select * from T where k between 3 and 5
这个语句的执行流程是:
- 在 k 索引树上找到 k=3 的记录,取得 ID = 300;
- 再到 ID 索引树查到 ID=300 对应的 R3;
- 在 k 索引树取下一个值 k=5,取得 ID=500.
- 再回到 ID 索引树查到 ID=500 对应的 R4;
- 在 k 索引树取下一个值 k=6,不满足条件,循环结束。
进行了两次回表,这是因为有些数据只在主键索引上存在。
索引覆盖
由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的 性能优化手段。
在一个市民信息表上,是否有必要将身份
证号和名字建立联合索引?
CREATE TABLE `tuser` (
`id` int(11) NOT NULL,
`id_card` varchar(32) DEFAULT NULL,
`name` varchar(32) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`ismale` tinyint(1) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `id_card` (`id_card`),
KEY `name_age` (`name`,`age`)
) ENGINE=InnoDB
如果说有一个需求时根据身份证号码查询他的名字,这个联合索引就有意义。查询这个联合索引就不需要进行回表。
最左前缀原则
创建name age 索引,索引项按照定义时的顺序排序。
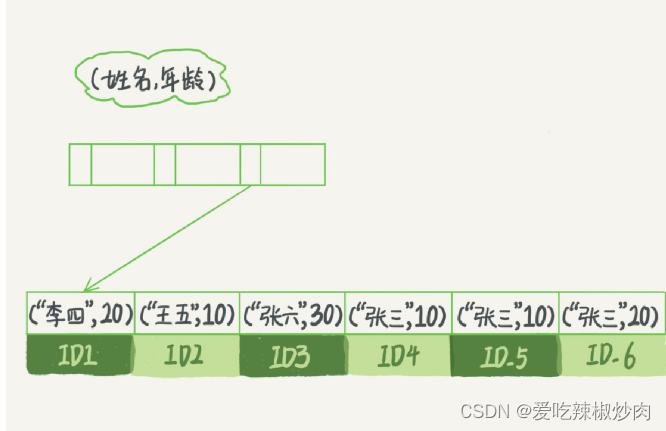
当你查询的 “张三” 时,快速定位到ID4然后从做往右寻找,
在MySQL5.6之前,如果查询那些不符合最左前缀的,会进行回表对比字段的值是否相等。
在5.6之后有索引下推的机制,在索引遍历时,对索引字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
总结:
- 使用覆盖索引是一种常见的优化手段。
- 尽量减少维护的索引数量。
- 索引下推:判断索引字段是否满足条件,减少回表的次数。