- 深解Cypher中的聚合
- 值或计数的聚合要么从查询返回,要么用作多步查询下一部分的输入。
- 查看数据模型
- CALL db.schema.visualization()
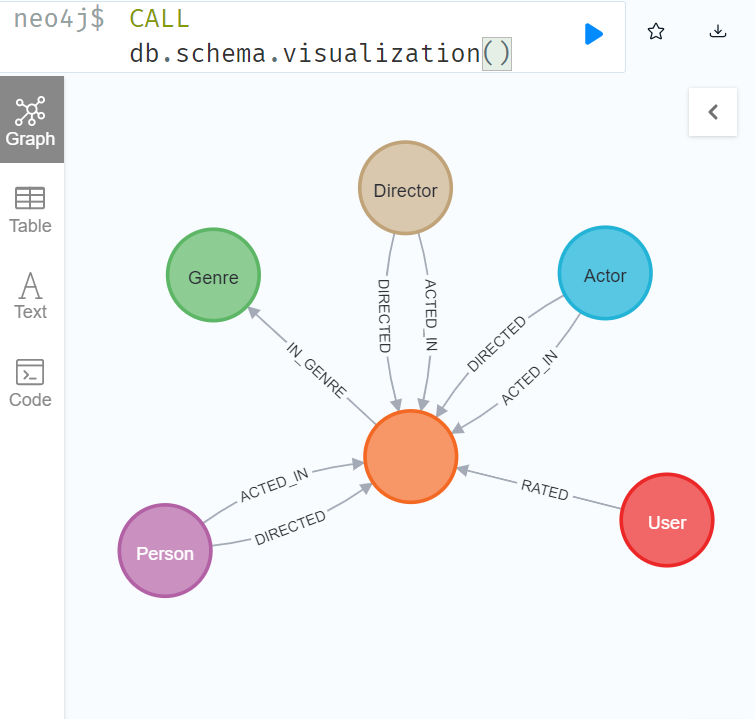
- CALL db.schema.visualization()
- 查看图中节点的属性类型
- CALL db.schema.notetypeproperties()
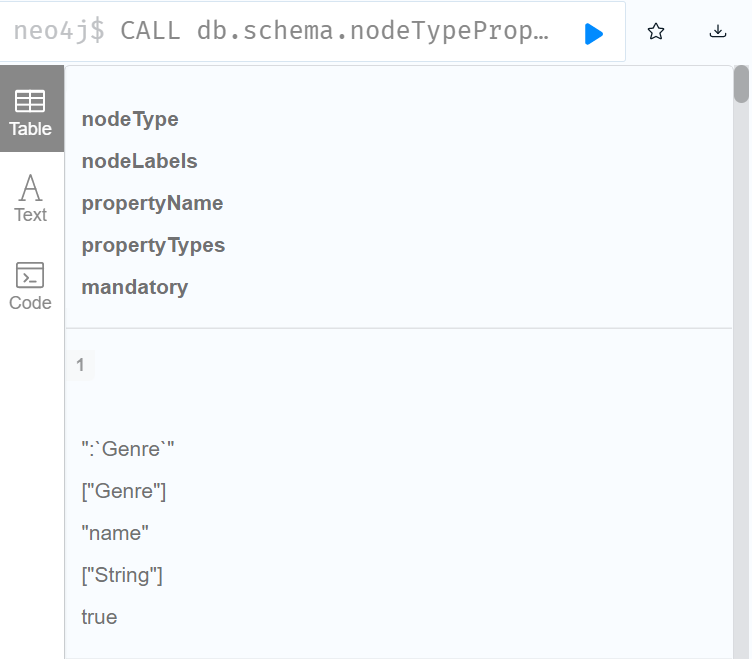
- CALL db.schema.notetypeproperties()
- 查看图中关系的属性类型
- CALL db.schema.reltypeproperties()
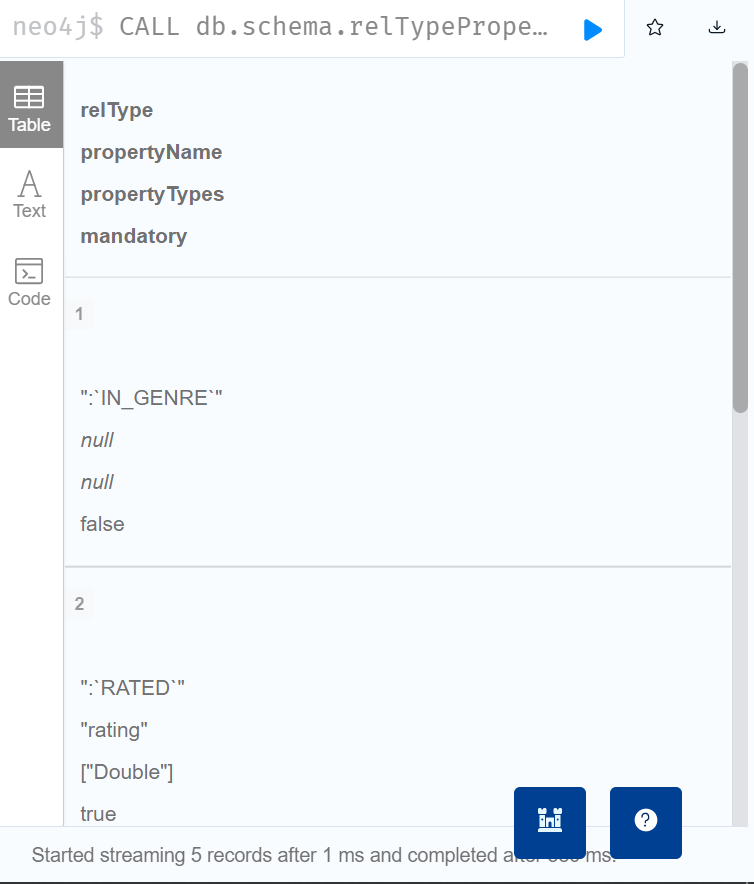
- CALL db.schema.reltypeproperties()
- Cypher中的聚合
- 列表
- 列表是包含元素的数组。列表中的元素不必都是同一类型。
- 使用 [ ]
- MATCH (m:Movie) RETURN [m.title, m.released, date().year - date(m.released).year + 1 ]
- 使用 collect()
- MATCH (a:Actor)--(m:Movie) WITH a,collect(m.title) AS Movies RETURN a.name AS Actor,Movies LIMIT 10
- 工作原理
- 返回一个元素列表。可以 collect() 在查询期间随时使用创建列表。在查询期间创建列表时,会发生聚合。
- 在聚合期间,图形引擎通常根据行中的某个值对数据进行分组。(非聚合值是分组键)
- Examples
- 多个MATCH
- PROFIL EMATCH (m:Movie {title:'Jupiter Ascending'}) MATCH (d:Person)-[:DIRECTED]->(m) MATCH (a:Person)-[:ACTED_IN]->(m) RETURN m.title AS Title, collect(DISTINCT a.name) AS Actors,collect(DISTINCT d.name) AS Directors
- 优化
- PROFILE MATCH (m:Movie {title:'Jupiter Ascending'}) MATCH (d:Person)-[:DIRECTED]->(m) WITH m, collect (d.name) AS Directors MATCH (a:Person)-[:ACTED_IN]->(m) RETURN m.title AS Title, collect(a.name) AS Actors, Directors
- 类似传统SQL将每部分添加查询条件得到最终结果
- 优化
- PROFIL EMATCH (m:Movie {title:'Jupiter Ascending'}) MATCH (d:Person)-[:DIRECTED]->(m) MATCH (a:Person)-[:ACTED_IN]->(m) RETURN m.title AS Title, collect(DISTINCT a.name) AS Actors,collect(DISTINCT d.name) AS Directors
- 单个MATCH
- PROFILE MATCH (d:Person)-[:DIRECTED]->(m:Movie {title:'Jupiter Ascending'})<-[:ACTED_IN]-(a:Person) RETURN m.title AS Title, collect(DISTINCT a.name) AS Actors,collect(DISTINCT d.name) AS Directors
