前言
在上一篇,我们对es进行了深入讲解,相信看过的小伙伴已经能基本掌握es的使用方法,我们知道,es主要针对的是搜索条件,在这方面es具有无可比拟的优势,但我们也会注意到,有时候搜索条件过于宽泛的时候,搜索结果集也将是非常庞大的,不仅服务器接口压力大,用户等的也很为难,为了解决这一问题,必须要对返回的数据进行处理,此时,分页就出现了,接下来,博主讲带两大家了解查询时的分页问题,并解决这个问题。
什么是分页查询
如上所述,分页查询是在返回数据量比较庞大时,为了能提高用户的体验,减少等待时间,而产生的一种数据分段方式,体现在展示层上就是数据的上拉加载,我们经常可以在购物类app上见到这样的设定,大多数情况下我们一页数据都为10条,大概是10条基本能满足查看一屏的需求和减少用户的等待时间的缘故,这是在移动端,在pc上可能略有不同,但基本都会以10的倍数存在。这便是分页查询。
分页查询的优点
分页查询的有点其实在上文中都已经说明,此处做一个总结,主要体现在三点上:
服务器
一次性查询所有信息,服务器压力过大,分页查询则可以降低服务器压力。
客户端
一次性显示所有信息,需要更多流量,加载更久,分页显示则可以解决这个问题。
用户体验
良好的用户体验可以让用户在应用上花费更多的时间,才能够提高购买率,也是服务商所希望的。最重要的一点,用户才不会放弃当前使用的应用。而且一般查询的数据都是会排序的,所以有价值的数据都会在前几页。
es的分页查询
