前言,
一次线程池的不当使用,导致了现场出现了线程死锁,接口一直不返回。而且由于这是一个公共的线程池,其他使用了次线程池的业务也一直阻塞,系统出现了OOM,不过是幸好是线程同事测试出来的,没有直接在生产坏境中出现这种事故,否则后果不堪设想。
具体情况
我接到一个需求,需要在多个excel中,根据excel中数据的关联关系,拼接出完整的记录,然后入库。其实这种情况,跟数据库中表情况挺类似的,如果将excel必做数据库中的表,就是几个表有数据,需要根据关联关系,写一个查询SQL,将查询出来的结果入库到另一张表中。
举个例子,虽然不太恰当,但是能说明情况
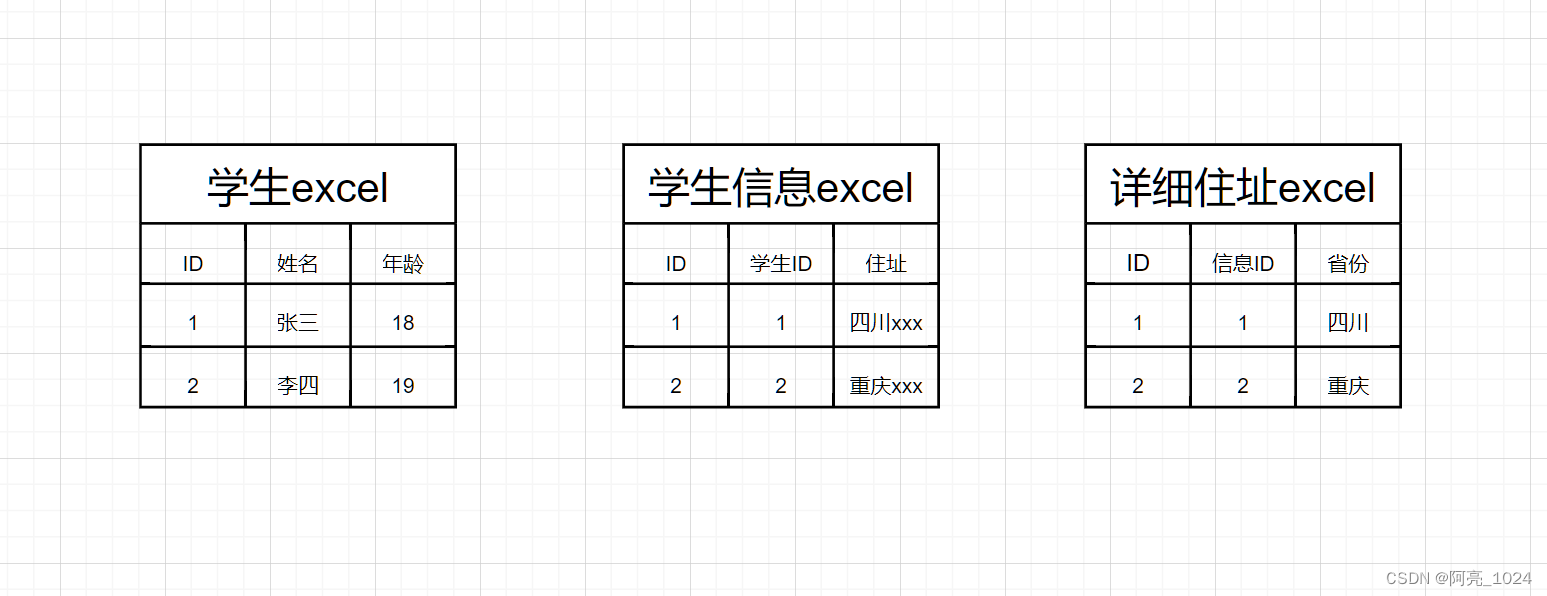
学生excel、学生信息excel、详细住址excel之间的关系是一对一对一,一条学生对应一条学生信息,一条学生信息对应一条详细住址。现在就是要将这三个excel中的记录,拼接成一条完整的记录,然后入库,每个excel中都有上万条记录。这里是excel不是数据库,没法写SQL。感觉此时就像自己来实现SQL的连表逻辑,多层循环,第一层遍历学生excel的数据,拿到一条学生数据之后再遍历第学生信息excel,根据学生ID去学生信息exe找找到学生信息记录,如果还有一层关联关系,就还得套一层循环。
