1. 引言
在学习笔记一中,我们介绍了几种常用的分类模型框架,如VGGNet,GoogleNet,和ResNet,并且介绍了几种简单的分割模型。如FCN,UNet,SegNet和Deeplab。从深度学习兴起到现在,模型一直朝着以下几个方向发展:
1模型特征提取能力;
2深层次模型构建问题;
3模型效率和模型体量问题。
2. 分割模型
1. Deeplab系列
学习笔记一中,我们介绍了Deeplab-v1版本,Deeplab-v1使用了空洞卷积,减少池化层的同时,扩大模型的感受野,可以在很大程度上还原了图像的低层特征。
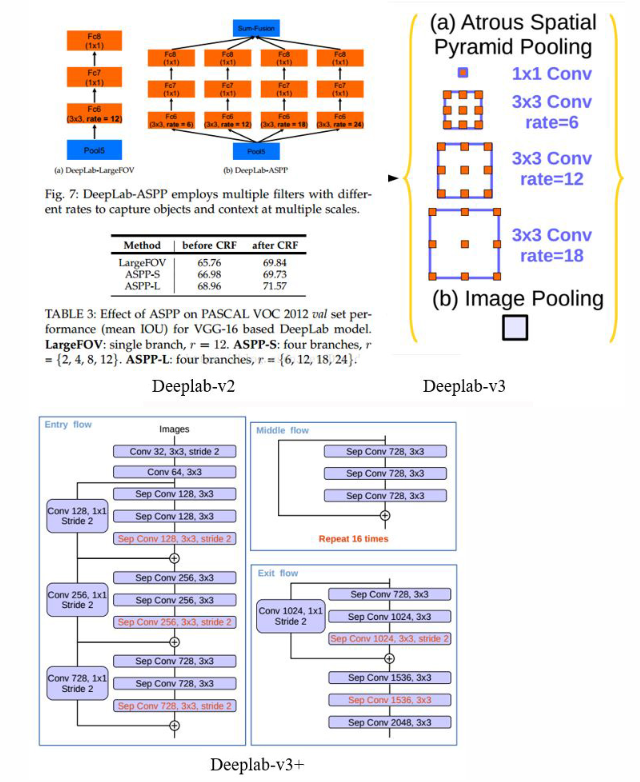
在Deeplab-v2中,受到SPP-Net的金字塔结构启发,采用多级金字塔结构,使用多尺度空洞卷积,构成ASPP结构,在v1和v2结构中,还使用了条件随机场CRF来优化分割结果。Deeplab-v3优化了ASPP结构,在v2版本中,由于空洞卷积的rate设置过大(论文中使用的是6,12,18),3×3的空洞卷积未能考虑邻域信息,会退化成1×1的卷积核。于是v3版本中加入了一个并行1×1的卷积核分支,再加上原来rate=6,12,18的卷积核并行,最后使用concat函数进行特征融合。在Deeplab-v3+中,传统卷积网络被替换成了深度可分离卷积,Encoder继续使用了Deeplab-v3的编码器,在后面又加入了传统分割的上升采样Decoder结构。
在传统卷积计算中,每个卷积核与输入层特征图相乘后再相加,输出特征图是由卷积核个数决定,如此实现特征提取。深度可分离卷积的卷积核个数和输入特征图相等,每个卷积核和相对应的特征图相乘,即输入特征图与输出特征图相等,如此减少了相乘后相加的操作,大大减少了计算量。在框架上,Deeplab-v3+使用了Xception结构,并用步长为2的深度分离卷积替代了最大池化层,减少特征的损失。
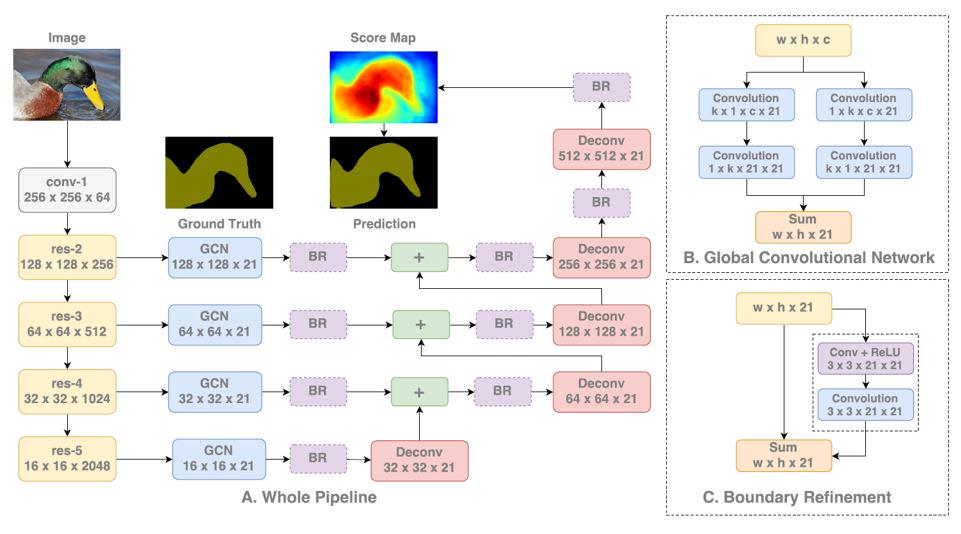
2. Global Convolutional Network(GCN)
