能量模型(Energy-based model)是一种以自监督方式执行的生成式模型,近年来受到了很多关注。本文将介绍ScoreGrad:基于连续能量生成模型的多变量概率时间序列预测。如果你对时间序列预测感兴趣,推荐继续阅读本文。
为什么时间序列预测很重要?
这是一个老生常谈的问题,因为时间序列预测在各个行业都有广泛的用例,从金融到能源,从医疗保健到农业等。
与其他人工智能领域(如计算机视觉)相比,时间序列具有挑战性的是高度的不确定性及其长/短依赖性等。也就是说,即使使用最先进的数学算法,就目前来说,你也不可能预测下个月比特币的价值,因为除了时间序列本身,还有很多外在因素。但是在众多应用中,深度学习模型被广泛用于预测未来,例如预测能源消耗,就能源来说,影响的因素较小,我们倒是可以对其进行研究。
为什么生成模型是人们关注的焦点?
生成模型是一种新的类型的深度学习模型,随着新一波有创意和有前途的初创企业在经济中获得越来越多的关注。生成模型中最受欢迎和流行的例子是著名的ChatGPT,它在最近几个月里征服了数百万人。
生成模型的机制可能听起来很复杂,本文也无法详细说明,但是一般来说生成模型能够生成新的数据(这是废话😒)。但这些数据可以是任何类型的数据,从图像到文本,当然也包括数字。
生成模型是如何工作的?
一句话总结生成数据的机制:他们通过学习训练数据中的统计模式来生成新的数据样本,然后使用这些知识随机创建新的、相似的样本。
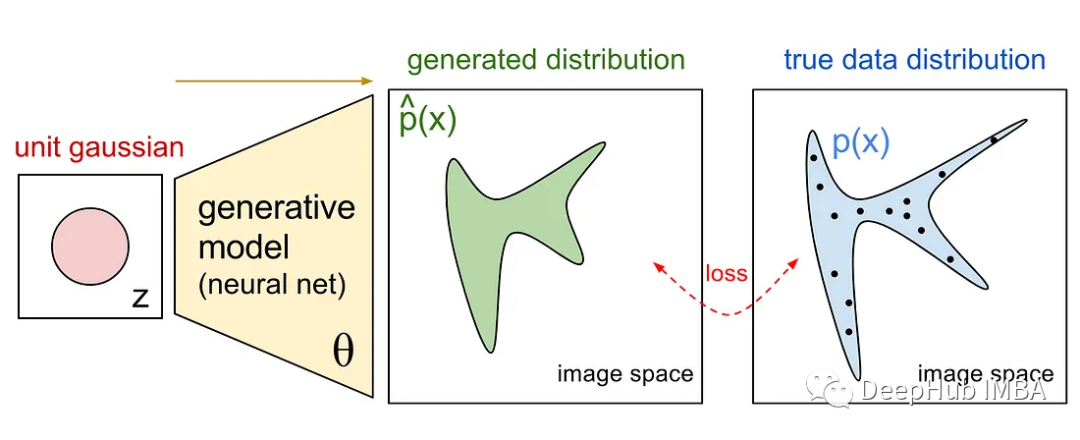
生成式模型试图生成尽可能接近真实数据分布的分布。
下面开始进入我们的正题
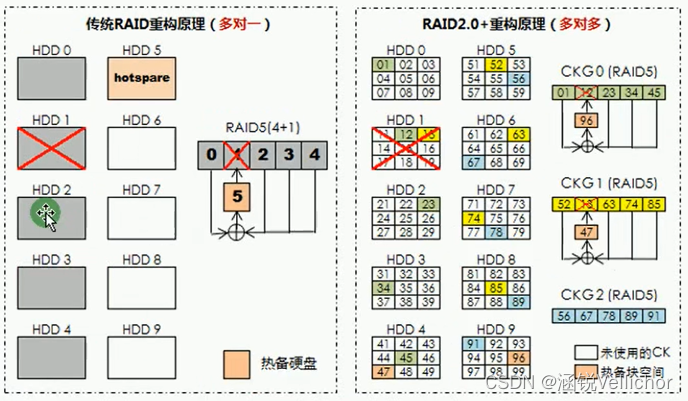
ScoreGrad是如何运作的?
ScoreGrad是一个用于预测时间序列数据的框架,使用复杂的数学和连续的基于能量的生成模型。它由两部分组成:一个特征提取模块,用于从数据中挑选出重要的部分;一个分数匹配模块,使用一种叫做随机微分方程的东西,通过回溯时间来进行预测。它的工作方式是通过在迭代循环中求解逆时SDE。
1、训练
通过输入多变量时间序列数据来训练模型,以最小化损失函数(如下所示):

