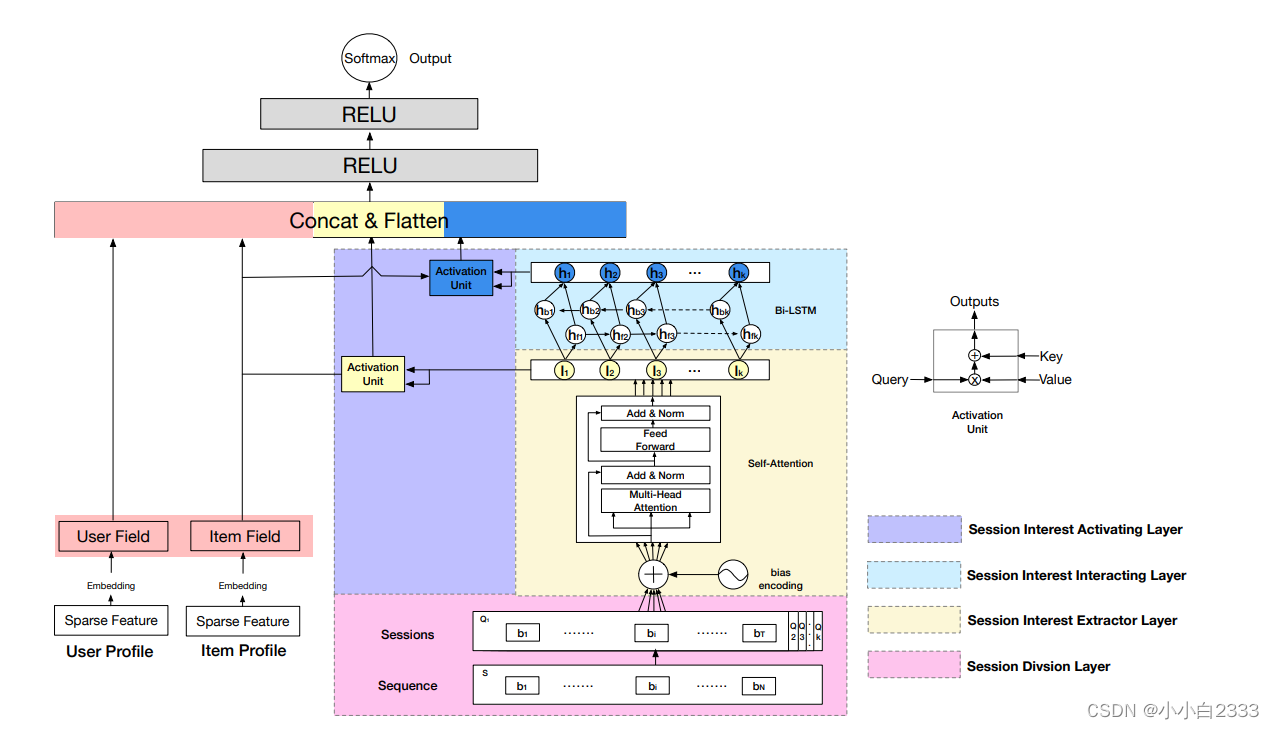
OpenCV各模块函数使用实例(11)
M、矩阵和数组操作(Operations on arrays)
本节描述矩阵的基本操作,这些操作是图像处理和其他数组算法实现的基本操作,包括矩阵的运算,特征值和特征向量,范数和逆矩阵,高阶多项式的根等数学运算。矩阵运算包括点积,叉积,卷积,滤波,匹配、统计分析等,都离不开矩阵的基本运算。下面介绍这些基本的矩阵运算,并编程实现查看运算效果,对运算有一个感性认知。函数的解释来源于opencv的core functions模块的operations for arrays节,编程实现由本人完成,使用opencv2.4.9版,对于更高版本的算法内容,移植于opencv的高版本源码。使用vs2010的win32 C++。
(1)、像素的算术操作
cv::absdiff (InputArray src1, InputArray src2, OutputArray dst)
逐元素计算两个数组之间差的绝对值或数组与标量之间差的绝对值。函数 cv::absdiff 计算有相同尺寸和类型的两个数组的差的绝对值:

当第二个数组是使用Scalar构造的且与src1有相同的通道数的标量数组,则差的绝对值为:

如果第一个数组是使用Scalar构造的且与src2有相同的通道数的标量数组,则差的绝对值:

这里的I 是数组元素的多维索引。在多通道数组中,每个通道单独处理。
注意
在深度为CV_32S 时,不进行饱和运算(Saturation)。此时在溢出的场合下可能得到负元素值。
参数
src1 | 第一个数组或标量 |
src2 | 第二个数组或标量 |
dst | 输出数组,与输入数组有相同的尺寸和类型 |
参见
cv::abs(constMat&)
例:
cv::absdiff(image1,image2,dst);
cv::absdiff(image1, Scalar(0,0,1),dst);
cv::absdiff(Scalar(0,0,1), image2,dst);
两个图像矩阵的绝对差,如图:

这里的显示图只能说明矩阵的逐元素操作有图像的显示意义,没有任何图像处理的实际意义,除非应用到视频流中可以检测到运动图像及目标跟踪的意义。以下图像现实都只有矩阵操作的意义。
cv::add (InputArray src1, InputArray src2, OutputArray dst,
InputArray mask=noArray(), int dtype=-1)
计算两数组或数组与标量之间的元素和。这个函数计算如下:
计算两个数组的和,如果两个数组有相同的尺寸和通道数:

计算数组和标量的和,如果src2由Scalar构造且与src1有相同的元素通道数:
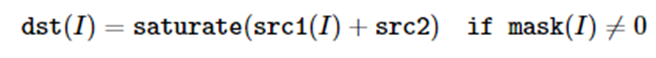
计算标量和数组的和,如果src1由Scalar构造且与src2有相同的元素通道数:

此处I 是数组元素的多维索引。对于多通道数组,每个通道单独处理。上述列表的头一个函数可以用矩阵表达式替换:
dst = src1 + src2;
dst += src1; // 等价于add(dst, src1,dst);
输入和输出数组都可以有相同或不同的深度。例如,将16位无符号数组加到8位有符号数组并存储和数组为32位浮点数组。输出数组的深度由dtype参数确定。在上面的第二和第三种情况,dtype可以设置为默认的-1,在第一种情况,如果src1.depth() == src2.depth(),dtype 也可以设置成默认的-1。此时输出数组与输入数组有相同的深度,可以是src1,src2或二者的深度。
注意
在输出数组深度为CV_32S 时,不执行Saturate运算。此时可能会获得不正确的负结果,这表明有溢出发生。
参数
src1 | 第一个输入数组或标量 |
src2 | 第二个输入数组或标量 |
dst | 输出数组,与输入数组有相同的尺寸和通道数,深度由dtype 或src1/src2确定 |
mask | 可选的操作屏蔽,8位单通道数组,指定可更改的输出数组元素 |
dtype | 可选的输出数组的深度(参见下面的讨论) |
参见
subtract, addWeighted, scaleAdd, Mat::convertTo
例:
cv::add (image1, image2, dst, noArray(), -1);
cv::add (image1, Scalar(0,0,1),dst, noArray(), -1);
cv::add (Scalar(0,0,1), image2,dst, noArray(), -1);
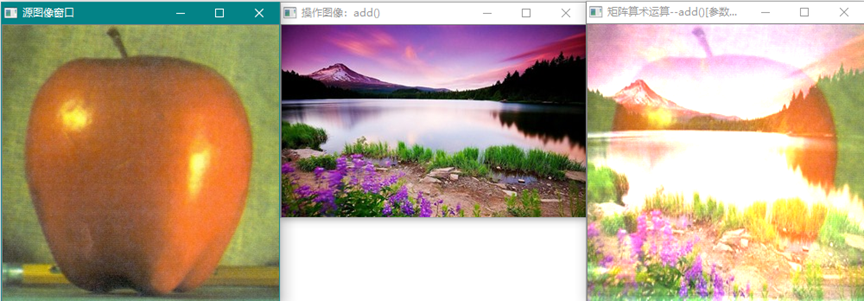
图像相加。
cv::subtract (InputArray src1, InputArray src2, OutputArray dst,
InputArray mask=noArray(), int dtype=-1)
计算两数组或数组与标量的像素差。这个函数做减法操作:
两个数组之间的差,输入数组有相同的尺寸和通道数:

数组与标量的差,如果src2 由Scalar构造且有相同的元素通道数:

标量与数组的差,如果src1 由Scalar 构造且有相同的元素通道数:

标量和数组的反向差,在SubRS场合:

此处I 是数组元素的多维索引。对于多通道数组,每个通道单独处理。
在第一种场合下,函数可以表示为矩阵表达式:
dst =src1 - src2;
dst-= src1; // 等价于subtract(dst, src1, dst);
输入数组和输出数组都可以有相同或不同的深度。例如,可以减一个8-位无符号数组并存储为不同的16位有符号数组。输出数组的深度由参数dtype 确定。在第二和第三中场及第一种场合下如果src1.depth() == src2.depth(),dtype可以设置为默认值-1。此时,输出数组与输入数组有相同的深度,可以是src1,src2 或二者的深度。
注意
在输出数组有CV_32S 深度时,不能执行饱和运算。在这种溢出的场合下可能得出不正确的带符号结果。
参数
src1 | 第一个输入数组或标量 |
src2 | 第二个输入数组或标量 |
dst | 输出数组,与输入数组同尺寸和通道数 |
mask | 可选操作屏蔽;这是一个8位单通道数组,指定可更改的输出数组元素 |
dtype | 可选的输出数组深度 |
参见
add, addWeighted, scaleAdd, Mat::convertTo
例:
cv::subtract(image1, image2,dst, noArray(), -1);
cv::subtract(image1, Scalar(0,0,1),dst, noArray(), -1);
cv::subtract(Scalar(0,0,1), image2,dst, noArray(), -1);
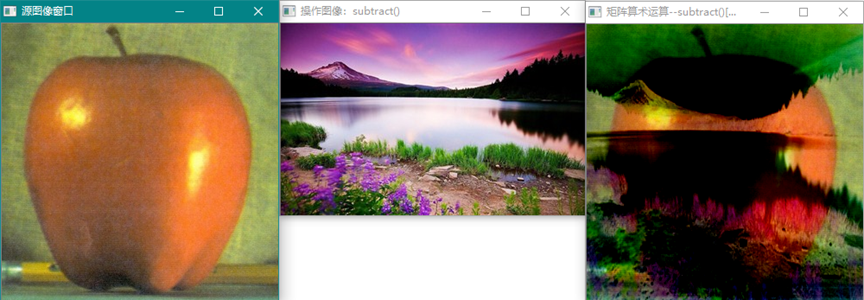
图像相减。
Scalar cv::sum (InputArray src)
计算数组元素的和,返回标量。每个通道单独处理。在对数组进行统计运算或计算矩阵的模或均值时用到sum函数。
cv::addWeighted (InputArray src1, double alpha, InputArray src2, double beta,
double gamma, OutputArray dst, int dtype=-1)
计算两个数组的权重和。

例:
dst= src1*alpha + src2*beta + gamma;
这是矩阵表达式方式的权重和。

权重和,当alpha=beta=1,gamma=0时,权重和与add()结果相同。
cv::multiply (InputArray src1, InputArray src2, OutputArray dst,
double scale=1, int dtype=-1)
数组元素的乘积:
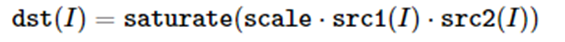
参见矩阵表达式的Mat::mul。

