点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—>【计算机视觉】微信技术交流群
2023 年 2 月 28 日凌晨,CVPR 2023 顶会论文接收结果出炉!这次没有先放出论文 ID List,而是直接 email 通知作者(朋友圈好友纷纷晒截图,报喜讯~你被刷屏了没?!)。
CVPR 2023 主委会官方发布这次论文接收数据:有效投稿 9155 篇(比 CVPR 2022 增加12%),收录 2360 篇(CVPR 2016 投稿才 2145 篇),接收率为 25.78 %。

CVPR 2023 会议将于 2023 年 6 月 18 日至 22 日在加拿大温哥华(Vancouver)举行。这次线下参加人数一定会比去年多很多,因为将会有一大波国内的学者线下参加学术交流(公费旅游bushi)。

Amusi 简单预测一下,CVPR 2023 收录的工作中 " 扩散模型、多模态、预训练、MAE " 相关工作的数量会显著增长。
本文快速整理了10篇 CVPR 2023 最新工作,内容如下所示。如果你想持续了解更多更新的CVPR 2023 论文和代码,大家可以关注CVPR2023-Papers-with-Code,在CVer公众号后台回复:CVPR2023,即可下载,链接如下:
https://github.com/amusi/CVPR2023-Papers-with-Code
这个项目是从2020年开始,累计提交了600+次!Star数已经破万+!覆盖CVPR 2020-2023的论文工作,很开心能帮助到一些同学。
如果你的 CVPR 2023 论文接收了,欢迎提交issues~
Backbone
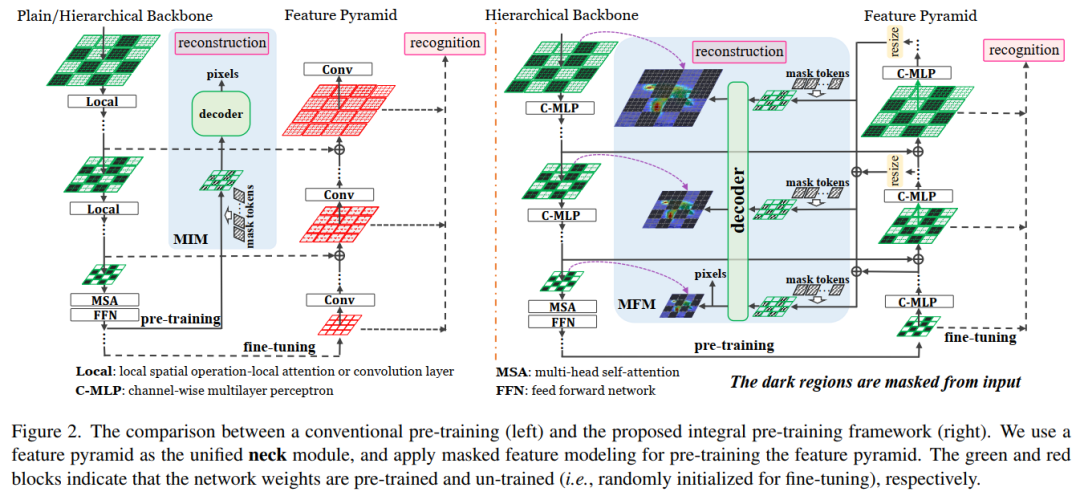
1. Integrally Pre-Trained Transformer Pyramid Networks
单位:国科大, 华为, 鹏城实验室
Paper: https://arxiv.org/abs/2211.12735
Code: https://github.com/sunsmarterjie/iTPN
本文提出整体预训练的ViT金字塔网络(iTPN):通过整体预训练主干和金字塔网络缩小上游预训练和微调的gap,表现SOTA!性能优于CAE、ConvMAE等网络,代码已开源!
