知识要点
-
AlexNet 是2012年ISLVRC 2012竞赛的冠军网络。
-
VGG 在2014年由牛津大学著名研究组 VGG 提出。
一 AlexNet详解
1.1 Alexnet简介
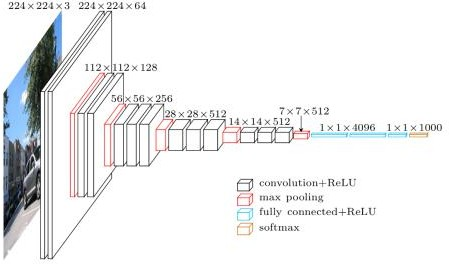
AlexNet 是2012年ISLVRC 2012(ImageNet Large Scale Visual Recognition Challenge)竞赛的冠军网络,分类准确率由传统的 70%+提升到 80%+。 它是由Hinton和他的学生Alex Krizhevsky设计的。也是在那年之后,深度学习开始迅速发展。
-
ISLVRC 2012竞赛
-
训练集:1,281,167张已标注图片
-
验证集:50,000张已标注图片
-
测试集:100,000张未标注图片
-
该网络的亮点在于:
- 首次利用 GPU 进行网络加速训练。
- 使用了 ReLU 激活函数,而不是传统的 Sigmoid 激活函数以及 Tanh 激活函数。
- 使用了 LRN 局部响应归一化。
- 在全连接层的前两层中使用了 Dropout 随机失活神经元操作,以减少过拟合。
过拟合:根本原因是特征维度过多,模型假设过于复杂,参数 过多,训练数据过少,噪声过多,导致拟合的函数完美的预测 训练集,但对新数据的测试集预测结果差。 过度的拟合了训练 数据,而没有考虑到泛化能力。
使用 Dropout 的方式在网络正向传播过程中随机失活一部分神经元。

经卷积后的矩阵尺寸大小计算公式为:N = (W − F + 2P ) / S + 1
-
输入图片大小 W×W
-
Filter大小 F×F
-
步长 S
-
padding的像素数 P
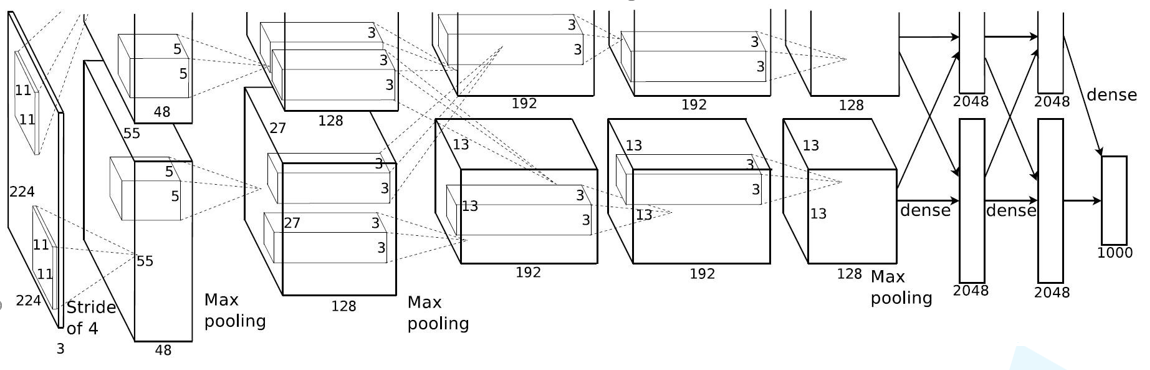
1.2 模型网络内部
1.2.1 conv1层

Conv1: kernels:48*2=96 kernel_size:11 padding:[1, 2] stride:4