矩阵乘积(逐像素),scale=0.01和scale=0.02的结果图像。再大的scale将饱和到白色。
cv::gemm (InputArray src1, InputArray src2,double alpha, InputArray src3,
double beta, OutputArray dst,int flags=0)
执行普通的矩阵乘法(不是元素乘积):

矩阵表达式的例:
dst= alpha*src1.t()*src2 + beta*src3.t();
这是真实的矩阵乘积,非像素乘积,图像表示没有意义:

两个图像的矩阵乘积(是矩阵的积,dij = s1i * s2j)。gemm操作需要src1的列数与src2的行数相同,因此在操作前需要处理src1/2,使之满足gemm的要求,否则gemm给出异常。本例中将src1/2变换到相同尺寸(以src1为准),然后转置src2(src3 = noarray(),beta=0):
cv::gemm(src1,src2.t(), alpha,noArray(), 0, dst);
cv::mulTransposed (InputArray src, OutputArray dst, bool aTa,
InputArray delta=noArray(), double scale=1, int dtype=-1)
数组的转置乘积,如果参数aTa = true:
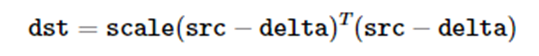
否则:

这个函数可用于计算协方差矩阵。
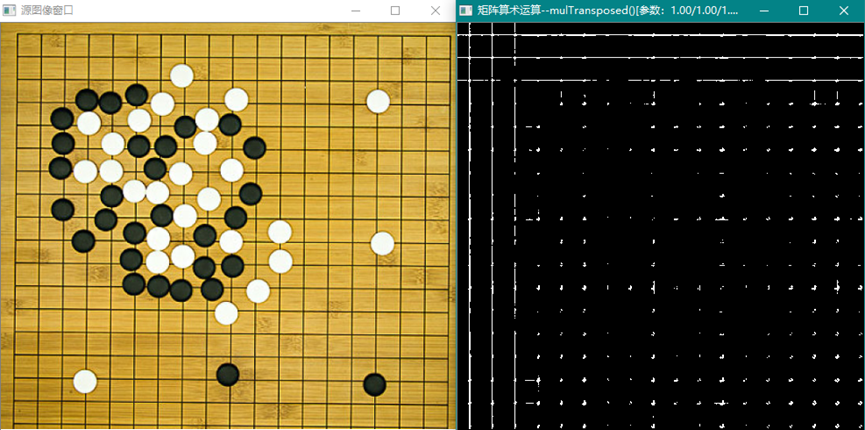
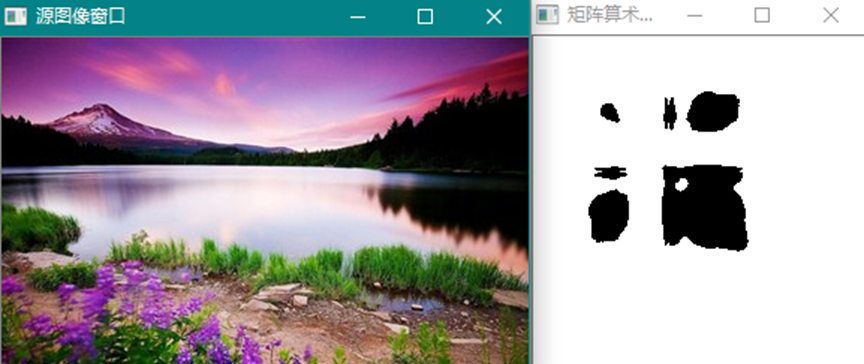
结果图像没有任何图像意义,其数学意义为矩阵的积。结果是正方形矩阵。
cv::scaleAdd (InputArray src1,double alpha, InputArray src2, OutputArray dst)
计算数组的变比加。
例:
Mat A(3, 3, CV_64F);
...
A.row(0) = A.row(1)*2+ A.row(2);

Scale=1时,等价于add()。
cv::setIdentity (InputOutputArray mtx, const Scalar &s=Scalar(1))
按比例初始化一个单位矩阵:

设置对角线元素为指定值。
例:
Mat A = Mat::eye(4,3, CV_32F)*5;
// Awill be set to [[5, 0, 0], [0, 5, 0], [0, 0, 5], [0, 0, 0]]
cv::divide (InputArray src1, InputArray src2, OutputArray dst,
double scale=1, int dtype=-1)
cv::divide (doublescale, InputArray src2, OutputArray dst,int dtype=-1)
执行两个矩阵或数组的除法操作,当src2的元素为0时,dst的对应元素也为0。src1可以是标量,此时dst = scale / src2(I)。

这是图像像素的除法操作结果。这只是显示了矩阵之间的除法操作。在图像上可看出除法操作有反黑为白的现象。
(2)、像素的位操作
cv::bitwise_and (InputArray src1, InputArray src2, OutputArray dst,
InputArray mask=noArray())
cv::bitwise_not (InputArray src, OutputArray dst,
InputArray mask=noArray())
cv::bitwise_or (InputArray src1, InputArray src2, OutputArray dst,
InputArray mask=noArray())
cv::bitwise_xor (InputArray src1, InputArray src2, OutputArray dst,
InputArray mask=noArray())
位操作是直接数组元素的位操作:




其中对于二元操作,src1或src2可以是Scalar构造的标量。

这是图像的位逻辑操作的结果,与、非、或、异或。
(3)、矩阵的统计操作
cv::calcCovarMatrix (const Mat *samples, int nsamples, Mat &covar, Mat &mean,
int flags, int ctype=CV_64F)
cv::calcCovarMatrix (InputArray samples, OutputArray covar,
InputOutputArray mean, int flags, int ctype=CV_64F)
计算矢量集的协方差矩阵。函数cv::calcCovarMatrix 计算协方差矩阵并可选择地输入/出矢量集的平均矢量。
参数
samples | 存储各个矩阵的实例 |
nsamples | 实例数 |
covar | 输出的协方差矩阵,类型为ctype,且有方形尺寸 |
mean | 输入或输出数组(依赖于flags参数),作为输入矢量的平均值 |
flags | 操作标志,是CovarFlags的组合 |
ctype | 矩阵类型,默认为CV_64F |
注,计算协方差的方法就是用到矩阵的基本运算:
计算采样的平均值mean,使用reduce()函数的CV_REDUCE_AVG方法
使用mulTransposed()函数计算协方差(aTa)。
在使用第一种方法时,采样矩阵(图像)可以变换成(1,n)形式的矩阵序列,然后进行计算,如:
for (int i = 0; i < maxSz0; i++){
vecM.push_back(src.row(i));
}
cv::calcCovarMatrix (&vecM[0], maxSz0, opMat, meanMat, CV_COVAR_NORMAL |CV_COVAR_ROWS);
使用第二种方法则:
cv::calcCovarMatrix(src, opMat, meanMat, CV_COVAR_NORMAL| CV_COVAR_ROWS);
此时函数内部自动把src看作为行(1,n)采样。
经过函数calcCovarMatrix()运算的图像,没有图像意义,仅作为协方差数据显示:
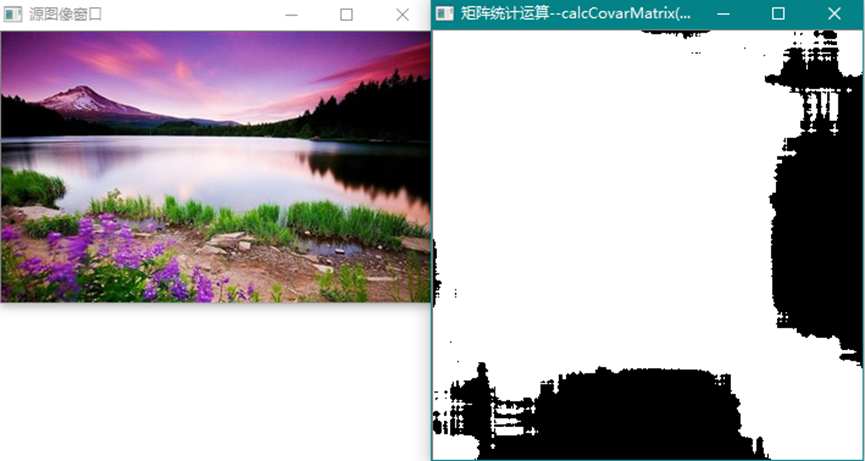
这是源图的协方差数据矩阵(方形)。

这是经过高斯滤波后的协方差数据矩阵。

这是经过canny运算后的特征图的协方差数据矩阵。
注意,协方差矩阵是对称矩阵,这从上面的途中可以看出,源图和滤波图的协方差数据有一些细微的变化,相对于特征图,差异就很明显了。
cv::cartToPolar (InputArray x, InputArray y, OutputArray magnitude,
OutputArray angle,bool angleInDegrees=false)
cv::polarToCart (InputArray magnitude, InputArray angle, OutputArray x,
OutputArray y,bool angleInDegrees=false)
矢量的坐标变换。cartToPolar从(x,y)计算极坐标的模和角度,polarToCart从极坐标的模和角度计算(x,y)。
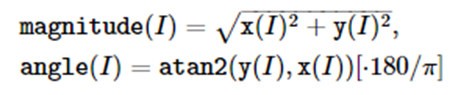
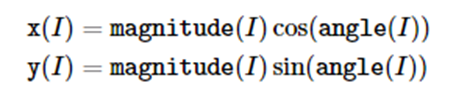
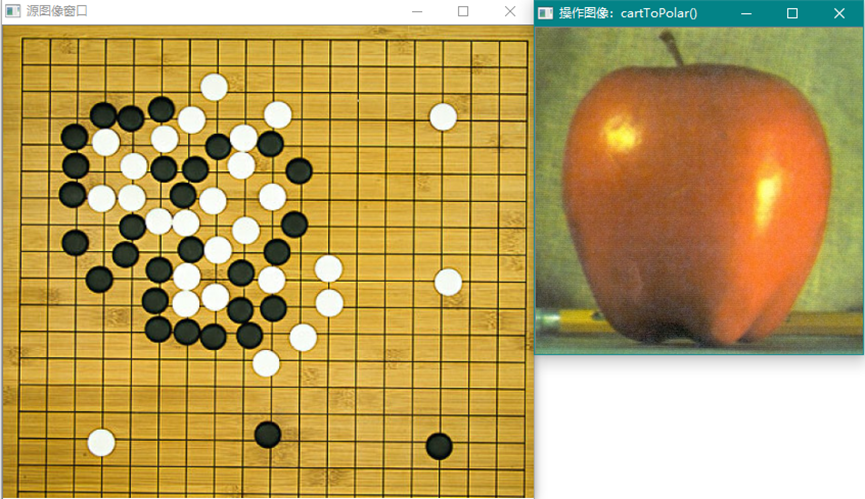
用两个图像分别表示x,y数组,计算坐标变换操作过程,并显示结果,注意结果没有图像学意义。首先是magnitude和angle的计算:
这是参与运算的源图x和y图,首先用cv::cvtColor()函数变换为灰度图,然后进行cartToPolar()操作,注意,使用resize()保证两个图像的尺寸一致:

一个是角度值呈像,一个是magnitude(模)值呈象。下面是polarToCart()操作:
使用源图作为magnitude和angle,计算x,y的值。
cv::magnitude (InputArray x, InputArray y, OutputArray magnitude)
计算矢量的模。