训练过程是下面的算法1的伪代码:

2、预测
把预测看作是反向连续时间SDE抽样的迭代。
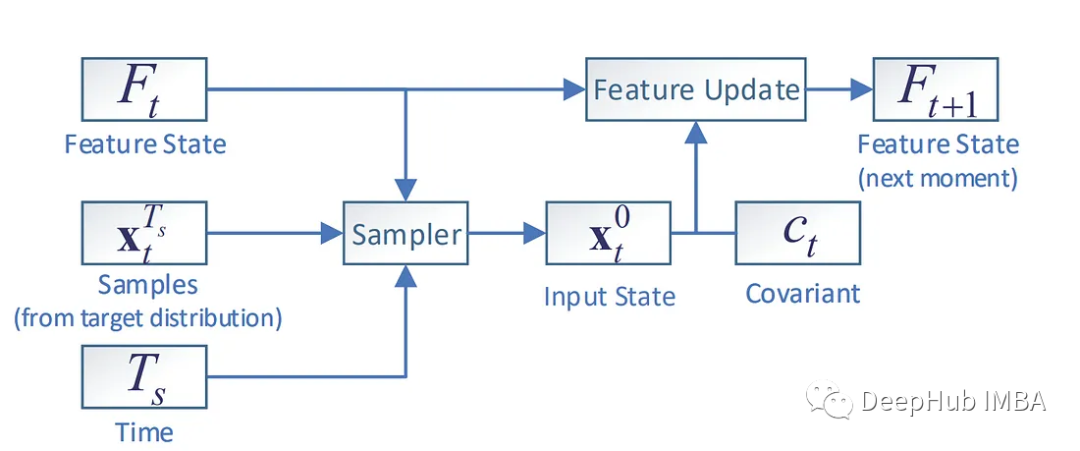
从预定分布中获取样本。将特征状态、样本和相应时间提供给试图解决反向SDE的采样器,这样就可以得到预测。
然后将预测(采样器的输出)、协变量和特征状态提供给一个名为时间序列的特征抽取模块,将其用于下一个预测。

ScoreGrad的架构
下图看着有很多的模块,并且很乱,别担心,下面会慢慢解释。😉
(a)时间步t的模型架构

(b)分数匹配模块架构

(1)符号和问题表述

应该注意的是,一直都有协变量的值。迭代预测的方式可以在下面公式2中表述:

(2)模型架构
该框架在每个时间步上都由两个模块组成;首先是时间序列的特征提取(TS),然后是基于条件SDE的分数匹配模块。
先介绍第一个模块“TS特征提取”:想要得到之前值的一个特殊特征;每个时间步中我们称它为Ft,因为要对所有时间步都这样做,所以需要更新它就需要定义了一个函数(R):
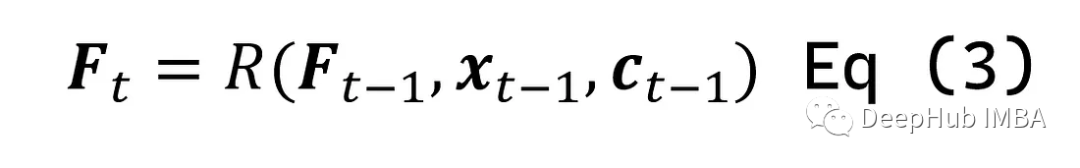
可以很容易地将Eq(2)转换为Eq(4),这是一个条件预测公式:
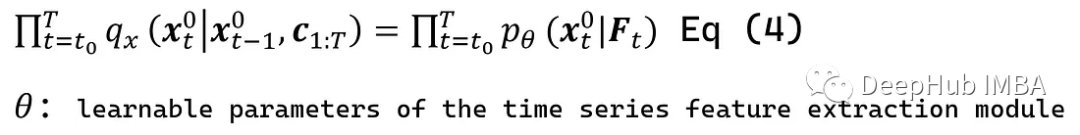
这里的Ft可以等价于rnn中的隐藏状态,TCN或基于注意力的模型中学习特征的向量表示。缺省情况下,ScoreGrad使用rnn。
下面就是基于条件SDE的分数匹配模块:为了调节SDE,使用Ft,如架构图中的分数匹配模块所示,将其输入到全连接的上采样器中,然后向上采样,这种操作发生在每个时间步,所以我们可以简单地使用时间t的对应状态。如果ts是积分时间,那么就有:

上面的公式是修正的条件逆时SDE。如果我们知道这个分数函数在所有时间步长的值,就可以用数值SDE求解器进行反转。那么这个分数函数是什么呢?是一个神经网络。
(3)条件分数网络
这部分受到两个论文的启发:1.WaveNet 2.DiffWave;有兴趣的可以去看看,这里就不多解释了
网络有三个输入:
- 特征(Ft )
- 输入状态(xt)
- 对应时间(ts)
用Conv1D (filter size= 1,3)改变输入状态,并将嵌入模块(对应时间)从位置嵌入改变为随机傅里叶特征。这里Ft (Feature)是评分网络的调节器。将隐藏表示+时间嵌入传递给卷积算子;然后添加输出并进行激活操作。
通过使用输出的一部分作为块的输出,其余部分用跳过连接输入求和到下一个块。最后将所有输出加在一起,并对最终输出进行简单的卷积变换。
语言描述有点复杂,可以根据ScoreGrad的架构图的分数匹配模块架构对应查看应该会更好的理解。
结果
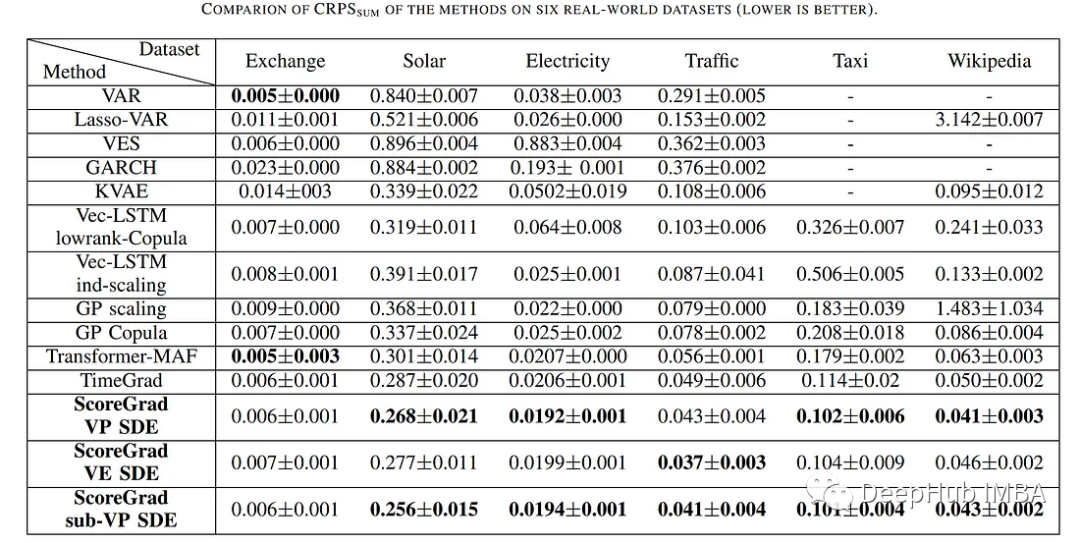
