摘要:本文整理自阿里巴巴高级技术专家,Apache Flink PMC 李劲松(之信),在 FFA 2022 实时湖仓的分享。本篇内容主要分为四个部分:
挑战:Streaming DW 面临的难题
案例:Flink+FTS 典型场景案例
v0.3:FTSV0.3 有什么能力来帮助上述场景
总结:回顾和项目信息
Tips:点击「阅读原文」查看原文视频&演讲 ppt
01
挑战:Streaming DW 面临的难题
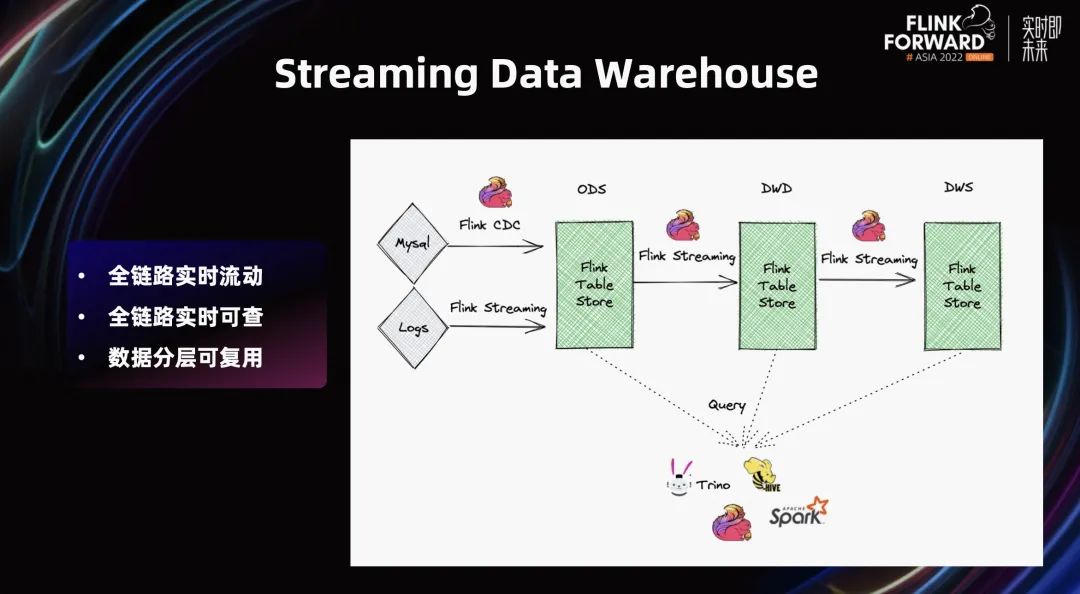
首先,讲一讲 Streaming Data Warehouse 面临的难题。Streaming Data Warehouse 是什么呢?
如上图所示,数据源从 MySQL 或 Logs,通过 Flink CDC 或 Flink Streaming,把数据摄入到仓里。这个仓可以分 ODS 层、DWD 层、DWS 层。每一层的存储写的是 Flink Table Store。
这样一个看起来跟离线数仓相似的 Pipeline,它的特点是全链路实时流动。通过 Flink Streaming 作业串联,在全链路流动的同时,数据沉淀到了 Flink Table Store 的存储上。这个存储不再是之前的 Kafka,只能留,不能查。
这个架构的典型特点是全链路实时可流动,全链路实时可查。这个存储里的数据,能被各生态的计算引擎查询分析。沉淀数据之后,每一份数据在 ODS 层、DWD 层、DWS 层,可以分层复用,减少大量存储和计算的浪费。

虽然这个架构理解起来非常的简单,但却不容易实现。我们来简单分析一下,存储在这个架构中的作用。存储主要有三个作用:
1. 消息队列。因为全链路是流起来的,存储本身要做一个消息队列,可流写、可流读,需要有一定的顺序性。
2. 沉淀数据。沉淀的历史数据需要要面向各生态计算引擎,做到可分析。沉淀数据之后,这部分数据应该被管理。