当然,这是最原始的想法,但是我不想这么做,一个表上万条记录,再套三层循环,效率很低了,而且就算三层循环跑完了,组装出来的上万条记录,也不可能一次性就能入库。所以我采用了线程池,我是这么想的:
- 那么多记录,使用线程分批处理,每个线程处理一批数据,每个批次1000条记录,相当于每次入库1000条。
- 当根据学生ID拿到一条学生信息记录之后,再使用线程池,分批去遍历详细住址excel,分批寻找,找到记录就起来,待所有的线程执行完成之后,将找到的记录返回去,再拼接起来,就成了完成的记录。
大概流程如下
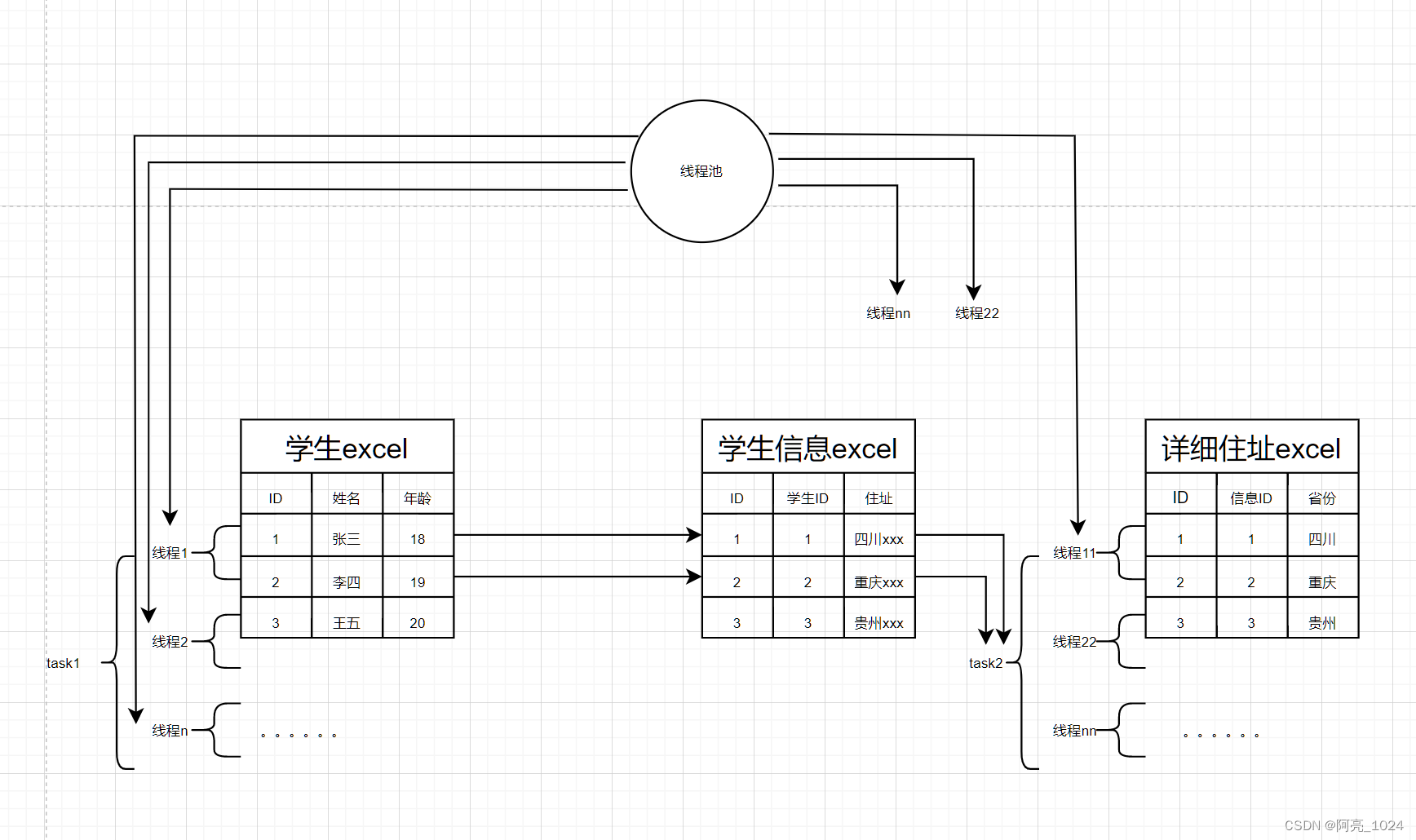
task1,就是分批处理学生excel,拿到每个学生记录,再去循环学生信息excel,找到唯一的记录,进行拼接,然后再使用线程池,执行task2,根据信息ID,去分批遍历详细住址excel,找到详细住址记录,再将其拼接,最终拼接成唯一的记录,返回,入库。
原因分析