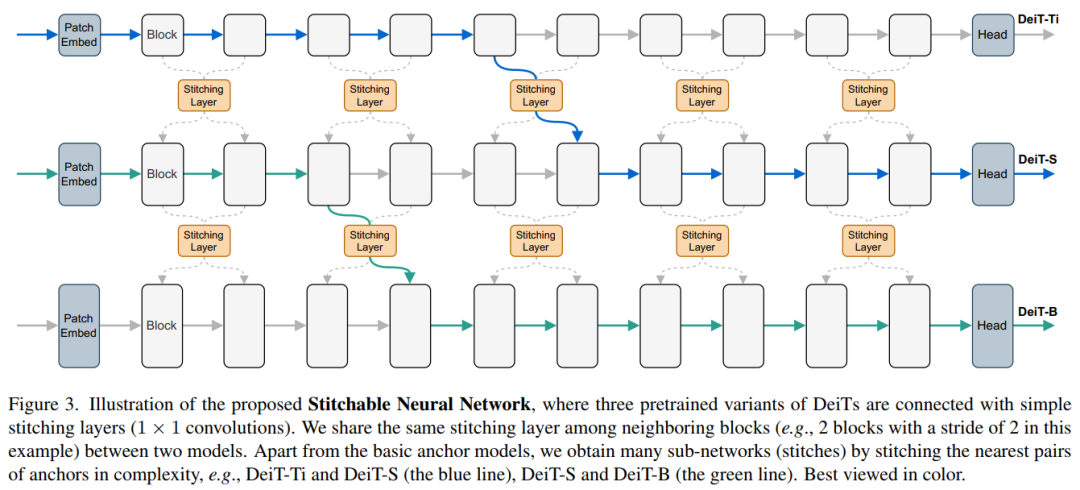
2. Stitchable Neural Networks
单位:蒙纳士大学ZIP Lab
Homepage: https://snnet.github.io/
Paper: https://arxiv.org/abs/2302.06586
Code: https://github.com/ziplab/SN-Net
Stitchable 神经网络(SN-Net):一种用于模型部署的新的可扩展和高效的框架,它可以快速地生成具有不同复杂性和性能权衡的大量网络,促进了现实世界应用的深度模型的大规模部署,代码即将开源!
MAE
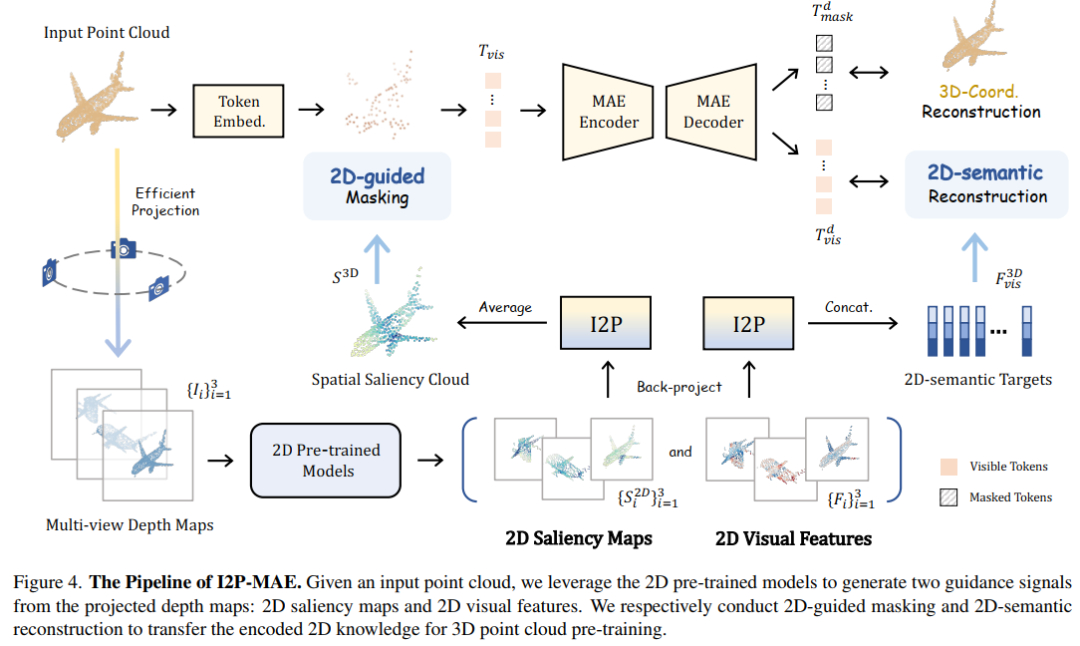
3. Learning 3D Representations from 2D Pre-trained Models via Image-to-Point Masked Autoencoders
单位:上海AI Lab, 港中大MMLab, 北大
Paper: https://arxiv.org/abs/2212.06785
Code: https://github.com/ZrrSkywalker/I2P-MAE
I2P-MAE:Image-to-Point掩码自编码器,一种从2D预训练模型中获得卓越的3D表示方法,在3D点云分类上表现SOTA(刷新ModelNet40和ScanObjectNN新记录)!性能优于P2P、PointNeXt等网络,代码即将开源!