-
input_size: [224, 224, 3]
-
output_size: [55, 55, 96]
N = (W − F + 2P ) / S + 1 = [224-11+(1+2)]/4+1 = 55
1.2.2 Maxpool1层
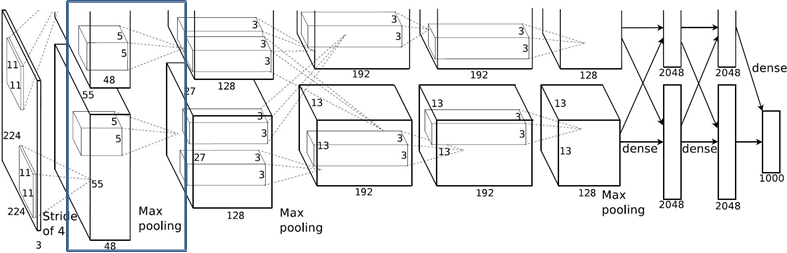
Conv1: kernels:48*2=96 kernel_size:11 padding: [1, 2] stride:4 output_size: [55, 55, 96]
Maxpool1: kernel_size:3 pading: 0 stride:2
-
input_size: [55, 55, 96]
-
output_size: [27, 27, 96]
- N = (W − F + 2P ) / S + 1 =(55-3)/2+1 = 27
1.2.3 Conv2层
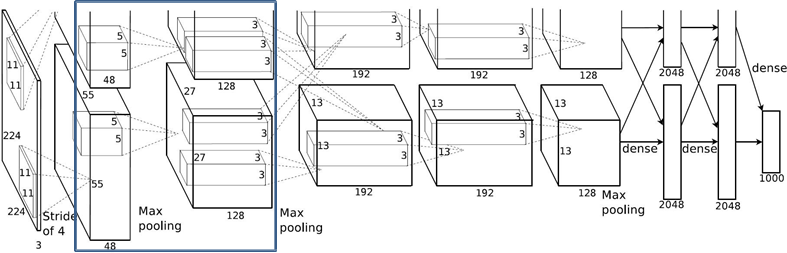
Conv1: kernels:48*2=96 kernel_size:11 padding: [1, 2] stride:4 output_size: [55, 55, 96]
Maxpool1: kernel_size:3 pading: 0 stride:2 output_size: [27, 27, 96]
Conv2: kernels:128*2=256 kernel_size:5 padding: [2, 2] stride:1
-
input_size: [27, 27, 96]
-
output_size: [27, 27, 256]
N = (W − F + 2P ) / S + 1 =(27-5+4)/1+1 = 27
1.2.4 Maxpool2层
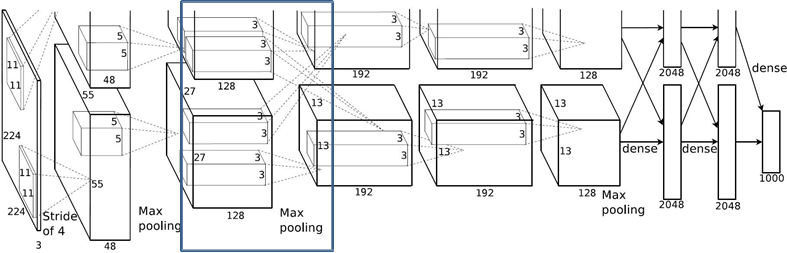
