说明
万丈高楼平地起
按照前面的规划,开始有序推进我的【15% 资金加速器】计划。这一步是通过某个源,获取分钟级数据,然后送到第一个ADBS。
Sniffer : 读取数据并发送到入队列。一开始我会把文件以离线形式上传到某个folder,所以sniffer读文件源,后续我会找到接口源。

嗯,先吐槽一下云服务商,去年的云主机价格贵了好多。腾讯1M的竟然500多一年,还算是几个大厂里面涨的少的。我觉得5M的500一年我还能接受,所以感觉是5倍的不值。
而且挺怪的是,IT设备一直在降价,内存条我一年前买4000块,现在是2千4;固态硬盘也差不多都在降。所以带宽反而涨咯?反正我觉得目前国内云服务市场的不那么市场,提升单价(而不是提升使用)是最容易摧毁这个市场的。曾经我还有考虑过建立云服务器集群,现在已经没这个想法了,有个2~3台就行,配置低的够用就行,还是走自建局域网比较靠谱。说起来我最早是搞光网络的,实在不明白这带宽是怎么提不上去的… 比造路造房子要简单很多啊,比5nm也要简单吧。
感恩的是国内还是有不少新的云服务商让薅羊毛,今天买了天翼云(看起来还是比较大方的)的一台5M主机,400多一年。大约在2个小时左右,我就完成了云主机的切换动作,以后大可以走开箱即用,过期即扔的策略。同一时刻只要有个2~3台就行了。
使用Jupyter的话,建议还是要5M的带宽,否则感觉等的时间太长了(估计是很多js之类的要下载)
内容
steady but firmly, I will made it
1 计划
嗯,话说又刷了一下网页,咻的一下就出来,爽的很,哈哈哈。
先建一个文件夹Step1DataETL, 之后启动了之后,新的数据就放在这里,而Sniffer也会去这里取数更新。初期在实操的时候采用手动的方式去下载和更新数据。
所以这次的任务包括两部分:
- 1 Action1:在jupyter中开发好ETL过程,算出结果
- 2 Action 2:在ADBS中将ETL过程复现,然后启动(多个)Worker去计算并校验
如同算法一样,在后续的步骤中都是如此。可能唯一的缺点是,这种运行方式需要在每一个时隙计算,所以会产生几十万次的数据库查询、计算,然后入库;不过庆幸的是,即使是这种情况,由于计算主要发生在局域网内,甚至是单个主机内,所以开销并不大。而且,这种全量计算相当于建立installed base只是进行一次,最多花费1天(?),之后都是秒级完成。
2 从某量化平台获取实验数据
我选择 沪深300ETF(510300)作为研究标的,具体原因就不解释了,反正我觉得可以。
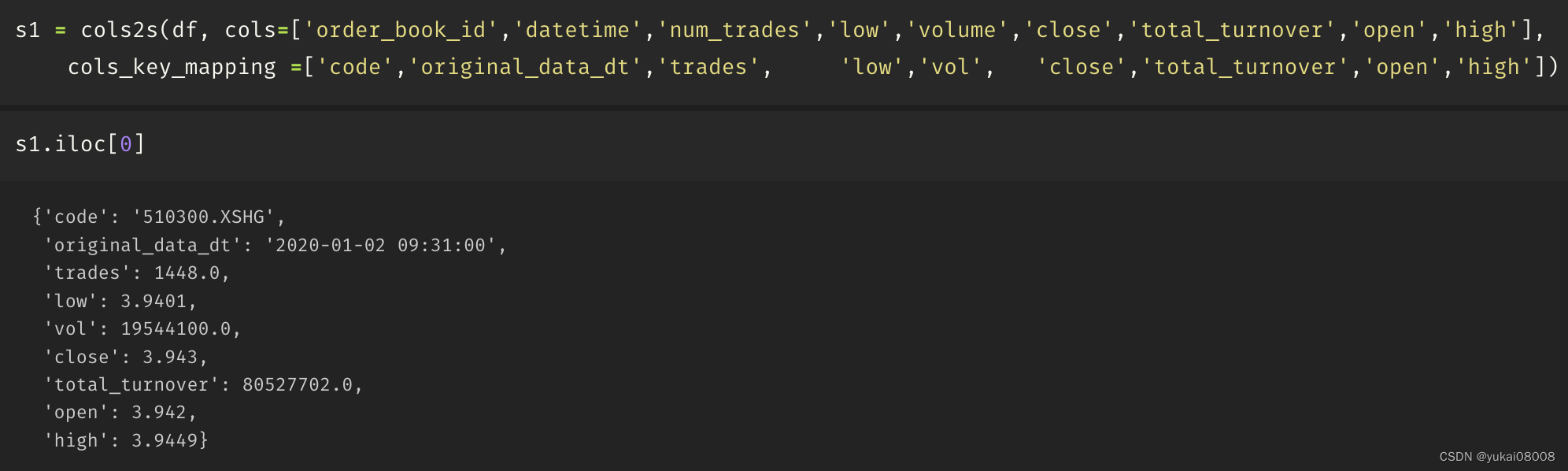
Data looked like this :
