文章目录
- 题目描述
- 题目链接
- 题目难度——中等
- 方法一:哈希表
- 代码/Python
- 代码/C++
- 总结
题目描述
给你一个长度为 n 的字符串数组 names 。你将会在文件系统中创建 n 个文件夹:在第 i 分钟,新建名为 names[i] 的文件夹。
由于两个文件 不能 共享相同的文件名,因此如果新建文件夹使用的文件名已经被占用,系统会以 (k) 的形式为新文件夹的文件名添加后缀,其中 k 是能保证文件名唯一的 最小正整数 。
返回长度为 n 的字符串数组,其中 ans[i] 是创建第 i 个文件夹时系统分配给该文件夹的实际名称。
示例 1:
输入:names = ["pes","fifa","gta","pes(2019)"]
输出:["pes","fifa","gta","pes(2019)"]
解释:文件系统将会这样创建文件名:
"pes" --> 之前未分配,仍为 "pes"
"fifa" --> 之前未分配,仍为 "fifa"
"gta" --> 之前未分配,仍为 "gta"
"pes(2019)" --> 之前未分配,仍为 "pes(2019)"
示例 2:
输入:names = ["gta","gta(1)","gta","avalon"]
输出:["gta","gta(1)","gta(2)","avalon"]
解释:文件系统将会这样创建文件名:
"gta" --> 之前未分配,仍为 "gta"
"gta(1)" --> 之前未分配,仍为 "gta(1)"
"gta" --> 文件名被占用,系统为该名称添加后缀 (k),由于 "gta(1)" 也被占用,所以 k = 2 。实际创建的文件名为 "gta(2)" 。
"avalon" --> 之前未分配,仍为 "avalon"
示例 3:
输入:names = ["onepiece","onepiece(1)","onepiece(2)","onepiece(3)","onepiece"]
输出:["onepiece","onepiece(1)","onepiece(2)","onepiece(3)","onepiece(4)"]
解释:当创建最后一个文件夹时,最小的正有效 k 为 4 ,文件名变为 "onepiece(4)"。
示例 4:
输入:names = ["wano","wano","wano","wano"]
输出:["wano","wano(1)","wano(2)","wano(3)"]
解释:每次创建文件夹 "wano" 时,只需增加后缀中 k 的值即可。
示例 5:
输入:names = ["kaido","kaido(1)","kaido","kaido(1)"]
输出:["kaido","kaido(1)","kaido(2)","kaido(1)(1)"]
解释:注意,如果含后缀文件名被占用,那么系统也会按规则在名称后添加新的后缀 (k) 。
提示:
- 1 <= names.length <= 5 * 10^4
- 1 <= names[i].length <= 20
- names[i] 由小写英文字母、数字和/或圆括号组成。
题目链接
题目难度——中等
方法一:哈希表
我们需要一个哈希表seen来记录每个文件名的出现次数,同时以这个出现次数作为我们获取答案的依据之一。
代码/Python
class Solution:
def getFolderNames(self, names):
used_names = {}
result = []
for name in names:
if name not in used_names:
# 如果名称没有被占用,直接使用
used_names[name] = 1
result.append(name)
else:
# 如果名称被占用,就把出现次数++
k = used_names[name]
while f"{name}({k})" in used_names:
k += 1
used_names[f"{name}({k})"] = 1
result.append(f"{name}({k})")
used_names[name] = k + 1 # 下一次要判断的
return result
代码/C++
class Solution {
public:
vector<string> getFolderNames(vector<string>& names) {
map<string, int> seen;
vector<string> res;
for(auto name: names){
// seen.count返回出现次数,find返回指向元素的迭代器
if(!seen.count(name)){
res.push_back(name);
seen[name] = 1;
}
else{
int k = seen[name];
while(seen.count(name + "(" + to_string(k) + ")")){
k++;
}
string t = name + "(" + to_string(k) + ")";
seen[t] = 1;
res.push_back(t);
seen[name] = k + 1;
}
}
return res;
}
};
上面的代码还可以写得更简单一些,直接用一个while来代替if-else,以python为例:
class Solution:
def getFolderNames(self, names):
seen = dict()
res = []
for name in names:
n = name
while n in seen:
n = f'{name}({seen[name]})'
seen[name] += 1
seen[n] = 1
res.append(n)
return res
总结
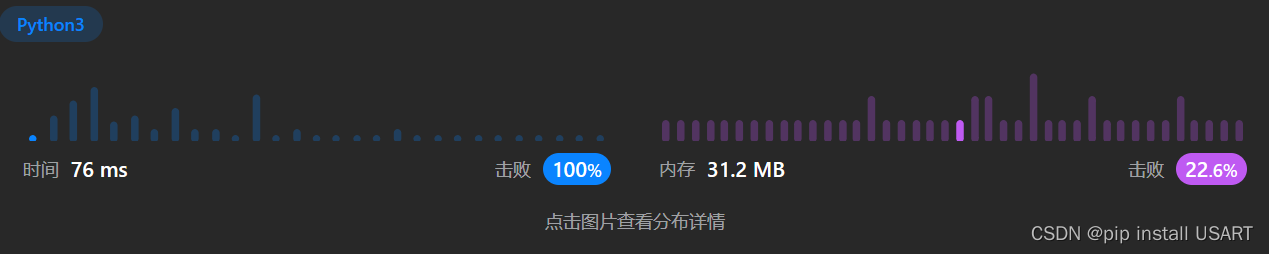
方法一时间复杂度应该是O(N)级的,空间复杂度O(N)。