文章目录
- 理解文件系统
- 了解磁盘结构
- inode
理解文件系统
了解磁盘结构
磁盘是计算机中的一个 机械设备
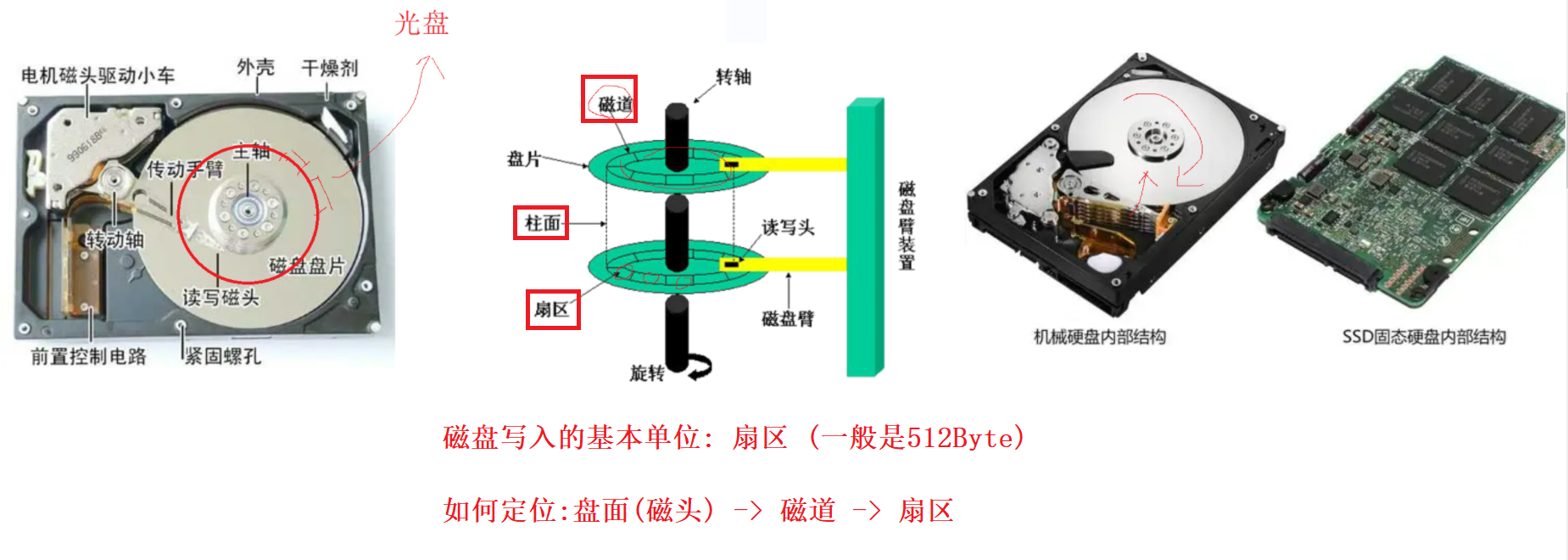
这个磁盘的盘片就像光盘一样,数据就在盘片上放着, 但是光盘是只读的,磁盘是可读可写的
机械硬盘的寻址的工作方式: 盘片不断旋转,磁头不断摆动,定位到特定的位置
我们可以把磁盘看成是 线性结构,站在OS的视角:我们就认为磁盘是线性结构,要访问某一个扇区,就要定位数组下标LBA,要写到物理磁盘上,就要把LBA地址转化成磁盘的三维地址(磁头,磁道,扇区)

inode
文件在磁盘上是如何保存的?
1)首先我们知道,文件是在磁盘中的, 而现在我们把磁盘认为是一个线性结构
磁盘的空间很大,管理成本高!但是我们可以划分进行管理,比如我们的国家,把土地划分成每一块,并且给每一块土地配合合适的管理人员
因此我们对大磁盘:
1.分区: 大磁盘->划分为若干个小空间
2.格式化: 给每个分区 写入文件系统 (比如:向某某省写入领导班子)
下面我们以一个小区域作为例子,理论上,如果我们能把这个小区域管理好, 其余区域再复用这个管理方式即可.
