raft是工程上使用较为广泛的强一致性、去中心化、高可用的分布式协议。(类似的还有ZAB,GOSSIP)
大概理解一下,强一致性就是任意时刻客户端在不同机器读到的数据一致.注意跟最终一致性区别,比如数据库mysql的主从复制,主库写了再同步到从库,这个过程是异步的,主库写好就返回客户端结果,但是访问从库却会失败因为这时还没有同步完成.
去中心化就是每个节点的地位相同,因为分布式的特点就是每个机器地位相同,没有主从之分.
高可用就是只要大于一半的节点正常,就可以继续服务.
为什么分布式重要,因为一台机器的处理能力和内存是有上限的,且越好的价格更贵,相比于多台机器.多台机器就要维护不同节点的数据一致性.因为网络等问题会出现故障.分布式后,处理能力并发能力提高了,而且容错性也高了.
raft协议牺牲了A保留了CP. 就是牺牲了部分服务的可用性(必须同步之后才能访问数据),来达到数据一致性,容错性是分布式必须有的.
AP就是牺牲了强一致性.比如购物网站,购票网站,流量特别大,导致下单之后才发现库存没了.
raft比Paxos容易理解,所以才用在工程上.为了这个,raft做的工作有:
问题分解:共识算法分解成领导选举 日志复制 安全性三个子问题,作为三个类实现
状态简化:减少状态数量和变动. raft每个节点只有三种状态(某一时刻只有一种,不会向Paxos有并存状态和依赖),只有两类rpc方法.
复制状态机
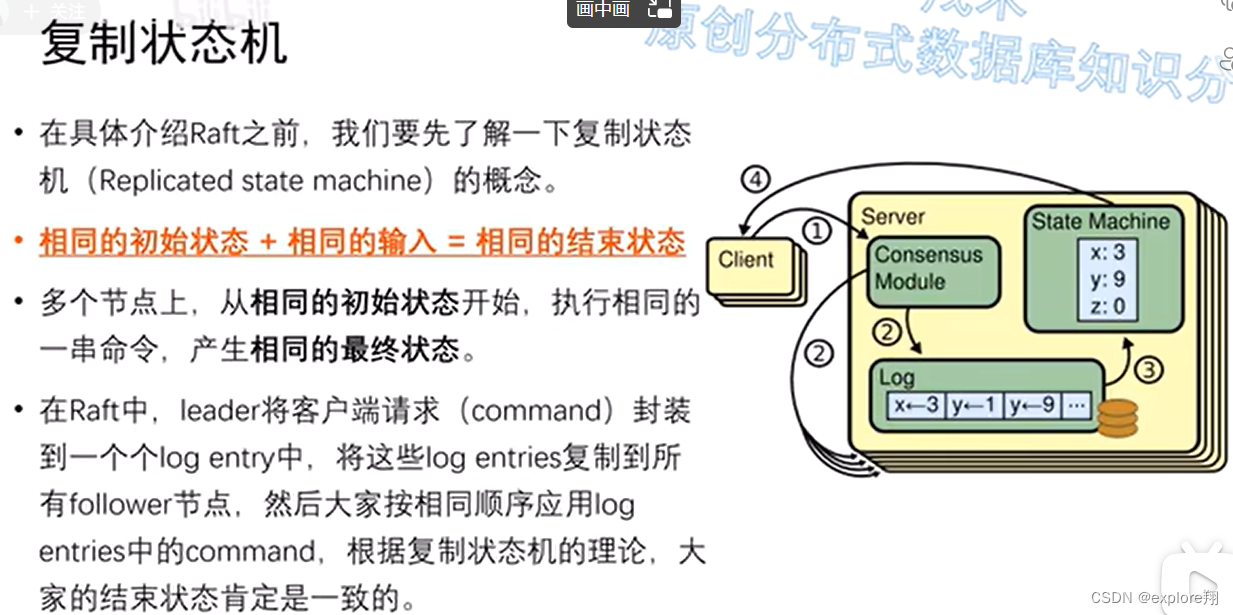
只是一个理论前提
状态简化