- 多个MATCH
- 收集节点
- MATCH (m:Movie) UNWIND m.languages AS language WITH language, collect(m) AS movies MERGE (l:Language {name:language}) WITH l, movies UNWIND movies AS m WITH l,mMERGE (l)<-[:SPEAKS]-(m)
- 以作为 language 分组键,收集节点
- 使用 nodes() 返回路径中的节点列表。
- MATCH path = (p:Person {name: 'Elvis Presley'})-[*4]-(a:Actor) WITH nodes(path) AS n UNWIND n AS x WITH x WHERE x:Movie RETURN DISTINCT x.title
- 收集关系
- MATCH (u:User {name: "Misty Williams"})-[x]->() WITH collect(x) AS ratings UNWIND ratings AS r WITH r WHERE r.rating <= 1 RETURN r.rating AS Rating, endNode(r).title AS Title
- 使用 endNode() 返回关系末尾的节点。
- 与子查询
- PROFILE MATCH (m:Movie)<-[:ACTED_IN]-(p:Person) WITH m, collect(p.name) AS Actors WHERE size(Actors) <= 3 RETURN m.title AS Movie, Actors
- 查询重写
- PROFILE CALL { MATCH (m:Movie)<-[:ACTED_IN]-(p:Person) WITH m , collect(p.name) as Actors WHERE size(Actors)<= 3 RETURN m.title as Movie, Actors } RETURN Movie, Actors
- 使用 count()
- 可以在查询处理期间对属性、节点、关系、路径或行进行计数。
- MATCH (a:Person)-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(d:Person) RETURN a.name AS ActorName,d.name AS DirectorName,count(*) AS NumMovies, collect(m.title) AS Movies ORDER BY NumMovies DESC
- 在属性值上使用
- MATCH (p:Person) RETURN count(p) , count(p.born),count(p.name)
- 此查询看到 born 的计数与其它不同,说明节点中无 born 属性
- MATCH (p:Person) RETURN count(p) , count(p.born),count(p.name)
- 作为过滤查询的子句
- MATCH (a:Person)-[:ACTED_IN]->(m:Movie) WITH a, count(*) AS NumMovies, collect(m.title) AS Movies WHERE NumMovies = 2 RETURN a.name AS Actor,Movies
- 计算节点数
- MATCH (p:Person {name: 'Elvis Presley'})-[]-(m:Movie)-[]-(a:Actor) RETURN count(*), count(m), count (a)
- 可以在查询处理期间对属性、节点、关系、路径或行进行计数。