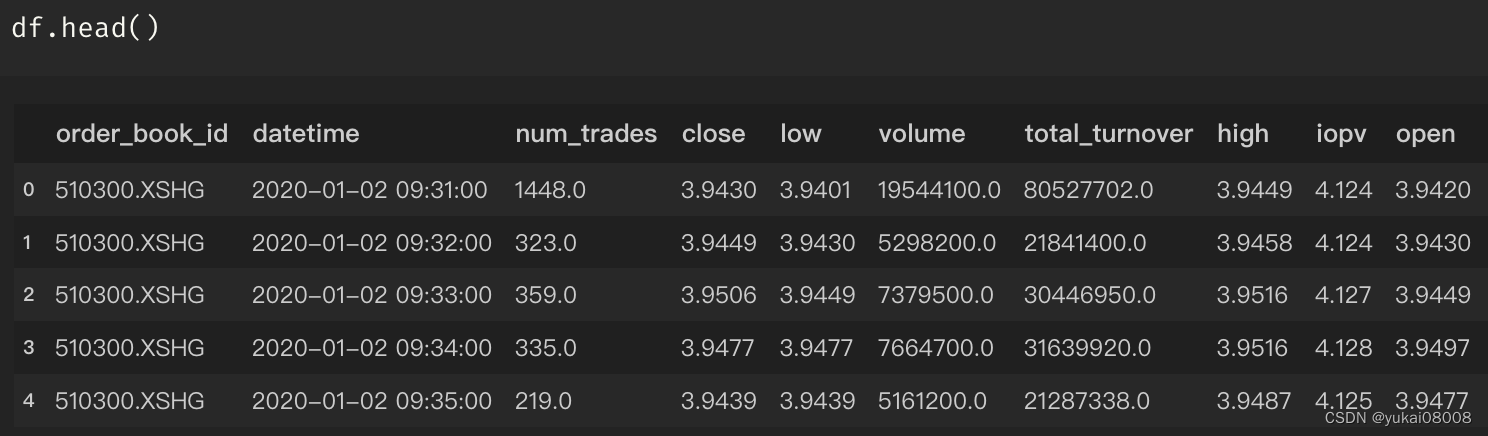
所以sniffer要做的事就是将数据简单清洗后送到入队列,主要包括了主键计算,计算时隙,变量名称映射等。
Step1中的ETL要做的主要任务是根据周期,计算出若干通用的基础特征, that’s all。

3 Sniffer Part
读取数据然后将最新的部分刷新到队列
- 1 有一个文件夹,里面会放入若干文件
- 2 有一个缓存,记得已经读取过哪些文件(Redis - Mongo)
- 3 读取最新时隙
- 4 读取最新的文件,然后将主时隙之后的新数据存入队列
3.1 数据库集群-缓存
这里需要有一个元数据缓存,可以使用mymeta集群来存储。主要的考虑是这个元数据库集群可以在公网上访问,并且传输的数据很小,这样对带宽也没什么压力。
关于这个公网集群的设计上,有两点需要注意/改进点。
在服务端,日志还是会不断膨胀,可以考虑在容器的启动时,不特别存储日志,而是通过docker自动管理日志的删减。
在使用端,要考虑到允许硬刷新的方式来重新建立连接,这样数据库集群的地址即使变了也不必担心。这个是需要埋在各个项目的设计里的。
本次的实验暂时不考虑数据库方面的改动,但是在使用时会使用Redis + Mongo的缓存读取方式。
- 1 在Redis中创建唯一的缓存名称
- 2 在Mongo集群中设立缓存表(Buffer.SnifferRedisMongo)
- 3 数据刷新时同时向Redis(+TTL)和Mongo更新
- 4 读取时优先从Redis读取, 如果没有数据则向Mongo读取,并将数据同步写入Redis + TTL
在Redis中创建唯一的缓存名称
缓存变量的命名按照 3X3的方式
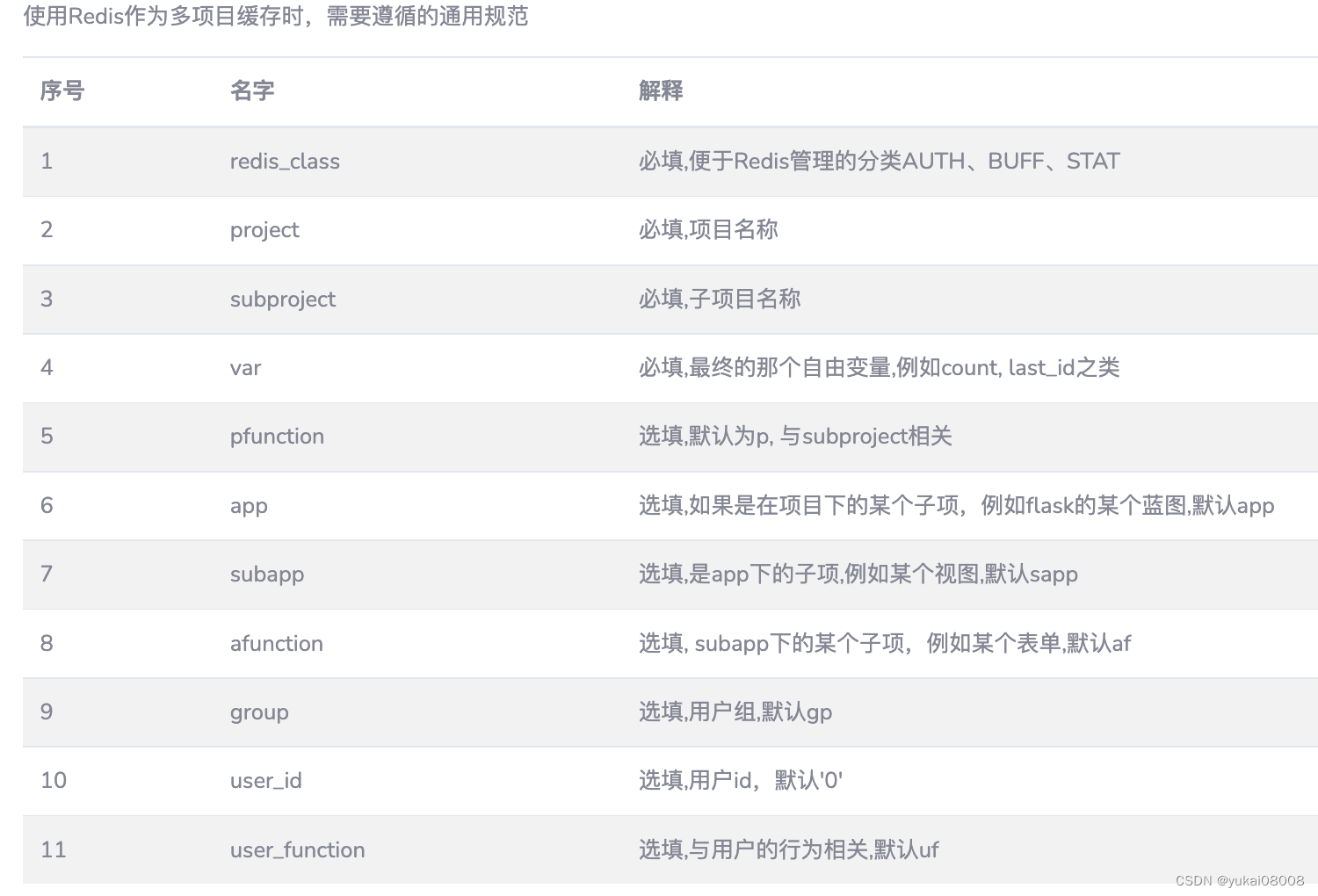
必填的参数
- redis_class: BUFF 缓存类
- project : microservice
- subproject: Quant
- app: data
- subapp: Step1ETL
- var: buffer_dict
通过RedisAgent来创建变量,会同时检查冲突(当前是否已经有了)
BUFF.microservice.Quant.pf.data.Step1ETL.af.gp.0.uf.buffer_dict
redis_agent_host = 'http://172.17.0.1:24021/'
redis_buff_var = {'redis_class':'BUFF','project':'microservice','subproject':'Quant',