计算输入图像的模(magnitude):
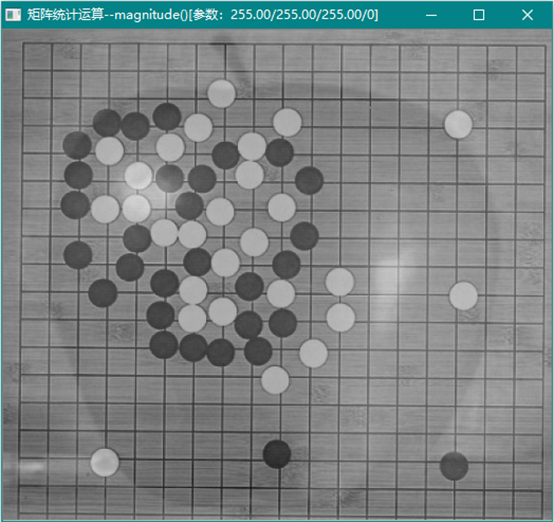
等同于cartToPolar()函数的模图像。
cv::phase (InputArray x, InputArray y, OutputArray angle,bool angleInDegrees=false)
计算2D矢量的转角(相位角)
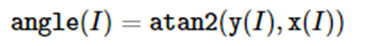

Phase()函数计算相位角,相当于cartToPolar()函数的angle(角度)。
cv::max (InputArray src1, InputArray src2, OutputArray dst)
cv::max (const Mat &src1,const Mat &src2, Mat &dst)
cv::max (const UMat &src1,const UMat &src2, UMat &dst)
取最大值作为输出。

如果是数组和标量,则

最大值操作,取两个图像(采样的最大值):

使用标量Scalar(),可以限定图像的像素范围。
cv::mean (InputArray src, InputArray mask=noArray())
计算数组的平均值

cv::min (InputArray src1, InputArray src2, OutputArray dst)
cv::min (const Mat &src1,const Mat &src2, Mat &dst)
cv::min (const UMat &src1,const UMat &src2, UMat &dst)
计算数组的最小值
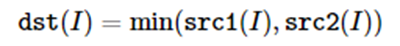
如果是数组和标量,则

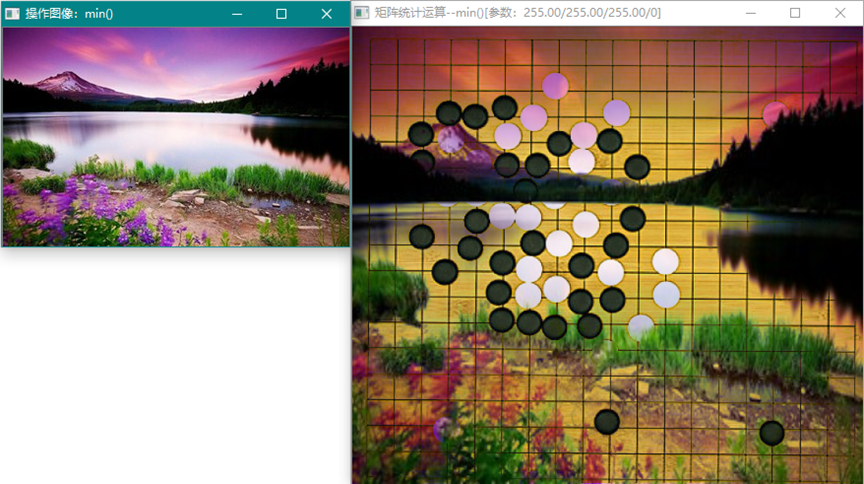
取图像(采样的最小值)。利用max和min函数的性质可以限定图像中像素的范围,过滤一定的色彩。因为可以使用标量Scalar()。
cv::minMaxIdx (InputArray src,double *minVal, double *maxVal=0, int *minIdx=0,
int *maxIdx=0, InputArray mask=noArray())
cv::minMaxLoc (InputArray src,double *minVal, double *maxVal=0,
Point *minLoc=0, Point *maxLoc=0, InputArray mask=noArray())
cv::minMaxLoc (const SparseMat &a,double *minVal, double *maxVal,
int *minIdx=0, int *maxIdx=0)
计算数组的最小最大值,及其位置索引,和位置坐标点。因为是单通道计算,因此对于彩色图像使用cv::cvtColor()函数转换为灰度图像。

绿色为最小值位置,红色为最大值位置,都是在行扫描过程中首次遇到的最大最小值位置。
是在bgr2gray灰度转换下计算的灰度最大最小值及其位置,实际图像中可能有多处最大最小值,这个位置是首次遇到的位置。
cv::solve (InputArray src1, InputArray src2, OutputArray dst,int flags=DECOMP_LU)
求解线性系统或最小二乘问题

cv::solveCubic (InputArray coeffs, OutputArray roots)
求三次方程的实数根,4元素矢量

三元素矢量

cv::solvePoly (InputArray coeffs, OutputArray roots,int maxIters=300)
求多项式方程的实数或复数根
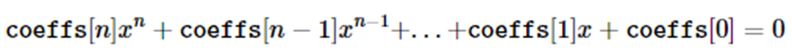
(4)、矩阵表达式操作
cv::completeSymm (InputOutputArray m, bool lowerToUpper=false)
完全对称操作,保持对角线不变,函数要求方形矩阵

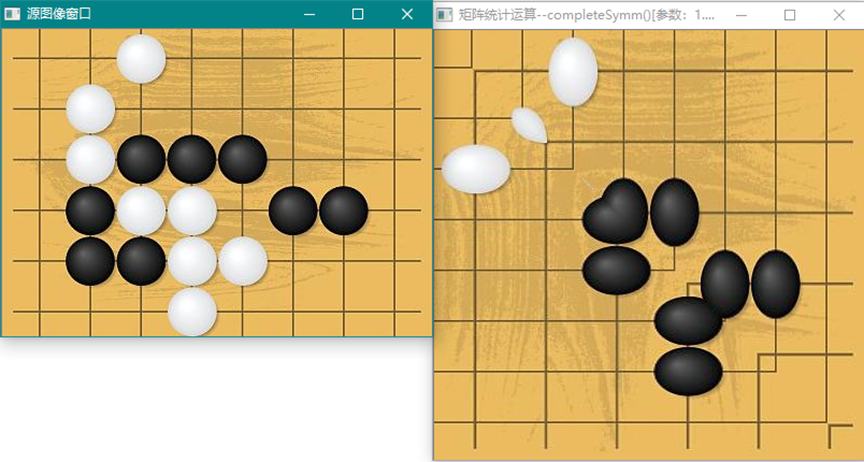
函数的图像效果,仅说明矩阵的对称运算就是把右上角的元素按对角线旋转到左下角。也可以是左下方的元素对称到右上方。
cv::compare (InputArray src1, InputArray src2, OutputArray dst,int cmpop)
执行矩阵元素的比较

标量比较



这是进行比较的两个源图像,比较时进行的是灰度图的比较,结果为:

左图为大于图,右图为小于图。这是两图逐像素比较的结果。
cv::convertFp16 (InputArray src, OutputArray dst)
转换矩阵到半精度浮点数
cv::convertScaleAbs (InputArray src, OutputArray dst,double alpha=1,
double beta=0)
按比例计算绝对值并转换到8位无符号整数

例:
Mat_<float>A(30,30);
randu(A, Scalar(-100),Scalar(100));
Mat_<float>B = A*5 + 3;
B = abs(B);
//Mat_<float> B = abs(A*5+3) 做相同的操作,但是这将分配一个临时矩阵
按指定的alpha和beta值变比例调整图像。
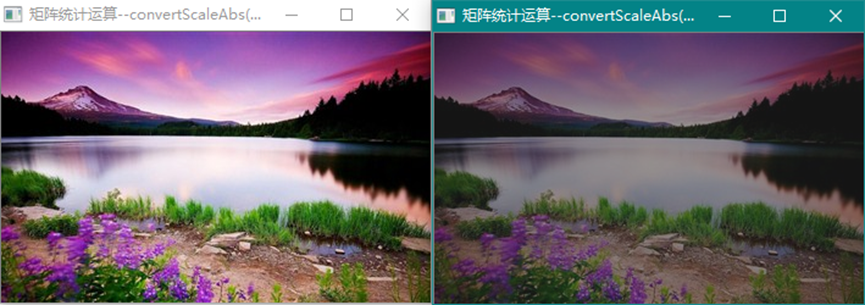
源图在alpha=0.5,beta=20时的变换图。
cv::copyTo (InputArray src, OutputArray dst, InputArray mask)
拷贝矩阵
cv::countNonZero (InputArray src)
统计非0元素数
cv::dct (InputArray src, OutputArray dst,int flags=0)
cv::idct (InputArray src, OutputArray dst,int flags=0)
执行离散余弦变换和逆变换。

这是dct变换和idct逆变换的图像表示。
cv::determinant (InputArray mtx)
计算行列式的值,对于三阶行列式直接计算。对于超过3阶的矩阵计算行列式则使用部分主元的LU分解法(partial pivoting)。
cv::dft (InputArray src, OutputArray dst,int flags=0, int nonzeroRows=0)
cv::idft (InputArray src, OutputArray dst,int flags=0, int nonzeroRows=0)
执行离散傅里叶变换,和逆变换。其中在变换之前使用cv::getOptimalDFTSize函数扩充数组尺寸到最优化尺寸。
例(计算卷积):
voidconvolveDFT(InputArray A, InputArray B, OutputArray C)
{
//如有必要,分配输出数组
C.create(abs(A.rows - B.rows)+1, abs(A.cols- B.cols)+1, A.type());
SizedftSize;
//计算DFT变换的尺寸
dftSize.width = getOptimalDFTSize(A.cols+ B.cols - 1);
dftSize.height =getOptimalDFTSize(A.rows + B.rows - 1);
//分配并初始化临时缓冲
MattempA(dftSize, A.type(), Scalar::all(0));
MattempB(dftSize, B.type(), Scalar::all(0));
//拷贝A和B到缓冲的左上角(tempA和tempB)
Mat roiA(tempA, Rect(0,0,A.cols,A.rows));
A.copyTo(roiA);
Mat roiB(tempB, Rect(0,0,B.cols,B.rows));
B.copyTo(roiB);
//现在开始直接变换A和B。使用"非0行"隐含加快处理
dft(tempA,tempA, 0, A.rows);
dft(tempB,tempB, 0, B.rows);
//谱相乘,函数处理封装的谱
mulSpectrums(tempA,tempB, tempA);
//将这个乘积反变换回频域。即使所有结果行都非零,也只需要头C.rows即可,因此只//可传递nonzeroRows ==C.rows。
//DFT_INVERSE表示逆变换
dft(tempA,tempA, DFT_INVERSE + DFT_SCALE,C.rows);
//拷贝结果到C
tempA(Rect(0,0, C.cols, C.rows)).copyTo(C);
//所有临时缓冲将自动释放
}
使频域原点在图像中间:
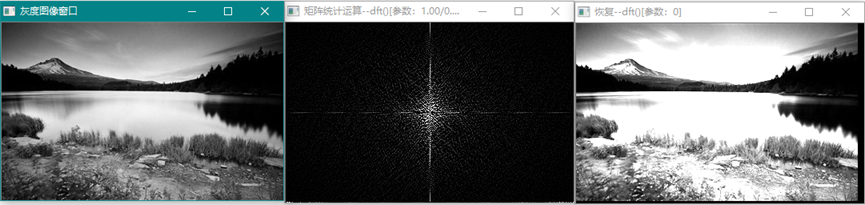
离散傅里叶变换,对源图进行频域变换,然后再对频域数据处理后进行逆变换获得滤波效果图。注:实际的频域数据经过中心化处理后获得的原点在中心的频域图像。
cv::getOptimalDFTSize (int vecsize)
计算扩充矢量的尺寸。
cv::eigen (InputArray src, OutputArray eigenvalues,
OutputArray eigenvectors=noArray())
cv::eigenNonSymmetric (InputArray src, OutputArray eigenvalues,
OutputArray eigenvectors)
计算对称和非对称矩阵的特征值和特征向量。函数cv::eigenNonSymmetric仅计算实数特征值。
Src * eigenvectors.row(i).t() = eigenvalues.at<srcType>(i) * eigenvectors.row(i).t()
这是图像矩阵的特征矢量图,特征值为一列向量:
没有图像意义。
cv::extractChannel (InputArray src, OutputArray dst,int coi)
cv::insertChannel (InputArray src, InputOutputArray dst, int coi)
抽取和插入通道,从原数组中抽取一个通道插入到目数组中。