- 使用模式理解
- 模式理解的行为类似于使用 OPTIONAL MATCH,并且对于这个特定的查询,经过的时间减少了。
- 原
- PROFILE MATCH(m:Movie) WHERE m.year = 2015 OPTIONAL MATCH (a:Person)-[:ACTED_IN]-(m) WITH m, collect(DISTINCT a.name) AS Actors OPTIONAL MATCH (m)-[:DIRECTED]-(d:Person) RETURN m.title AS Movie, Actors, collect (DISTINCT d.name) AS Directors
- 模式
- PROFILE MATCH (m:Movie) WHERE m.year = 2015 RETURN m.title AS Movie,[(dir:Person)-[:DIRECTED]->(m) | dir.name] AS Directors,[(actor:Person)-[:ACTED_IN]->(m) | actor.name] AS Actors
- 原
- 模式理解条件的过滤
- MATCH (a:Person {name: 'Tom Hanks'}) RETURN [(a)--(b:Movie) WHERE b.title CONTAINS "Toy" | b.title ]AS Movies
- 返回的列表添加更多属性(相当于Oracle中的合并列)
- 相当于不重复属性的collect(),注:模式理解下的属性可能为0,所有用size()定义
- MATCH (a:Actor)-[:ACTED_IN]->(m:Movie) WHERE 2000 <= m.year <= 2005 AND a.born.year >= 1980 RETURN a.name AS Actor, a.born AS Born,collect(DISTINCT m.title) AS Movies ORDER BY Actor
- MATCH (a:Actor) WHERE a.born.year >= 1980 WITH a, [(a)-[:ACTED_IN]->(m:Movie) WHERE 2000 <= m.year <= 2005 | m.title] AS Movies WHERE size(Movies) > 0 RETURN a.name as Actor, a.born as Born, Movies
- MATCH (a:Person {name: 'Tom Hanks'}) RETURN [(a)--(b:Movie) WHERE b.title CONTAINS "Toy" | b.title + ": " + b.year] AS Movies
- 相当于不重复属性的collect(),注:模式理解下的属性可能为0,所有用size()定义
- 模式理解的行为类似于使用 OPTIONAL MATCH,并且对于这个特定的查询,经过的时间减少了。
- 列表
Cypher中的聚合
news2026/2/15 5:04:36
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/380019.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
普通二本,去过阿里外包,到现在年薪40W+的高级测试工程师,我的两年转行经历...
我是一个普通二本大学机械专业毕业,14年毕业,16年转行,目前做IT行业的软件测试已经有3年多,职位是高级软件测试工程师,坐标上海…我想现在我也有一点资格谈论关于转行这个话题;希望你在决定转行之前&#x…
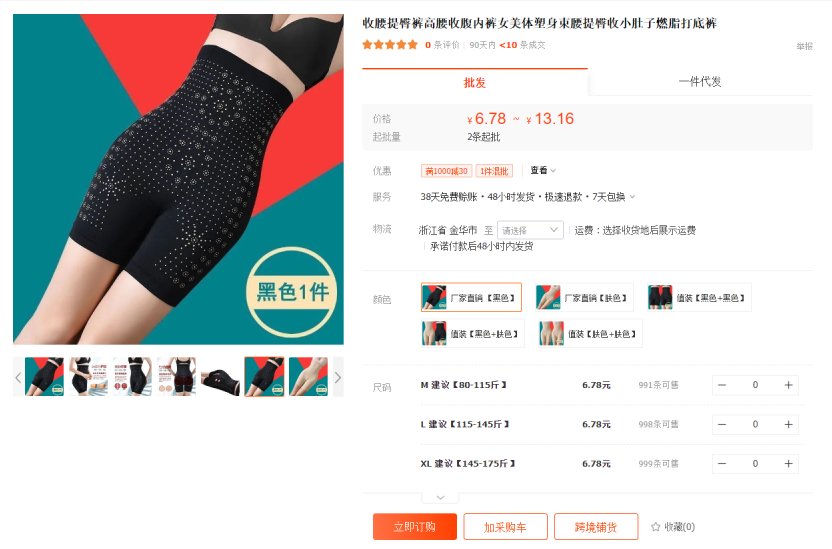
爆品分析第4期 | 从周销12件到3700+件,这款收腰裤热度和口碑都爆了!