例如:
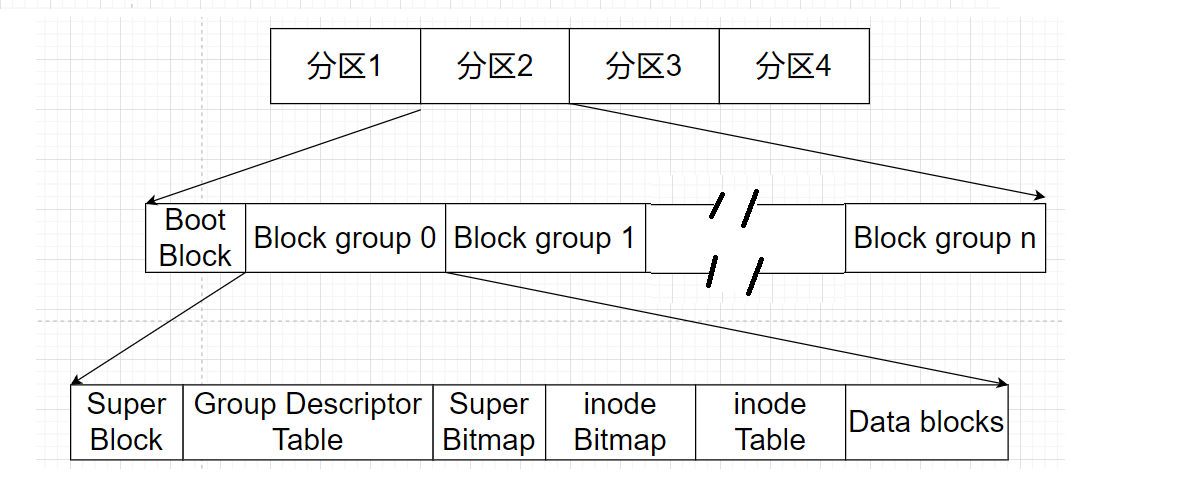
- Block Group:ext2文件系统会根据分区的大小划分为数个Block Group.而每个Block Group都有着相同的结构组成 政府管理各区的例子
- 超级块(Super Block):存放文件系统本身的结构信息.记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息.Super Block的信息被破坏,可以说整个文件系统结构就被破坏了
- GDT,Group Descriptor Table:块组描述符,描述块组属性信息
- 块位图(Block Bitmap):Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用
- inode位图(inode Bitmap):每个bit表示一个inode是否空闲可用
- 节点表:存放文件属性 如 文件大小,所有者,最近修改时间等
- 数据区:存放文件内容
每个分区最初都可以有Boot Block,是与启动相关的,供启动时查找分区, 我们再把剩下的空间继续拆解分组, Block group 0,Block group 1,…Block group n ,如果我们能管理好Block group 0,就能管理好1~n ,于是研究文件系统,就变成了研究一个Block group 0
文件 = 文件内容 + 文件属性 ,文件内容放在Data blocks中,属性放在inode Table中
其中文件内容就算就算当中存储的数据,文件属性就算文件的一些基本信息,如:文件名,文件大小,文件的创建时间等信息
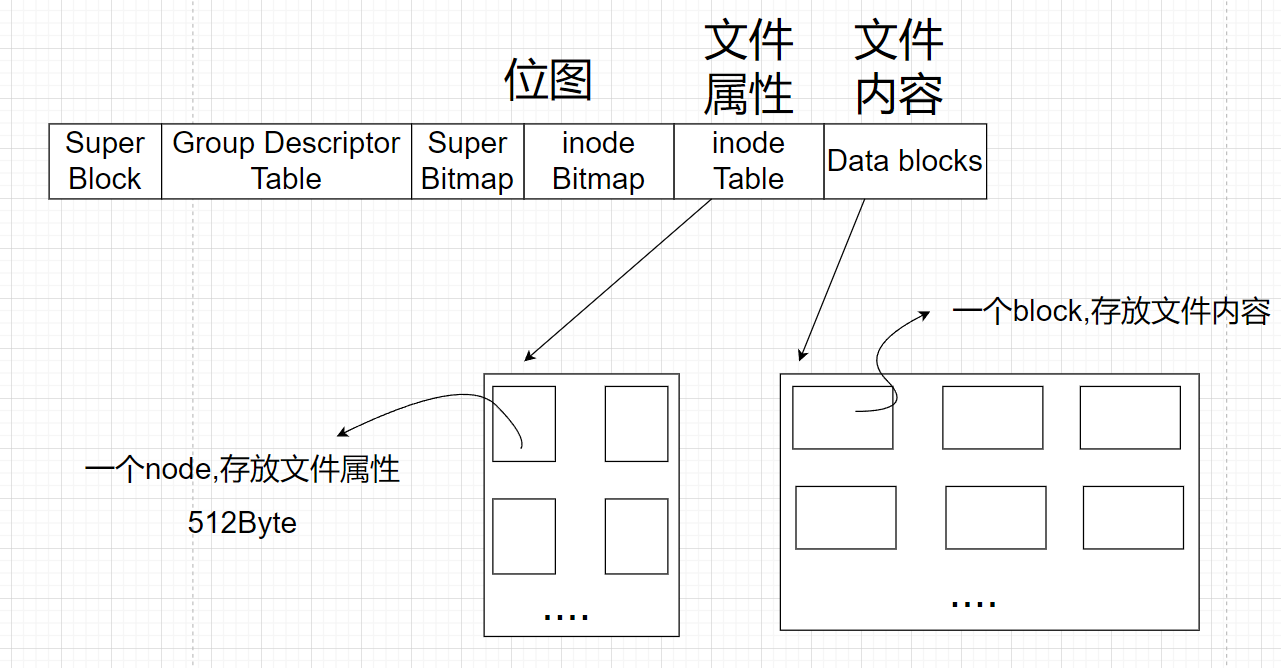
文件属性和文件内容分开存放,那他们是怎么关联的呢?