3. 存储需要增强流计算,让流计算变得更简单,解决流计算的难题。
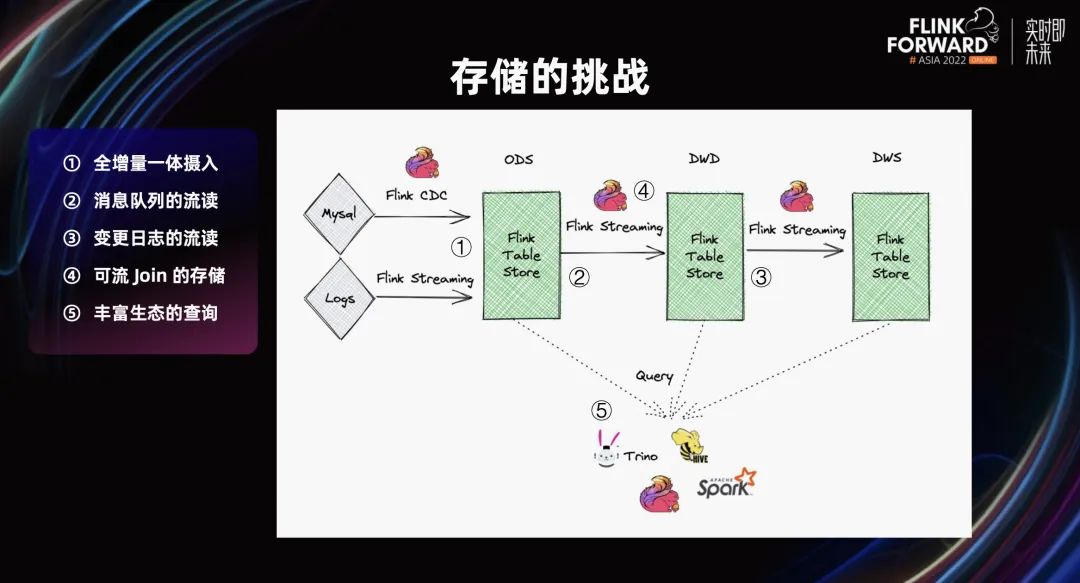
如上图所示,存储在这个架构里发挥了多少作用,又有多少挑战呢?
1. 全增量一体摄入。在一个流作业中,全量数据读完之后,无缝切换到增量数据再读,数据和流作业一起进入下一个环节。存储在这里遇到的挑战是,既然有数据全增量一体摄入,说明数据量很大,数据乱序很严重。存储能不能撑住?能不能用高吞吐来支撑全增量一体摄入?
2. 消息队列的流读。存储本身作为消息队列需要流写、流读,非常灵活。存储能不能提供全增量一体的流读?能不能指定 timestamp 从历史开始读增量?
3. Changelog 的流读。图中的第三部分,Flink 基于 State 的计算严格依赖 Changelog。如果 Changelog 错误,Flink 计算将出现各种各样正确性的问题。当用户输入到存储后,从存储流读的 log 是否准确?变更日志是否完整?这些问题是非常关键。
4. 可流 Join 的存储。目前,流计算中 Join 是非常头疼的问题。不光是流计算本身在存储和流计算结合,存储本身也应该在流 Join 上发挥较大的作用。
5. 丰富生态的查询。存储跟计算不一样,存储要有比较好的生态。因为不能假设计算能解决一切问题,所以存储需要被各种引擎查询。它必须有一个较好的生态。
02
案例:Flink+FTS 典型场景案例
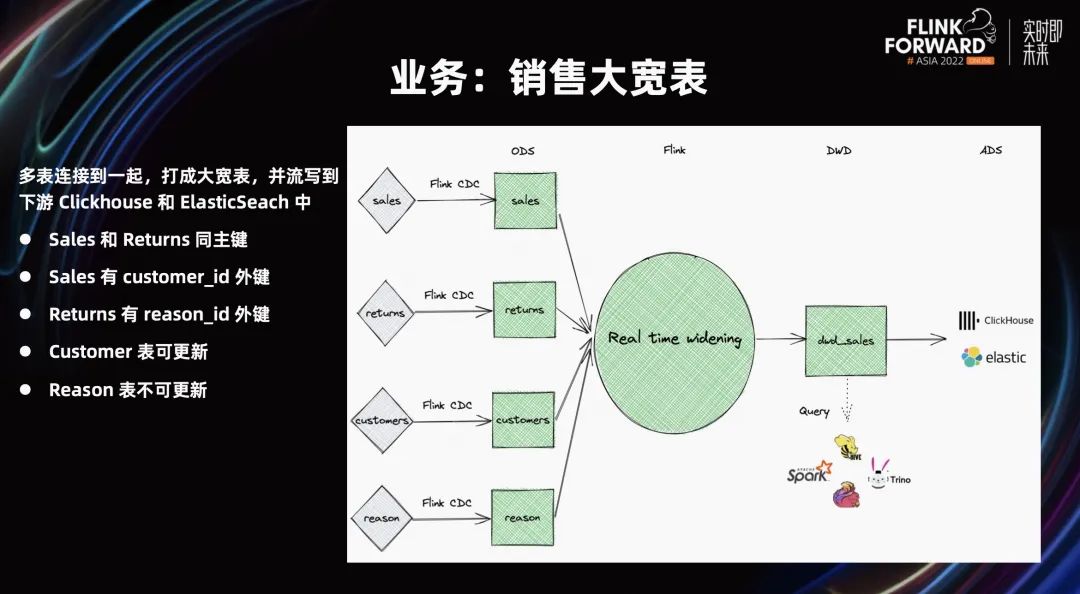
如上图所示,在业务上这个案例是一个销售大宽表。它的业务逻辑是上图中的的四张表,我需要把订单表、退货表、顾客表和退货原因表,打宽到一起,方便各种引擎查询。