为了解决感受野问题,GCN参考了FCN的网络结构,在每个池化层操作后,GCN使用了与特征图大小一致的卷积核进行全局卷积,并与经过反卷积的特征图融合。全局卷积操作在池化之前,扩大了模型的感受野,并借助FCN的思想,将全局感受野与反卷积结果融合,减少信息损失的同时,增强了分割结果图的细节信息。然而,FCN参数过多,训练较慢,GCN加入的大卷积操作会进一步增大计算量,影响模型的效率。
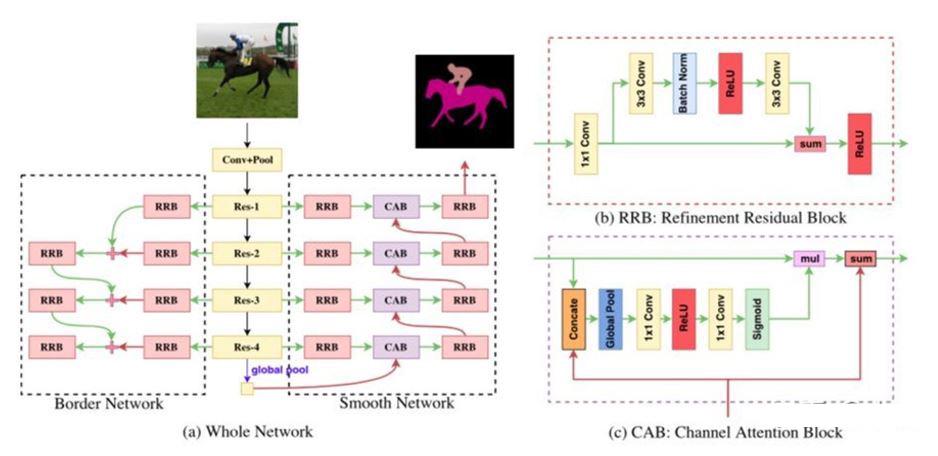
3. Discriminative Feature Network(DFN)
DFN主体框架是ResNet,主要包括两个子网络SmoothNetwork和BorderNetwork。SmoothNetwork网络负责解决类内不一致问题,即类内部出现一些噪音和错误。BorderNetwork网络用于判别类间差距,强化类别间判别效果。在SmoothNetwork网络中,使用了改进的Residual模块进行训练。BorderNetwork中加入了Attention模块,优化了各个通道的权重,提高了特征分类的准确性。对于网络训练,两个模块的loss同时计算,通过一个参数K调整其占的权重。
4. ExFuse架构
在之前的网络结构中,低级特征并不具有语义信息,而一般的模型直接将不具备语义信息的低级特征和经过多层卷积的高级语义特征进行融合,这种方式虽然在一定程度上考虑了低级特征,缺没有顾及到低级特征和高级特征融合时存在的特征不一致问题。ExFuse在结构上参考了U-net的编码-解码结构,在编码结构中,每层低级特征中引入多层语义监督(SS)模块,在编码前期使用辅助监督的方式完善低级特征。在特征融合模块,使用了高级语义嵌入(SEB)模块,将高层语义信息进行上采样并与低层特征图进行点乘融合,使得特征图既具有语义的同时,还具备低层特征的细节信息。在经过特征融合后,加入了GCN,提高感受野的同时嵌入更多的邻域信息。

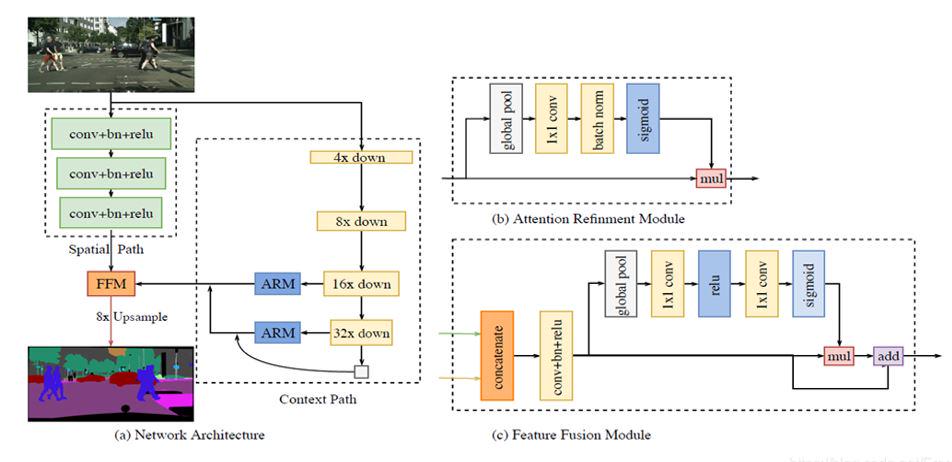
5. Bilateral Segmentation Network(BiseNet)