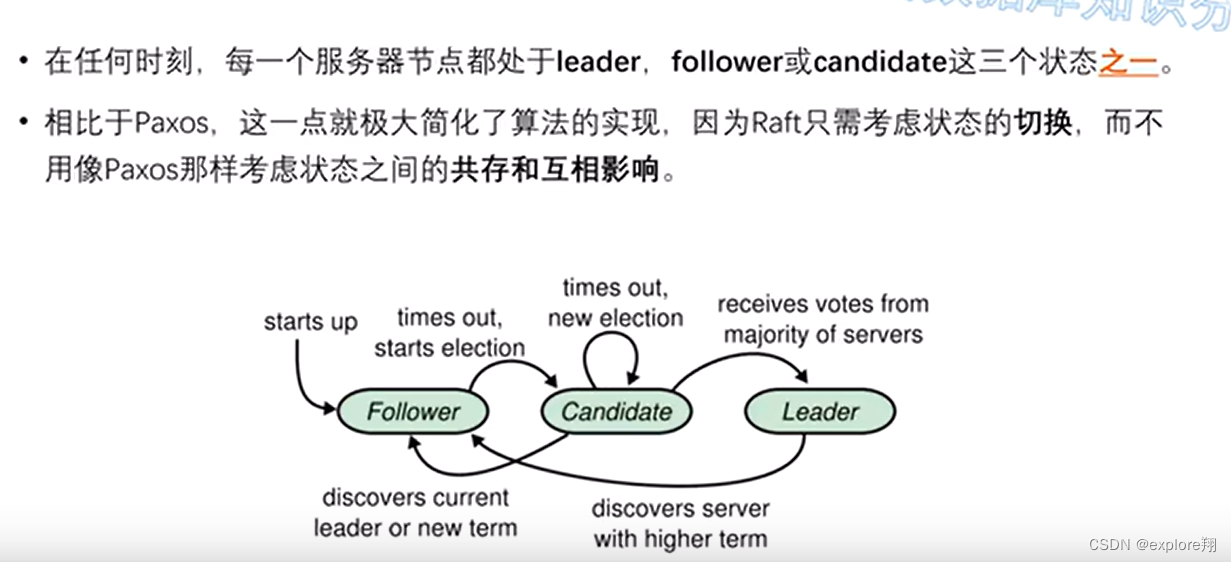
大致流程: 每个节点初始化是follower,如果发现Leader失效(心跳机制),就变成参与者,
如果票数过半竞选成功,就变成leader为客户端提供服务.
如果都没有成功,就再次选举;
如果失败,变成follower,会有新的leader来通知;
(很多细节后面再理解)
任期的概念:整数,一直递增,每次新选举一个leader任期加1;

这里可以看到任期的一个重要作用:任期可以比较. 比如请求投票时,如果请求节点A的任期号小于follower,那么follower会拒绝投票,并且竞选者会更新自己的任期号. leader会给不知道的同志发心跳, 包含任期,比较后同志修改自己的任期.
领导者选举
如果follwer一段时间没收到leader心跳,就会自己变成竞选者,做以下动作:
增加自己的任期号,变成竞选者,投票给自己,并发向其他节点请求投票;
它选举有三种结果:
1 成功选上,变成leader,给其他节点发心跳表明自己的地位;
2 没选上,收到其他节点的心跳,且该节点任期号大于等于自己的(一般是等于),变成follwer
3 一段时间后没有成功(过个竞选者,得票分散没超过半数).每个竞选者在随机超时时间后任期号加1,变成follower,进入下一个选举阶段.

这里注意,请求投票使会把自己最后一个日志号和最后一个日志的任期发送给follower.这一点后面再说
日志复制 最核心部分

客户端怎么知道新leader是哪个节点?