'app':'data','subapp':'Step1ETL','var':'buffer_dict'}
req.post(redis_agent_host + 'redis_naming_test/',json = redis_buff_var).json()
{'data': None,
'msg': 'NOT Existed, <<<<<< BUFF.microservice.Quant.pf.data.Step1ETL.af.gp.0.uf.buffer_dict',
'status': True}
在Mongo集群中设立缓存表(Buffer.SnifferRedisMongo)
本质上这个是为了更好的支持Redis的持久化创建的:我希望每个在内存中的变量都有ttl,同时也希望当再次需要时可以容易的再进入内存。
这样的连接还是比较有意思,直接就可以创建连接了
cur_machine = get_machine_name()
cur_machine='m7'
print('Current Machine', cur_machine)
w = WMongo('w')
target_server = 'mymeta'
cur_w = w.TryConnectionOnceAndForever(server_name =target_server)
Wmongo_v9000.012
设置当前连接 local
>>> Switching To Mymeta
设置当前连接 local
在CN001访问mymeta,通用
当前机器的名称: 48831f790d1d
1.当前使用的MongeAgent:http://172.17.0.1:24011/
2.Tier1:meta, Tier2:servers
3.ConnectionHash:e8d1bc791049988d89465d5ce24d993b
4.FilterDict:{'my_server_pkey': 'mymeta'}
5.Limits:1
6.Sort:
7.Skip:0
>>> Hit Records
当前机器的局网: None
【I】目标服务的机器:Clulster, 目标服务的机器局网:NO_LAN
【I】采用wan方式连接目标主机
Wmongo_v9000.012
设置当前连接 local
此时建立连接
target connection hash: 38aeabac8113f89488d5f530dca85827
接下来只要设置好两个变量就可以
| 序号 | 变量名 | 解释 |
|---|---|---|
| 1 | redis_var_key | 存储在redis中的键,索引 |