Conv2: kernels:128*2=256 kernel_size:5 padding: [2, 2] stride:1 output_size: [27, 27, 256]
Maxpool2: kernel_size:3 pading: 0 stride:2
-
input_size: [27, 27, 256]
-
output_size: [13, 13, 256]
N = (W − F + 2P ) / S + 1 = (27-3)/2+1 = 13
1.2.5 Conv3层
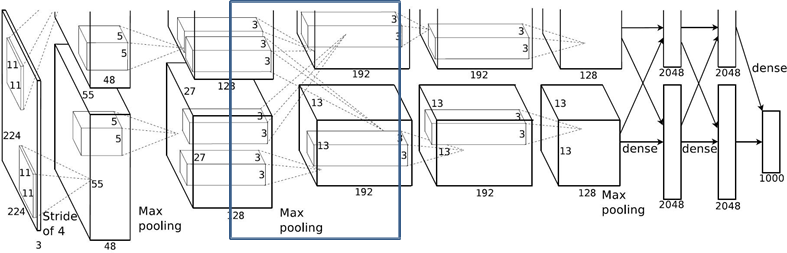
Maxpool2: kernel_size:3 pading: 0 stride:2 output_size: [13, 13, 256]
Conv3: kernels:192*2=384 kernel_size:3 padding: [1, 1] stride:1
-
input_size: [13, 13, 256]
-
output_size: [13, 13, 384]
N = (W − F + 2P ) / S + 1 =(13-3+2)/1+1 = 13
1.2.6 Conv4层
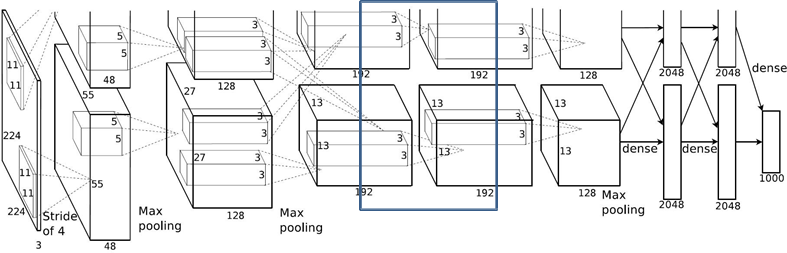
Conv3: kernels:192*2=384 kernel_size:3 padding: [1, 1] stride:1 output_size: [13, 13, 384]
Conv4: kernels:192*2=384 kernel_size:3 padding: [1, 1] stride:1
-
input_size: [13, 13, 384]
-
output_size: [13, 13, 384]
N = (W − F + 2P ) / S + 1 = (13-3+2)/1+1
1.2.7 Conv5层
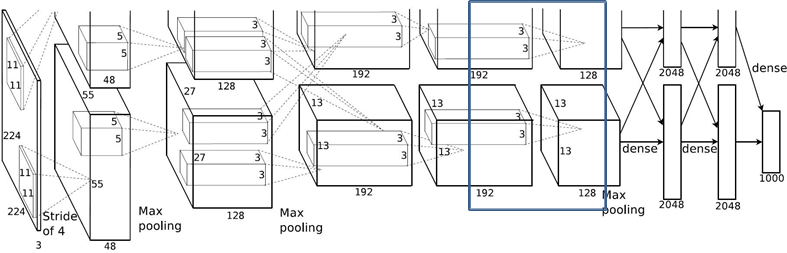