写完代码之后,我自己造了一些数据进行测试,没得问题,测试也造了一些数据测试,也没发现这个问题。(没有进行大量数据进行性能测试),丢给现场,现场同事使用真实数据进行验证的时候出了问题。为啥自测和测试同事测试都没问题,而现场同事验证就出了问题呢?本质的原因就是数据量,自测和测试同事在测试时造的数据数据量都很小,一旦数据量大了就会出现问题。
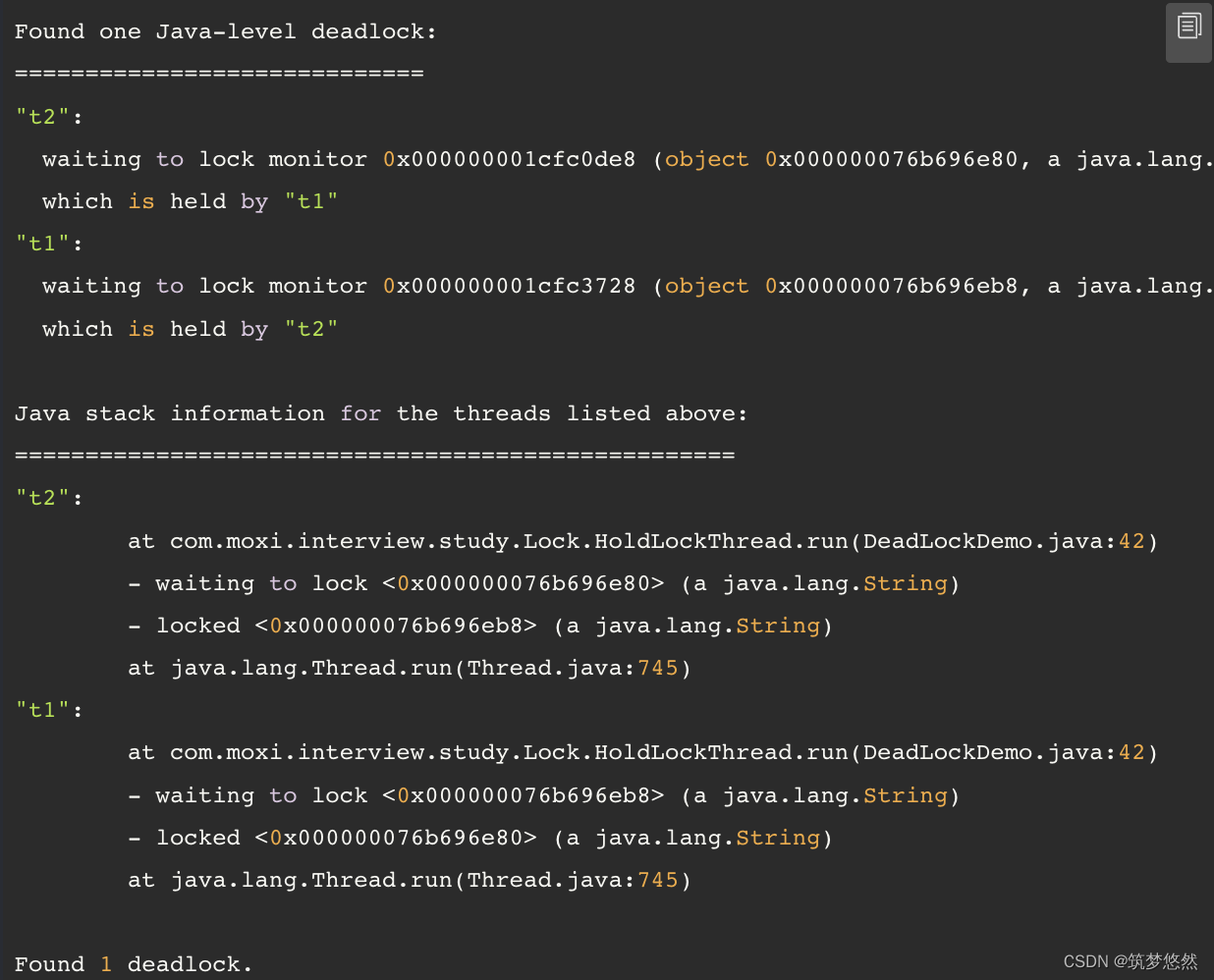
数据量小的时候,task1使用线程池中的线程,没用使用完,线程池中还有剩余的线程,所以task1执行到需要条用task2时,还有多余的线程去执行task2。而一旦数据量比较大的时候,执行到task1时,就直接将线程池中所有的线程占用完了,线程池中的所有线程都在执行task1,然后执行到需要调用task2时,又要到线程池中去获取线程,结果此时已经没有多余的线程了,task1就阻塞了,等待线程池中有空余的线程。但线程池中所有的线程都阻塞在调用task2处,都在等待,就形成了线程死锁。
解决办法
当然,出现这个问题,说明我们在设计之初就有漏洞,最正确的做法应该是设计时就不要让同一个线程池执行父子任务。那既然出现了这个问题,该如何解决呢?或者说,这个情况正确的设计是什么呢?我觉得有两个方向:
- 如果系统资源足够:那么就再创建一个线程池,让task2使用另一个线程池,相互独立,那么就不会出现线程死锁
- 如果系统资源不够:那么task2就不使用线程池进行执行,使其单线程跑,那么也不会出现线程死锁。
两种方式的比较:
如果最初在设计时,我更倾向于使用方式2,因为task1将所有的线程都占满了,那说明线程池的利用率已经是最高了,让task2去单线程跑,也没有什么不妥。而如果一味的去新建线程池,有滥用系统资源的嫌疑。
讲师我现在的情况是,代码已经写成了这样了,我更倾向于方式2,因为那样对我原有的代码改动最小,只用将task2提交到另一个线程池就可以了,而且我们硬件资源也是足够的。如果采用方式1,改动比较大。
示例代码
这种情况是与语言无关的,我的主语言是java,所以使用java代码写一个示例,让java道友有更深刻的认识。
// java代码待补充









![Python进阶-----面对对象6.0(绑定方法[类方法、静态方法]与内置方法)](https://img-blog.csdnimg.cn/5c0ec2c6c7364648b068b4e2cefdd18c.png)