如果是新leader,就直接执行,如果是follower了,会有新leader的心跳信息包含其地址,发给客户端重定位,如果故障找下一个节点。
只有日志号和任期号才能唯一确定日志。(比如leader宕机后会出现日志号相同但是日志内容不同)
leader把收到的指令通过rpc并行发给其他人,让他们复制。**只有该条目被超过半数的人复制后,leader才会在本地执行该指令把结果返回客户端(提交)**对这一点理解很重要,这就是为什么是强一致性,放弃了可用性,因为有阻塞的过程,要等半数的人复制完才返回指令。
(这里有个疑问,只是半数的复制完成,如果在其他没复制完成的查询,结果不就不一致了吗?)
还有一个问题?是不是超过半数节点复制,leader一定会提交呢,不是,因为复制完成到follower通知leader,到leader提交, 是需要时间的,不是原子操作,如果这段时间leader宕机,就无法提交。这也是安全性的一个问题。
日志复制时follower,leader故障解决
1 follower缓慢
如果follower一直没有响应,那么leader会不断重发追加条目rpc,哪怕leader已经提交了,不能放弃任何一个follower,要保证所有节点一致;
2.follower宕机后恢复
这时raft会开始一致性检查,保证可以恢复崩溃后缺失的日志。(注意理解为什么崩溃后不能直接重发rpc呢,因为在崩溃期间,Leader可能已经换了好几个了,并且这个人恢复后状态也是未知的,可能丢失日志?。新的leader不知道这个人的宕机前日志复制的进度)
所谓的一致性检查,就是追加条目的rpc中会记录前一个日志的日志号和任期号,如果在他的日志中找不到前一个日志,就拒绝这个日志,leader重新发送前一个日志,逐渐定位到第一个缺失的日志。
(其实可以follower把最后一个日志的日志号和任期号发给leader不就好了,不需要一个个的找,这些不影响具体功能)
3.leader宕机
宕机后可能已经复制了部分日志到follower但是未提交,新选出的leader有可能也没有这些未提交的日志,在客户端来说没问题,没提交就是请求失败了。
但是一旦leader恢复后,他变成follower,就可能出现它的后面部分日志和新leader日志不同,那些复制了未提交日志的其他follower也会出现这种情况。
解决办法就是:强制follower复制leader的日志。通过一致性检查找到第一个一致的日志,把后面的日志覆盖掉。其实覆盖的都是未提交的日志,不会影响一致性。(还有问题就是会有数据丢失)
可以看到,这种机制,**导致leader当权后不需要复杂的操作,只需要一直rpc,日志就可以复制到一致状态,且leader永远不会覆盖或删除自己的日志。**很简洁。
**只要过半的服务器正常,就可以正常提供服务;
单个运行慢的follower不影响整体性能。**它慢慢自己追加就可以。
关于追加日志的rpc,需要更加详细了解一下:
除了leader当前任期号、id、前一个日志的任期号和日志号,日志体。还有一个leader已提交的日志号leader commit。意义在于:
对于follower来说,接收到leader日志,不会立即提交,因为要等到leader确认复制到大多数,并提交,再通过rpc通知follower已提交,也就是这个leader commit,然后follower才会提交。
对于追加日志回复rpc,只有任期号大于等于自己,通过了一致性检查,才返回true,否则返回false
安全性问题
对于一些故障情况,做了一些补充性的规则限制。
1、leader宕机: 选举限制
前面我们分析了,leader宕机后,最后几个日志可能复制到一些节点,但是另一些节点follower是有可能担任leader,这时候那些未被提交的日志永远不会补上,就丢失了,虽然后面leader通过覆盖可以让前面的日志保持一致,但是后面的日志肯定是丢失了。
这肯定不行,因为你明明保存了x=3,过半的节点也成功复制了这一点,提交之前,因为leader宕机,操作丢失了,岂不是有问题。虽然不是一致性的问题,因为返回失败,但是明明已经过半节点成功复制了。
解决办法就是选举限制:在竞选者发送请求投票的rpc中,有自己最后一个日志的任期号和日志号,如果follower发现自己的日志比它的还新,就拒绝投票。这保证了那些复制进度少的follower不会当选leader,复制最多的follower才有机会当选。这样的话,只要有一个节点复制了,后期这些信息都不会丢失,除非一个都没复制,leader就宕机了。
新的定义:先比较最后一个日志的任期,再比较日志号。(如果遗漏了整个任期,是不可能当选的)
2、leader宕机处理:新leader是否要提交之前任期内的日志条目
考虑一个问题:leader提交之后,要通过leadercommit(可以是心跳或下一个追加rpc)来通知follower提交,如果在这之前leader宕机,那么导致客户端成功返回,但是follower并没有提交这些条目,那么新leader是否要提交呢?