NeRF
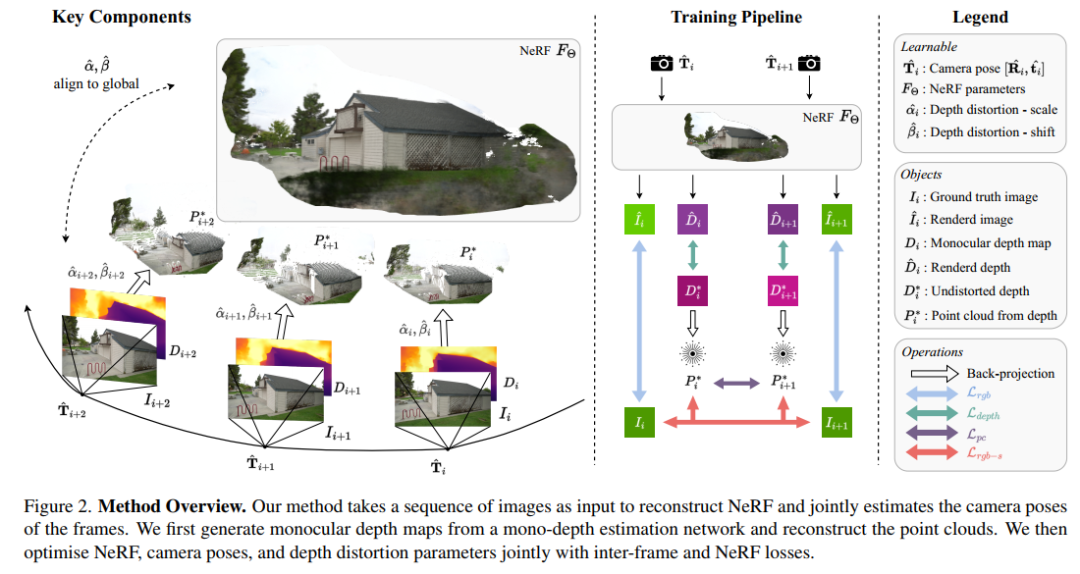
4. NoPe-NeRF: Optimising Neural Radiance Field with No Pose Prior
单位:牛津大学
Home: https://nope-nerf.active.vision/
Paper: https://arxiv.org/abs/2212.07388
Code: None
NoPe-NeRF:一个端到端可微模型,用于联合相机姿势估计和从图像序列中进行新颖的视图合成,在真实室内和室外场景上实验表明:此方法在新颖的视图渲染质量和姿态估计精度方面优于现有方法。
Diffusion Models(扩散模型)
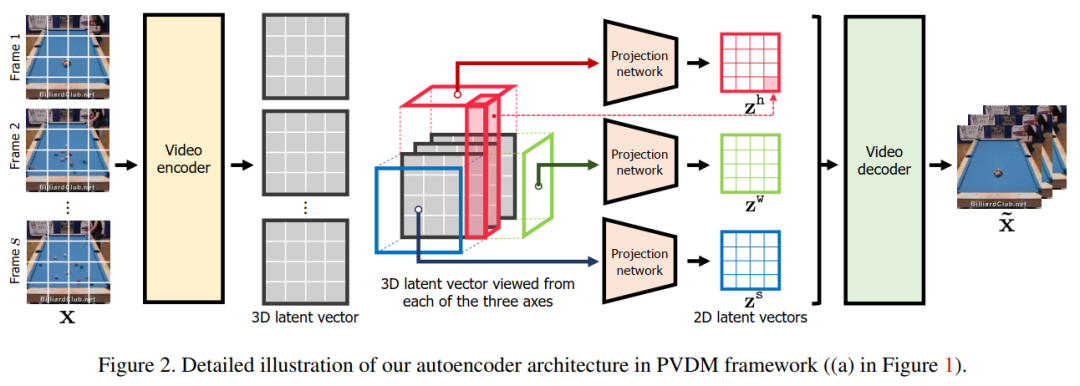
5. Video Probabilistic Diffusion Models in Projected Latent Space
单位:KAIST, 谷歌
Homepage: https://sihyun.me/PVDM/