| 2 | redis_var_val | 存储在redid中的值 |
这个函数多创建了几个索引,但都属于默认的索引
tier1 ='Buffer'
tier2 ='SnifferRedisMongo'
index_var = 'redis_var_key'
cur_w.ensure_mongo_index(tier1 =tier1, tier2 =tier2, key_index=index_var)
{'data': {'redis_var_key': 'Not Existed and Created'}, 'msg': 'ok', 'status': True}
{'data': {'_is_enable_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True}
{'data': {'_create_time_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True}
{'data': {'_update_time_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True}
{'data': {'_ch001_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True}
{'data': {'_ch001_cnt_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True}
读取最新时隙
这个在刚开始其实并不能读到(表内为空),可以先试一下连接,然后就要往里面灌数据了,然后才能继续测试这个功能。
# 读取redis变量
redis_var_name = 'BUFF.microservice.Quant.pf.data.Step1ETL.af.gp.0.uf.buffer_dict'
ttl = 10000
buffer_mongo_name = 'mymeta'
buffer_mongo_w = from_pickle(buffer_mongo_name)
buffer_mongo_tier1 = 'Buffer'
buffer_mongo_tier2 = 'SnifferRedisMongo'
# 1 直接读取
buffer_dict = req.post(redis_agent_host + 'getv/',json ={'k':redis_var_name}).json()['data']
print('[1]直接从redis读取 buffer_dict', buffer_dict)
