作者:皮皮雷 来源:投稿
编辑:学姐
论文题目
How Effective is Task-Agnostic Data Augmentation for Pretrained Transformers?
论文作者
S. Longpre, Y. Wang, and C. DuBois
论文发表于
2020 EMNLP findings

摘要
任务无关的数据增广(DA)在NLP中运用广泛,尤其是在数据稀少的情况下、或者在下游任务中接非预训练模型(如LSTM,CNN)效果显著。有时候,下游任务接预训练语言模型(如BERT)也会有所提升。
论文提出的问题是:
当DA运用在预训练语言模型上,到底有多少效果?
论文使用两种常规的数据增广方法:
Easy Data Augmentation (EDA) (Wei and Zou, 2019) 和回译(Sennrich et al., 2015),在6个数据集、5种分类任务(情感分类SST2,RT、主观性SUBJ、问题类型TREC、句子相似STS-B、推理MNLI)、3个预训练语言模型(BERT, XL-NET, and ROBERTA)上比较DA的效果。
结果发现,尽管前人实验证实DA方法在非预训练语言模型上效果显著,但是不适用于预训练语言模型,哪怕是在数据稀少的情况下。
结论
在用PLM做文本分类时,增广手段不能起到提升作用。推测是因为PLM在预训练过程中已经拥有较多的语言知识(无需再次增强)。

数据集
·情感分类 SST2, RT
·主观性 SUBJ
·问题分类 TREC
·句子相似 STS-B
·推理 MNLI
用于测试的数据: 在这些数据集的测试集中随机抽取1000条。
训练数据大小: N ∈ {500, 1000, 2000, 3000, Full},以模拟在数据稀疏情况下的表现
数据增广方法
1.Back Translation (回译) : 英语 → 德语
英语1句的德语翻译,再翻回6句不同的英语,取6句话中与原文编辑距离最长的。
目的:最大限度增加语言的丰富程度(linguistic variety)
2.Easy Data Augmentation (EDA) 包括同义词替换、随机交换词语顺序、随机插入和删除词语
变量:数据增广的总量,设置参数τ ∈ {0.5, 1, 1.5, 2}. N ×τ 是增广的数据量。
模型
研究者测试了3种预训练语言模型在数据增广下的表现。
BERT-BASE
XLNET-BASE
ROBERTA-BASE
实验
先调参:对于每一种数据增广策略(不增广、回译、EDA)分别调参,采用30次随机搜索方法调参,确保模型发挥较好的效果。
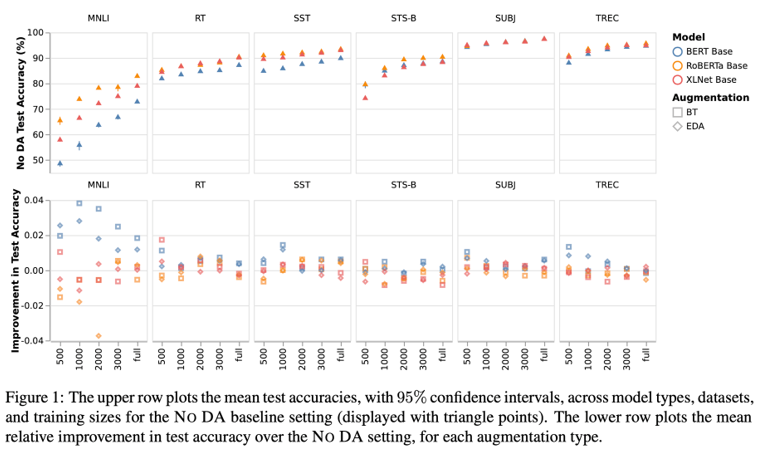
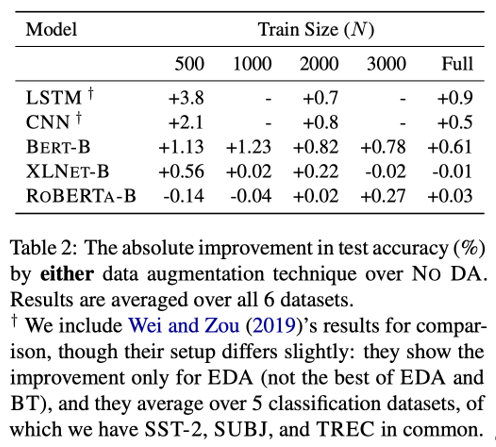
实验数据发现数据增广的方法收效甚微。研究者接下来讨论产生这种情况的原因。
讨论:为什么数据增广的策略没有效果?
现象1:数据增广对BERT的增益比另外两个模型大。而且BERT的预训练数据量相对了另外两个模型小。所以推测预训练过程达到了和数据增广相似的效果。
研究者建议:数据增广可以增加任务相关语料的语言学丰富度,尤其是当预训练不足够的时候。
现象2:RT情感分类数据集中,少见的、别出心裁的表达构成了很多难例(如“wishy-washy”),模型较难归纳出这些词所属的情感类别。在这些难例上,预训练模型做对了,而LSTM没做对。
这些结果表明数据增广和预训练都提高了模型处理复杂语言结构、歧义词和标签类别中未出现的词语的能力。
评价
在竞赛中,我们常常看到数据增广的方法能够提分,而且提分不少,因此数据增广被当做一个有口皆碑的刷分利器。而这篇Apple公司的论文正是关注数据增广在预训练模型上的表现,做了一系列的实验,结果却和我们以前的认知大相径庭。
这是为什么呢?在读的过程中我也意识到了一些问题。比如,分类效果没有提升,是因为总数据量的增加导致的?还是数据增广方法的应用导致的?如果把这个变量分离出来做比较,可能会更有说服力一些。
而且,在我们的经验中,数据增广方法在一些数据集上有神奇的效果、在另一些上没有,这也是符合“no free lunch”定律的:天下没有一种普适的模型和算法能一下找到所有问题的最优解。
不过这篇论文的优点在于提出的问题非常基础、有建设性。相信里面有更多的东西有待挖掘,比如,数据增广方法能够奏效的数据集,它们本身有什么特点?而数据增广收效甚微的数据集又有什么特点?这些都是这篇文章引出的问题和思考。
论文链接:
https://arxiv.org/abs/2010.01764
关注下方《学姐带你玩AI》🚀🚀🚀
回复“ACL”领取NLP顶会600多篇经典论文
码字不易,欢迎大家点赞评论收藏!