分割网络一直在探究低层特征和高层特征的融合问题。在BiseNet中,提取全局细节信息的Spatial Path的模块和提取语义信息的Context Path模块并不是通过简单的相加进行融合,而是通过一个Feature Fusion Module(FFM)模块整合后接入一个训练模型,让其进行自训练,从而达到融合效果。在特征融合后,同样引入了注意力机制。特别地,在Loss function中,Context Path的Loss是作为辅助判别函数来进行计算。
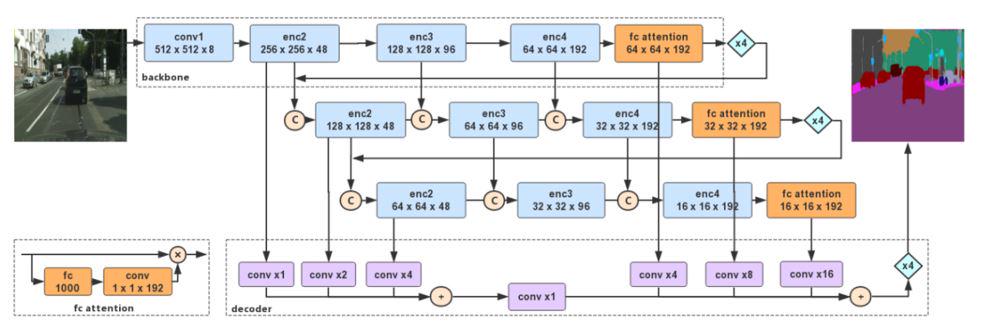
6. Deep Feature Aggregation Network(DFANet)
DFANet是一种轻量级网络结构,在Encode结构中,同样使用的深度可分离卷积网络减少卷积参数。整个DFANet的特征处理网络有两种方法:子网特征聚合和子阶段聚合。子网特征聚合负责将每个backbone(图中虚线框)输入到下一个backbone进行特征聚合。子阶段聚合负责将本阶段经上采样后高级语义特征和本阶段正常下采样的特征聚合(图中C字母部分)。为了维持模型的感受野, 在模型的fc-attention模块,使用的是分类模型的预训练参数。此操作的原因是分类数据集远远多于分割数据集,因此全连接参数训练得更为彻底。
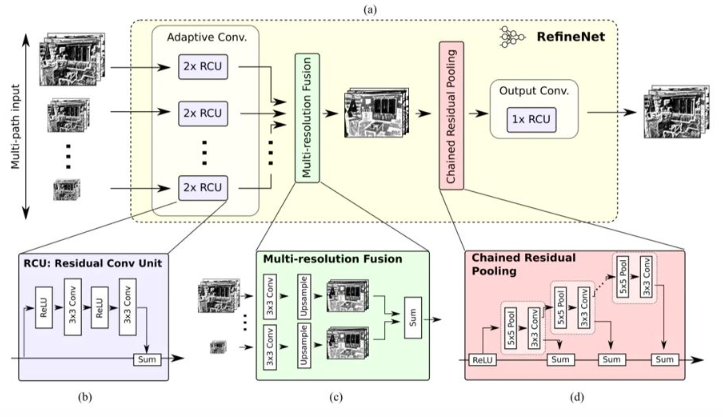
7. RefineNet
RefineNet在总体结构上延续了Unet的思路,但是在特征融合上并不是像U-net网络中直接将下采样的特征图和上采样后的语义特征图进行特征融合,而是使用了一个Refine模块进行处理。在RefineNet的下采样阶段使用了ResNet作为模型的框架,对于每次下采样后,都会有一个Refine模块进行特征融合处理。Refine模块总共包括三个子模块:第一个RCU模块用于预训练调整权重;MRF模块则是特征融合模块,主要作用是将经过预训练的特征图和上采样模块的特征进行融合。CRP模块是为了通过大池化窗口捕捉语义信息,最后通过一个RCU模型进行融合训练。
3. 总结
本篇主要讲了各种分割模型的优缺点,深度学习中每年会有模型的创新,但是在其思想上还是会有类似的地方,理解这些模型的内核思想,是了解深度学习模型,构建自己模型的重要方法。