Conv4: kernels:192*2=384 kernel_size:3 padding: [1, 1] stride:1 output_size: [13, 13, 256]
Conv5: kernels:128*2=256 kernel_size:3 padding: [1, 1] stride:1
-
input_size: [13, 13, 384]
-
output_size: [13, 13, 256]
N = (W − F + 2P ) / S + 1 = (13-3+2)/1+1
1.2.8 Maxpool3层
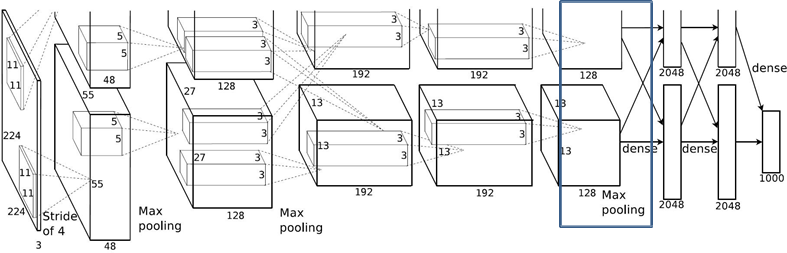
Conv5: kernels:128*2=256 kernel_size:3 padding: [1, 1] stride:1 output_size: [13, 13, 256]
Maxpool3: kernel_size:3 padding:0 stride:2
-
input_size: [13, 13, 256]
-
output_size: [6, 6, 256]
N = (W − F + 2P ) / S + 1 = (13-3)/2+1 = 6
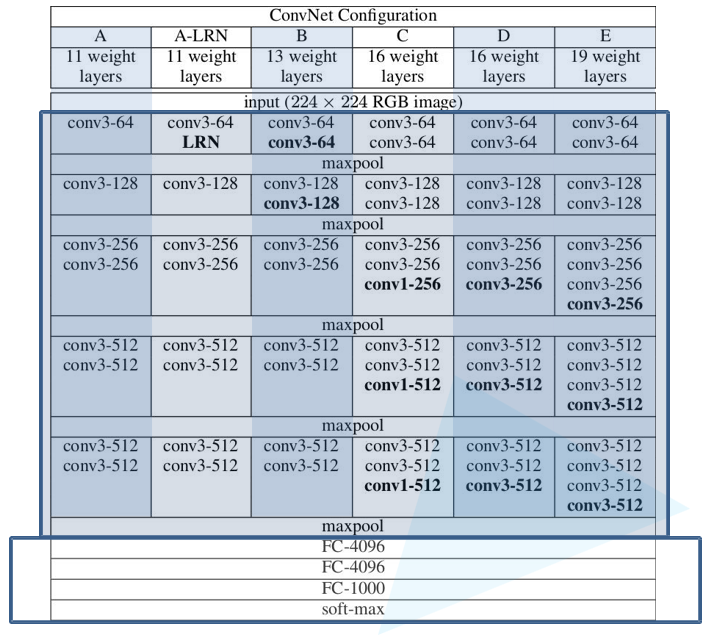
1.3 图像内部尺寸变换
| layer_name | kernel_size | kernel_num | padding | stride |
| Conv1 | 11 | 96 | [1, 2] | 4 |
| Maxpool1 | 3 | None | 0 | 2 |
| Conv2 | 5 | 256 | [2, 2] | 1 |
| Maxpool2 | 3 | None | 0 | 2 |
| Conv3 | 3 | 384 | [1, 1] | 1 |
| Conv4 | 3 | 384 | [1, 1] | 1 |
| Conv5 | 3 | 256 | [1, 1] | 1 |