# 2 如果为空则去mongo读取
if buffer_dict is None :
print('[2]向mongo发起查询 buffer_dict')
buffer_data_list = buffer_mongo_w.query_recs(tier1=buffer_mongo_tier1, tier2 = buffer_mongo_tier2,
filter_dict ={'redis_var_key':redis_var_name},silent=True)['data']
if len(buffer_data_list):
print('[3]查询到结果,并重新写入redis')
buffer_dict = buffer_data_list[0]['redis_var_val']
# 设置新的buffer变量
resp_dict = req.post(redis_agent_host + 'setv/',
json ={'k':redis_var_name,
'v':buffer_dict,'ex_seconds':ttl}).json()
if resp_dict['status']:
print('[4]写入redis成功')
else:
buffer_dict = {}
buffer_dict['already_read_files'] = []
# 当前的文件列表
cur_data_files = [x for x in os.listdir(data_path) if not x.startswith('.') or x.endswith('.csv')]
# 缓存中的文件列表
buffer_data_file = buffer_dict['already_read_files']
# 本次要读取的差集
gap_files = sorted(list(set(cur_data_files) - set(buffer_data_file)))
print(gap_files)
[1]直接从redis读取 buffer_dict None
[2]向mongo发起查询 buffer_dict
['510300_20230215.csv']
到这里又是一个小段落,关于程序所需要使用的缓存(Redis和Mongo)方法。
接下直接对于数据进行处理,按照要求将原始数据转为一下字段:
先从量化平台下载数据
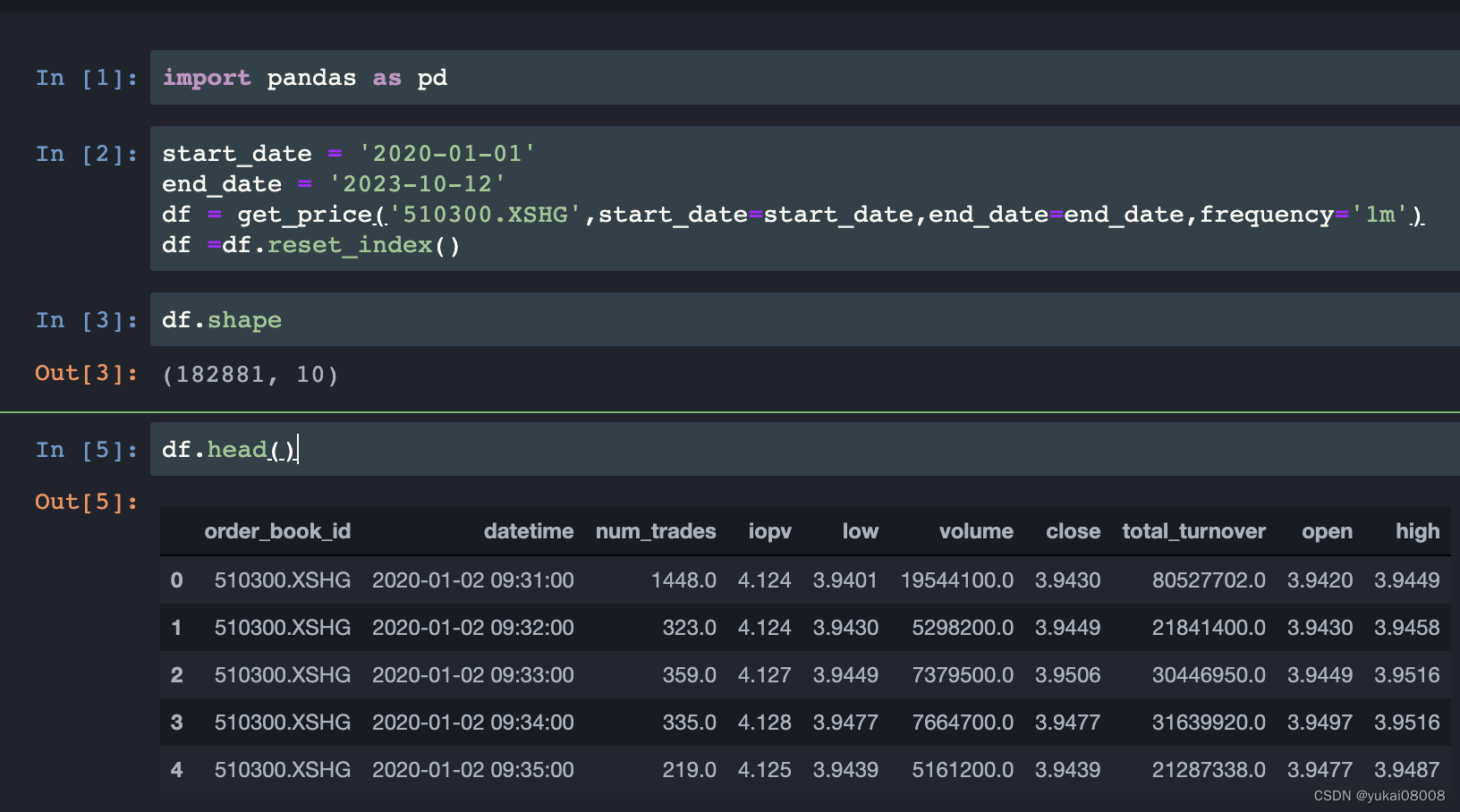
然后进行一些变换:
- 1 变量的筛选/映射