衣食住行,衣是排在第一位的,作为复购率最高的类目之一,服饰一直是TikTok上电商选品的风向标,是衡量电商发展情况的重要参考指标。随着疫情的结束和经济的日渐好转,消费者对服装类的需求上升。除了时装、T恤等日常消费的…
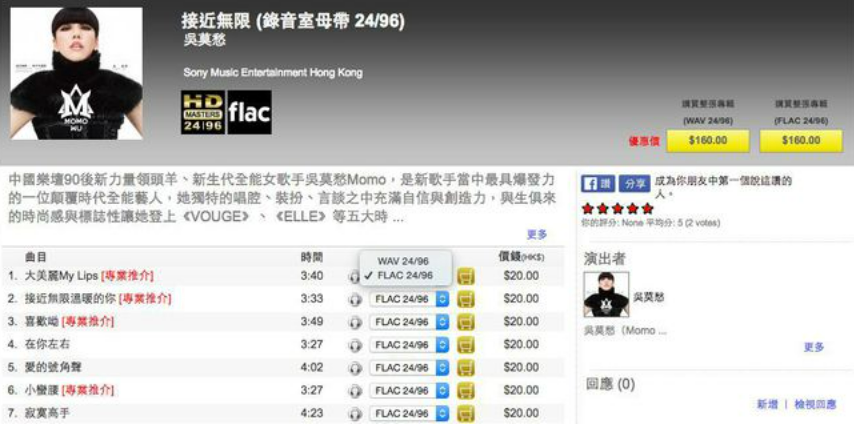
无损音乐格式:FLAC和ALAC
前言:我最近在弄苹果的airplay项目,发现airplay2对比airplay多了音质方面的增强。AAC和MP3接触过,但对FLAC和ALAC完全不了解,整理学习资料汇总成如下信息: AirPlay2
在2017年推出,在前一代AirPlay的基础上…

一篇文章搞性IPV6的原理和配置
本章对IPV6做了简单的介绍,并通过实验让读者了解IPV6地址和6TO4隧道的配置方法。 本章包含以下内容:
IPV6的概述 配置IPV6地址 配置6to4隧道
10.1 IPv6的概述
IPv6(Internet Protocol Version 6)是网络层协议…
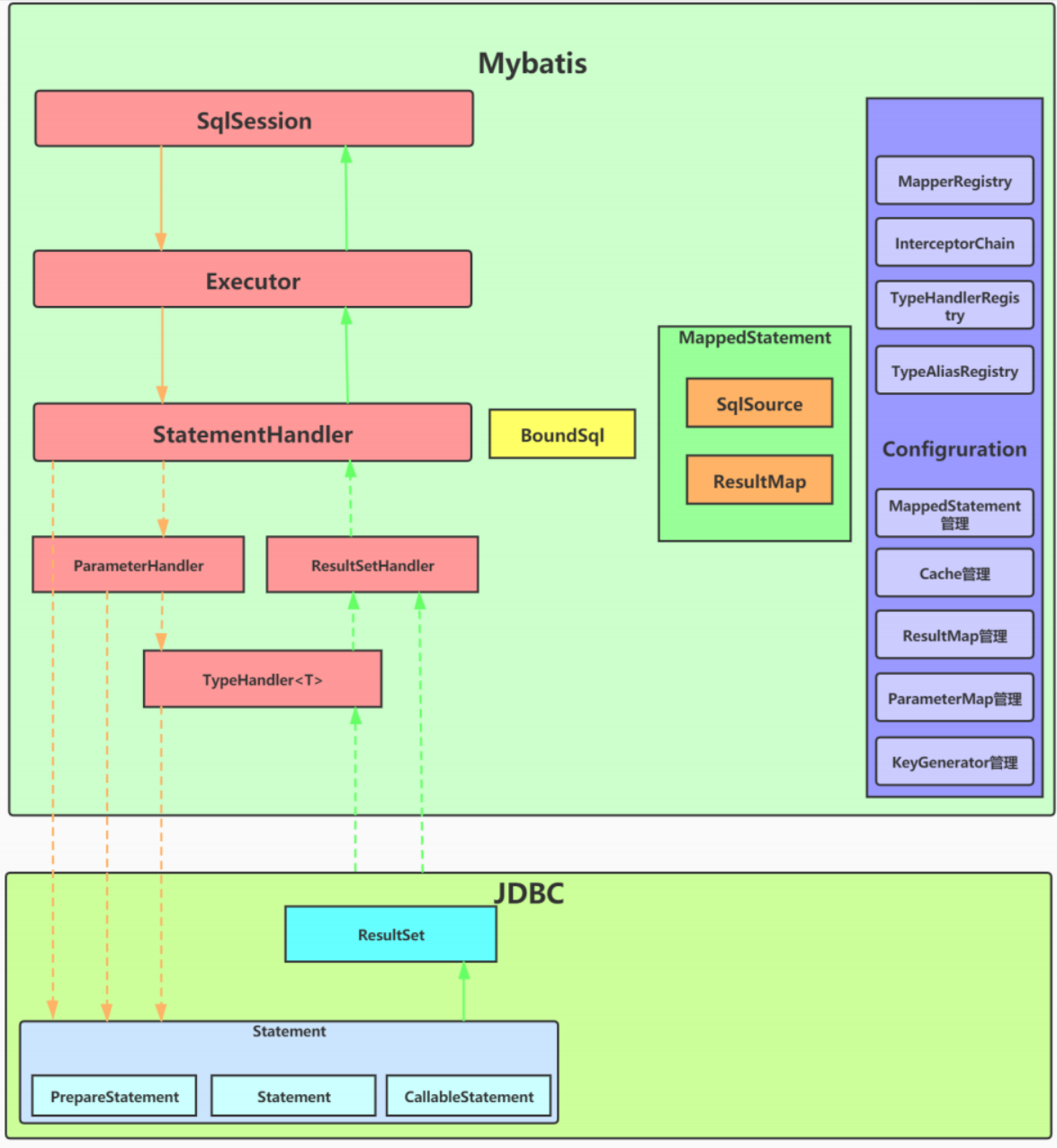
MyBatis源码分析(一)MyBatis整体架构分析
文章目录一、为什么要用MyBatis1、原始JDBC的痛点2、Hibernate 和 JPA3、MyBatis的特点4、MyBatis整体架构5、MyBatis主要组件及其相互关系6、MyBatis源码的特点二、源码环境搭建未完待续一、为什么要用MyBatis
1、原始JDBC的痛点