不会。**因为很可能出现已提交的日志被覆盖的情况。**leader宕机后,可能follower最后日志的任期更大,更新,覆盖已经提交的日志。
只有自己任期内的日志才会通过计算副本数目的方式(超过半数)来提交,因为自己的任期可以确保最大。
那么之前任期的日志怎么提交呢?其实很简单,新leader在自己任期提交一条日志后,leadercommit更新,大家自然就把之前的日志一起提交了。
(实际项目中,一个节点当选leader,可发送一个空的追加rpc,这样就把之前没提交的提交了,因为是空日志体,所以很快,这个方法叫no-op)
follower和candidate宕机处理
比较简单,就是通过一致性检查,然后无限重试发送rpc来同步。
时间可用性限制
raft不依赖时间,哪怕因为网络因素,后发的rpc先到,也不会影响正确性。怎么理解呢?比如追加rpc, x=1,x=2如果x=2先到follower,会因为rpc中有前一个日志的任期和日志号,如果没有,也就是x=1没有,是会拒绝这个日志的,一直等到x=1到了。
广播时间1ms级别<<选举超时时间100ms级别<<平均故障时间几个月左右
集群成员变更问题
在需要改变集群配置时,比如增减节点,替换宕机机器,改变复制程度等。
我们可以把集群停止再变更,这简单一点,但是必然要停止服务,而且手动操作存在风险,raft要满足自动化变更。
自动化变更最大的难点就是:在转换过程中会出现同一任期的两个leader。(脑裂问题)因为分布式场景下,不可能同一时间在所有机器上应用变更,天然限制。因为可能存在某个区间,集群被分为两个独立的大多数。
解决办法:两阶段
集群先切换到一个过渡的配置,成为联合一致
第一阶段,配置信息包装在追加rpc中,leader发起联合一致信息给follower。这时,所有rpc要在新旧两个配置中都达到大多数才算成功。
第二阶段,leader发起new,使集群进入新配置,这时,所有rpc只要在新配置达到大多数就算成功。
(配置日志和其他日志不同,配置日志只要复制了,就会使用,不需要提交)
为什么该方案可以保证不会出现多个 leader?我们来按流程逐阶段分析。