前文es中没有对分页查询做说明,我们接上一篇的结尾,在项目中继续操作,但在说分页前,我们需要先对排序做一个了解,es的排序写法其实和SQL很相似,这在前文中我们已经有所见识,下面就一起来看看吧。
排序
排序和上一篇结尾的单条件/多条件查询都属于条件查询,我们在Repository类中来写一下怎么进行排序,在类中添加如下方法:
// 排序查询
// 默认情况下,ES查询结果按score排序,如果想按其他的规则排序可以加OrderBy
// 和数据库一样,默认升序排序 Desc结尾会降序
Iterable<People> queryItemsByNameMatchesOrderByBraveDesc(String name, Double brave);接着进行测试,在测试类中添加如下测试方法:
// 排序查询
@Test
void queryOrder(){
Iterable<People> items=peopleRepository
.queryItemsByNameMatchesOrderByBraveDesc("西游");
items.forEach(item -> System.out.println(item));
}提示:在测试前,务必保证es处于启动状态,由于不是当天写的,所以es停止了,运行后发现报错,启动es后正常,下面看运行结果:
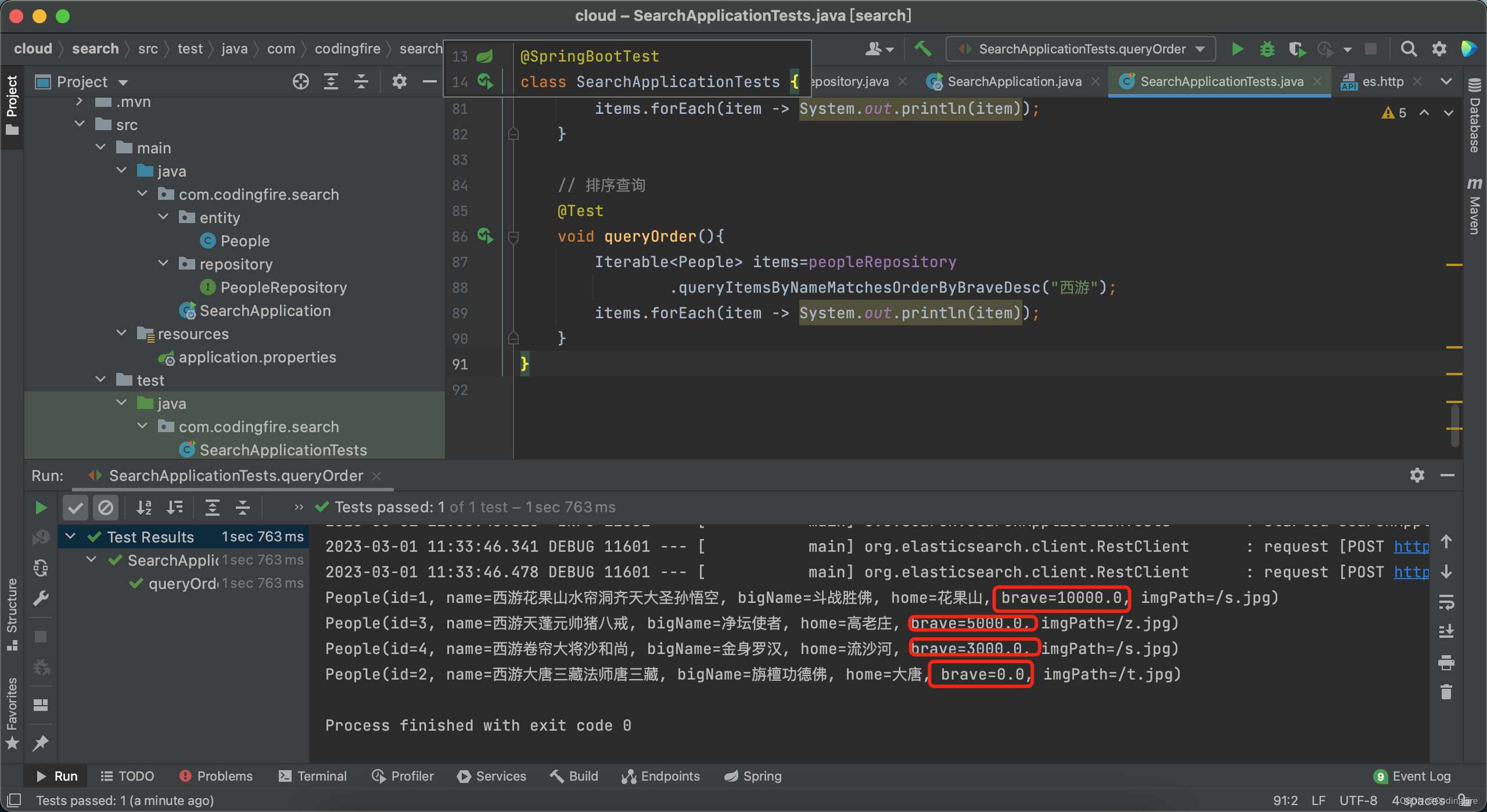
是按照我们想要的战力进行的排序,测试成功,你成功了吗?
