目录
- 1.mixup技术简介
- 2.pytorch实现代码,以图片分类为例
1.mixup技术简介

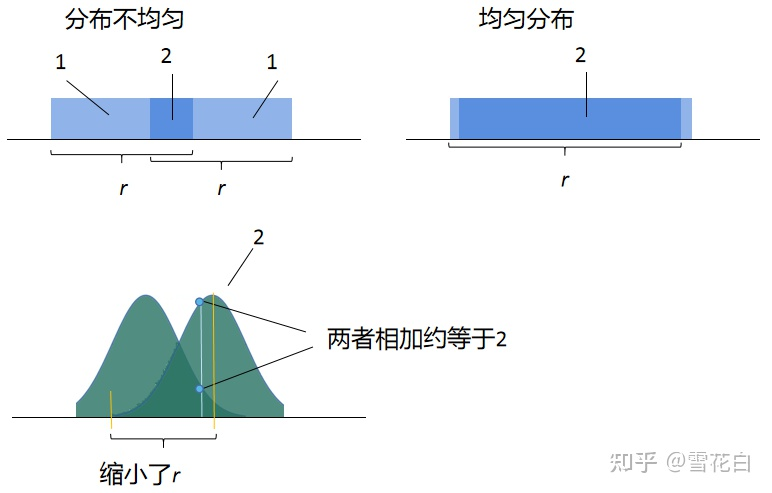
mixup是一种数据增强技术,它可以通过将多组不同数据集的样本进行线性组合,生成新的样本,从而扩充数据集。mixup的核心原理是将两个不同的图片按照一定的比例进行线性组合,生成新的样本,新样本的标签也是进行线性组合得到。比如,对于两个样本x1和x2,它们的标签分别为y1和y2,那么mixup生成的新样本x’和标签y’如下:
x’ = λx1 + (1-λ)x2
y’ = λy1 + (1-λ)y2
其中,λ为0到1之间的一个随机数,它表示x1和x2在新样本中的权重。
本文中,使用mixup扩充数据集后的损失函数,为:
loss = λ * criterion(outputs, targets_a) + (1 - λ) * criterion(outputs, targets_b)
即由两张图片融合后新图片的损失为,分别计算原先两图片与各自标签的损失值之和。
mixup也可以增加数据集的多样性,从而降低模型的方差,提高模型的鲁棒性。
总之,mixup是一种非常实用的数据增强技术,它可以用于各种机器学习任务中,可以有效地防止过拟合,并且可以提高模型的泛化能力。在实际应用中,mixup可以帮助我们更好地利用有限的数据集,并且提高模型的性能。
2.pytorch实现代码,以图片分类为例
import matplotlib.pyplot as plt
import torchvision
import torch
import torch.nn as nn
import torchvision.models as models
import torchvision.transforms as transforms
import numpy as np
import torch.nn.functional as F
from PIL import Image
import os
import cv2
# 加载resnet18模型
resnet18 = models.resnet18(pretrained=False)
