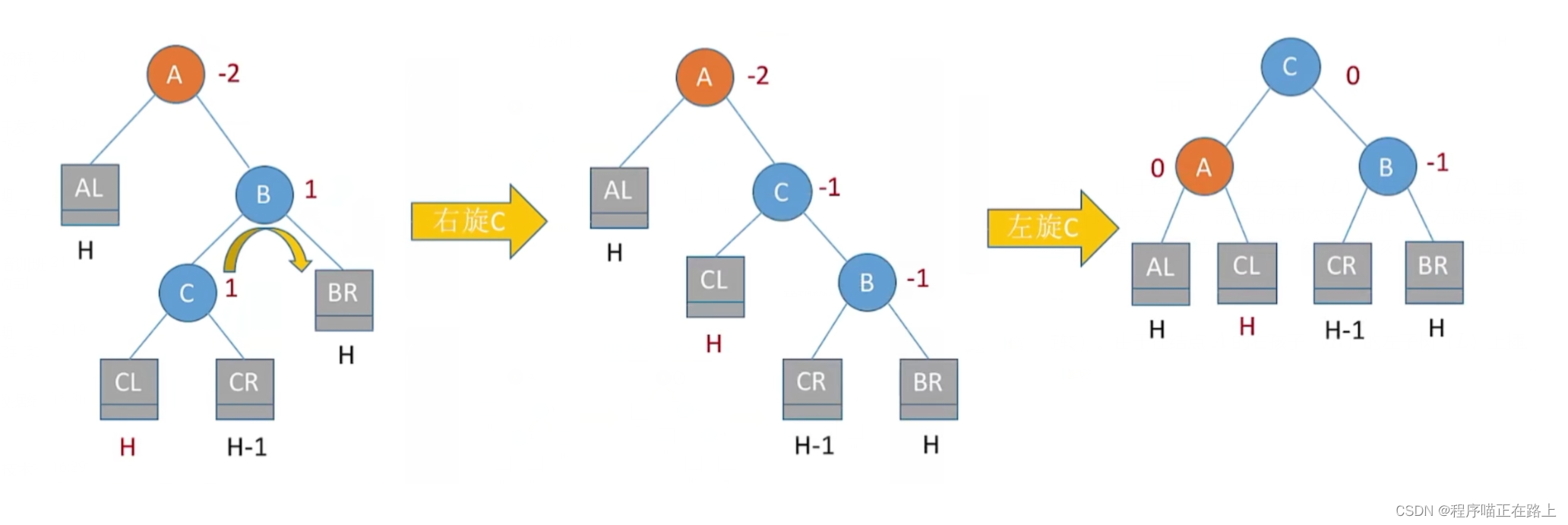
R L RL RL 平衡旋转(先右后左双旋转)。由于在结点 A A A 的右孩子 ( R R R)的左子树( L L L)上插入了新结点, A A A 的平衡因子由 − 1 -1 −1 增至 − 2 -2 −2,导致以 A A A 为根的子树失去平衡,需要进行两次旋转操作,先右旋转后再左旋转。先将 A A A 的右孩子 B B B 的左子树的根结点 C C C 向右上旋转提升到 B B B 结点的位置,然后再把该 C C C 结点向左上旋转提升到 A A A 结点的位置
注意:
只有左孩子才能右上旋,只有右孩子才能左上旋
查找效率分析
若树高为 h h h,则最坏情况下,查找一个关键字最多需要对比 h h h 次,即查找操作的时间复杂度不可能超过 O ( h ) O(h) O(h)
平衡二叉树 —— 树上任一结点的左子树和右子树的高度之差不超过 1 1 1
我们假设以 n h n_h nh 表示深度为 h h h 的平衡树中含有的最少结点数,则有 n 0 = 0 , n 1 = 1 , n 2 = 2 n_0 = 0, n_1= 1, n_2 = 2 n0=0,n1=1,n2=2,并且有 n h = n h − 1 + n h − 2 + 1 n_h = n_{h-1} + n_{h-2} + 1 nh=nh−1+nh−2+1
可以证明含有 n n n 个结点的平衡二叉树的最大深度为 O ( l o g 2 n ) O(log_2{n}) O(log2n),平衡二叉树的平均查找长度为 O ( l o g 2 n ) O(log_2{n}) O(log2n)
哈夫曼树
带权路径长度
结点的权:有某种现实含义的数值(比如表示结点的重要性等)
结点的带权路径长度:从树的根到该结点的路径长度(经过的边数)与该结点上权值的乘积
树的带权路径长度:树中所有叶子结点的带权路径长度之和( W P L , W e i g h t e d P a t h L e n g t h WPL, Weighted \ Path \ Length WPL,Weighted Path Length)
W P L = ∑ i = 1 n w i l i WPL = \sum_{i=1}^{n}w_i l_i WPL=i=1∑nwili
哈夫曼树
在含有 n n n 个带权叶结点的二叉树中,其中带权路径长度( W P L WPL WPL)最小的二叉树称为哈夫曼树,也称为最优二叉树
哈夫曼树的构造
给定 n n n 个权值分别为 w 1 , w 2 , . . . , w n w_1, w_2,..., w_n w1,w2,...,wn 的结点,构造哈夫曼树的算法描述如下:
- 将这 n n n 个结点分别作为 n n n 棵仅含一个结点的二叉树,构成森林 F F F
- 构造一个新结点,从 F F F 中选取两棵根结点权值最小的树作为新结点的左右子树,并且将新结点的权值置为左、右子树上根结点的权值之和
- 从 F F F 中删除刚才选出的两棵树,同时将新得到的树加入 F F F 中
- 重复步骤 2 2 2 和 3 3 3,直至 F F F 中只剩下一棵树为止
哈夫曼树特点:
- 每个初始结点最终都称为叶结点,且权值越小的结点到根结点的路径长度越大
- 哈夫曼树的结点总数为 2 n − 1 2n-1 2n−1
- 哈夫曼树中不存在度为 1 1 1 的结点
- 哈夫曼树并不唯一,但 W P L WPL WPL 必然相同且为最优
哈夫曼编码
固定长度编码 —— 每个字符用相等长度的二进制位表示
可变长度编码 —— 允许对不同字符用不等长的二进制位表示
若没有一个编码是另一个编码的前缀,则称这样的编码为前缀编码,前缀编码解码无歧义,非前缀编码解码有歧义
由哈夫曼树得到哈夫曼编码 —— 字符集中的每个字符作为一个叶子结点,每个字符出现的频度作为结点的权值,根据上面介绍的方法构造哈夫曼树
哈夫曼树不唯一,因此哈夫曼编码也不唯一
哈夫曼编码可用于数据压缩