来看看底层的代码逻辑:
### 单字段搜索排序
POST http://localhost:9200/peoples/_search
Content-Type: application/json
{
"query": {"match": { "name": "西游" }},
"sort":[{"brave":"desc"}]
}可以在条件中增加其他的条件进行尝试。
分页加排序
我们在使用es时用了SpringData框架,其支持分页查询,只需要修改参数和返回值就能实现自动分页的效果,这就帮我们省去了很多的代码和功夫,下面让我们来看看它是怎么分页的。
我们以刚刚的排序为例,在其基础上进行修改,额外增加一个方法:
// 分页查询
// 当查询数据较多时,我们可以利用SpringData的分页功能,按用户要求的页码查询需要的数据
// 返回值修改为Page类型,这个类型对象除了包含Iterable能够包含的集合信息之外,还包含分页信息
Page<People> queryItemsByNameMatchesOrderByBraveDesc(String name, Pageable pageable);接着我们开始进行测试,由于我们数据量比较少,我们会把每页的数据设置的很少,看看代码怎么写:
// 分页查询
@Test
void queryPage(){
int pageNum=1; //页码
int pageSize=2; //每页条数
Page<People> page= peopleRepository
.queryItemsByNameMatchesOrderByBraveDesc(
"西游", PageRequest.of(pageNum-1,pageSize));
page.forEach(item -> System.out.println(item));
// page对象中还包含了一些基本的分页信息
System.out.println("总页数:"+page.getTotalPages());
System.out.println("当前页:"+page.getNumber());
System.out.println("每页条数:"+page.getSize());
System.out.println("当前页是不是首页:"+page.isFirst());
System.out.println("当前页是不是末页:"+page.isLast());
}我们在这里要注意分页的起始页,程序中我们第一位总是0开始的,但在生活中都是从1开始的,为了让主观上认为从1开始,我们在内部做减1操作。
运行测试代码,查看结果:
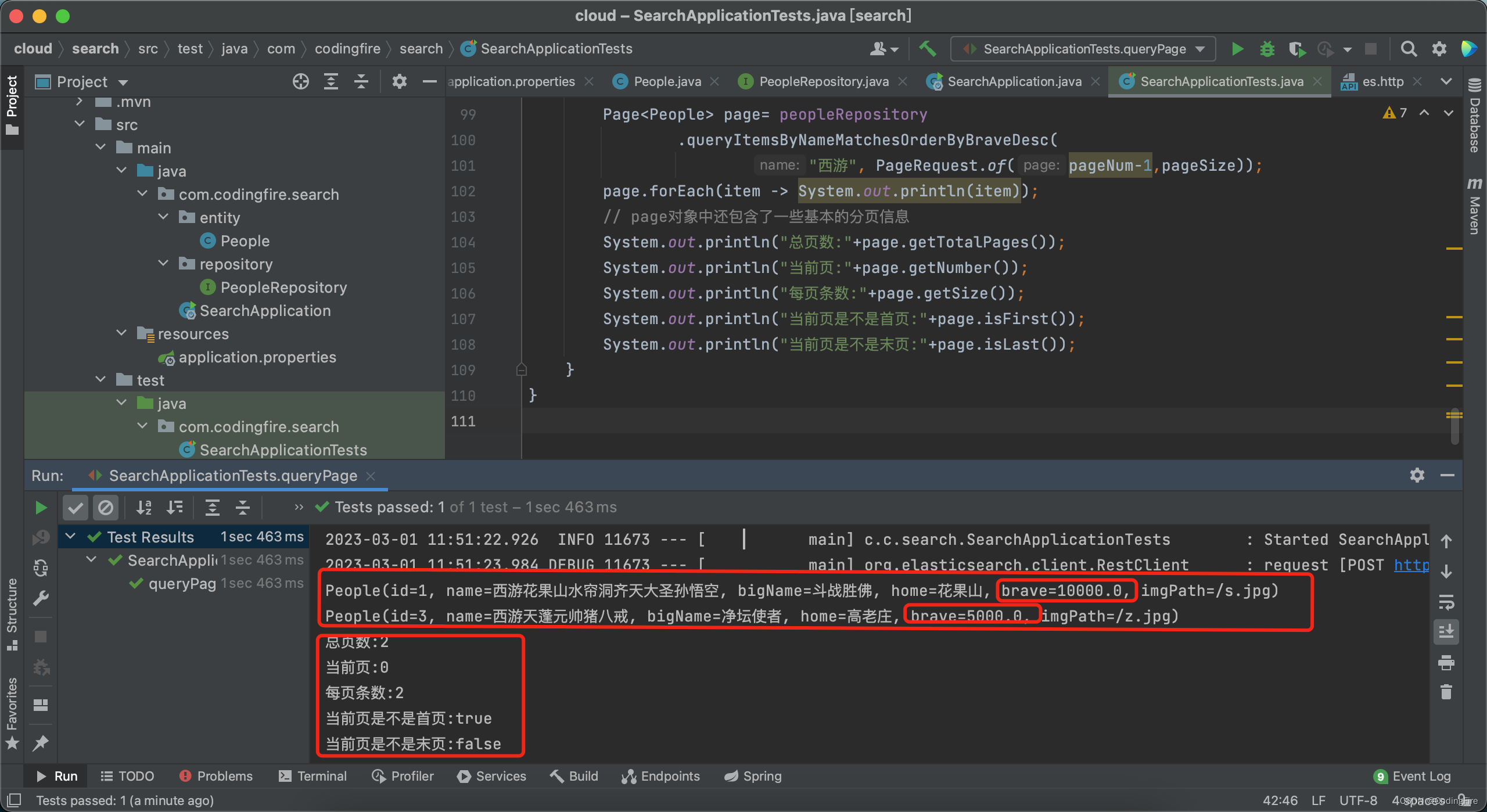
结果是按照排序后进行分页的,数据完全正确,测试成功。es的分页到这里就结束了,你学会了吗?新来的童鞋建议先看前一篇es,结合代码操作一遍,理解会更加的透彻。
数据库分页
PageHelper