接着,增量数据写到 Clickhouse 或 ElasticSeach 中。Trino + FTS 的查询可以满足不少场景,但是有些查询的要求更高,它的依赖面向 OLAP 面向索引。
因此,四个多表连接到一起,打成大宽表,然后写到一张表当中,并且增量数据写到下游的引擎中。在流计算中,如何做到 realtime 的打宽?这是一个比较难的问题。
我们先来分析下此例子中的各个表,因为订单表和退货表是同主键的,它们都有订单 ID,订单表中也有顾客 ID,它可以和顾客表进行 Join,获取一些维表信息。其次,顾客表一直在变化,顾客可以修改自己的信息。最后,退货原因表是不可变的。因为退货就原因,一般是不能被编辑的。
对于业务来说,有一个非常简单的思路,就是把这四张表 Join 一下,然后写到存储当中。但是这种方法的代价非常高,存储会成倍增加,成本非常高。
面对真实的业务,我们想让业务实现更多的离线计算、离线 Pipeline 变的实时化。但业务切换到实时化后,实时计算的成本是离线计算的数十倍。
所以针对此案例,如何使用 Flink Table Store 呢?

我们首先创建 DWD 的大宽表。订单 ID 是主键,有些字段来自订单表,有些字段来自退货表,还有一些字段来自顾客表和退货原因表。
通过定义,它声明 merge-engine=partial-update,changelog-producer=full-compaction,剩下的两个是相关的参数。
通过 Flink Table Store 的 partial-update 的能力,使得相同的两张表同时写到一个大宽表当中,更新各自的字段,互不影响。而且因为配置了 changelog-producer,所以在 Compaction 时会产生正确的宽表日志,下游的流读可以读到最新合并后的数据。
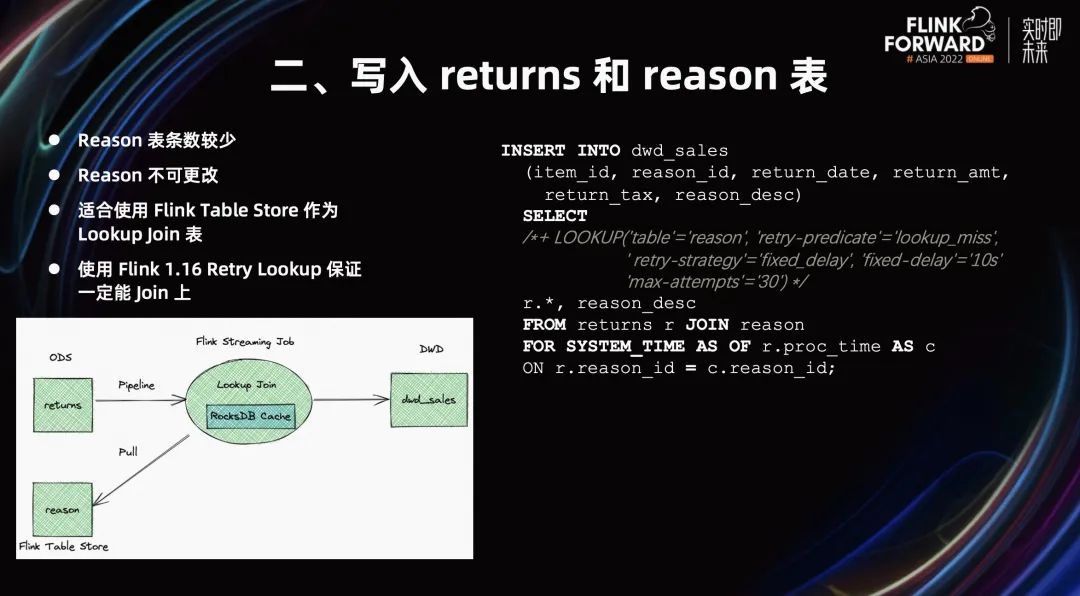
接下来,对于顾客表和退货原因表,怎么打宽?