| Maxpool3 | 3 | None | 0 | 2 |
| FC1 | 2048 | None | None | None |
| FC2 | 2048 | None | None | None |
| FC3 | 1000 | None | None | None |
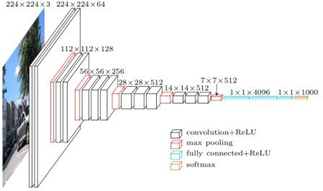
二 VGG详解
2.1 简介
VGG在2014年由牛津大学著名研究组VGG (Visual Geometry Group) 提出,斩获该年ImageNet竞 中 Localization Task (定位 任务) 第一名 和 Classification Task (分类任务) 第二名。
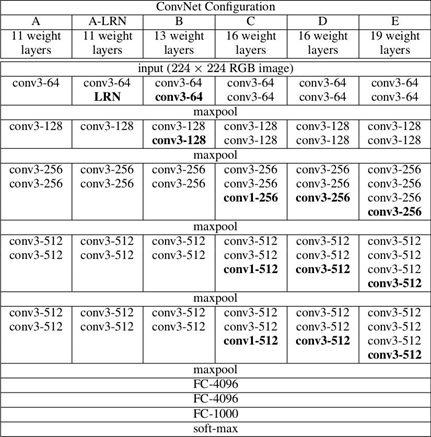
网络中的亮点:通过堆叠多个 3x3的卷积核 来替代大尺度卷积核(减少所需参数)
论文中提到,可以通过堆叠两个3x3的卷 积核替代5x5的卷积核,堆叠三个3x3的卷积核替代7x7的卷积核。
2.2 基本概念拓展—CNN感受野
在卷积神经网络中,决定某一层输出结果中一个元素所对应的输入层的区域大小,被称作感受野(receptive field)。通俗的解释是,输出feature map上的一个单元对应输入层上的区域大小。
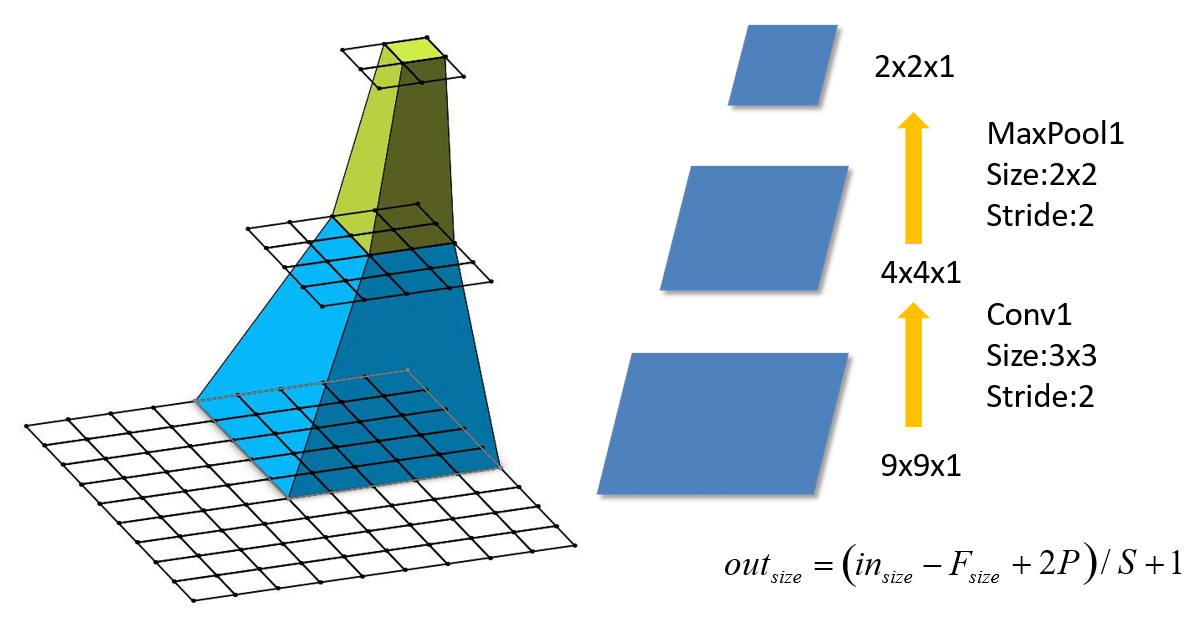
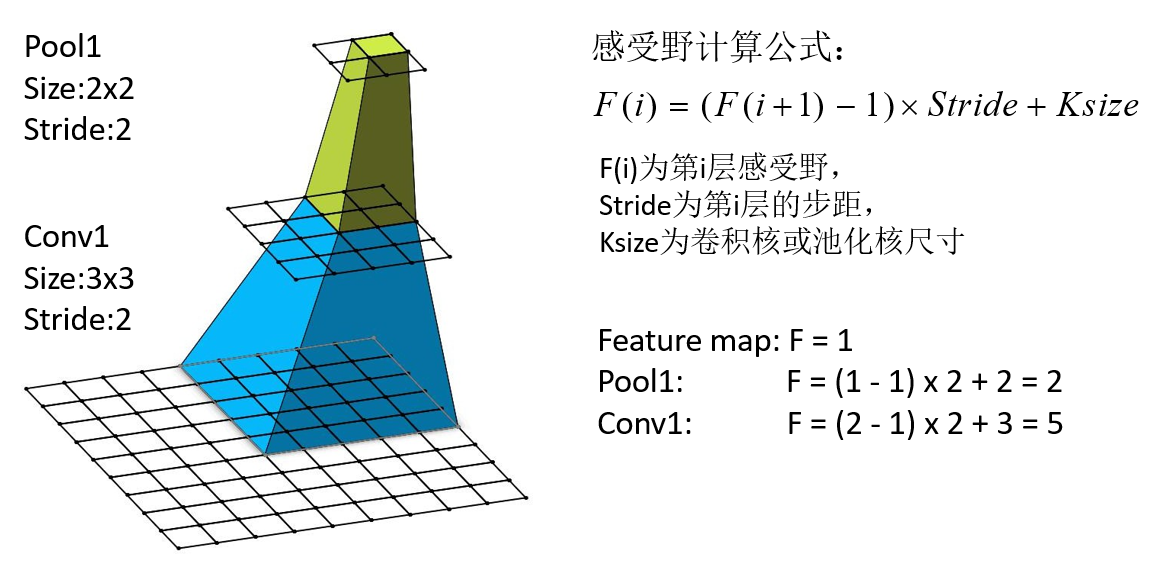
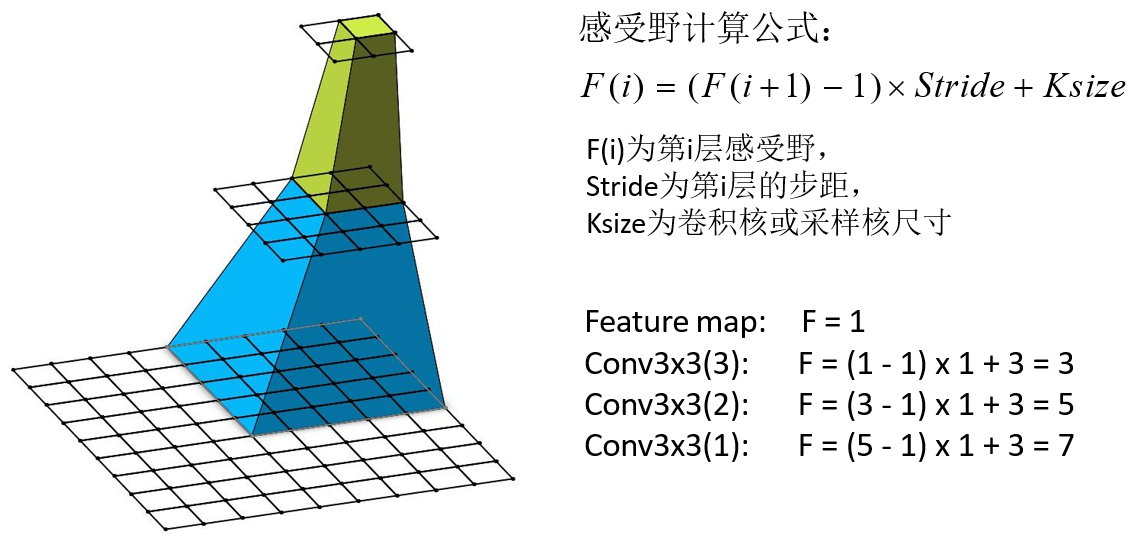
论文中提到,可以通过堆叠两个3x3的卷积核替代5x5的卷积核,
堆叠三个3x3的卷积核替代7x7的卷积核。
使用7x7卷积核所需参数,与堆叠三个3x3卷积核所需参数(假设输入输出channel为C)
- conv的stride为1,padding为1
- maxpool的size为2,stride为2
![]()