SQL中我们通过limit关键字来进行分页查询,但却需要实时进行计算,在Spring Data中,我们通过框架帮我们解决了这个问题,PageHelper也是一个框架,它帮我们自动实现了分页效果,我们可以像Spring Data里那样,通过提供页码和数量来达到分页的目的。
所谓自动实现,也只是PageHelper在程序运行时,通过向SQL语句末尾添加limit的方式来实现分页,不要觉得讽刺,你当然可以选择自己来写,那是你的自由,我们使用框架的目的就是帮助我们降低开发的成本,提高开发的效率。
为了说明PageHelper的用法,我们还是在微服务的项目中进行同步讲解,以代码实战的形式进行。没有看过微服务篇的同学可以先去看看,这里要用到项目的工程,你也可以选择自建一个新的工程。但可能会略微有些麻烦。
添加依赖
我们在order模块进行代码的编写,首先添加依赖如下:
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
</dependency>
此依赖在添加senta依赖时已经添加过,我们要知道。
基本使用
持久层
我们在OrderMapper接口中添加查询的方法如下:
@Select("select id,user_id,commodity_code,count,money from order_tbl")
List<Order> findAllOrders();需要注意,此方法不需要添加分页相关的参数,如limit,我们使用的框架会自动追加参数进去。他不区分SQL语句是写在注解中还是xml文件中。
业务逻辑层
在实现类OrderServiceImpl中添加此方法:
// 分页查询所有订单的方法
// pageNum是要查询的页码
// pageSize是每页的条数
public PageInfo<Order> getAllOrdersByPage(Integer pageNum, Integer pageSize){
// 利用PageHelper框架的功能,指定分页的查询的页码和每页条数
// pageNum为1时,就是查询第一页,和SpringData的分页不同(SpringData分页0表示第一页)
PageHelper.startPage(pageNum,pageSize);
// 调用查询所有订单的方法
// 因为上面设置了分页查询的条件,所以下面的查询就会自动在sql语句后添加limit关键字
// 查询出的list就是需要查询的页码的数据
List<Order> list=orderMapper.findAllOrders();
// 我们完成了分页数据的查询,但是当前方法要求返回分页信息对象PageInfo
// PageInfo中可以包含分页数据和各种分页信息,这些信息都是自定计算出来的
// 要想获得这个对象,可以在执行分页查询后实例化PageInfo对象,所有分页信息会自动生成
return new PageInfo<>(list);
}PageInfo对象既包含查询数据结果,又包含分页信息,我们来看看该类中有哪些属性:
//当前页
private int pageNum;
//每页的数量
private int pageSize;
//当前页的行数量
private int size;
//当前页面第一个元素在数据库中的行号
private int startRow;
//当前页面最后一个元素在数据库中的行号
private int endRow;
//总页数
private int pages;
//前一页页号
private int prePage;
//下一页页号
private int nextPage;
//是否为第一页
private boolean isFirstPage;
//是否为最后一页
private boolean isLastPage;
//是否有前一页
private boolean hasPreviousPage;
//是否有下一页
private boolean hasNextPage;
//导航条中页码个数
private int navigatePages;
//所有导航条中显示的页号
private int[] navigatepageNums;
//导航条上的第一页页号
private int navigateFirstPage;
//导航条上的最后一页号
private int navigateLastPage;根据需要选择需要的参数。
控制器层
业务逻辑层完成后,就需要在控制器层通过接口来调用接口方法,在OrderController类中添加如下控制器方法:
@GetMapping("/page")
@ApiOperation("分页查询订单")
@ApiImplicitParams({
@ApiImplicitParam(value = "页码",name="pageNum",example = "1"),
@ApiImplicitParam(value = "每页条数",name="pageSize",example = "10")
})
public JsonResult<PageInfo<Order>> pageOrders(Integer pageNum, Integer pageSize){
// 分页调用
PageInfo<Order> pageInfo=orderService.getAllOrdersByPage(pageNum,pageSize);
return JsonResult.ok("查询完成",pageInfo);
}你可以从方法中看到我们之前写的方法的影子,只是在参数方面我们做了一些调整,加入了分页相关的信息。由于我们这里没有写接口方法,所以为了调用实现类中的方法,我们需要修改此类中IOrderService为OrderServiceImpl,直接调用实现方法。
测试
在这里,启动nacos和seata,如果es还开启着,可以关闭了,博主的电脑都开始烫了。接着运行order
模块,额,报错?看看啥报错:
java.sql.SQLNonTransientConnectionException: Public Key Retrieval is not all以前都没报这个错啊,奇怪了,数据库也没升级,经查询,通过在spring.datasource.url后添加allowPublicKeyRetrieval=true可解决此问题。注意添加的格式:
url: jdbc:mysql://localhost:3306/cloud_db?useSSL=false&useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai&allowMultiQueries=true&allowPublicKeyRetrieval=true启动成功后,我们在浏览器输入在线文档的地址:http://localhost:20002/doc.html
打开此页面:
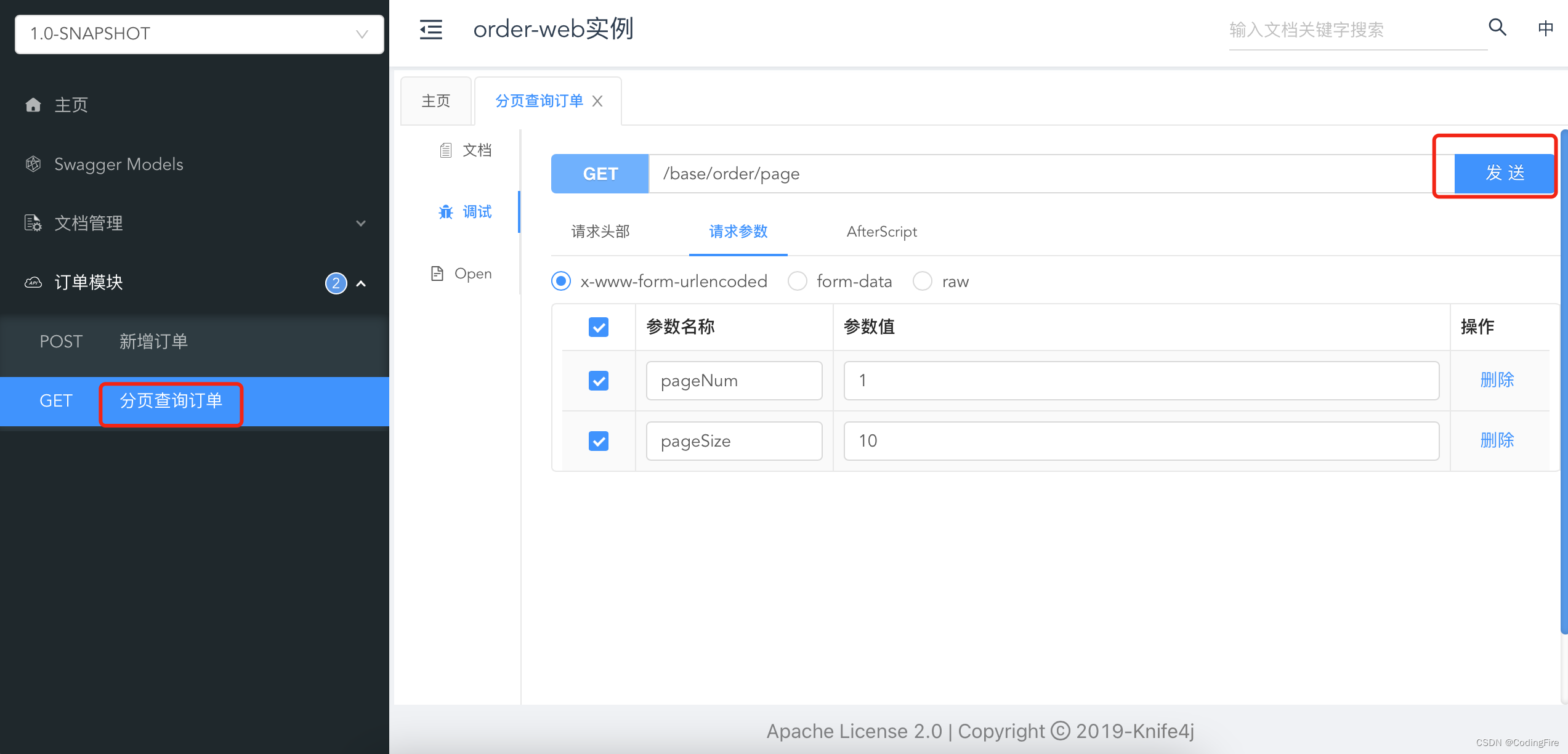
点击发送按钮,可看到如下数据:
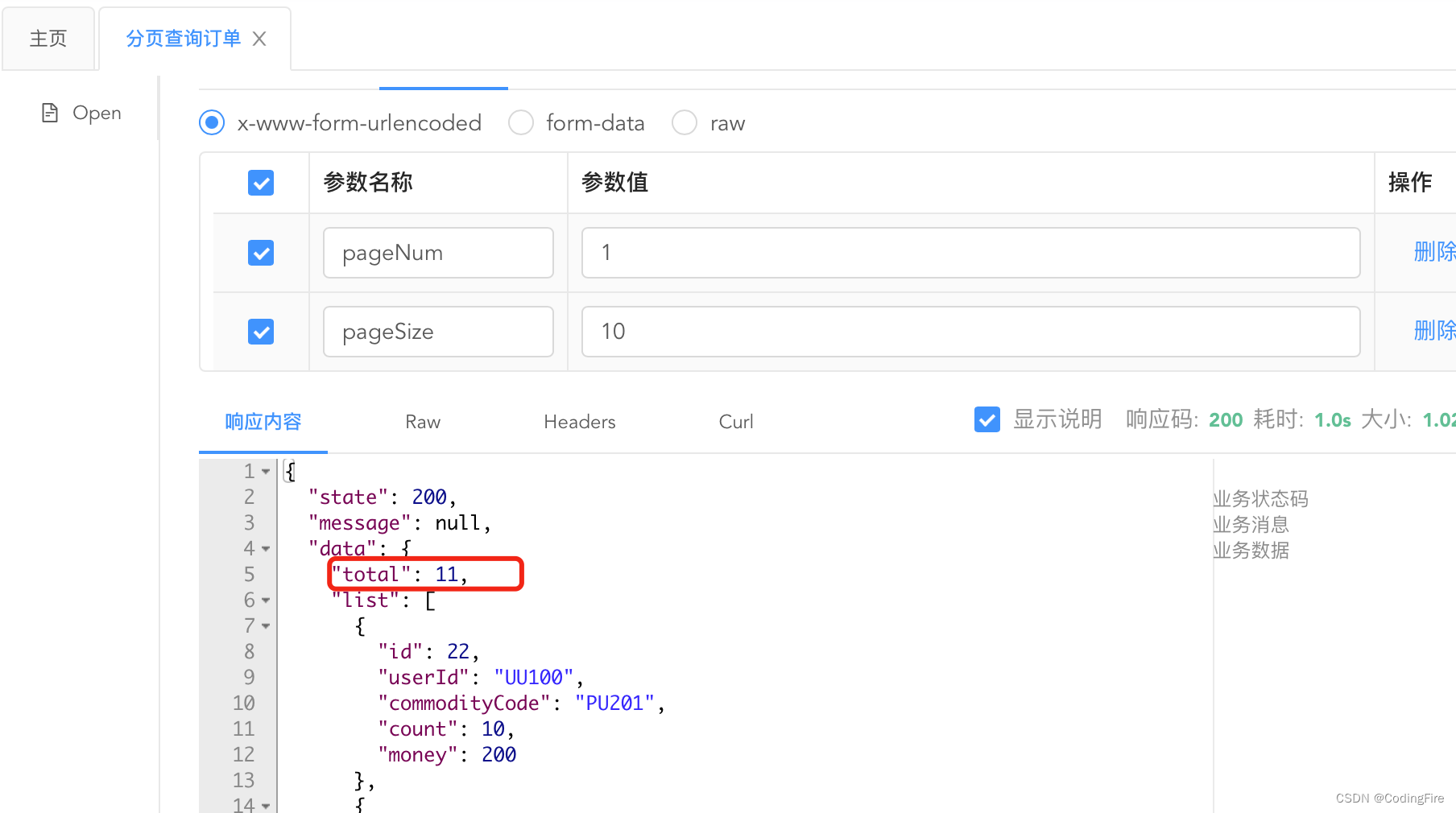
博主的数据库有11条数据,第一页给了10条数据,将页码改为2后,点击发送:

控制台中也打印出了自动追加limit的SQL语句:
==> Preparing: select id,user_id,commodity_code,count,money from order_tbl LIMIT ?, ?
==> Parameters: 10(Long), 10(Integer)
这里只返回了一条数据,就代表我们的测试已经成功了。但,我们注意到,上面的代码中还是存在一定问题,因为我们没有使用接口进行调用,而是直接调用了实现类方法,这是不符合规则的。原因可以看下方数据返回的内容。下面,我们将来完善这个步骤。
数据返回
分页查询我们在上面的方法中使用的PageInfo作为返回值,这是不合适的,因为使用此类,这个类就会出现在任何调用这个方法的模块,这些模块都将添加PageHelper的依赖,而且我们也不方便来做一些自定义的东西,为了解决此问题,我们需要在commons模块中添加一个返回类来代替PageInfo。
添加依赖
所以在PageInfo模块中,我们添加依赖如下:
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.2.0</version>
</dependency>
添加替代类
接着我们在restful包中新建一个JsonPage类,将PageInfo类封装进去:
package com.codingfire.cloud.commons.restful;
import com.github.pagehelper.PageInfo;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import java.io.Serializable;
import java.util.List;
// 通用支持分页查询的结果对象类型