退货原因表有一个特点是,它的表条数较少,退货表不可更改。所以它比较适合使用 Flink Table Store 作为 Lookup Join 表。进行 Lookup Join,Flink Table Store 会维护一些磁盘 cache。用户不用担心数据量太大,导致 OOM。
结合使用 Flink 1.16 Retry Lookup,保证退货表一定能 Join 到 reason 表。即使 reason 表更新较慢,它也能保证 Join 上。通过 Flink Retry Lookup 的方式,成本比较低。
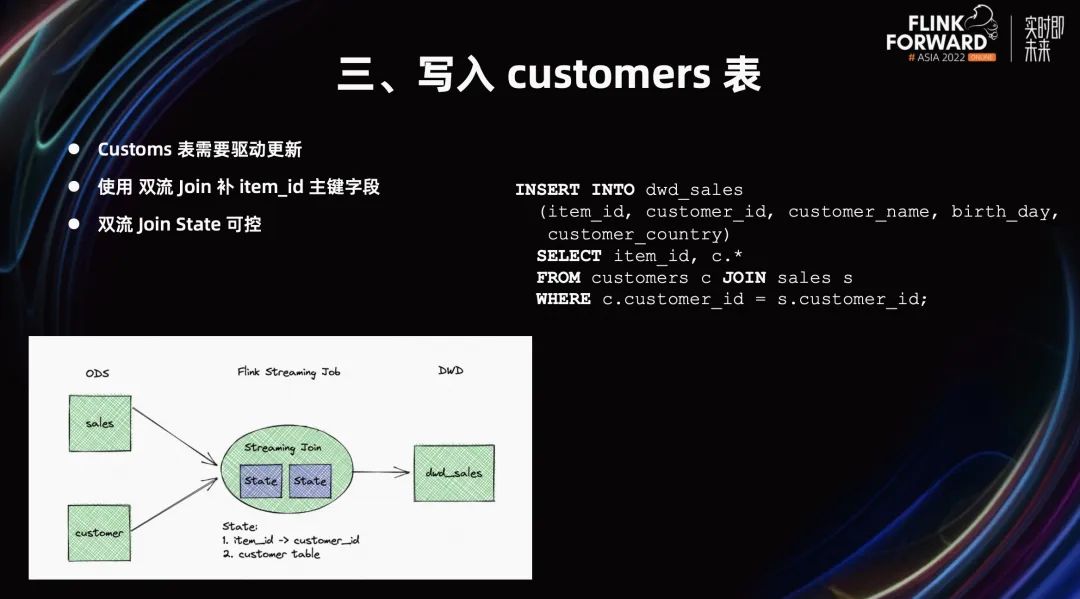
接下来,讲一讲顾客表。顾客表跟退货表不一样,顾客表的数据量较大,它需要驱动更新。结合 Flink Table Store,希望能提供一个新的思路。
顾客表和订单表 Join,它只有订单 ID 和顾客 ID 的映射关系,以及顾客表的其它字段。顾客表没有订单表的主键。所以这里的需求是,我们需要给顾客表拿到订单表的主键,也就是订单 ID。
我们可以启动一个双流 Join 来使得顾客表拿到订单 ID,这个双流 Join 的 State 存储成本是 订单 ID 和顾客 ID 的映射关系,以及顾客表的内容,我们可以认为这个 State 不太大,它的成本可控,毕竟它没有保存庞大的订单表。
