背景需求:
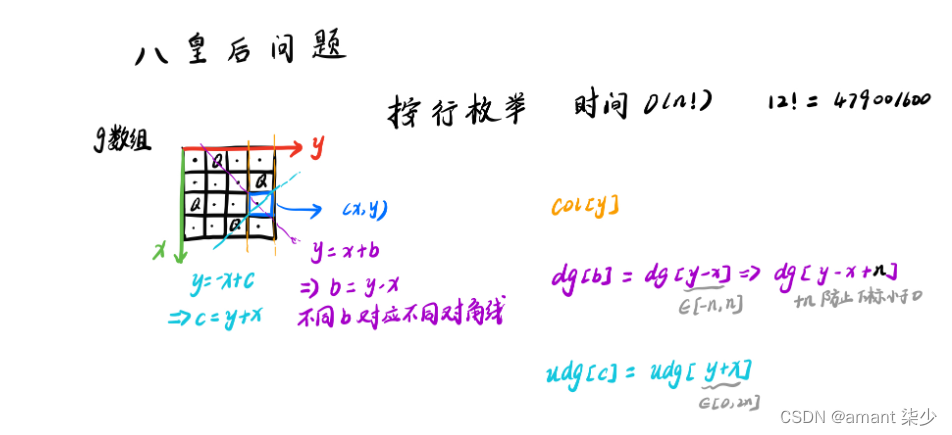
上一篇计算了教职工的姓氏谁最多,col[0]]
这一篇统计教职工的(姓氏+名字)里面哪些字出现最多。
材料准备:
1、下载所有员工名单


写代码。py
包含”姓氏+名字“的重字率统计
from pandas import DataFrame, Series
import pandas as pd
import numpy as np
import xlrd
# 读取列
worksheet = xlrd.open_workbook(r'D:\test\02办公类\08姓氏最多的人\20230227上海市闵行区景谷第二幼儿园教职工列表 - 副本.xls')
sheet_names= worksheet.sheet_names()
print(sheet_names)
for sheet_name in sheet_names:
sheet = worksheet.sheet_by_name(sheet_name)
rows = sheet.nrows # 获取行数
cols = sheet.ncols # 获取列数,尽管没用到
all_content = []
cols = sheet.col_values(1) # 获取第二列内容, 数据格式为此数据的原有格式(原:字符串,读取:字符串; 原:浮点数, 读取:浮点数)
print(cols[1:])
print(cols[1:])
print(type(cols[1])) #查看数据类型
# name_list = ["张三", "李四", "周瑜", "张三", "张三", "李四", "王五", "张飞", "张飞", "周瑜"]
#提取第一个姓(目前没有复姓,所以都取第一个姓)
b = []
for i in cols[1:]: # cols[1:]不要第一行的”教职工名字“
# for c in i: #在所有的名字中的第1-4个字开始遍历(包括姓氏)
for c in i[1:]: # 在所有的名字中的第2个字开始遍历(不包括姓氏)
print(c)
b.append(c)
print(b)
name_dict = {}
for name in b:
# 取出字典中的所有keys值
key_list = name_dict.keys()
# key_list = name_dict[0]
# print(key_list)
if name in key_list:
name_dict[name] += 1
else:
name_dict[name] = 1
# # 根据字典中的value值进行倒序排序
name_dict = sorted(name_dict.items(), key=lambda item:item[1], reverse=True)
print(name_dict )
d=[]
for c in range(0,len(name_dict)):
aa=name_dict[c][0]
bb=name_dict[c][1]
print(aa,bb)

2、结果展示

问题:
我发现姓氏也在里面容易搞混,如果不需要姓氏,只计算名字的第2、3、4个字,怎么做?
微调加个取值范围即可,

不包含姓氏的”名“统计
from pandas import DataFrame, Series
import pandas as pd
import numpy as np
import xlrd
# 读取列
worksheet = xlrd.open_workbook(r'D:\test\02办公类\08姓氏最多的人\20230227上海市闵行区景谷第二幼儿园教职工列表 - 副本.xls')
sheet_names= worksheet.sheet_names()
print(sheet_names)
for sheet_name in sheet_names:
sheet = worksheet.sheet_by_name(sheet_name)
rows = sheet.nrows # 获取行数
cols = sheet.ncols # 获取列数,尽管没用到
all_content = []
cols = sheet.col_values(1) # 获取第二列内容, 数据格式为此数据的原有格式(原:字符串,读取:字符串; 原:浮点数, 读取:浮点数)
print(cols[1:])
print(cols[1:])
print(type(cols[1])) #查看数据类型
# name_list = ["张三", "李四", "周瑜", "张三", "张三", "李四", "王五", "张飞", "张飞", "周瑜"]
#提取第一个姓(目前没有复姓,所以都取第一个姓)
b = []
for i in cols[1:]: # cols[1:]不要第一行的”教职工名字“
# for c in i: #在所有的名字中的第1-4个字开始遍历(包括姓氏)
for c in i[1:]: # 在所有的名字中的第2个字开始遍历(不包括姓氏)
print(c)
b.append(c)
print(b)
name_dict = {}
for name in b:
# 取出字典中的所有keys值
key_list = name_dict.keys()
# key_list = name_dict[0]
# print(key_list)
if name in key_list:
name_dict[name] += 1
else:
name_dict[name] = 1
# # 根据字典中的value值进行倒序排序
name_dict = sorted(name_dict.items(), key=lambda item:item[1], reverse=True)
print(name_dict )
d=[]
for c in range(0,len(name_dict)):
aa=name_dict[c][0]
bb=name_dict[c][1]
print(aa,bb)


名字中出现
最多的是“红”12人,
其次是“美”6人
第三是“英”5人
“霞、爱、伟、丽”4人
“文、芳、华、丹、雯、萍、莲、莉、慧、梅”3人
一看名字就知道教工中的女性比例很高啊
同样对我班级孩子的名字进行统计(有重复率的如下)


欣3人,女孩
一3人,男孩
贝2人,女孩
天2人,女孩
颖2人,女孩
清2人,女孩
喆2人,男孩
博2人,男孩

![[1.3_1]计算机系统概述——操作系统的运行机制](https://img-blog.csdnimg.cn/img_convert/ef202017d6e57cd710ee55f4dd67be68.png)