Paper: https://arxiv.org/abs/2302.07685
Code: https://github.com/sihyun-yu/PVDM
据称PVDM:是第一个用于视频合成的latent扩散模型,它学习低维隐空间中的视频分布,可以在有限资源下使用高分辨率视频进行有效训练,以使用单个模型合成任意长度的视频,代码刚刚开源!单位:KAIST, 谷歌
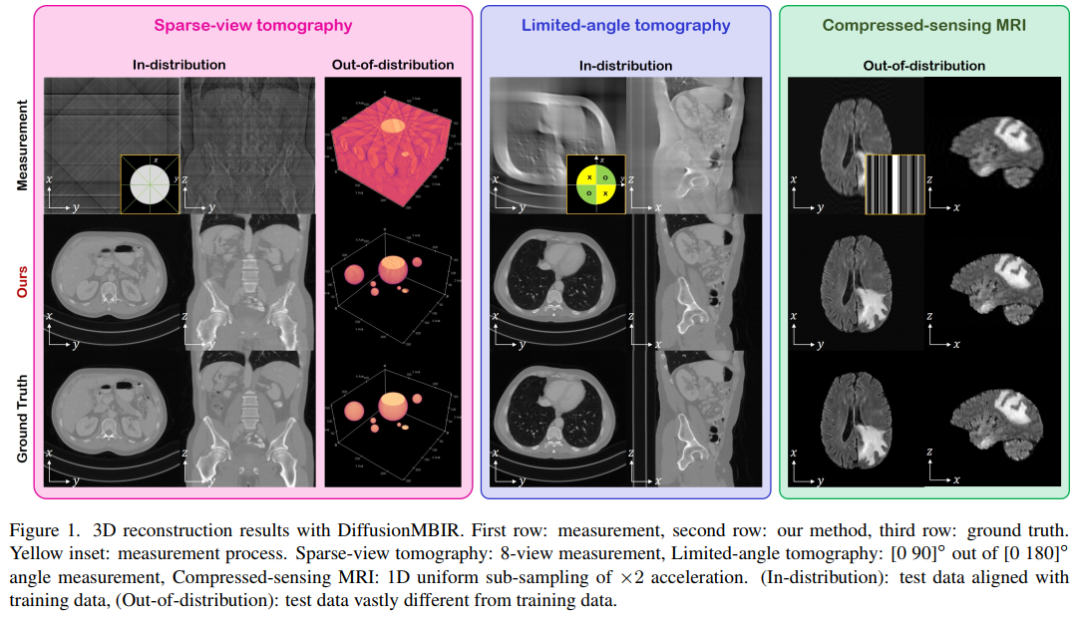
6. Solving 3D Inverse Problems using Pre-trained 2D Diffusion Models
单位:KAIST, 洛斯阿拉莫斯国家实验室
Paper: https://arxiv.org/abs/2211.10655
Code: None
本文提出DiffusionMBIR:一种用于3D医学图像重建的扩散模型重建策略,实验证明:其能够实现稀疏视图CT、有限角度CT和压缩感知MRI的最先进重建。
视觉和语言(Vision-Language)