经过 Join 之后,这个顾客表就能拿到订单 ID,可以进行上述基于 FTS 的 Partial Update。
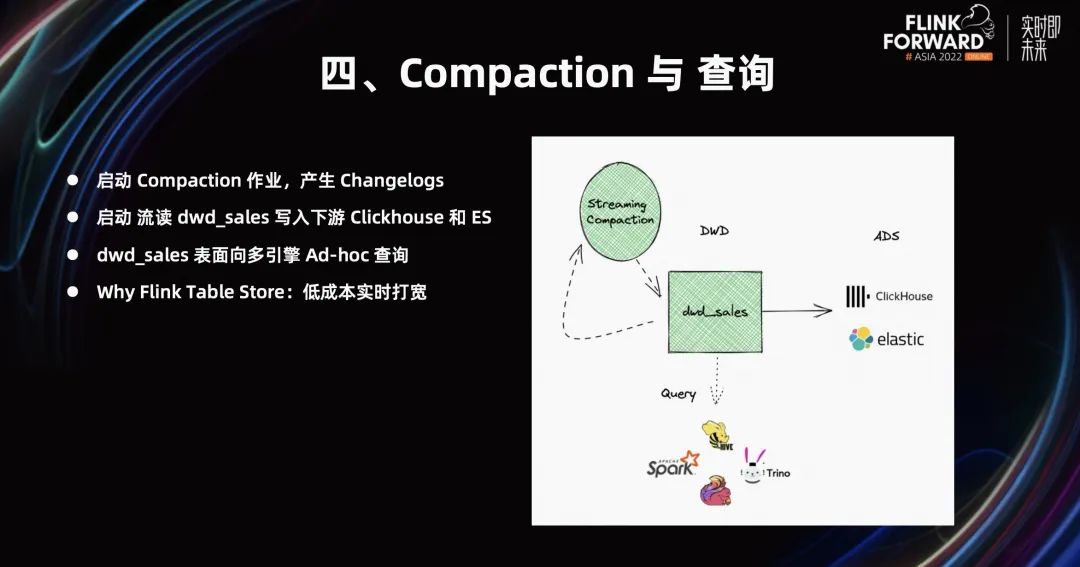
完成上游四张表 Partial Update 的写入之后,最后启动 Compaction 作业,它会不断地产生 Changelog。所以下游可以启动流读作业,来流读这张大宽表,写入下游 Clickhouse 和 ES 当中。除此之外,这张大宽表面向多引擎,可以进行 Ad-hoc 查询,你可以使用 Hive、Spark、Flink 或者 Trino 来实时查询。
为什么要选择 Flink Table Store 呢?因为 Flink Table Store 使用方便,能够低成本实时打宽。
03
V0.3:FTSV0.3 有什么能力
来帮助上述场景
即将发布的 Flink Table Store 0.3,有哪些功能实现上述的场景?
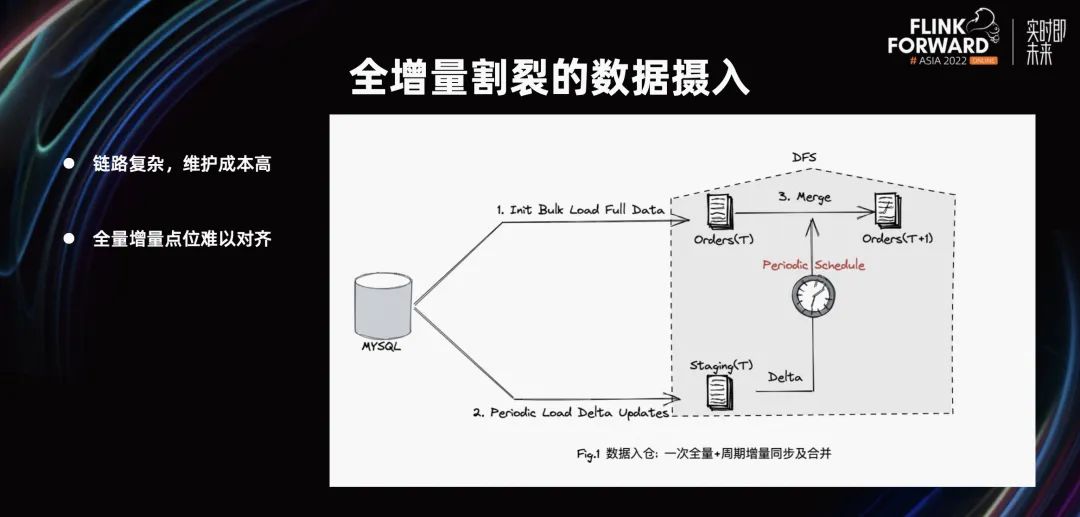
第一个场景,全增量一体导入。在早期版本中,从 MySQL 把所有数据 Bulk Load 到一张表中。然后,将定期的增量数据 Load 到数仓当中,进行定期的调度作业。
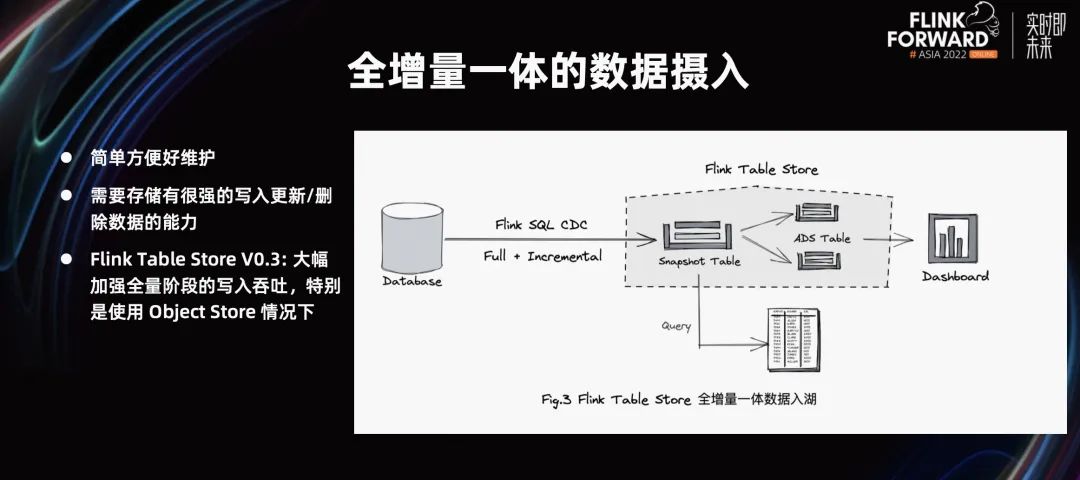