在传统JDBC场景下,SQL 夹杂在Jav…

Databend 开源周报第 80 期
Databend 是一款现代云数仓。专为弹性和高效设计,为您的大规模分析需求保驾护航。自由且开源。即刻体验云服务:https://app.databend.com 。Whats New探索 Databend 本周新进展,遇到更贴近你心意的 Databend 。Features & Improvements :…
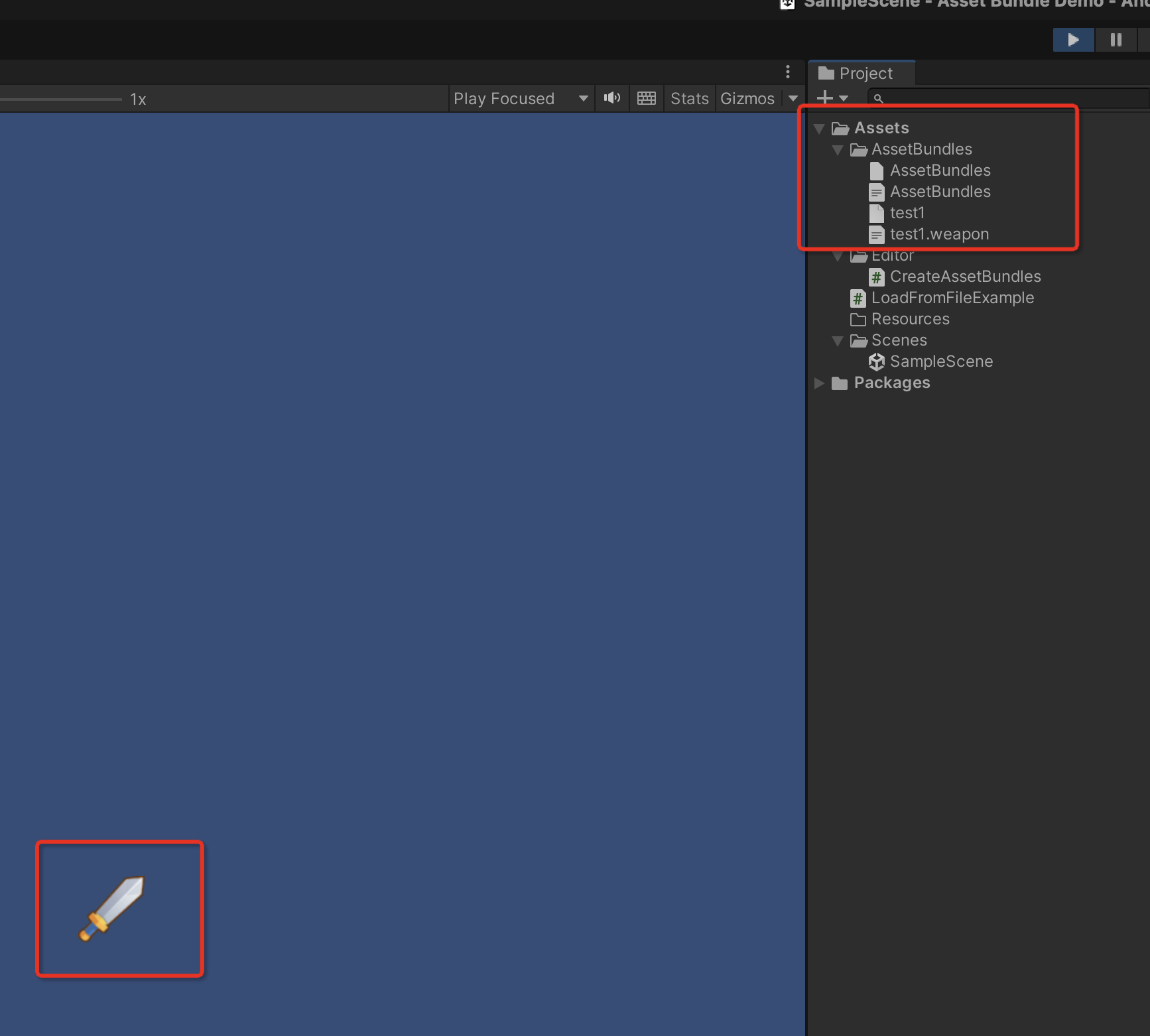
Unity Asset Bundle学习 - 加载本地资源
Unity的 Asset Bundle 文档 https://docs.unity3d.com/cn/2019.4/Manual/AssetBundles-Workflow.html 第一次接触 直接按官方文档操作 下面接着按文档走流程 构建AssetBundle 此脚本将在 Assets 菜单底部创建一个名为 Build AssetBundles 的菜单项,该菜单项将执行与…
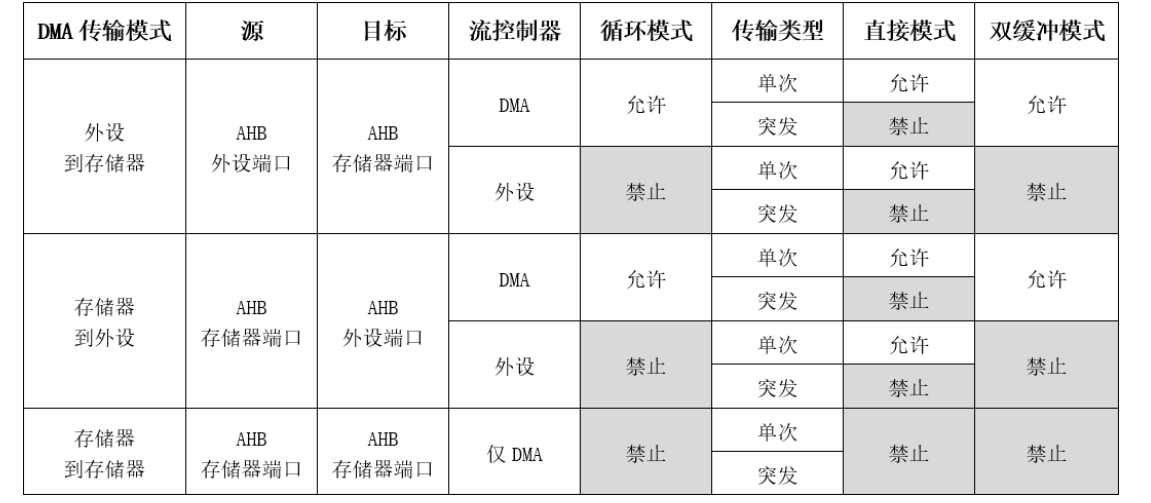
STM32学习笔记-DMA
文章目录一、功能框图通道选择仲裁器FIFO1. **FIFO**: First in First out2. FIFO作用:端口二、DMA模式配置1. 传输模式2. 源地址和目标地址3. 流控制器4. 循环模式5. 传输类型6. 直接模式7. 双缓冲模式8.DMA中断事件三、程序设计1. DMA初始化结构体DMA(Direct Memo…