采用简单的映射,这看起来有点像AETL,但我不想让这步操作过于规范化。最主要是因为这步是负责接入的,逻辑很简单,但是变化又很多。而AETL最好基于一些固定的Base进行操作。
- 2 其他变量的增加/计算
# 将沪深300增加对应的字段
def sniffer_work(some_dict):
res_dict = {}
res_dict['market'] = 'SH'
res_dict['data_slot'] = ts2ord(inverse_time_str(some_dict['original_data_dt']))
res_dict['data_dt'] = slot_ord2str(res_dict['data_slot'] )
res_dict['code'] = some_dict['code'].replace('.XSHG','')
# 计算主键
res_dict['rec_id'] = '_'.join( [ str(res_dict['market']),str(res_dict['code']),str(res_dict['data_slot']) ])
# 其他价格
res_dict['open'] = some_dict['open']
res_dict['close'] = some_dict['close']
res_dict['high'] = some_dict['high']
res_dict['low'] = some_dict['low']
res_dict['vol'] = some_dict['vol']
res_dict['amt'] = some_dict['total_turnover']
res_dict['trades'] = some_dict['trades']
return res_dict
主要是校验一下数据时间是否一致(因为做了统一的时隙转换)
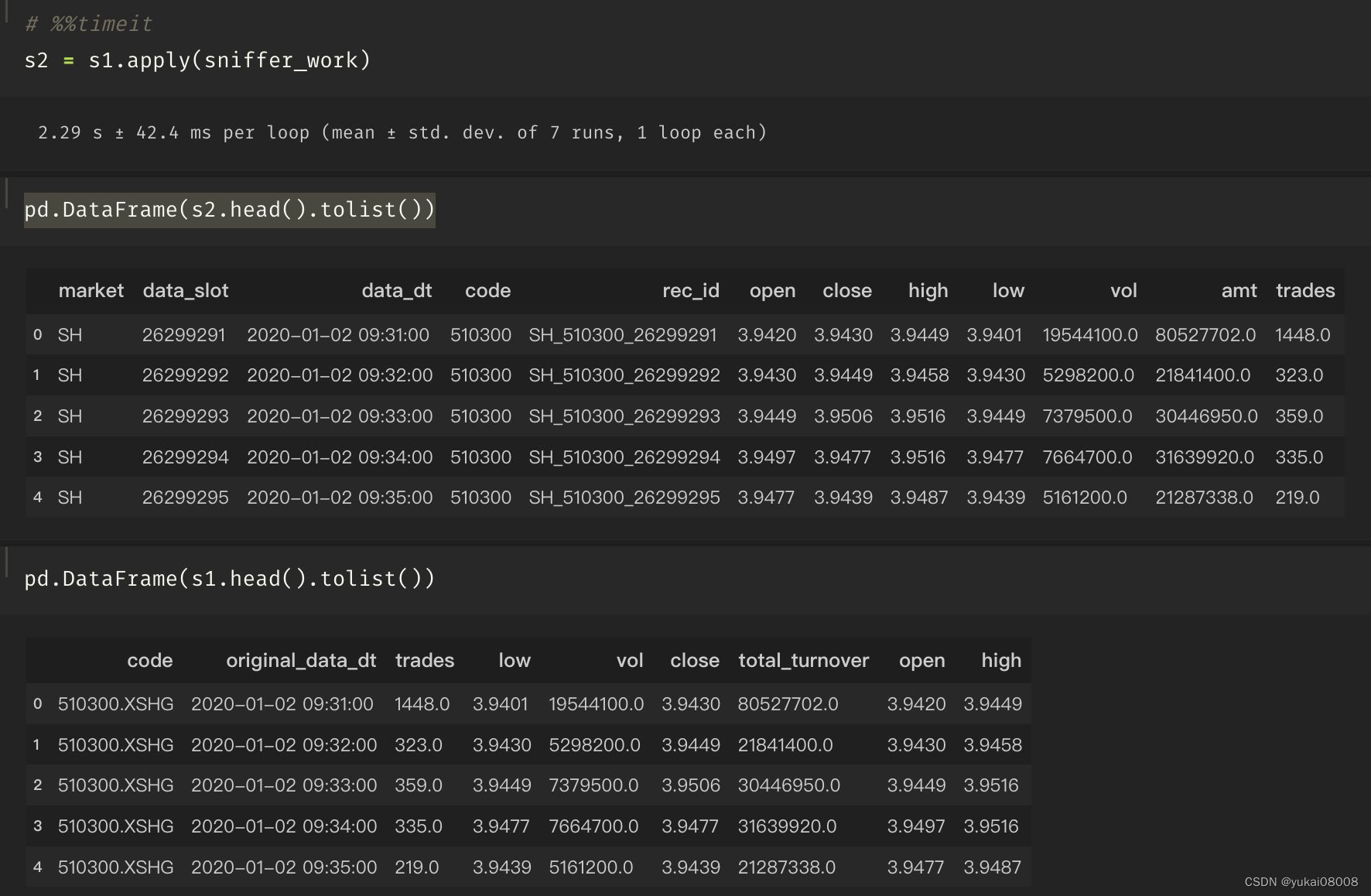
- 3 数据投送
sniffer在处理好数据之后,就要向入队列发送。在此之前,我先试一下读取「当前已处理」的最大时隙,看看如果没有缓存的时候如何处理。
在处理完成后,就要给redis和mongo进行缓存变量的更新,包括当前处理的文件名和「当前已处理」最大时隙。
碰到了一个幺蛾子,感受上特别毁三观,记录一下。
1. 换了frp服务器,当时比较忙,没有在portal上修改ip,但是以为改了
2. 写入数据后发现portal的页面不刷新数据条数
3. 看到monto 3T上显示数据服务,但是没有表了
第一反应是程序出bug了,还是首先怀疑自己
第二反应是磁盘掉了,怀疑pcie转接
第三反应是xfs格式化的问题
很惶恐,我的微服务、底层数据库啊
...