这个流程链路较复杂,维护成本比较高。由于全量增量点位较难以对齐,所以全增量一起导入,后期不用维护。除此之外,需要存储有较强的写入、更新、删除数据的能力,才能撑得住大数据流量。
Flink Table Store 0.3 大幅增强全量阶段的写入存储,特别是写入时使用的对象存储,0.3 大幅增强吞吐能力,有比较好的吞吐性。
后续在 0.4 中,也将提供整库同步和 Schema Evolution 同步,将更好的提高入湖的用户体验。
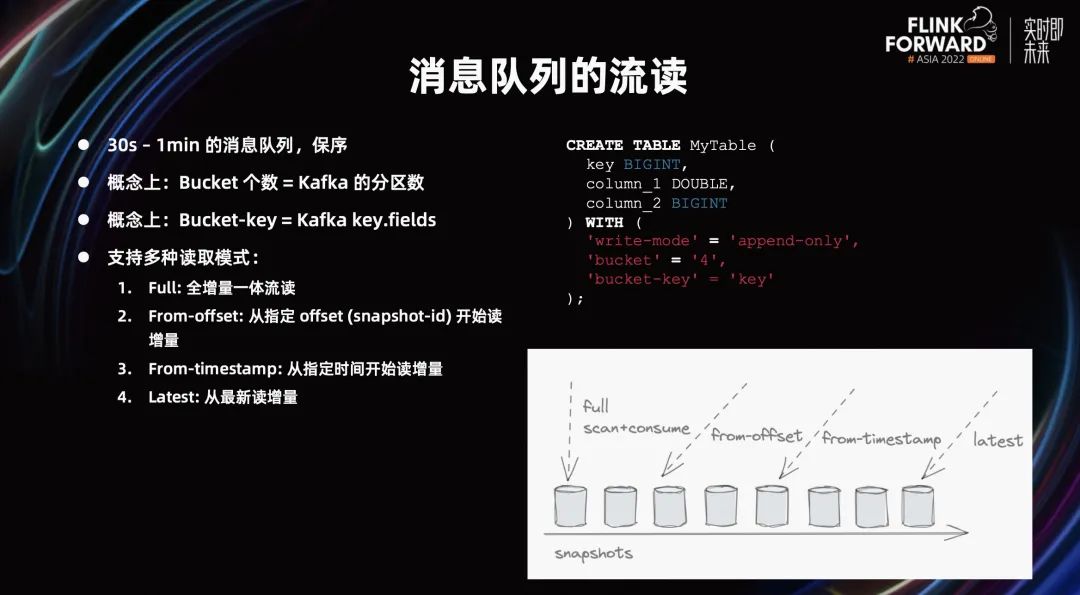
第二个场景消息队列的流读。作为消息队列必须要好用,在不声明 Kafka 的情况下,Flink Table Store 表的流读,希望能做到 30 秒到 1 分钟的延迟,跟消息队列的顺序一致。并且 Flink Table Store 也支持多种啊读取模式。比如全增量一起的流读,每次读都能看到所有的数据。
除此之外,你可以通过 from-snapshot,从指定 snapshot-id 开始读增量。你也可以通过 from-timestamp,从指定时间开始读增量。你还可以指定 Latest,从最新数据,读增量。Flink Table Store 的消息队列跟 Kafka 完全对齐。

第三个场景,变更日志流读。
举个例子,如上图所示,当你声明主键之后:
1. 插入一条数据,主键为 1,column_1 为 1.0.