将灰度图像插入到操作图像的指定通道(此处为0通道)。
cv::flip (InputArray src, OutputArray dst,int flipCode)
翻转数组元素,水平或垂直翻转数组元素,这是对源图进行上下翻转:

cv::invert (InputArray src, OutputArray dst,int flags=DECOMP_LU)
求逆矩阵或伪逆矩阵,伪逆矩阵是逆矩阵与原矩阵的乘积与单位矩阵的差最小(原矩阵与逆矩阵的乘积=单位矩阵)。注:矩阵的行列式|A|是否等于0,若等于0,称矩阵A为奇异矩阵;若不等于0,称矩阵A为非奇异矩阵。 同时,由|A|≠0可知矩阵A可逆,这样可以得出另外一个重要结论:可逆矩阵就是非奇异矩阵,非奇异矩阵也是可逆矩阵。这里的奇异或非奇异矩阵指的都是方阵。矩阵的秩是最大不为零的子式(子行列式)的阶数。满秩矩阵一定是可逆矩阵,可逆矩阵一定是满秩的,这是矩阵可逆的充要条件。
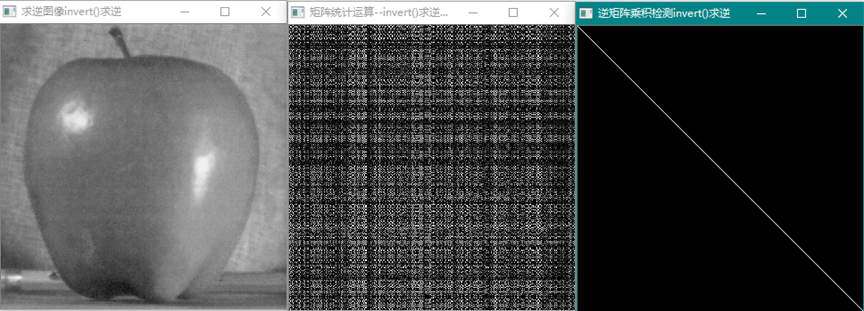
这是图像矩阵求逆运算后得到的逆矩阵,然后用逆矩阵与源图像乘积,得到单位矩阵,验证了矩阵的逆的属性。
cv::exp (InputArray src, OutputArray dst)

cv::log (InputArray src, OutputArray dst)
cv::pow (InputArray src,double power, OutputArray dst)
cv::sqrt (InputArray src, OutputArray dst)
对数组进行指数、对数、幂和平方根运算,对于幂运算,有如下公式:
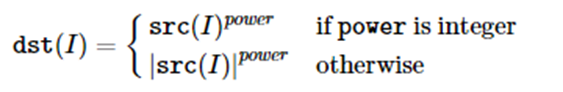
这是对源图使用比例为5,7,15,和255,做的指数运算,最后的图,其像素的指数值超界。

这是pow()取值为0.5、0.7、1.3时的运算结果。下图是源图取平方根:

cv::mixChannels (const Mat *src,size_t nsrcs, Mat *dst,size_t ndsts,
const int *fromTo, size_t npairs)
cv::mixChannels (InputArrayOfArrays src, InputOutputArrayOfArrays dst,
const int *fromTo, size_t npairs)
cv::mixChannels (InputArrayOfArrays src, InputOutputArrayOfArrays dst,
const std::vector< int > &fromTo)
从输入的数组列表中拷贝指定通道到输出数组的指定通道,可对多数组的通道进行洗牌
例:
Mat bgra( 100,100, CV_8UC4, Scalar(255,0,0,255));
Mat bgr(bgra.rows, bgra.cols, CV_8UC3 );
Mat alpha(bgra.rows, bgra.cols, CV_8UC1 );
// 形成矩阵列表,这是一个相当有效的操作
// 因为矩阵数据是没有被拷贝,仅仅是一个头
Mat out[] = {bgr, alpha };
//bgra[0] -> bgr[2], bgra[1] -> bgr[1],
//bgra[2] -> bgr[0], bgra[3] -> alpha[0]
intfrom_to[] = { 0,2, 1,1, 2,0, 3,3 };
mixChannels(&bgra, 1, out, 2, from_to, 4 );

把原图的1,0通道分别放到操作图的1,2通道上,操作图仅保留了0通道。
cv::split (const Mat &src, Mat *mvbegin)
cv::split (InputArray m, OutputArrayOfArrays mv)
分解多通道数组成为单通道数组
例:
Mat m(2, 2, CV_8UC3, d);
Mat channels[3];
split(m,channels);
/*
channels[0]=[ 1, 4;7, 10]
channels[1]=[ 2, 5;8, 11]
channels[2]=[ 3, 6;9, 12]
*/

把原图的三个通道分别抽取出来,形成三个单通道图像(灰度图)。
cv::reduce (InputArray src, OutputArray dst,int dim, int rtype, int dtype=-1)
缩减矩阵的维数,将2D矩阵缩减到行/列向量,可以有:
REDUCE_SUM //向量元素值=所在行/列的和
REDUCE_AVG //向量元素值=所在行/列的平均值
REDUCE_MAX //向量元素值=所在行/列的最大值
REDUCE_MIN //向量元素值=所在行/列的最小值
在求矩阵的平均值时,可以缩减2D到1D,然后再缩减1D到数值。
例1:
Mat m = (Mat_<uchar>(3,2) << 1,2,3,4,5,6);
Mat col_sum, row_sum;
reduce(m,col_sum, 0, REDUCE_SUM, CV_32F);
reduce(m,row_sum, 1, REDUCE_SUM, CV_32F);
/*
m =[ 1, 2;3, 4;5, 6]
col_sum =[9, 12]//列相加
row_sum =[3;7;11]//行相加
*/
列2(两通道):
// 两通道
char d[]= {1,2,3,4,5,6};
Mat m(3, 1, CV_8UC2, d);
Matcol_sum_per_channel;
reduce(m,col_sum_per_channel, 0, REDUCE_SUM, CV_32F);
/*
col_sum_per_channel=[9, 12]
*/
cv::repeat (InputArray src,int ny, int nx, OutputArray dst)
Matcv::repeat (const Mat &src,int ny, int nx)
重复拷贝输入数组到输出数组,使用公式

cv::rotate (InputArray src, OutputArray dst,int rotateCode)
旋转2D矩阵到90度,180度,270度等,可以指定顺时针或逆时针
cv::transpose (InputArray src, OutputArray dst)
转置矩阵,行变列,列变行。在做矩阵变换时经常用到转置操作,在Mat类型的对象下,Mat::t()函数获得矩阵的转置矩阵。


原图像的转置图像(只是视觉效果)。
(5)、矩阵的变换操作
cv::batchDistance (InputArray src1, InputArray src2, OutputArray dist,
int dtype, OutputArray nidx,int normType=NORM_L2,
int K=0, InputArray mask=noArray(),
int update=0, bool crosscheck=false)
原始的最近邻域查询法(没有资料详细说明其原理)。
输入参数:
src1 采样矩阵尺寸为N1 x M,类型为CV_32F或CV_8U
src2 采样矩阵尺寸为N2 x M,类型为CV_32F或CV_8U
输出参数:
dst 目的矩阵(参见下面描述)
nidx 从0开始的最近邻域索引(尺寸N1 x K)。仅在 K>0时进行计算,否则返回空矩阵
可选参数:
DType 默认为-1
NormType 用于距离尺度。默认为'L2'
K 需要查找的最近邻域数。如果K=0 (默认),则计算矩阵全部的点对距离(矩阵尺寸为N1 x N2),否则仅计算k个最近邻域的距离(矩阵尺寸为N1 x K)。
Mask 屏蔽矩阵,默认为空
Update 默认为0
CrossCheck 默认为false.
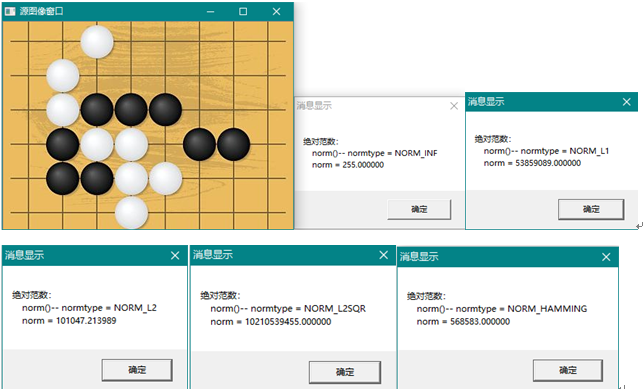
距离算法主要适用于特征点矢量的相似度比较,使用训练图像获得的关键点矢量,对查询图像序列进行特征点匹配操作,计算距离,并判断距离的大小,用以确定训练图像与查询图像之间的关系(比如相似度)。作为图像分类,使用距离匹配算法可以粗略估算出图像所属类别。batchDisdance()计算的是矩阵的每一行作为向量进行两组向量的距离计算获得N1 x N2结果矩阵表示的距离数CV_32F类型。如下图:

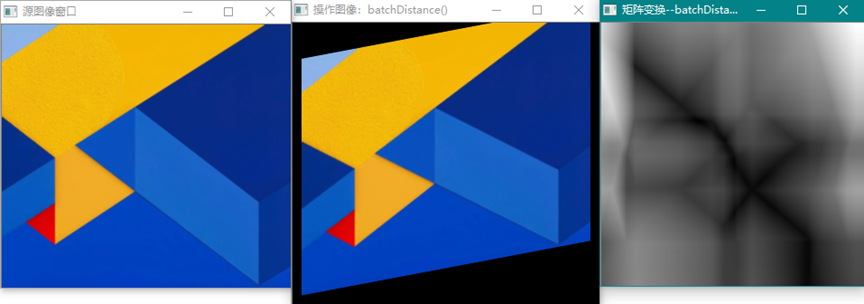

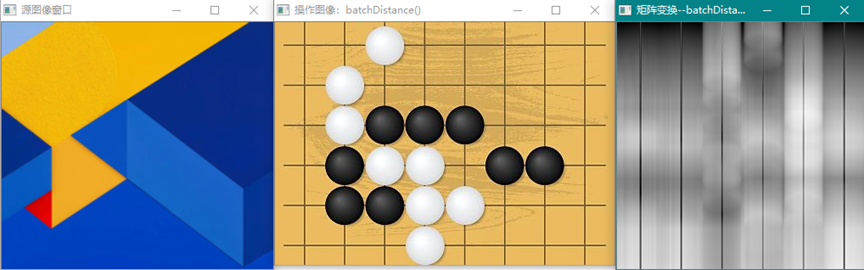
从距离图上并不能分辨出相比较的两幅图像有什么本质上的差别,因此单从距离计算上不能分类图像或进行目标检测与匹配。要完成目标检测与匹配功能,应依据距离原理,使用opencv中的2D Features Framework提供的功能:Feature Detection and Description、DescriptorMatchers和Keypointsand Matches等功能(见ObjectDetection)。
cv::Mahalanobis (InputArray v1, InputArray v2, InputArray icovar)
计算两矢量之间的马氏(Mahalanobis)距离(表示数据的协方差距离)。可以看作是欧氏距离的一种修正,修正了欧式距离中各个维度尺度不一致且相关的问题。在使用时,icovar是v1 + v2的协方差矩阵,然后求逆获得(也可以使用非单位对角线矩阵求逆获得)。
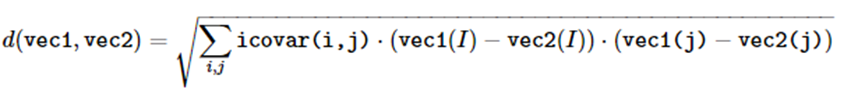
给出v1到v2的马氏距离,其中v2为标准点的mean矢量,icovar为标准点的协方差的逆矩阵。v1为要测算的矢量。