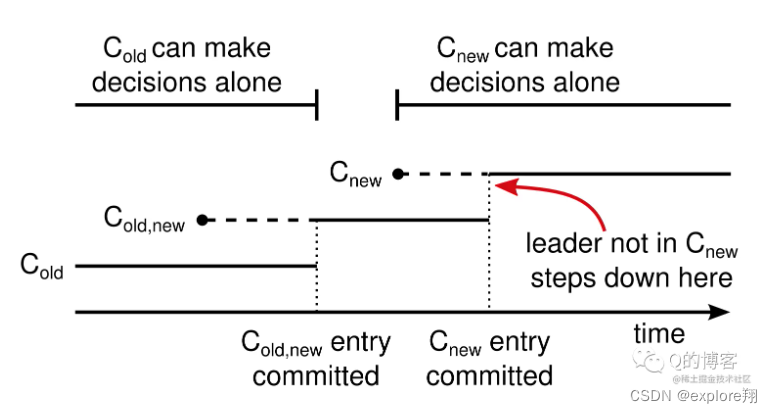
阶段1. C-old,new 尚未 commit
该阶段所有节点的配置要么是 C-old,要么是 C-old,new,但无论是二者哪种,只要原 leader 发生宕机,新 leader 都必须得到大多数 C-old 集合内节点的投票。
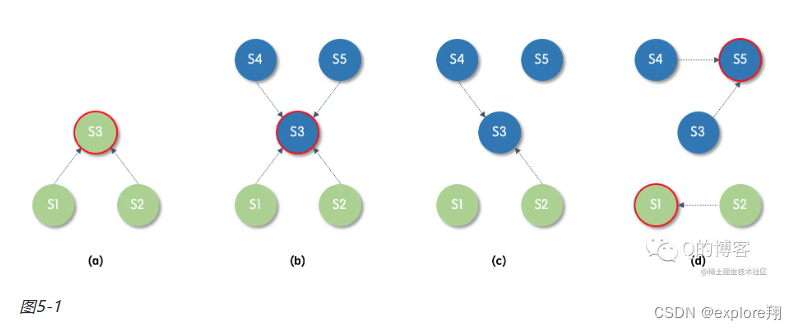
以图5-1场景为例,S5 在阶段d根本没有机会成为 leader,因为 C-old 中只有 S3 给它投票了,不满足大多数。
阶段2. C-old,new 已经 commit,C-new 尚未下发
该阶段 C-old,new 已经 commit,可以确保已经被 C-old,new 的大多数节点(再次强调:C-old 的大多数节点和 C-new 的大多数节点)复制。
因此当 leader 宕机时,新选出的 leader 一定是已经拥有 C-old,new 的节点,不可能出现两个 leader。
阶段3. C-new 已经下发但尚未 commit
该阶段集群中可能有三种节点 C-old、C-old,new、C-new,但由于已经经历了阶段2,因此 C-old 节点不可能再成为 leader。而无论是 C-old,new 还是 C-new 节点发起选举,都需要经过大多数 C-new 节点的同意,因此也不可能出现两个 leader。
阶段4. C-new 已经 commit
该阶段 C-new 已经被 commit,因此只有 C-new 节点可以得到大多数选票成为 leader。此时集群已经安全地完成了这轮变更,可以继续开启下一轮变更了。
其它方法,简单来说就是论证一次只变更一个节点的的正确性,并给出解决可用性问题的优化方案。
Raft 提供了一种机制去清除日志里积累的陈旧信息,叫做日志压缩。
快照(Snapshot)是一种常用的、简单的日志压缩方式,ZooKeeper、Chubby 等系统都在用。简单来说,就是将某一时刻系统的状态 dump 下来并落地存储,这样该时刻之前的所有日志就都可以丢弃了。注意,在 Raft 中我们只能为 committed 日志做 snapshot,因为只有 committed 日志才是确保最终会应用到状态机的。