7. GIVL: Improving Geographical Inclusivity of Vision-Language Models with Pre-Training Methods
单位:UCLA, 亚马逊Alexa AI
Paper: https://arxiv.org/abs/2301.01893
Code: None
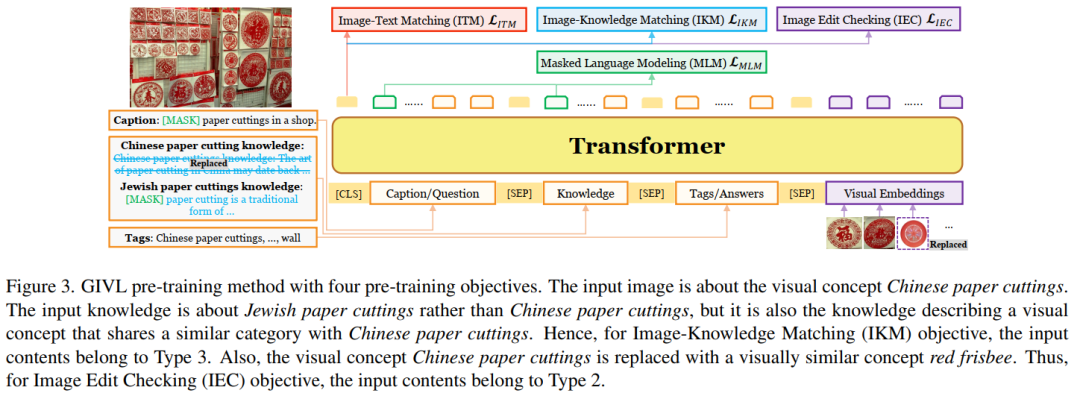
本文提出GIVL:一种地理包容性视觉和语言预训练模型,在地理多样化的V&L任务上实现了最先进的和更均衡的性能。
目标检测(Object Detection)
8. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
单位:YOLOv4 原班人马
Paper: https://arxiv.org/abs/2207.02696
Code: https://github.com/WongKinYiu/yolov7
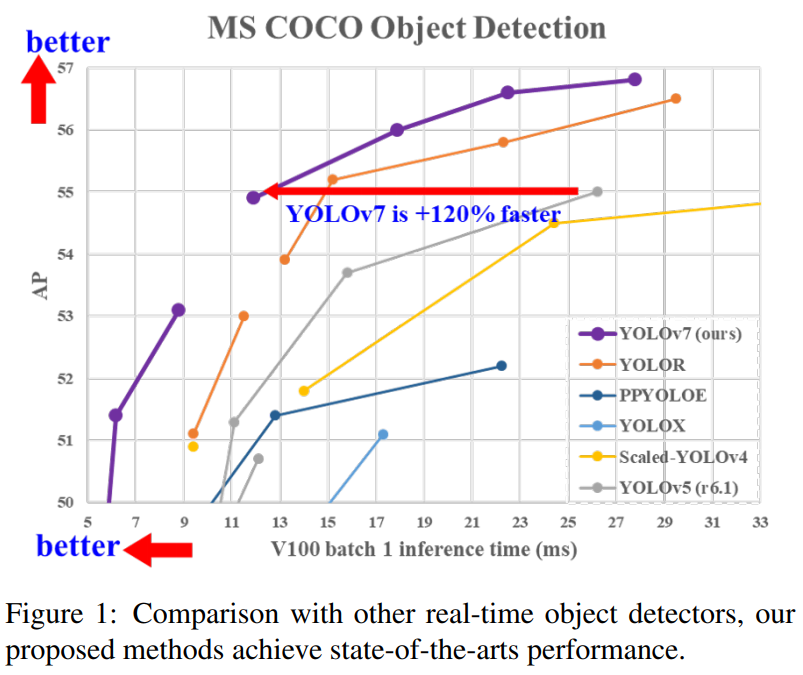
超越YOLOv5、YOLOX、PPYOLOE、YOLOR等目标检测网络!