通过两幅图,由左图计算mean矢量(列)和icovera,对右图的每一列计算马氏距离double。并显示min、max、mean值。

两张不同的图的马氏距离。不同类型的图的马斯距离:
从马斯距离的数据分析并不能直接判别图像的特征,距离属性是在特征点(keypoint)的检测、描述和匹配中判别属性的相似性测度。不是直接图像像素计算(见Object Detection)。
cv::mulSpectrums (InputArray a, InputArray b, OutputArray c,int flags,
bool conjB=false)
执行两个傅里叶谱的按元素相乘操作,这个函数与dft和idft一起,可计算卷积(conjB=false),或相关性(conjB=true)。例(计算离散傅里叶变换的卷积,功率谱相乘):
voidconvolveDFT(InputArray A, InputArray B, OutputArray C)
{
//如果需要则分配一个输出数组。注此处的A.rows-B.rows是选取的输出大小,对于
//比较小的B,逆变换可以看到完整矩阵(图像A),所以应该用A.rows+B.rows作为输//出尺寸。
C.create(abs(A.rows - B.rows)+1, abs(A.cols- B.cols)+1, A.type());
SizedftSize;
//计算DFT变换尺寸
dftSize.width = getOptimalDFTSize(A.cols+ B.cols - 1);
dftSize.height =getOptimalDFTSize(A.rows+ B.rows - 1);
//分配临时缓冲并进行初始化
Mat tempA(dftSize,A.type(), Scalar::all(0));
MattempB(dftSize, B.type(), Scalar::all(0));
//拷贝A 和 B 到tempA 和 tempB的左上角
Mat roiA(tempA, Rect(0,0,A.cols,A.rows));
A.copyTo(roiA);
Mat roiB(tempB, Rect(0,0,B.cols,B.rows));
B.copyTo(roiB);
//现在直接变换粘贴的A和B
//使用"非0行"提示进行快速处理
dft(tempA,tempA, 0, A.rows);
dft(tempB,tempB, 0, B.rows);
//进行谱乘积,这个函数可较好地处理整装的谱数据
mulSpectrums(tempA,tempB, tempA);
//逆变换乘积数据到频率域,尽管所有结果行都是非0的,也仅仅只需要头C.rows。因//此只需传输C.rows个非0行。
dft(tempA,tempA, DFT_INVERSE + DFT_SCALE,C.rows);
//现在拷贝结果到C。注:对于较大的B矩阵(不是滤波核,与A的差较小或相等),上面//的C将返回结果的一角或缩为一点,因此实际返回应该为tempA尺寸,才完整。
tempA(Rect(0, 0, C.cols, C.rows)).copyTo(C);
//所有临时缓冲都自动被释放
}

这个例子只是说明上例中的C矩阵返回的是部分数据矩阵,也许在谱数据矩阵中C是对的,但是在处理图像中,显然是部分数据。不知道为什么。如果更大的B,不如B = A,此时上例中返回的是一个点。下面是计算的谱矩阵图像:

一般而言,convolveDFT使用核矩阵作为B对A进行滤波操作,也可以对图像进行模糊处理。
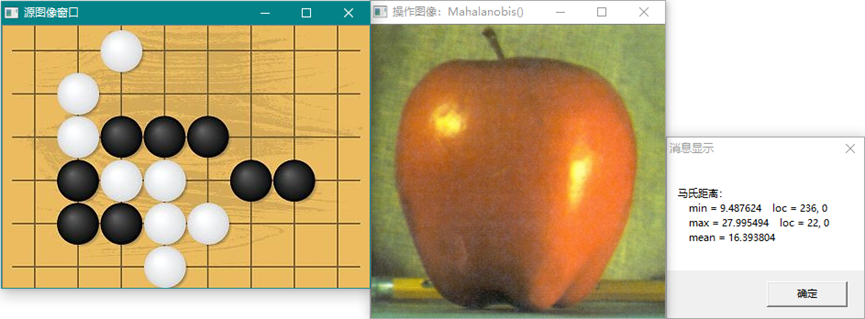
double cv::norm (InputArray src1,int normType=NORM_L2,
InputArray mask=noArray())
double cv::norm (const SparseMat &src,int normType)
计算绝对范数,按指定范数类型计算源矩阵的范数。
double cv::norm (InputArray src1, InputArray src2,int normType=NORM_L2,
InputArray mask=noArray())
计算绝对范数差或相对范数差,按指定范数类型计算两源矩阵差的范数。


cv::normalize (InputArray src, InputOutputArray dst, double alpha=1,
double beta=0, int norm_type=NORM_L2,
int dtype=-1, InputArray mask=noArray())
cv::normalize (const SparseMat &src, SparseMat &dst,double alpha, int normType)
规范化数组的范数或值的范围。
例:
vector<double> positiveData = { 2.0, 8.0, 10.0 };
vector<double> normalizedData_l1, normalizedData_l2;
vector<double> normalizedData_inf, normalizedData_minmax;
//概率范数(总计数)
// sum(numbers) = 20.0
// 2.0 0.1(2.0/20.0)
// 8.0 0.4(8.0/20.0)
// 10.0 0.5 (10.0/20.0)
normalize(positiveData,normalizedData_l1, 1.0, 0.0, NORM_L1);
//单位矢量范数: ||positiveData|| = 1.0
//矢量的模为sqrt(sqr(2)+sqr(8)+sqr(10))=sqrt(168)=12.96,则0.15=2/12.96
// 2.0 0.15
// 8.0 0.62
// 10.0 0.77
normalize(positiveData,normalizedData_l2, 1.0, 0.0, NORM_L2);
//最大元素范数
// 2.0 0.2(2.0/10.0)
// 8.0 0.8(8.0/10.0)
// 10.0 1.0 (10.0/10.0)
normalize(positiveData,normalizedData_inf, 1.0, 0.0, NORM_INF);
//范围范数[0.0;1.0],仿射变换范围
// 2.0 0.0 (移位到左边界)
// 8.0 0.75 (6.0/8.0)
// 10.0 1.0 (移位到有边界)
normalize(positiveData,normalizedData_minmax, 1.0, 0.0, NORM_MINMAX);
cv::perspectiveTransform (InputArray src, OutputArray dst, InputArray m)
执行矩阵的透射变换,其中m为3x3或4x4浮点变换矩阵,在图像变换节中有getXXXX函数可以获得相应的变换矩阵m。
cv::transform (InputArray src, OutputArray dst, InputArray m)
执行m指定的矩阵变换,在图像变换节中有getXXXX函数可以获得相应的变换矩阵m。
关于目标检测的实例分析(Objectdetector):
目标检测主要用到的是最近邻域算法(矢量距离算法),其中用到detector属性检测器,keypoints矢量,descriptor描述符和matcher器等对象联合操作。下述程序来自opencv的实例:
这段程序展示使用features2d框架查找和匹配两个图像的关键点。一种情况是,第二个图像是第一个图像通过单应性变换合成的,第二种情况是本身就有两张图像。
Case1: 第二个图像是从第一个给定图像通过使用随机生成的单应矩阵获得的
argv[0]<<[检测器类型] [描述符类型] [匹配器类型] [匹配滤波类型] [图像] [评估(0 or 1)]"
case1下命令行输入如下:
descriptor_extractor_matcher SURF SURF FlannBased NoneFilter cola.jpg 0
Case2: 给定两个图像。如果ransacReprojThreshold>=0 则计算单应矩阵"
argv[0]<<[检测器类型] [描述符类型] [匹配器类型] [匹配滤波类型] [图像1] [图像2] [ransacReprojThreshold]
在两种情况下,匹配都使用单应矩阵滤波(如果ransacReprojThreshold>=0)
case2下命令行输入如下:
descriptor_extractor_matcher SURF SURF BruteForce CrossCheckFilter cola1.jpgcola2.jpg 3
可用的检测器类型值:见opencv的createFeatureDetector()函数资料
可用的描述符类型值:见opencv的createDescriptorExtractor()函数资料
可用的匹配器类型值:见opencv的createDescriptorMatcher()函数资料
可用的匹配滤波类型值:NoneFilter, CrossCheckFilter
//
if( argc != 7&& argc != 8 ){
help(argv);
return -1;
}
boolisWarpPerspective= argc == 7;
doubleransacReprojThreshold= -1;
if( !isWarpPerspective)
ransacReprojThreshold= atof(argv[7]);
cout << "< 建立检测器,描述符抽取器和描述符匹配器..." << endl;
Ptr<FeatureDetector>detector = FeatureDetector::create( argv[1]);
Ptr<DescriptorExtractor>descriptorExtractor = DescriptorExtractor::create(argv[2] );
Ptr<DescriptorMatcher>descriptorMatcher = DescriptorMatcher::create( argv[3]);
intmactherFilterType= getMatcherFilterType( argv[4] );
booleval = !isWarpPerspective ? false: (atoi(argv[6])== 0 ? false : true);
cout << ">"<< endl;
if( detector.empty() || descriptorExtractor.empty() || descriptorMatcher.empty()){
cout<< "不能建立给定类型的检测器或描述符抽取器或描述符匹配器" << endl;
return -1;
}
cout << "< 读图像..." << endl;
Matimg1 = imread( argv[5]), img2;
if( !isWarpPerspective)
img2 = imread( argv[6]);
cout << ">"<< endl;
if( img1.empty() || (!isWarpPerspective&& img2.empty())){
cout<< "不能读入图像" << endl;
return -1;
}
cout << endl<< "< 抽取第一幅图像的关键点..." << endl;
vector<KeyPoint> keypoints1;
detector->detect( img1, keypoints1 );
cout << keypoints1.size() << "点" << endl << ">"<< endl;
cout << "< 计算第一幅图像关键点的描述符..." << endl;
Matdescriptors1;
descriptorExtractor->compute(img1, keypoints1,descriptors1 );
cout << ">"<< endl;
namedWindow(winName, 1);
RNGrng = theRNG();
doIteration( img1, img2, isWarpPerspective,keypoints1, descriptors1,
detector,descriptorExtractor, descriptorMatcher,mactherFilterType, eval,
ransacReprojThreshold,rng );
for(;;){
charc = (char)waitKey(0);
if( c == '\x1b' ){ // esc
cout<< "退出 ..." << endl;
break;
}elseif( isWarpPerspective){
doIteration(img1, img2, isWarpPerspective, keypoints1,descriptors1,
detector,descriptorExtractor, descriptorMatcher,mactherFilterType, eval,
ransacReprojThreshold,rng );
}
}
return 0;
这里只是给出了命令行主程序段的说明,详细请参见descriptor_extractor_matcher.cpp程序文件位置在:opencv\sources\samples\cpp。可以选择图像,查看程序运行结果:
一般而言,使用同名的检测器和描述符进行匹配效果比较好,比如SURF/SURF、ORB/ORB等。ORB对角点目标有较好的检测效果,如图:

使用ORB/ORB/BruteForce/NONE_FILTER/ransacReprojThreshold=3.0。而使用SURF/SURF/BruteForce/NONE_FILTER/ransacReprojThreshold=3.0则如下图:

而对于一般图像,SURF则显示较理想的结果:

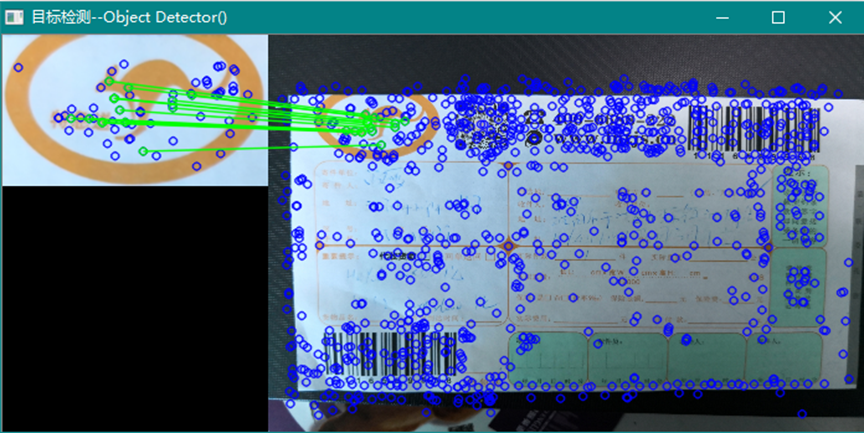

可以使用映射点获得的变换矩阵画出目标的位置:

使用ORB/ORB则:
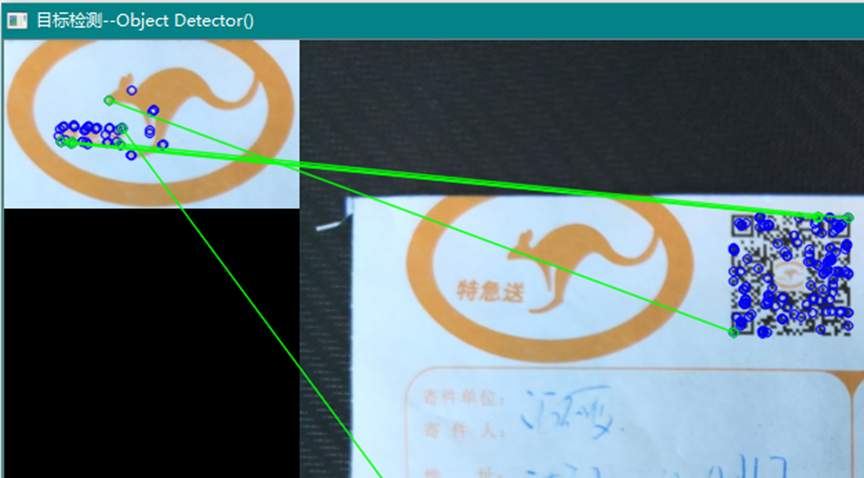
由此看出,选择检测器类型与对应的检测场景必需相关联才能获得较好的效果。
Opencv除了上面提到的检测器等类型之外还有其他类型的检测器,需要直接使用检测器类进行建立,如:KAZE、AgastFeatureDetector等。
Ptr< KAZE >detect = KAZE::create();
以下是opencv4.3.0所支持的检测器和描述符抽取器(来自opencv资料,及相关文章)。
特征点检测算法的评估一般是重复率指标,在OpenCV中使用 cv::evaluateFeatureDetector()函数测试各个算法针对不同的应用场景,例如像基础的特征点检测算法:FAST、Harris、Hessian等并不支持尺度的变换,如果图像对存在一定的尺度变换,那么该类别算子重复率可能就会不佳。SIFT、SURF等具备尺度变换的性能,但是并不具备仿射的因素,HarrisAffine与HessianAffine与MSER算子是针对仿射的因子,可能就会对仿射变换的图像性能体现较佳的效果,但是也带来极大的计算时间。
属性检测器:
Opencv中的属性检测器封装了一个通用接口,允许你更容易的切换不同算法来解决相同问题,并比较其中的差异,得到较完美的结果。所有实现关键点检测的类都继承于FeatureDetector接口。
描述符抽取器:
OpenCV中的关键点描述符抽取器封装了一个通用接口,以方便用户能够容易地切换不同算法解决相同问题,比较其中差异,获得完美结果。以下各节专门描述这些关键点检测器和描述符抽取器。描述符表示为多维空间中的矢量,所有实现矢量描述符抽取的对象都继承于DescriptorExtractor接口。
在现实生活中,我们从不同的距离、不同的方向、不同的角度、不同的光照条件下观察一个物体时,物体的大小、形状、亮度分布都会有所不同。但是,我们的大脑中依然可以判断它是同一个物体。理想的特征描述子就应该具备这样的性质。即对于大小、方向旋转、灰度亮度变化的图像中,同一特征点应该具有相似的特征描述子,我们将此称为描述子的可复现性。
理想的描述符
当我们以理想的方式计算图像中关键点的描述子的时候,同样的特征点,在不同的图像中应该具有相同的结果。即描述子对于光照、旋转、尺度具有一定的鲁棒性。
我们用BRIEF算法得到的描述子并不具备以上这些性质。因此,我们得想办法改进我们的算法。ORB并没有解决尺度一致性的问题,OpenCv中实现的ORB算法采用图像金字塔来改善这方面的性能。ORB算法主要解决了BRIEF描述子不具有旋转不变性的问题。
回顾一下BRIEF描述子的计算过程:在当前关键点P的周围以一定方式选取N个点对,组合这N个点对的T操作的结果,这个组合结果就是这个关键点最终的描述子。当我们选取点对的时候,是以当前关键点为原点,以水平方向为X轴,以垂直方向为Y轴建立坐标系。当图片发生旋转时,坐标系不变,同样的取点模式,取出来的点却不一样,计算得到的描述子也不一样,这是不符合我们要求的。因此,我们需要重新建立坐标系,使新的坐标系可以随着图片的旋转而旋转。这样我们以相同的取点模式取出来的点就具有一致性。
打个比方,我们有一个印章,上面刻着一些直线。用这个印章在一张图片上盖一个章子,图片上的某个点被取出来。印章不变动的情况下,转动下图片,再盖一个章子,但是这次取出来的点对就和之前的不一样。为了使2次取出来的点一样,我们需要将章子也旋转同一个角度,再盖章。ORB在计算BRIEF描述子的时候,建立的坐标系是以关键点为圆心,以关键点和取点区域的形心的连线为X轴建立的2维坐标系 。在下图中,P为关键点。圆内为取点的区域,每个小格子代表一个像素。现在我们把这块圆心看做一块木板,木板上每个点的质量等于其对应的像素值。根据积分学的知识,我们可以求出这个密度不均匀木板的质心Q。计算公式如下所示,其中R为圆的半径。我们知道圆心是固定的,而且随着物体的旋转而旋转,当我们以PQ为坐标时,在不同的旋转角度下,我们以同一取点模式取出来的点是一致的,这就解决了旋转一致性的问题。上文摘自https://www.cnblogs.com/wyuzl/p/7838103.html
1、cv::AgastFeatureDetector
用法:
Ptr<AgastFeatureDetector> myAgastFeatureDetector = AgastFeatureDetector::create()
其中参数:
int threshold=10,
bool nonmaxSuppression=true,
DetectorType type=OAST_9_16
这个类封装了属性检测器 AGAST的方法。这个监测器给出的是角点检测,检测灰度图像的角点作为检测的关键点Keypoint。可以使用其他描述符抽取器获得关键点的描述符。然后使用匹配器进行目标的描述符匹配。下图是使用AGAST检测器和SURF描述符抽取器和BRUTFORCE匹配器给出的图像处理结果:
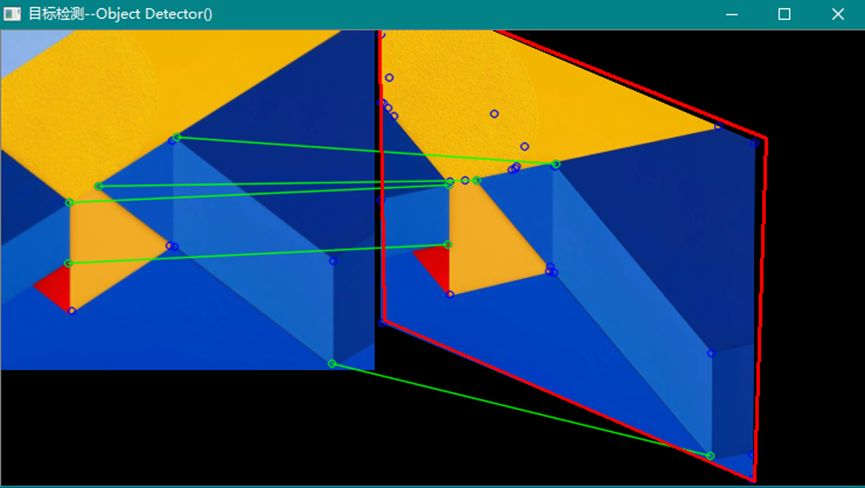
可见AGAST检测器对角点是非常敏感的。
2、cv::KAZE
用法:
Ptr<KAZE>myKAZE = KAZE:: create()
其中参数:
boolextended=false,
boolupright=false
float threshold=0.001f,
int nOctaves=4,
int nOctaveLayers=4,
KAZE::DiffusivityTypediffusivity=KAZE::DIFF_PM_G2
这个类实现了KAZE关键点检测器和描述符抽取器的功能。KAZE。描述符仅能用于KAZE关键点。这个类是线程安全的。
注:
在需要使用描述符时,Feature2D::detectAndCompute提供较好的性能。而使用Feature2D::detect 然后再使用Feature2D::compute 则尺度空间锥被计算了两次。
AKAZE 实现T-API。在图像使用UMat格式传输时,某些算法使用OpenCL。
这个类不仅实现了关键点的检测,而且还实现了描述符的抽取,因此使用这个类建立的检测器只能使用这个类自己的抽取器进行描述符的抽取。然后使用匹配器。
KAZE(AKAZE)是基于非线性插值的方法,这一点在图像处理方面来说确实比SURF和SIFT要好,毕竟图像大多是不连续的。AKAZE是KAZE的加速版。效果如图(KAZE):

3、cv::BRISK
用法:
Ptr< BRISK >myBRISK = BRISK ::create (intthresh=30,
int octaves=3,
float patternScale=1.0f)
Ptr< BRISK >myBRISK = BRISK ::create (conststd::vector< float > &radiusList,
const std::vector< int > &numberList,
float dMax=5.85f,
float dMin=8.2f,
const std::vector< int >&indexChange=std::vector< int >())
Ptr< BRISK >myBRISK = BRISK ::create (intthresh,
int octaves,
const std::vector< float >&radiusList,
const std::vector< int > &numberList,
float dMax=5.85f,
float dMin=8.2f,
const std::vector< int >&indexChange=std::vector< int >())
这个类实现了BRISK关键点检测器和描述符抽取器(Binary robust invariant scalable keypoints,二值稳定的尺度不变关键点)。强壮的尺度不变关键点在图片中比较少见,因此可结合其他匹配原则进行多组合匹配来定位图片中的目标。稳定不变的关键点一般使用高斯锥进行检测。这样的稳定点比较少见,在使用双向过滤后,存在的关键点大概率是正确的监测点(如果存在),如果这样的点大于3,则可用于计算目标映射变换矩阵。
4、cv::FastFeatureDetector
用法:
Ptr< FastFeatureDetector > myFAST = FastFeatureDetector::create()
参数:
int threshold=10,
bool nonmaxSuppression=true,
FastFeatureDetector::DetectorType type=FastFeatureDetector::TYPE_9_16
这个类封装了使用FAST方法的属性检测器。