2. 再次插入了一条数据,主键仍为 1,column_1 为 2.0.
3. 此时,对流作业进行流读,SUM 的结果应该是 3.0 还是 2.0?
简单的计算,SUM 的结果就是 3.0,因为出现过两条数据,所以加起来就是 3.0。但是,这两条数据是相同的主键,它在更新时应该产生撤回,正确答案应该是 2.0。
Flink Table Store 提供多种 Changelog Producer 模式:
1. 比如 None,存储不产生 Changelog,交给 Flink SQL 产生。Flink SQL 流读的下游会产生一个相关节点,让下游流作业使用 Changelog Normalize 节点。这个节点的 Cost 比较大。
2. 比如 Input,当 input 来自数据库 CDC 的输入,如果可以无条件信任 input,你可以选择 Input,来自数据库的 CDC 数据可以保证流读到正确的 Changelog。
3. 在 Flink Table Store 0.3 中,提供了 Full-Compaction,随着 Full-Compaction 产生完全正确的 Changelog,对流作业的正确性,各种模式的支持非常有用,但是你需要平衡 Full-Compaction 的成本和多久进行一次 Full-Compaction 的时延。
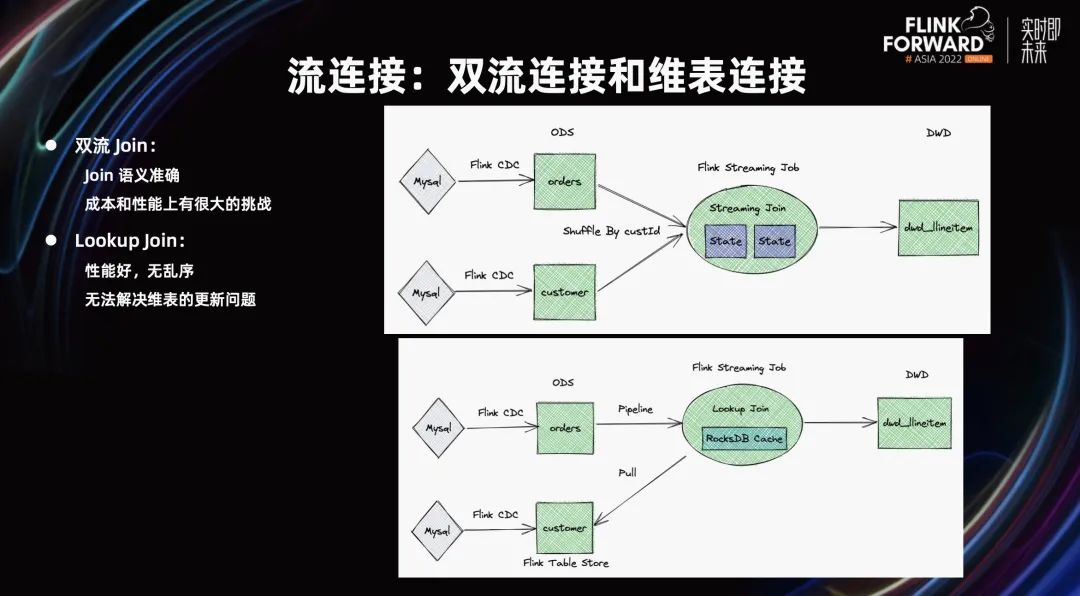
第四个场景,流连接。存储对流式数仓到底起什么作用?我们主要规定了三个作用,即消息队列、临时数据可查、生态好。在 Flink Table Store 0.3,继续加强了生态。当前,流面对的挑战仍有很多,最大的挑战是 Join。典型的 Join 有四种模式可以支持。
第一个模式,双流 Join。假设拿到两个 CDC 的流,按照 Flink SQL 写法,Join 的结果就可以往下写了。此时,Join 要处理两条流,在 Streaming Join 中需要物化,在 State 中保存两个流物化的所有数据。假设 MySQL 中分库分表有 1000 万条,Streaming 中就要保存 1000 万条,而且如果有多个 Join,数据将会被重复的保存,造成大量的成本。
双流 Join 的好处是,Join 的语义非常正确,有保证,任何更新都能正确处理。但它缺点是,成本和性能有比较大的挑战,其成本非常高。