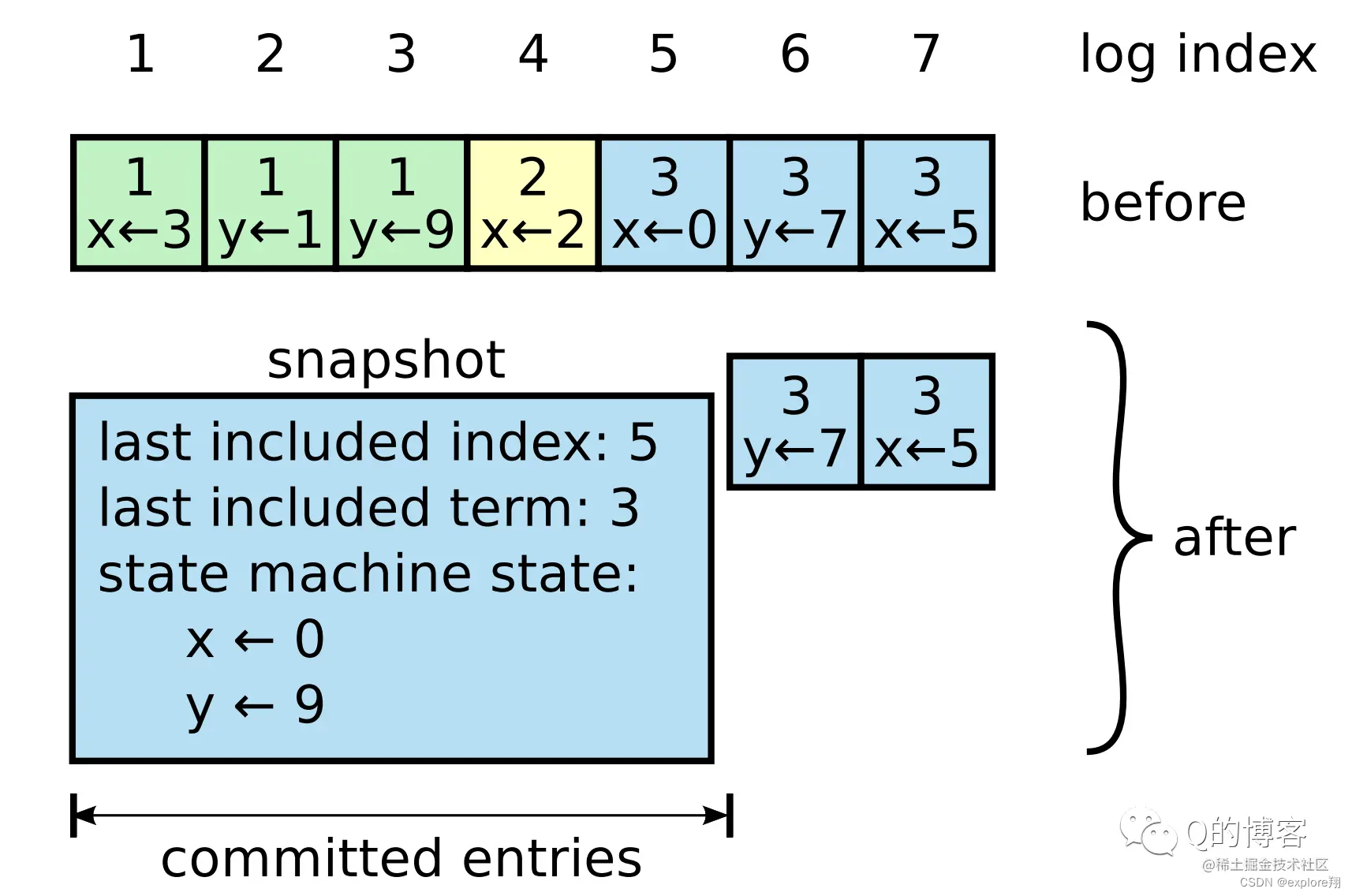
快照一般包含以下内容:
日志的元数据:最后一条被该快照 apply 的日志 term 及 index
状态机:前边全部日志 apply 后最终得到的状态机
当 leader 需要给某个 follower 同步一些旧日志,但这些日志已经被 leader 做了快照并删除掉了时,leader 就需要把该快照发送给 follower。
同样,当集群中有新节点加入,或者某个节点宕机太久落后了太多日志时,leader 也可以直接发送快照,大量节约日志传输和回放时间。
同步快照使用一个新的 RPC 方法,叫做 InstallSnapshot RPC。
线性一致性与读性能优化
对于调用时间存在重叠(并发)的请求,生效顺序可以任意确定。
对于调用时间存在先后关系(偏序)的请求**,后一个请求不能违背前一个请求确定的结果**。
使用了 Raft 的系统都是线性一致的吗?不是的,Raft 只是提供了一个基础,要实现整个系统的线性一致还需要做一些额外的工作。
写主读从缺陷分析
真正关键的点在于读操作的处理方式,这涉及到整个系统关于一致性方面的取舍。
在该方案中我们假设读操作直接简单地向 follower 发起,那么由于 Raft 的 Quorum 机制(大部分节点成功即可),针对某个提案在某一时间段内,集群可能会有以下两种状态:
某次写操作的日志尚未被复制到一少部分 follower,但 leader 已经将其 commit。
某次写操作的日志已经被同步到所有 follower,但 leader 将其 commit 后,心跳包尚未通知到一部分 follower。
以上每个场景客户端都可能读到过时的数据,整个系统显然是不满足线性一致的。
写主读主缺陷分析
在该方案中我们限定,所有的读操作也必须经由 leader 节点处理,读写都经过 leader 难道还不能满足线性一致?是的!! 并且该方案存在不止一个问题!!