我们平常都是用文件名访问文件,但是在Linux下,在系统层面,文件名以及它的后缀是没有意义的,只是为了方便给用户使用. Linux真正标识一个文件,是通过文件的inode编号 ,一个文件对应一个inode,一个inode也有自己的编号
inode里面有什么
要创建文件,就要在inode Table中申请一个未被使用的inode,填入文件的属性, 在Data blocks中也要创建一个block,用于存放文件的内容, inode用数组存储了相关联的blocks块编号,
Linux真正标识一个文件,是通过文件的inode编号,一个文件一个inode
//包含所有的文件的属性
struct inode
{
//数据
int inode_num;
int blocks[32];
};
inode和inode编号:
保存文件信息的结构称为inode,因为系统中存在大量的文件,我们需要给每个文件的属性集起一个唯一的编号标识它,即 inode编号
我们怎么在inode Table申请一个未被使用的inode 和 如何在 Data blocks中申请未被使用的数据块?
使用遍历的话效率太低, 于是我们有位图inode Bitmap 和 block Bitmap来标识
例子:
0000 1111
从右往左,每一个比特位位置的含义是: inode编号 比特位的内容含义:特定的inode是否被使用
于是创建文件,申请一个未被使用的inode,就遍历inode Bitmap,找到第一个比特位为0的位置, 申请block数据块也同理, 当我们遍历到若干个为0的数据块位置,填入到blocks数组中构造映射关系
问:inode不保存文件名, 文件名是怎么和inode做对应的?
首先,我们要知道, Linux下一切皆是文件, 目录也是文件!所以在磁盘上,目录也有自己的 inode,目录也有自己的数据, 目录的数据块存放什么? -> 目录下的文件名和其对应的inode编号
- 那目录的inode中存放什么信息?
目录的大小,权限,链接数, 拥有者,所属组等

- 目录的数据块block放什么
首先我们要知道,我们所创建的所有文件,都放在特定的目录下,用户要用文件名,而系统用的是inode,因此 目录的数据块中存的是文件名和inode的映射关系
如何理解创建一个空文件
1.遍历inode Bitmap,找到比特位为0的位置,申请一个未被使用的inode
2.将inode表中找到对应的inode, 并将文件的属性信息填到inode结构当中
3.将该文件的文件名和inode指针添加到目录文件的数据块当中
如何理解对文件信息写入
1.通过文件的inode编号找到对应的inode结构
2.通过inode结构找到存储该文件内容的数据块,并将数据写入数据块
3.若不存在数据块或者申请的数据块已经写满了,就需要遍历block Bitmap找到一个空间的块号,并在数据区当中找到对应的空闲块,把数据写入到数据块当中,最后还需要建立数据块和inode结构的对应关系
描述下面的操作在系统层面都干了什么
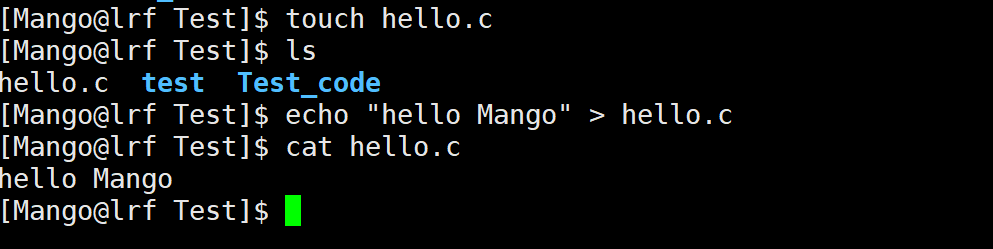
1)创建文件: 遍历inode Bitmap位图找到比特位为0的位置, 然后把该位置比特位置为1,申请一个未被使用的inode,填入属性信息,并把这个文件名和inode的映射关系写到目录的Data blocks中
2)查看目录:根据该目录数据块的内容,通过inode找到与其映射的文件名
3)向文件当中写入:遍历位图block map找到若干个未被使用的数据块,把该文件的inode和这些blocks建立映射关系,然后向blocks写入内容
4)查看文件内容: cat hello.c -> 查看当前Test目录的data Blocks的数据块->找到hello.c这个文件名和其inode编号的映射关系 -> 在inode Table中找到inode -> 在inode结构体中找到对应的blocks[] -> 打印文件内容
问:删除文件做了些什么?