最后发现,是没有改地址。忙过头了,自己吓自己。
因为队列长度十万的限制,所以分两次写入数据
# 获取已处理的时隙
already_done_data_slot = buffer_dict.get('already_done_data_slot') or 0
sel = handled_df['data_slot'] >already_done_data_slot
submit_df = handled_df[sel]
project_name ='MyQuantBase'
gs_id = 'rec_id'
step1_stream_in = 'step1_stream_in'
step1_stream_workin = 'step1_stream_workin'
step1_stream_workout = 'step1_stream_workout'
step1_mongo_in = 'step1_mongo_in'
step1_mongo_out = 'step1_mongo_out'
step1_mongo_meta = 'step1_mongo_meta'
full_name_step1_stream_in = '%s.%s' % (project_name,step1_stream_in)
print(full_name_step1_stream_in)
# 第一部分(不超过10万条)
part1_df = submit_df.iloc[:90000]
part2_df = submit_df.iloc[90000:]
part1_listofdict = part1_df.to_dict(orient='records')
part2_listofdict = part2_df.to_dict(orient='records')
resp = req.post(redis_agent_host + 'batch_add_msg/',
json ={'stream_name':full_name_step1_stream_in,'msg_dict_list':part1_listofdict,'maxlen':100000}).json()
resp = req.post(redis_agent_host + 'batch_add_msg/',
json ={'stream_name':full_name_step1_stream_in,'msg_dict_list':part2_listofdict,'maxlen':100000}).json()
print(resp)
最后更新缓存
buffer_dict['already_read_files'].append(gap_files[0])
buffer_dict['already_done_data_slot'] = int(submit_df['data_slot'].max())
resp_dict = req.post(redis_agent_host + 'setv/',
json ={'k':redis_var_name,
'v':buffer_dict,'ex_seconds':ttl}).json()
redis_buffer_dict = {'redis_var_key':redis_var_name,'redis_var_val':buffer_dict}
w = WMongo('w')
target_server = 'mymeta'
try:
cur_w = from_pickle(target_server)
color_print('【Loading cur_w】from pickle')
except:
w = WMongo('w')
cur_w = w.TryConnectionOnceAndForever(server_name =target_server)
to_pickle(cur_w, target_server)
tier1 ='Buffer'
tier2 ='SnifferRedisMongo'
cur_w.insert_or_update_with_key(tier1 = tier1, tier2 = tier2, data_listofdict = [redis_buffer_dict], key_name='redis_var_key')