20 | k8s v1.20集群搭建master和node
1 单节点master
1.1 服务器整体规划
1.2 单Master架构图
1.3 初始化配置
1.3.1 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld1.3.2 关闭selinux
sed -i s/enforcing/disabled/ /etc/selinux/config # 永久
setenforce 0 # 临时 1.3.3 关闭swap …
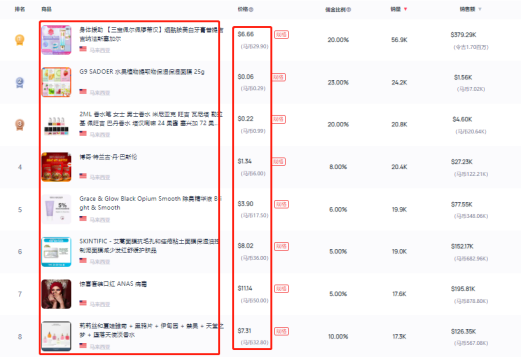
tiktok小店如何找到美妆爆品?(内附2月tiktok数据分析)
根据相关数据统计,2023年来全球美妆个护零售总额稳步增长。随着全球化加剧,越来越多的美妆个护品牌选择出海,寻找新的增长和变现机会。Tiktok的快速发展给这些美妆个护品牌提供了新的可能,打通了出海的新思路。同时对于出海的小店…
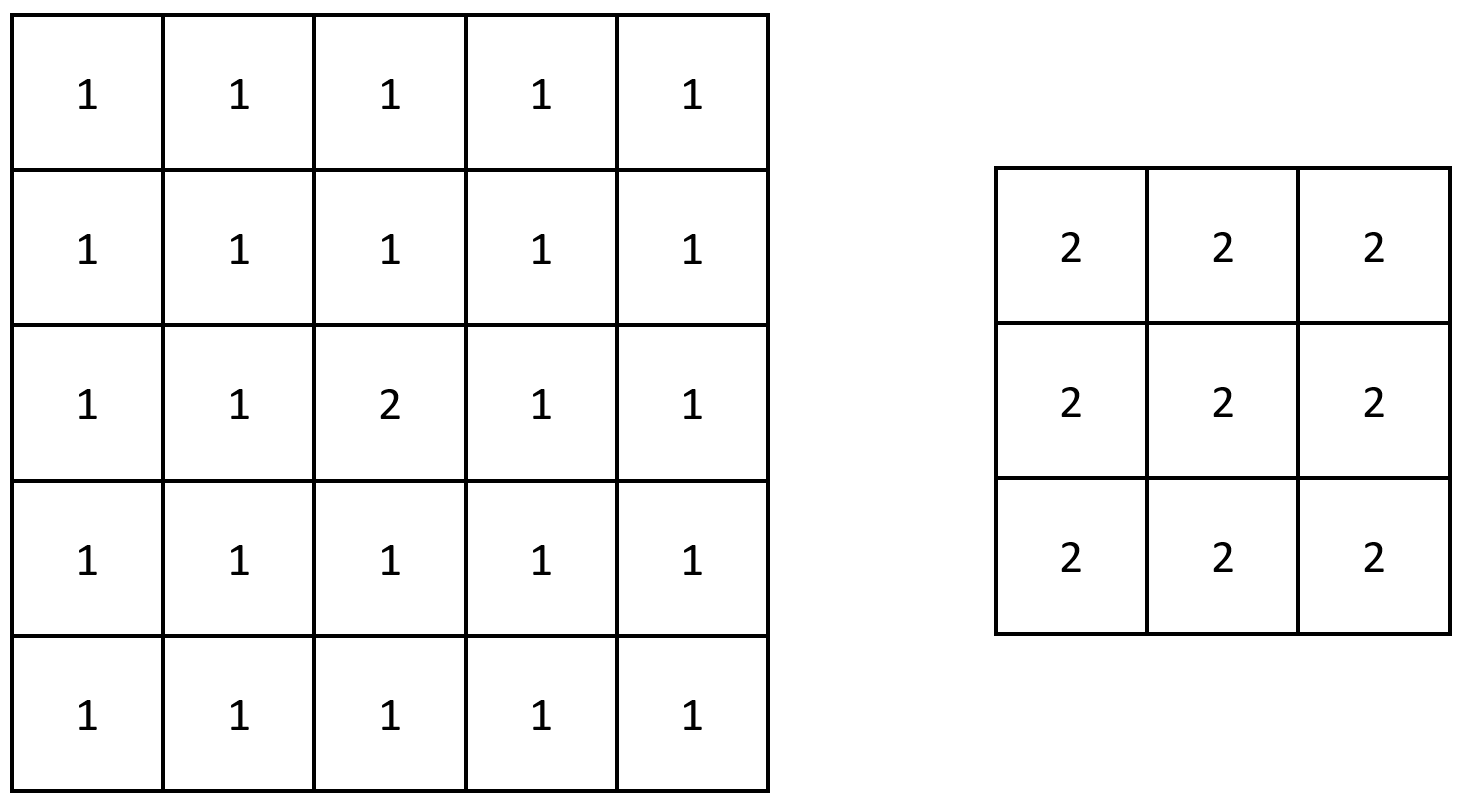
LeetCode 2373. 矩阵中的局部最大值
LeetCode 2373. 矩阵中的局部最大值
难度:easy\color{Green}{easy}easy 题目描述
给你一个大小为 nxnn x nnxn 的整数矩阵 gridgridgrid 。