第二个模式,Lookup Join。假设定义一张叫表叫主流,主流过来需要 Join 补字段。此时,可以把维表当做镜像表,在维表数据来的时候,不断 Lookup 维表数据。Lookup Join 的好处是性能非常好,主表不会乱序,但无法解决维表的更新问题。
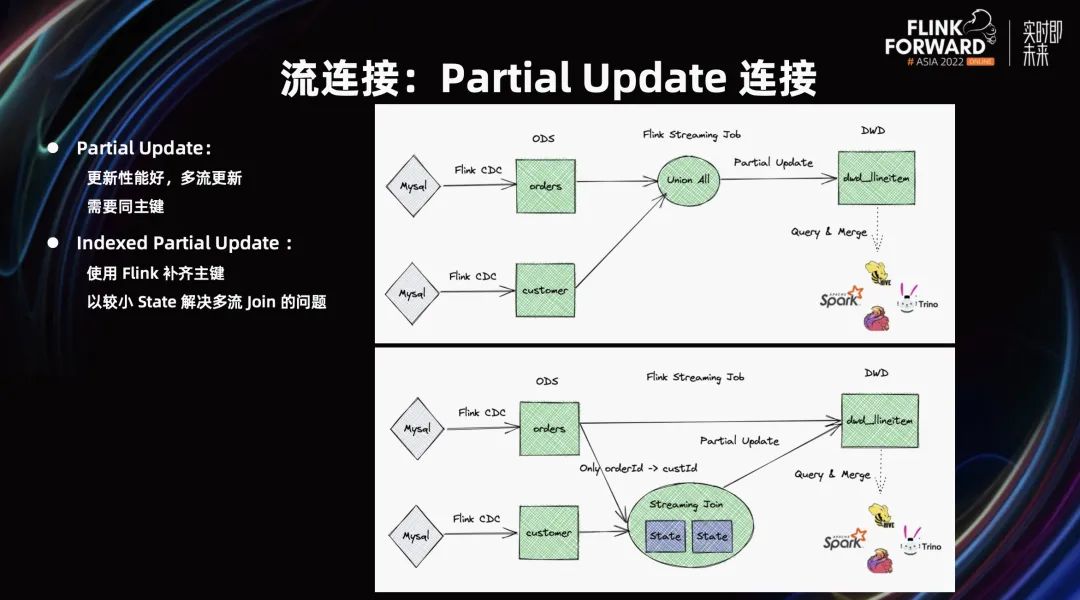
第三个模式,Partial Update。它可以帮助 Streaming 来做 Join 能力。Partial Up date 的本质是存储本身,具有通过组件来更新部分列的能力。如果两张表都有相同主键,它们可以分别进行 Partial Update。它的好处是性能非常好,给存储很多空间来优化性能。性能较好,成本较低。但它的缺点是需要有同主键。
第四个模式,Indexed Partial Update。它可以使用 Flink 补齐主键,只需要拿到该主键件和主表主键间的映射关系即可。其次,由于维表的数据量比主表数据量要小很多,所以成本可控。通过使用 Flink 补齐主键之后,以较小 State 解决多流 Join 的问题。
综上所述,我们希望提供尽可能多的 Join 模式,让大家根据自己的业务来选择需要的模式。
04
总结:回顾和项目信息

第一部分,我们分析目前 Streaming Data Warehouse 的问题。它的主要挑战是架构,我们在逐步解决;
第二部分,我们描述 Flink Table Store V0.3 核心解决的场景;
第三部分,我们将了讲 Flink Table Store V0.3 哪些功能能帮助上述案例;
第四部分,Flink Table Store 会继续加强 Streaming Data Warehouse,来解决更多问题。
■ 如果有需求和问题,请联系我们!

Flink Table Store 作为 Apache Flink 的子项目,它有自己的用户文档。用户可以通过相关链接,咨询相关问题。与此同时,推荐大家入钉钉群,与我们直接沟通。

往期精选





▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」,查看原文视频&演讲 PPT
点击「阅读原文」,查看原文视频&演讲 PPT