给一张测试图,对测试图分别cpu和GPU进行处理,进行时间统计,最后做展示。
环境:win10 + cuda11.3 +python3.7 + numba 等
硬件:cpu:i59400 ,gpu:RTX1650 4G
首先进行cuda安装,cuDNN等的安装,参考该博客https://blog.csdn.net/xiao_yun_zi/article/details/124046964?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522167774321216800180677939%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=167774321216800180677939&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v1~pc_rank_34-1-124046964-null-null.142v73pc_new_rank,201v4add_ask,239v2insert_chatgpt&utm_term=%E6%B8%85%E5%8D%8E%E6%BA%90%E9%95%9C%E5%83%8F%E5%AE%89%E8%A3%85cuda11.3&spm=1018.2226.3001.4187
安装成功后,可以看到自己GPU的信息,大小,传输带宽等

python GPU编程示例如下:
import cv2
import time
import numpy as np
import math
from numba import cuda
@cuda.jit
def process_gpu(img_gpu, channels):
tx = cuda.blockIdx.x*cuda.blockDim.x + cuda.threadIdx.x
ty = cuda.blockIdx.y*cuda.blockDim.y + cuda.threadIdx.y
for c in range(channels):
color = img_gpu[tx, ty][c]*2 +30
if color > 255:
img_gpu[tx, ty][c] = 255
elif color < 255:
img_gpu[tx, ty][c] = 0
else:
img_gpu[tx, ty][c] = color
def process_cpu(img_cpu, dst_cpu):
rows, cols, channels = img_cpu.shape
for j in range(cols):
for i in range(rows):
for c in range(channels):
color = img[i, j][c]*2 + 30
if color > 255:
dst_cpu[i, j][c] = 255
elif color < 0:
dst_cpu[i, j][c] = 0
else:
dst_cpu[i, j][c] = color
if __name__ == '__main__':
img = cv2.imread("test.jpg")
cv2.namedWindow("test", 1)
try:
cv2.imshow("test", img)
except:
print("load failed")
rows, cols, channels = img.shape
img_cpu = img.copy()
dst_cpu = img.copy()
start_cpu = time.time()
process_cpu(img_cpu, dst_cpu)
end_cpu = time.time()
print("cpu_time:",str(end_cpu-start_cpu))
cv2.imshow("cpu_photo", dst_cpu)
############### gpu process #########
img_gpu = cuda.to_device(img)
threadperblock = (32, 32)
blockpergrid_x = int(math.ceil(rows/threadperblock[0]))
blockpergrid_y = int(math.ceil(cols/threadperblock[1]))
blockpergrid = (blockpergrid_x, blockpergrid_x)
cuda.syncthreads
start_gpu = time.time()
process_gpu[blockpergrid, threadperblock](img_gpu, channels)
cuda.syncthreads
end_gpu = time.time()
print("gpu_time: ", str(end_gpu-start_gpu))
dst_gpu = img_gpu.copy_to_host()
cv2.imshow("img_gpu", dst_gpu)
cv2.waitKey(0)
cv2.destroyWindow("test")
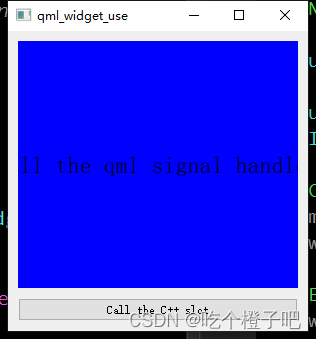
运行结果展示:


通过结果可以看出,cuda编程加速很多,同时发现GPU得到的图片比cpu得到的图片失真很多。暂时,不知道原因,等待继续研究。
编程时遇到编译问题:numba.cuda.cudadrv.error.NvvmError: Failed to compile
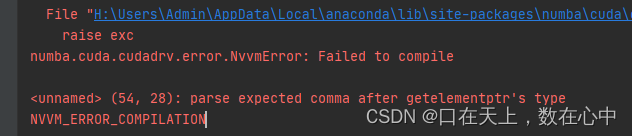
**有校解决办法是用conda 安装numba ,**若用conda 安装遇到如下错误:
Preparing transaction: done
Verifying transaction: failed
RemoveError: 'requests' is a dependency of conda and cannot be removed from
conda's operating environment.
请先将conda 升级。强制升级命令为conda update --force conda


![[Java基础]—JDBC](https://img-blog.csdnimg.cn/09c5eafae5a04af08542e67ebeb8a613.png#pic_center)