FAST不支持尺度和仿射不变性特征检测,因此对于不变尺度关键点检测能够给出比较好的检测结果。而对于变尺度和仿射图像得目标检测则效果不理想。上图是使用FAST检测器和SIFT描述符抽取器,以及CROSS_CHECK_FILTER组合的目标检测效果。
5、cv::GFTTDetector
用法:
Ptr< GFTTDetector >myGFTT = GFTTDetector::create()
参数:
int maxCorners=1000,
double qualityLevel=0.01,
double minDistance=1,
int blockSize=3,
bool useHarrisDetector=false, double k=0.04
Ptr< GFTTDetector >myGFTT = GFTTDetector::create()
int maxCorners,
double qualityLevel,
double minDistance,
int blockSize,
int gradiantSize,
bool useHarrisDetector=false,
double k=0.04
这个类封装了使用goodFeaturesToTrack函数构造的属性检测器。以harris角点作为关键点,useHarrisDetector参数指定角点的判定依据是使用Harris还是使用Shi-Tomasi。从默认值可以看出GFTT默认使用Shi-Tomasi判定依据。

这是GFTT检测器与BRISK描述符抽取器组合的检测结果。

这是GFTT检测器与ORB描述符抽取器组合的检测结果。由于结果点少于4,所以不能画出目标位置框。GFTT还可以与其他描述符抽取器组合。在GFTT生成关键点时,用时较长。
6、cv::MSER
用法:
Ptr< MSER >myMSER = MSER::create()
参数:
int _delta=5, // 比较值
int _min_area=60, //修剪小于minArea的域
int _max_area=14400, //修剪大于maxArea的域
double _max_variation=0.25, 修剪其子域有较小尺寸的域(最大变异小于)
double _min_diversity=.2, //对彩色图像,回溯检查以裁撤差异小于min_diversity 的mser点
int _max_evolution=200, //对彩色图像,进化步长
double _area_threshold=1.01, //对彩色图像,引发再初始化的区域阈值
double _min_margin=0.003, //对彩色图像,要放弃的太小的边缘
int _edge_blur_size=5 //对彩色图像,边缘模糊的孔径尺寸
MSER是最大稳定极值区域特征点检测器。这个类封装了所有MSER算法检测器的参数。
MSER有两种不同的实现:一是灰度图像,一是彩色图像
灰度图像算法来自《线性时域最大稳定极值域的论文(Linear time maximally stable extremal regions)》,这篇文章声称快于联合查询算法。
彩色图像算法来自《最大稳定彩色区域识别与匹配(Maximally stable colour regions for recognition and matching)》,它比灰度图像算法慢3到4倍,chi_table.h文件是直接取值论文的源码,它可以在GPL下发布。
MSER的基本原理和用途:
MSER对一幅已经处理成灰度的图像做二值化处理,这个处理的阈值从0到255递增,这个阈值的递增类似于在一片土地上做水平面的上升(分水岭算法原理),随着水平面上升,高高低低凹凸不平的土地区域就会不断被淹没,而这种高低不同就相当于图像中灰度值的不同。在一幅含有文字(类似标记)的图像上,有些区域(比如文字)由于颜色(灰度值)是一致的,因此在水平面(阈值)持续增长的一段时间内都不会被覆盖,直到阈值涨到文字本身的灰度值时才会被淹没,这些区域就叫做最大稳定极值区域(坚持了灰度变化的一段距离而区域不变)。
7、cv::ORB
用法:
Ptr< ORB >myORB = ORB::create()
参数:
intnfeatures=500, //记录的最大特征数。
float scaleFactor=1.2f, //高斯锥销毁率,大于1。
scaleFactor==2表示典型的高斯锥,此时每一个次层都有4x小的像素,而大比例因子将戏剧性地降低特征的匹配得分。另一方面,太靠近1的比例因子将表明要覆盖一定的尺度范围将需要更多的高斯锥层并且速度也会受到影响。
intnlevels=8, //高斯锥的层数。
最小层有线性尺寸:
input_image_linear_size/pow(scaleFactor, nlevels - firstLevel)。
intedgeThreshold=31, //这是属性不能被检测的边缘尺寸。粗略地匹配于patchSize参数。
intfirstLevel=0, //源图像所在的高斯锥的层次。前面的层由upscaled源图像来充填。
int WTA_K=2, //定向BRIEF描述符的每个元素产生的点数。默认值为2意指BRIEF取随机点对并比较它们的亮度,所以有0/1响应。其他的可能值是3和4。3意指取3个随机点(当然,这些点的坐标是随机的,但是它们可以由预定义的种子生成,所以每一个BRIEF描述符的元素都可以从像素矩形中被确切地计算),找出最大亮度的点并输出占优点的索引(0, 1 or 2)。这样的输出占据2个二进制位,因而也将需要特殊的变异Hamming 距离,表示为NORM_HAMMING2 (每盘占2个位)。当WTA_K=4时,取4 随机点来计算每个盘(这也占有2个位,可能值为0,1,2 或3)。
ORB::ScoreTypescoreType=ORB::HARRIS_SCORE, //默认为HARRIS_SCORE意指使
用Harris算法计算特征排名(这个分数被写入KeyPoint::score并且用于保存最佳的nfeatures个特征)。FAST_SCORE是另一种参数值,它产生有点不太稳定的关键点,但计算速度要稍微快一点。
intpatchSize=31, //用于定向BRIEF描述符的孔径尺寸。当然,对于较小的高斯锥层这个由
特征覆盖的图像感知区将更大一些。
intfastThreshold=20 // Fast阈值
这个类实现了ORB(定向BRIEF)关键点检测器和描述符抽取器(一种对sift和surf的有效替代算法Orb: an efficient alternative to sift or surf)。这个算法使用FAST在高斯锥上检测稳定的关键点,使用FAST或Harris响应来选择最强特征,使用一阶矩查找它们的方向,使用BRIEF计算其描述符 (随机点对k-元组的坐标并根据尺度方向旋转)
ORB(Oriented FAST and Rotated BRIEF)是OrientedFAST + Rotated BRIEF的缩写。是目前最快速稳定的特征点检测和提取算法,许多图像拼接和目标追踪技术都利用ORB特征进行实现。

从上图可知ORB对角点敏感,而其他类型的关键点,往往出错,如图:

使用同样的参数,基本上没有对的点。
8、cv::SimpleBlobDetector
用法:
Ptr< SimpleBlobDetector > mySimpleBlobDetector = SimpleBlobDetector::create()
参数:
const SimpleBlobDetector::Params ¶meters=SimpleBlobDetector::Params()
这个类实现了一个从图像中抽取图块的简单算法:
通过阈值转换法,施加minThreshold (含)到maxThreshold (不含)选取的几个阈值,使用邻域阈值之间的距离thresholdStep转换原图像到二进制图像。
通过findContours 从每一个二进制图像中抽取连通域并计算他们的中心。
通过坐标分组二进制图像的中心。靠近的中心形成一个组,对应于一个图块,这通过minDistBetweenBlobs参数来控制。
从分组中估算最终的图块中心以及其半径,并作为关键点的位置和尺寸返回。
这个类对返回的图块执行几个过滤操作。在使用中应设置filterBy参数为true/false来允许对应的过滤操作。可用的过滤为:
By color. 这个过滤器比较二进制图像在图块中心点的blobColor 强度。如果它们不同,这个图块被滤掉。使用blobColor = 0 来抽取黑图块,blobColor = 255来抽取白图块。
By area. 抽取面积在minArea (含)和maxArea (不含)之间的图块。
By circularity. 抽取圆形在minCircularity (含)和maxCircularity (不含)之间的图块。
By ratio of the minimum inertia to maximum inertia. 抽取惯性比率在minInertiaRatio (含)和maxInertiaRatio (不含)之间的图块。
By convexity. 抽取具有凸性(面积/ 图块凸包面积)在minConvexity (含)和maxConvexity (不含)之间的图块。
参数的默认值为抽取黑圆图块。SimpleBlobDetector检测器对于圆形对象检测效果比较理想,其他形状的关键点则非常差,有时根本检测不到(比如角点)。如图:

在SimpleBlobDetector下几乎所有的圆形点都检测到了,而没有一个非圆形点(比如骰子的边缘)。

9、cv::xfeatures2d::HarrisLaplaceFeatureDetector
这个类实现了Harris-Laplace属性检测,称之为尺度与仿射不变的关键点检测。如图:

10、cv::xfeatures2d::SIFT
这是一个关键点的描述符抽取器类,实现了SIFT算法(尺度不变性特征变换算法)。可以使用其他检测器检测图像的关键点(感兴趣的特征点,比如角点,圆点,区域属性点等),然后使用SIFT或其它描述符抽取器建立特征点的描述符(保证特征点的尺度,旋转,仿射等形变状态下的属性不变性),再通过匹配器进行特征点的矢量距离计算,在支持各种形变状态下的不变性基础上实现特征点的配对(单应性计算),进行图像的目标检测。如图:

大多数检测器和抽取器多是针对角点性质的关键点进行操作的。
11、cv::xfeatures2d::SURF
这个类实现了对图像的快速稳定特征点检测和描述符抽取算法(extracting Speeded Up Robust Features)。
算法参数:
int extended
0 表示计算出基本描述符(64元素)
1 表示计算出扩展描述符(128元素)
int upright
0 表示检测计算每个特征的方向
1 表示不计算方向(这要快得多)。例如,如果从立体图像对匹配图像,或做图像缝合连接时,匹配的特征可能有非常小的转角,此时为了加速抽取特征,可以设置upright=1
double hessianThreshold 关键点检测器的阈值。对特征点,其阈值大于 hessianThreshold的才被关注。因此这个阈值越大,检测到的特征点越少。较好的默认值是300 到 500,这取决于图像的对比度
int nOctaves 这是检测器所使用的高斯锥分层数。默认设置为4。如果想要获得更多的关键点,可以使用较大的值。减少这个值,将获得较少的关键点
int nOctaveLayers 这是每一个高斯锥层上的图像数。默认设置为2
注意
使用SURF 特征检测器的例子可以在opencv_source_code/samples/cpp/generic_descriptor_match.cpp中找到
其它的例子可以在 opencv_source_code/samples/cpp/matcher_simple.cpp中找到