@Data
public class JsonPage<T> implements Serializable {
// 按照实际需求,定义这个类中的属性
@ApiModelProperty(value = "当前页码",name = "pageNum")
private Integer pageNum;
@ApiModelProperty(value = "每页条数",name = "pageSize")
private Integer pageSize;
@ApiModelProperty(value = "总条数",name = "totalCount")
private Long totalCount;
@ApiModelProperty(value = "总页数",name = "totalPages")
private Integer totalPages;
// 声明一个属性,来承载查询到的分页数据结果
@ApiModelProperty(value = "分页数据",name = "list")
private List<T> list;
// 所有属性写完了,下面要编写将其他框架的分页结果转换成当前类对象的方法
// SpringDataElasticsearch或PageHelper等具有分页功能的框架,均有类似PageInfo的对象
// 我们可以分别编写方法,将它们转换成JsonPage对象,我们先只编写PageHelper的转换
public static <T> JsonPage<T> restPage(PageInfo<T> pageInfo){
// 下面开始将pageInfo对象的属性赋值给JsonPage对象
JsonPage<T> result=new JsonPage<>();
result.setPageNum(pageInfo.getPageNum());
result.setPageSize(pageInfo.getPageSize());
result.setTotalCount(pageInfo.getTotal());
result.setTotalPages(pageInfo.getPages());
result.setList(pageInfo.getList());
// 返回赋值完毕的JsonPage对象
return result;
}
}
修改业务逻辑层
在IOrderService接口类中添加新接口方法:
// 分页查询所有订单的方法
JsonPage<Order> getAllOrdersByPage(Integer pageNum, Integer pageSize);接着在实现类OrderServiceImpl中修改原来的实现方法如下:
public JsonPage<Order> getAllOrdersByPage(Integer pageNum, Integer pageSize){
// 利用PageHelper框架的功能,指定分页的查询的页码和每页条数