问题一:状态机落后于 committed log 导致脏读
一个提案只要被 leader commit 就可以响应客户端了,Raft 并没有限定提案结果在返回给客户端前必须先应用到状态机。所以从客户端视角当我们的某个写操作执行成功后,下一次读操作可能还是会读到旧值。
这个问题的解决方式很简单,在 leader 收到读命令时我们只需记录下当前的 commit index,当 apply index 追上该 commit index 时,即可将状态机中的内容响应给客户端。
问题二:网络分区导致脏读
假设集群发生网络分区,旧 leader 位于少数派分区中,而且此刻旧 leader 刚好还未发现自己已经失去了领导权,当多数派分区选出了新的 leader 并开始进行后续写操作时,连接到旧 leader 的客户端可能就会读到旧值了。
因此,仅仅是直接读 leader 状态机的话,系统仍然不满足线性一致性
Raft Log Read
我们可以将读请求同样作为一个提案走一遍 Raft 流程,当这次读请求对应的日志可以被应用到状态机时,leader 就可以读状态机并返回给用户了。为什么这种方案满足线性一致?因为该方案根据 commit index 对所有读写请求都一起做了线性化,这样每个读请求都能感知到状态机在执行完前一写请求后的最新状态,将读写日志一条一条的应用到状态机,整个系统当然满足线性一致。但该方案的缺点也非常明显,那就是性能差,读操作的开销与写操作几乎完全一致。而且由于所有操作都线性化了,我们无法并发读状态机。
Raft 读性能优化
接下来我们将介绍几种优化方案,它们在不违背系统线性一致性的前提下,大幅提升了读性能。
6.3.1 Read Index
其大致流程为:
Leader 在收到客户端读请求时,记录下当前的 commit index,称之为 read index。
Leader 向 followers 发起一次心跳包,这一步是为了确保领导权,避免网络分区时少数派 leader 仍处理请求。
等待状态机至少应用到 read index(即 apply index 大于等于 read index)。
执行读请求,将状态机中的结果返回给客户端。
这里第三步的 apply index 大于等于 read index 是一个关键点。因为在该读请求发起时,我们将当时的 commit index 记录了下来,只要使客户端读到的内容在该 commit index 之后,那么结果一定都满足线性一致
Lease Read
与 Read Index 相比,Lease Read 进一步省去了网络交互开销,因此更能显著降低读的时延。
基本思路是 leader 设置一个比选举超时(Election Timeout)更短的时间作为租期,在租期内我们可以相信其它节点一定没有发起选举,集群也就一定不会存在脑裂,所以在这个时间段内我们直接读主即可,而非该时间段内可以继续走 Read Index 流程,Read Index 的心跳包也可以为租期带来更新。
Follower Read
这里我们给出一个可行的读 follower 方案:Follower 在收到客户端的读请求时,向 leader 询问当前最新的 commit index,反正所有日志条目最终一定会被同步到自己身上,follower 只需等待该日志被自己 commit 并 apply 到状态机后,返回给客户端本地状态机的结果即可。这个方案叫做 Follower Read。
注意:Follower Read 并不意味着我们在读过程中完全不依赖 leader 了,在保证线性一致性的前提下完全不依赖 leader 理论上是不可能做到的。
![buu [INSHack2017]rsa16m 1](https://img-blog.csdnimg.cn/ae2a5bb09fc84278995374e53e363f9b.png)