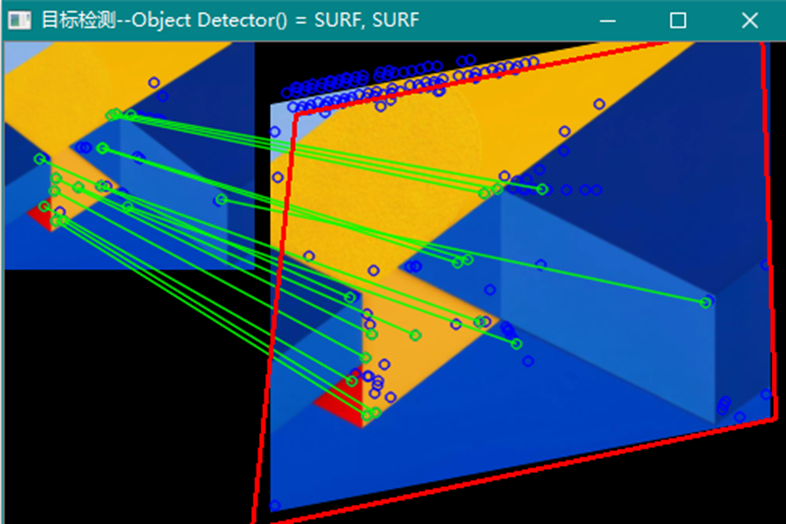
12、cv::xfeatures2d::BriefDescriptorExtractor
这是一个“二进制稳健独立基础特征”描述子抽取器对象,建立实例时需要给出如下参数:
参数
bytes | 描述子的字节长度,一般取16,32 (默认)或64 |
use_orientation | 关键点采样模式使用的朝向,默认是禁止使用朝向指定 |
注意:BRIEF关键点属性不支持仿射变换,对于缩放图像对象效果不佳。使用FAST检测器和BRIEF描述符的目标检:

也可以使用其他检测器如:MSER等。

不同的检测器得出的结果不尽相同,应依据实际情况进行组合。
13、cv::xfeatures2d::FREAK
这个类实现了FREAK(快速视网膜关键点)的关键点描述符,这个算法定位于一种新奇的关键点描述,受启发于人类的视觉系统,更精切地讲是视网膜,创造了快速视网膜关键点(FREAK)。通过有效地比较视网膜采样模式下的图像密度,计算一个二进制聚类串生成的关键点。FREAK一般来讲在低存储负载下计算是比较快的,并且比SHIF,SURF和BRISK更健壮。它是已存在关键点算法的另一种有竞争力的选择,特别是在嵌入式应用中。以上是opencv资料翻译。下面是来自网络的文章摘编。
FREAK算法只实现了描述符提取部分,不包含关键点检测器。它的计算方式是计算了用于二值比较的面积。FREAK算法并不使用均匀平滑图像周围的像素进行比较,相反用于比较的像素点分别都对应了不同大小的积分区域,离描述符中心越远的点对应的积分区域越大。FREAK算法通过这种方式模拟人的视觉系统特征,也因此得名Fast RetinalKeypoint。
FREAK算法计算关键点描述符的原理示意图如下,其中直线连接的是可能的测试点对,圆圈表示的是每个顶点关联的接受域(Receptive Field),接受域的面积随着其关联顶点距离中心距离的增大而增大。
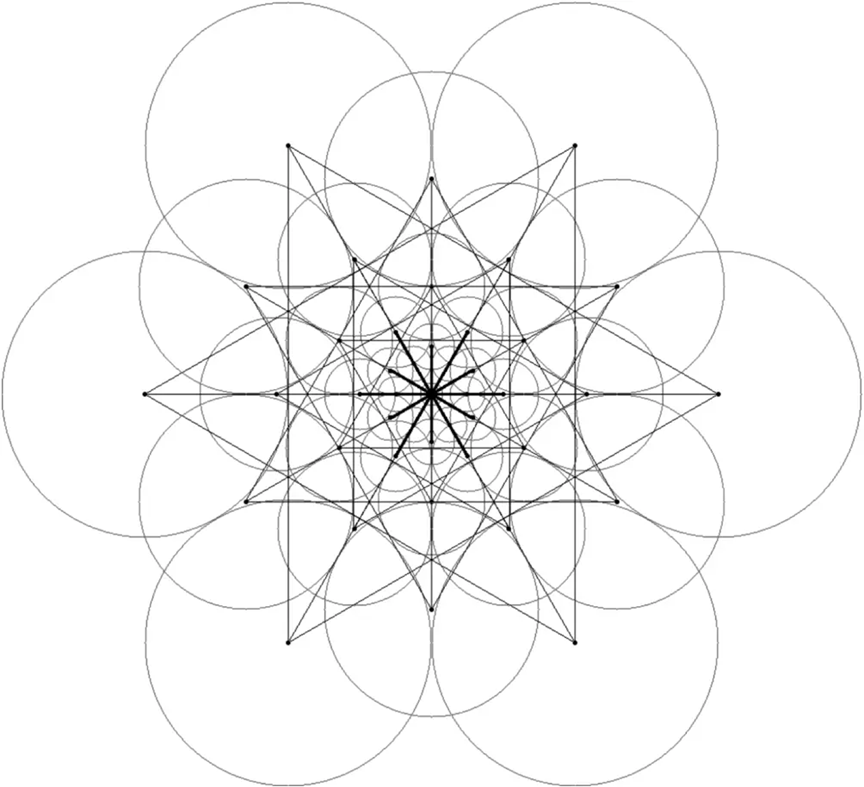
在FREAK算法中,用于比较的像素其强度值都可以看作是在原图中该点附近像素强度的高斯加权和(即指定领域中像素密度均值)。在上图中引入了待比较像素的接受域概念,并且考虑了视网膜上神经细胞和使其发生响应的感光器集合之间的关系。在标准的结构中,FREAK算法包含43个接收域(7层外延点对,每层6个接收域,以及中心点一个接收域)。
FREAK的作者使用了一种自学习技术组织这些接受域中可能的测试对,并按照效果(所谓效果应该是“差异性”,对于没有差异性或差异性较小的测试点可判定其为非关键点)递减排序。通过这种方式,具有更高辨识度的测试对(通过较大特征训练集得出)相对于更低辨识度的测试对具有更高的优先级。在应用中,对于几十个不同大小的接受域和几千个可能的测试对,只有最有用的512个测试对才有保留的价值。
FREAK算法计算描述符时使用的方向和采样区域大小都是相同的,此时FREAK不具备旋转一致性和缩放一致性。在OpenCV的实现中,扩展了该算法,通过一些额外的计算来确定关键点的特征方向和大小,从而实现旋转一致性(作为交换会降低描述符的辨识度)和缩放一致性。通过参数orientationNormalized和scaleNormalized可以分别开启和关闭这两个选项。以上摘编来自链接:https://www.jianshu.com/p/cb9eec8912f4。
注意:描述符是对检测到的关键点进行不同格式的描述,使用不同检测器,在同一图像上可以获得不同的关键点位置,比如角点、原点,质心等。对这些关键点进行不同格式的描述,形成可矢量比较的描述符,然后进行描述符的目标检测形成匹配模式。
网络上还有许多关于FREAK描述符的理论文章可以参考,但是实际测试图像目标检测效果的案例不多,这里给出一些算法的测试案例,实际情况说明FREAK的效果不理想,远不如其他描述符的实际检测效果,也许是用法不正确导致的(因为没有自学习的过程和关键点的选择过程)。





从上面的示例中可以看出FREAK对于同场景的图像检测可能会得出比较好的结果,而对于场景中需要检测目标位置的应用,FREAK效果并不理想,这一点从网络上的文章中也能够看出(此处表示的是个人观点,通过程序测试不同图像的检测效果后得出的结论)。从同一个图片剪裁下来的部分进行目标检测,例如:
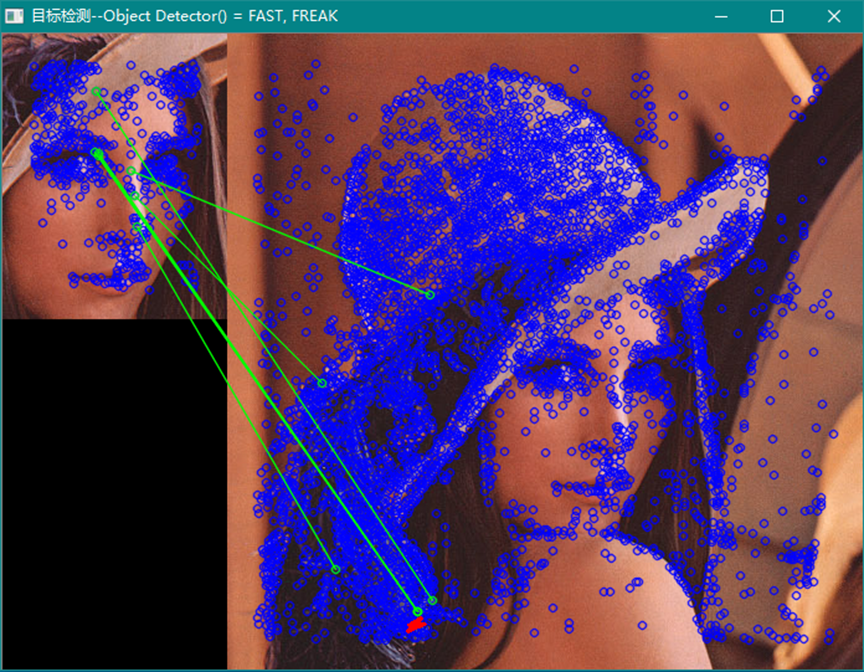

而用其它检测器和描述符则效果很好,如:


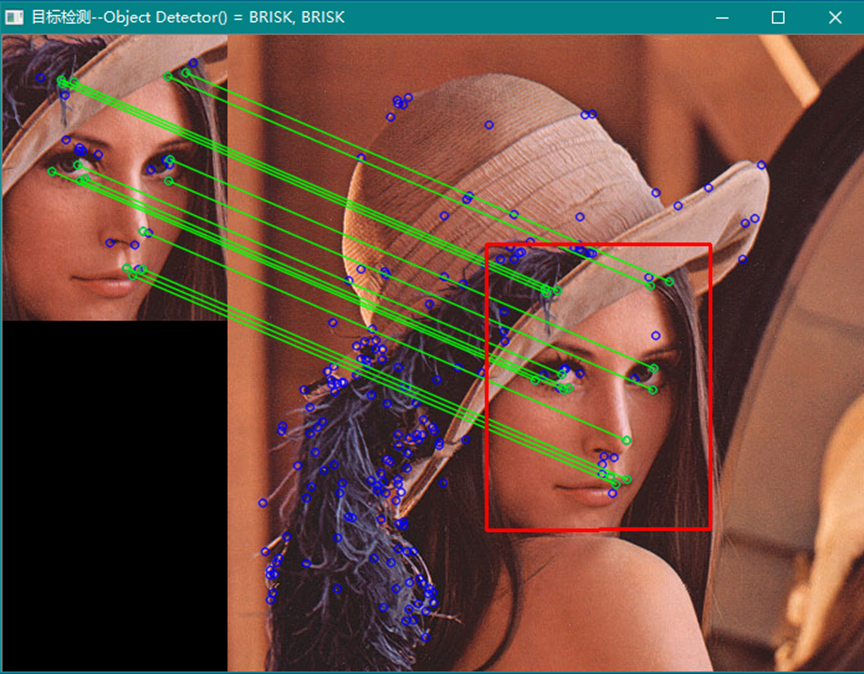
注意:窗口标题指示的是使用的关键点检测器和描述符算法,矩形框给出的是目标位置范围。
14、cv::xfeatures2d::StarDetector
Star检测器给出的是关键点检测算法。它采用的滤波形状类似于星形,因此称之为STAR(CenSurE,中心环绕极值关键点检测)算法。
算法详解见https://blog.csdn.net/youcans/article/details/128565226
检测效果:

上述测试采用的检测器是STAR,描述符为SIFT。所有测试均是在opencv3.4.10版本下进行的。