这部分是研究中最重要的部分;因为这是表明模型有效的一部分。这里提到了与其他以前的模型进行比较的结果。
该模型在包括Exchange、太阳能、电力、交通、出租车和维基百科在内的各个行业的各种基准数据集上进行评估。
这里的区别点是他们使用了一个名为“连续排名概率分数(CRPS)”的分数,如下所示:
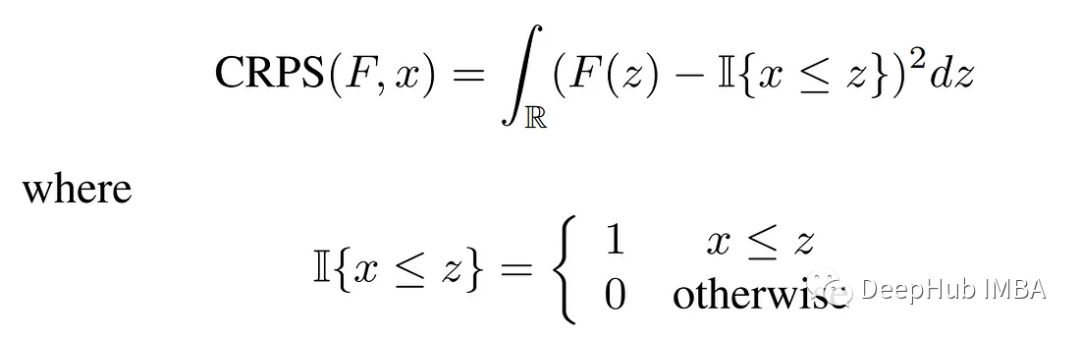
使用这个分数来计算累积分布函数(CDF)F与真实值x的相容程度。然后通过计算每个时间步的CROS,可以计算CRPS_sum:
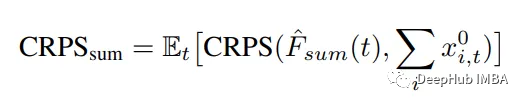
然后就得到了下面的结果:
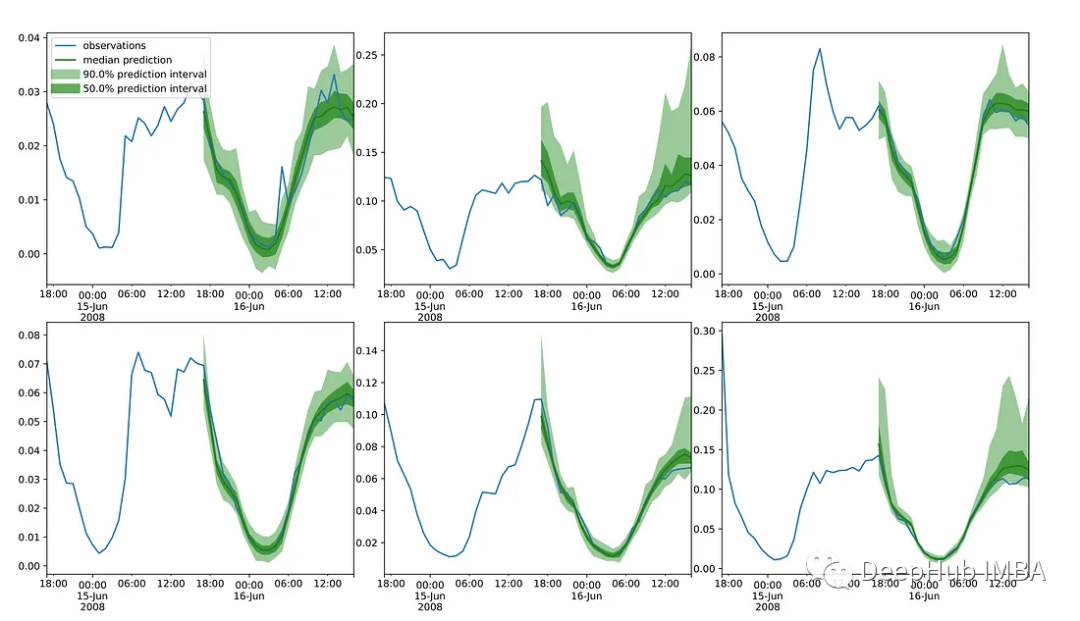
基于VP SDE和交通数据集实际观察的ScoreGrad预测区间。
论文地址:https://avoid.overfit.cn/post/7dc6c0db14cc4e919bc4dbb8d342b0e0
作者:Reza Yazdanfar