删除一个文件,并不删除属性和数据,只是把它是否有效删除掉了
只需要在位图中把对应inode编号的比特位由1置为0,把使用的数据块也在位图中由1置为0,并不需要改动文件属性和数据,所以删除数据一般是很快的
当我们删除文件后短时间内是可以恢复的, 为什么说是短时间内呢,因为该文件对应的inode号和数据块号已经被置为了无效,因此后续创建其他文件或是对其他文件进行写入操作申请inode号和数据块号时,可能会将该置为无效了的inode号和数据块号分配出去,此时删除文件的数据就会被覆盖,也就无法恢复文件了
为什么拷贝文件的时候很慢,而删除文件的时候很快
因为拷贝文件需要先创建文件,然后再对该文件进行写入操作,该过程需要先申请inode号并填入文件的属性信息,之后还需要再申请数据块号,最后才能进行文件内容的数据拷贝,而删除文件只需将对应文件的inode号和数据块号置为无效即可,无需真正的删除文件,因此拷贝文件是很慢的,而删除文件是很快的
如何理解目录
1.都说在Linux下一切皆文件,目录当然也可以被看作为文件
2.目录有自己的属性信息,目录的inode结构当中存储的就是目录的属性信息,比如目录的大小、目录的拥有者等
3.目录也有自己的内容,目录的数据块当中存储的就是该目录下的文件名以及对应文件的inode指针
注意: 每个文件的文件名并没有存储在自己的inode结构当中,而是存储在该文件所处目录文件的文件内容当中.因为计算机并不关注文件的文件名,计算机只关注文件的inode号,而文件名和文件的inode指针存储在其目录文件的文件内容当中后,目录通过文件名和文件的inode指针即可将文件名和文件内容及其属性连接起来
如何理解把一个文件移动到另一个目录下
实际上是把文件名和inode的映射关系到另一个目录下
在命令行输入ls -l可以查看各个文件的属性信息

其中每一列代表的内容都不一样:
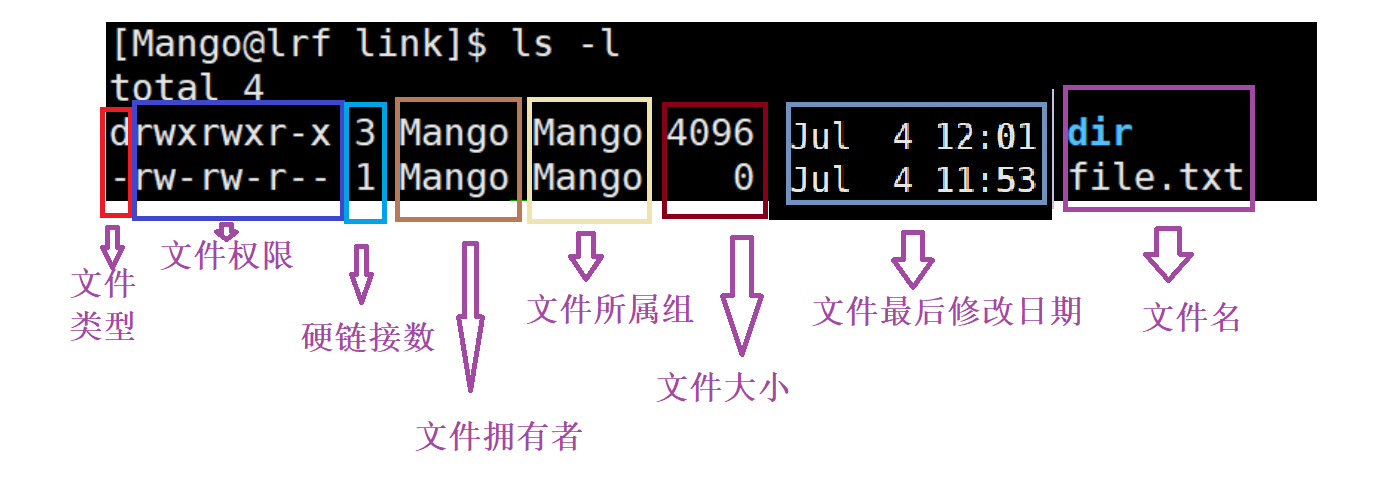
注意:无论是文件内容还是文件属性,他们都是存储在磁盘当中的