9. DETRs with Hybrid Matching
单位:北大, 中科大, 浙大, MSRA
Paper: https://arxiv.org/abs/2207.13080
Code: https://github.com/HDETR
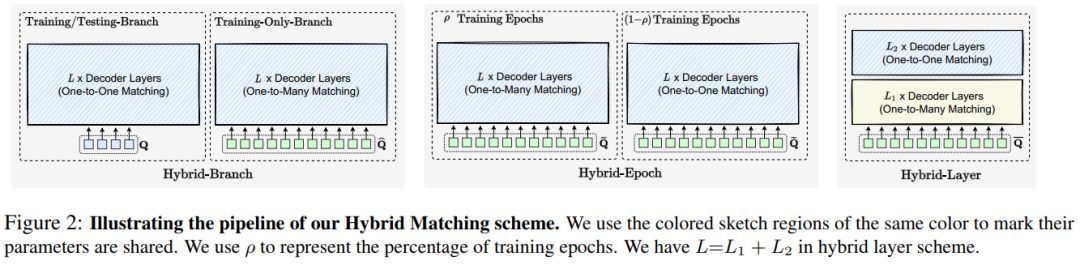
本文提出一种非常简单且有效的混合匹配方案,以解决基于 DETR 的方法在多种视觉任务(2D/3D目标检测、姿态估计等)上的低训练效率,并提高准确性,如助力PETRv2、TransTrack和可变形DETR等网络性能提升,代码已开源!
10. Enhanced Training of Query-Based Object Detection via Selective Query Recollection
单位:CMU, Meta AI
Paper: https://arxiv.org/abs/2212.07593
Code: https://github.com/Fangyi-Chen/SQR
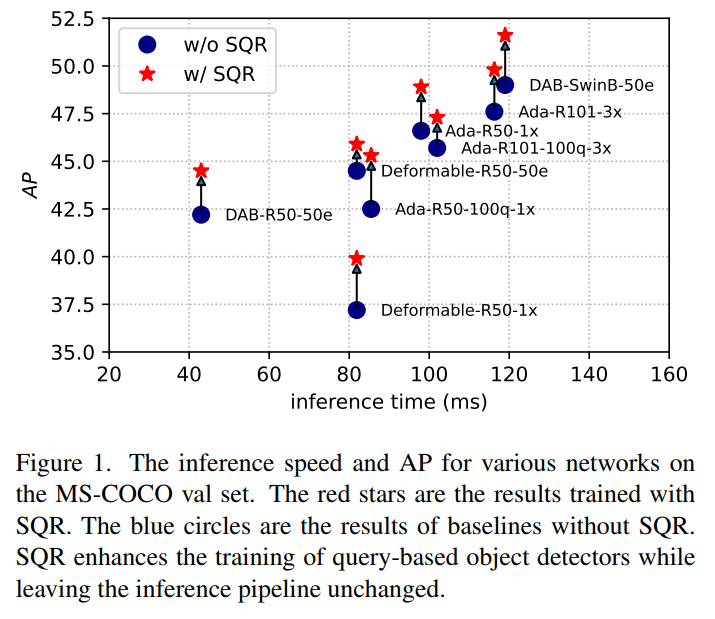
即插即用!本文提出选择性查询回忆(SQR):一种基于查询的目标检测器训练新策略,可以很容易地插入到各种DETR变体中,显著提高它们的性能,代码已开源!
点击进入—>【计算机视觉】微信技术交流群
最新CVPP 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看