# 获取resnet18最后一层输出,输出为512维,最后一层本来是用作 分类的,原始网络分为1000类
# 用 softmax函数或者 fully connected 函数,但是用 nn.identtiy() 函数把最后一层替换掉,相当于得到分类之前的特征!
#Identity模块,它将输入直接传递给输出,而不会对输入进行任何变换。
resnet18.fc = nn.Identity()
# 构建新的网络,将resnet18的输出作为输入
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.resnet18 = resnet18
self.fc1 = nn.Linear(512, 256)
self.fc2 = nn.Linear(256, 64)
self.fc3 = nn.Linear(64, 10)
self.fc4 = nn.Linear(10, 2)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = self.resnet18(x)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = F.relu(self.fc4(x))
x = self.softmax(x)
x=x.view(-1,2)
return x
#使用mixup时的数据集融合器,输入数据集的输入(一批图片),以及对应标签,返回线性相加后的图片
def mixup_data(x, y, alpha=1.0):
#随机生成一个 beta 分布的参数 lam,用于生成随机的线性组合,以实现 mixup 数据扩充。
lam = np.random.beta(alpha, alpha)
#生成一个随机的序列,用于将输入数据进行 shuffle。
batch_size = x.size()[0]
index = torch.randperm(batch_size)
#得到混合后的新图片
mixed_x = lam * x + (1 - lam) * x[index, :]
#得到混图对应的两类标签
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam
# 实例化网络
net = Net()
# 将模型放入GPU
net = net.cuda()
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化器,添加l2正则化
optimizer = torch.optim.Adam(net.parameters(), lr=0.0005,weight_decay=0)
# 加载数据集
# 创建一个transform对象
def rgb2bgr(image):
image = np.array(image)[:, :, ::-1]
image=Image.fromarray(np.uint8(image))
return image
transform = transforms.Compose([
transforms.ColorJitter(brightness=1, contrast=1, saturation=1, hue=0.5),
# rgb转bgr
torchvision.transforms.Lambda(rgb2bgr),
torchvision.transforms.Resize(112),
# 入的图片为PIL image 或者 numpy.nadrry格式的图片,其shape为(HxWxC)数值范围在[0,255],转换之后shape为(CxHxw),数值范围在[0,1]
transforms.ToTensor(),
# 进行归一化和标准化,Imagenet数据集的均值和方差为:mean=(0.485, 0.456, 0.406),std=(0.229, 0.224, 0.225),
# 因为这是在百万张图像上计算而得的,所以我们通常见到在训练过程中使用它们做标准化。
transforms.Normalize(mean=[0.406, 0.456, 0.485], std=[0.225, 0.224, 0.229]),
# #这行代码表示使用transforms.RandomErasing函数,以概率p=1,在图像上随机选择一个尺寸为scale=(0.02, 0.33),长宽比为ratio=(1, 1)的区域,
# #进行随机像素值的遮盖,只能对tensor操作:
transforms.RandomErasing(p=0.1, scale=(0.02, 0.2), ratio=(1, 1), value='random')
])
train_dataset = torchvision.datasets.ImageFolder(r'D:\eyeDataSet\train', transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=128, shuffle=True)
test_dataset = torchvision.datasets.ImageFolder(r'D:\eyeDataSet\test', transform=transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=128, shuffle=True)
## 绘制训练及测试集迭代曲线
# 记录训练集准确率
train_acc = []
# 记录测试集准确率
test_acc = []
for epoch in range(50):
running_loss = 0.0
#[(0, data1), (1, data2), (2, data3), ...]
for i, data in enumerate(train_loader, 0):
# 获取输入
inputs, labels = data
inputs, labels = inputs.cuda(), labels.cuda()
# mixup扩充数据集
inputs, targets_a, targets_b, lam = mixup_data(inputs, labels, alpha=1.0)
# 梯度清零
optimizer.zero_grad()
# forward + backward
outputs = net(inputs)
#这里对应调整了使用mixup后的数据集的loss
loss = lam * criterion(outputs, targets_a) + (1 - lam) * criterion(outputs, targets_b)
loss.backward()
# 更新参数
optimizer.step()
# 打印log信息
# loss 是一个scalar,需要使用loss.item()来获取数值,不能使用loss[0]
running_loss += loss.item()
if i % 10 == 9: # 每200个batch打印一下训练状态
print('[%d, %5d] loss: %.3f' \
% (epoch+1, i+1, running_loss / 2000))
running_loss = 0.0
# 在每次训练完成后,使用测试集进行测试
correct = 0
total = 0
with torch.no_grad():
for i2,data2 in enumerate(test_loader):
#控制测试集的数量
if i2>5:
break
images, labels = data2
images, labels = images.cuda(), labels.cuda()
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
test_acc.append(100 * correct / total)
print('Accuracy of the network on the test images: %.3f,now max acc is %.3f' % (
100 * correct / total,max(test_acc)))
# 保存测试集上准确率最高的模型
if 100 * correct / total == max(test_acc):
if not os.path.exists(r'./result'):
os.makedirs(r'./result')
if max(test_acc)>93:
savename="./result/bestmodel"+"%.3f"%max(test_acc)+".pth"
torch.save(net.state_dict(), savename)
print("最大准确度:",max(test_acc))