生成一个大小为 (n−2)x(n−2)(n - 2) x (n - 2)(n−2)x(n−2) 的整数矩阵 maxLocalmaxLocalmaxLocal ,并满足…

解决Ubuntu虚拟机不能复制粘贴
安装虚拟机的时候就有点不顺,在填写用户名和密码的时候键盘敲不上字,重新又安装了几次才行,安装成功后发现不能复制粘贴主机的内容,这肯定不行啊,找解决方案,网上也有很多,有如下:重…
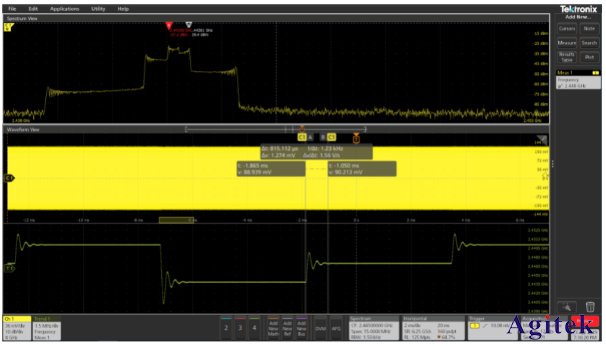
泰克示波器|MSO64示波器的应用
泰克新一代示波器MSO64为实例来讲解时频域信号分析技术。MSO64采用全新TEK049平台,不仅实现了4通道同时打开时25GS/s的高采样率,而且实现了12-bit高垂直分辨率。同时,由于采用了新型低噪声前端放大ASIC—TEK061,大大降低了噪声水平…
Springboot整合Easy-Es
版本说明
Springboot 2.7.5JDK 17Elasticsearch 7.14.0Easy-Es 1.1.1《点我进入Easy-Es官网》PS:目前Easy-Es暂不支持SpringBoot3.X
Windows10安装Elasticsearch
《安装Elasticsearch教程》
pom.xml
<parent><groupId>org.springframework.boot<…
SpringBoot集成Swagger3.0(入门)01
创建SpringBoot项目 创建完成后再pom文件中导入swagger3.0依赖,具体的pom文件内容如下:
<?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://w…

一看就懂 —— Spring boot + Spring MVC + MyBatis 基础框架demo
目录 前言
一、项目依赖
二、配置文件
三、创建数据库和实体类
3.1、创建数据库
3.2、创建实体类
四、构建 Mapper 层代码实现(接口 XML)
4.1、创建接口
4.2、创建 XML
4.3、XML 文件与接口的对应关系
五、实现服务层
六、实现控制器
小结 …

原生JS实现拖拽排序
拖拽(这两个字看了几遍已经不认识了)
说到拖拽,应用场景不可谓不多。无论是打开电脑还是手机,第一眼望去的界面都是可拖拽的,靠拖拽实现APP或者应用的重新布局,或者拖拽文件进行操作文件。
先看效果图&am…
动态IP与静态ip的区别是什么
1、DHCP IP即动态ip,可以自动获取IP地址。静态ip上网又被称为固定IP地址上网,需要手动设置IP地址。2、在网速上,动态ip和静态ip没有区别。3、动态ip不是一个真实的IP地址,静态IP是可以直接上网的IP地址。静态ip和动态ip设置方法&a…

Python3-列表
Python3 列表
序列是 Python 中最基本的数据结构。
序列中的每个值都有对应的位置值,称之为索引,第一个索引是 0,第二个索引是 1,依此类推。
Python 有 6 个序列的内置类型,但最常见的是列表和元组。
列表都可以进…