在Python中数组的功能由列表来实现,本文主要介绍一些力扣上关于数组的题目解法
寻找数组中重复的数字
题目链接

题目大意: 给出一个数组,数组长度为n,数组里的数字在[0,n-1]范围以内,数字可以重复,寻找出数组中任意一个重复的数字,返回结果
解法一
该题最基础的思路是使用字典dict记录每个数字出现的频次,所以dict的键值对<key,value>应为<元素,元素出现的次数>,然后我们遍历这个dict找出任意一个value大于1的元素输出即可
其算法框架如下:
对于数组nums,和字典dict
//对nums数组的元素进行循环操作
for(num: nums){
if(元素在字典中存在){
进行元素的value的自增并替换
}else{
将<元素,1>加入字典
}
}
//遍历字典
for(entry:dict){
if(entry.value>1)return entry.key
}会用到的函数:
- 获取字典的所有键值对:dic.items()
hello这里是分割线,没做完可不能往下看哦------------------------------------------------------------------------
class Solution(object):
def findRepeatNumber(self, nums):
dic={}
#遍历数组
for num in nums:
if num in dic: dic[num]=dic[num]+1
else: dic[num]=1
#遍历字典
for key,value in dic.items():
if(value>1): return key
return -1结语: 可以看到我们通过遍历数组+遍历字典的方式解决了该题,回顾知识点
遍历字典的方式为: for key,value in dic.items():其中key为元素,value为频次
这里主要是为了让羊羊熟悉一下字典的使用,接下来我们使用一次遍历解决该问题
解法二
通过上述解法我们发现,其实我们不必记录每个元素重复了多少次(也就是说<key,value>中的value是没有必要的),只需要知道在遍历到当前元素的时候,检查该元素是否已经重复即可,因此我们舍弃字典改用集合来处理这个问题
算法框架如下:
对于数组nums,和集合set
//对nums数组的元素进行循环操作
for(num: nums){
if(元素在集合中存在){
return num
}else{
将元素加入集合set
}
}
会用到的函数如下:
- 集合的初始化语句: dic=set()
- 向集合添加元素:dic.add(num)
分割线---------------------------------------------------------------------------------------------------------------------
class Solution:
def findRepeatNumber(self, nums: [int]) -> int:
dic = set()
for num in nums:
if num in dic: return num
dic.add(num)
return -1解法三
可以看到的是我们使用集合与字典的去重功能完成了上述题目,可是你有没有发现,题目条件中:元素的范围在[0,n-1]之间,这个条件我们上述两种解法是没有使用到的,如果我们利用这个条件,不使用集合与字典也能解题,这样空间复杂度是不是又优化了
该条件可以解释为,在这个数组中,索引和值是一对多的关系,一个值可以对应多个索引:

核心思想
让当前数组充当集合,建立索引与值的对应关系,我们要理解重复数字在数组中的特殊性,假设我们的数组为[3,2,1,2],那么2这个数字有什么除了重复以外的特殊性呢,现在还看不出来,我们先按照值和下标一一对应的方式重新排列一下这个数组,排序后为[2,1,2,3],因为缺少0这个索引,所以重复的元素一定会填充这个缺失的索引
这种按照下标和数组值重新排列数组的方式叫原地哈希,以后的算法中还会遇到很多次
理解了这个以后我们再来看,索引0处的2和索引2处的2有什么隐藏关系呢?
对于已经重复的元素,在本来的索引处(也就是索引2处的2),一定有nums[i]=i,而散落在其他索引位置的元素一定没有位置可以去(索引0处的2只能待在nums[i]!=i的位置),故当我们遍历到一个元素,nums[i]!=i (nums[0]!=2),但是nums[nums[i]]==num[i] (nums[2]=2)时,说明元素重复
分析过程
定义当前数组为nums,初始索引值为i=0;
- 如果nums[i]=i :说明数字此时已经在索引位置,不需要交换,所以跳过即可
- 如果nums[nums[i]]=nums[i]: 代表nums[i]处的索引和i处的索引元素值都是nums[i],这个时候我们就找到了一组重复的值了,直接返回结果
- 其他情况: 交换索引i和索引nums[i]的元素值
举个栗子
对于数组[2,3,1,0,2,5,3]来说,初始情况如下:
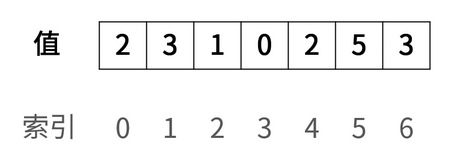
- 我们用绿色表示当前的索引i
- 用蓝色表示当nums[i]
- 红色表示nums[nums[i]]
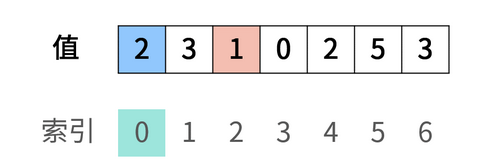
第一步,遍历索引0,蓝红色处的值并不相等,进行交换操作
交换前:
交换后,注意此时蓝红色的值已经发生了变化,因为原来在索引2处的值现在被交换到索引1处了:
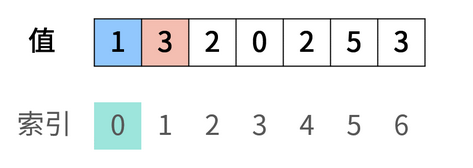
继续进行交换操作,因为蓝红色的值依旧不相等:

继续交换!!

可以发现,经过我们前面的交换,数组的前端的值和索引已经完全一一对应了,在一一对应的情况下,我们应该执行索引++,跳过操作,因此下一个被遍历的索引应该是4
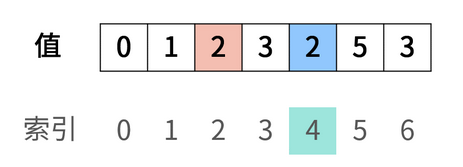
好了关键点来了,在遍历索引4的时候我们发现蓝色与红色的值终于相等了,这就是我们向返回的结果,此时我们应返回结果2
分割线给出答案---------------------------------------------------------------------------------------------------------
class Solution:
def findRepeatNumber(self, nums: [int]) -> int:
i = 0
while i < len(nums):
if nums[i] == i:
i += 1
continue
if nums[nums[i]] == nums[i]: return nums[i]
#这里是一个交换操作
nums[nums[i]], nums[i] = nums[i], nums[nums[i]]
return -1关于python中的交换操作:
Python 中, a,b=c,d 操作的原理是先暂存元组 (c,d) ,然后 “按左右顺序” 赋值给 a 和 b 。
因此,若写为 nums[i],nums[nums[i]]=nums[nums[i]],nums[i],则 nums[i]会先被赋值,之后 nums[nums[i]] 指向的元素则会出错,这点需要注意一下总结起来就是:在交换时如果后者用到了前者(nums[nums[i]]用到了nums[i],你把nums[i
]当成x,是不是就是nums[x]用到了x)就会出错,需要反着写