// pageNum为1时,就是查询第一页,和SpringData的分页不同(SpringData分页0表示第一页)
PageHelper.startPage(pageNum,pageSize);
// 调用查询所有订单的方法
// 因为上面设置了分页查询的条件,所以下面的查询就会自动在sql语句后添加limit关键字
// 查询出的list就是需要查询的页码的数据
List<Order> list=orderMapper.findAllOrders();
// 我们完成了分页数据的查询,但是当前方法要求返回分页信息对象PageInfo
// PageInfo中可以包含分页数据和各种分页信息,这些信息都是自定计算出来的
// 要想获得这个对象,可以在执行分页查询后实例化PageInfo对象,所有分页信息会自动生成
// ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
return JsonPage.restPage(new PageInfo<>(list));
}修改控制器层
此时,控制器层因为上面的代码修改已经报错了,然后修改控制器层方法,有两处:
第一处是OrderServiceImpl:
private OrderServiceImpl orderService;
private IOrderService orderService;其实就是修改回来,第一行改回第二行。
第二处是原方法修改返回值:
public JsonResult<JsonPage<Order>> pageOrders(Integer pageNum, Integer pageSize){
// 分页调用
JsonPage<Order> jsonPage=orderService.getAllOrdersByPage(pageNum,pageSize);
return JsonResult.ok("查询完成",jsonPage);
}一路修改,到这里就结束了。我们可以重新order模块,通过在线文档来进行测试,发现测试结果是一样的,这就可以了,测试成功,这一步是对返回值做了处理,使我们可以自定义返回值的对象,是代码更加的灵活,你可以对比修改前后返回值的结构。
结语
分页查询在开发中的使用非常频繁,就是再小的项目也离不开分页功能,虽然不一定使用es,但分页绝对会用,学完此篇,分页功能你就基本掌握了,剩下的就是在实践中使用此功能,相信你一定已经学会了。另外,分页功能还不算难,和es比起来算是比较基础的功能了,只是涉及es的分页,才展开讲了一下,这是每一个后台开发者都必须会的内容,大家有时间多做练习,自己进行尝试,才能够掌握得更好。又到了和大家说再见的时候,觉得不错,就三连(点赞,收藏,评论)支持一下吧。









![[busybox] busybox生成一个最精简rootfs(下)](https://img-blog.csdnimg.cn/5332d8e0aa0a4c6995299ee449494438.png)