在Mongo里有了就不会掉了

4 AETL Part
这部分用来生成基础变量,这些变量是生成交易信号的基础。
按AETL的规范,从实例开始,构建指标计算
注意,原来的Dummy处理是不对的,要按照顺序来(默认的Dummy处理的是非时序数据)。也要确保统计的周期足够。
这部分的调试要放在终端中进行,这样可以直接取数。
任务通道:默认的情况下ABDS会创建一个通道「_ch001」,Dummy也在使用这个通道进行任务的流转。
Redis队列里里的每个元素是什么?
**这个概念需要明确一下,Redis队列里,一条数据有时是数据,有时候也可以是任务。**例如,当用户发起一系列实体解析请求时,每条数据可能是一段文字,那么Worker可以一次获取n条处理。在当前场景下,因为每个任务的取数实际上是rolling的,如果把数据都放进队列是不合适的,所以每条数据实际上是一个任务。
Worker每次提取一个任务,根据任务中的data_slot,追溯过去n个周期的数据,然后进行计算、更新。以本次为例,最大的回顾周期是24000,所以Worker在获得当前任务的数据时隙后,向Mongo发起取数,然后在获得的数据内进行各种计算。
从本质上说,这种方式是将pandas rolling的动作延展到了队列上,最大的好处是提供了持久化的工作机制,同时也提供了超大型计算的基础(通过数据库存放超大型数据,每次任务所提取的数据是相对小的)。
接下来,使用终端进行Worker的开发:
核心的转换部分
max_T = max(T_list)
print('最大回顾周期',max_T)
recs = cur_w.query_recs(tier1 = tier1, tier2 = tier2,filter_dict = {'$and':[{'market':'SH',
'code':code}]},limits= max_T, sort_tuple_list = [('data_slot',-1)])['data']
# print(len(recs))
# 如果有充足的数据才计算
res_dict = {}
if len(recs) == max_T:
res_df = pd.DataFrame(recs).sort_values(['data_slot'])
for T in T_list:
res_dict['open_T_%s' % T] = float(res_df.iloc[-T]['open'])
res_dict['high_T_%s' % T] = res_df.iloc[-T:]['high'].apply(float).max()
res_dict['low_T_%s' % T] = res_df.iloc[-T:]['low'].apply(float).min()
res_dict['vol_T_%s' % T] = res_df.iloc[-T:]['vol'].apply(float).sum()
res_dict['amt_T_%s' % T] = res_df.iloc[-T:]['amt'].apply(float).sum()
res_dict['trades_T_%s' % T] = res_df.iloc[-T:]['trades'].apply(float).sum()
res_dict['vol_T_mean_%s' % T] = res_df.iloc[-T:]['vol'].apply(float).mean()
res_dict['amt_T_mean_%s' % T] = res_df.iloc[-T:]['amt'].apply(float).mean()
res_dict['trades_T_mean_%s' % T] = res_df.iloc[-T:]['trades'].apply(float).mean()
res_dict['close_T_mean_%s' %T] = res_df.iloc[-T:]['close'].apply(float).mean()
结果如下:
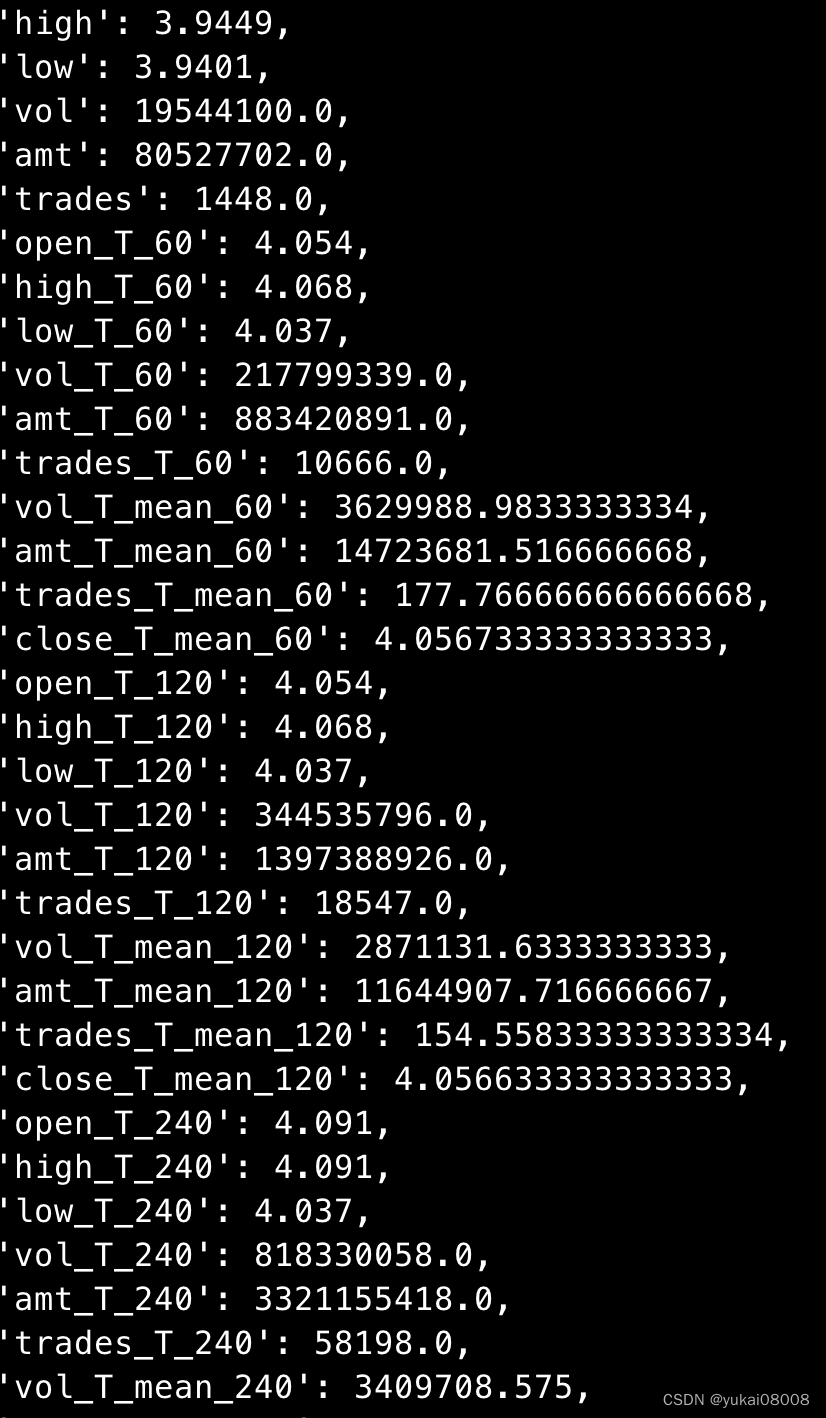
这样就可以了,接下来就是最后一部分工作,整合并运行。
仔细配置了Worker,设置了一些索引之后,开始正式运行。跑一天我观察一下结果再看看是否要调整。
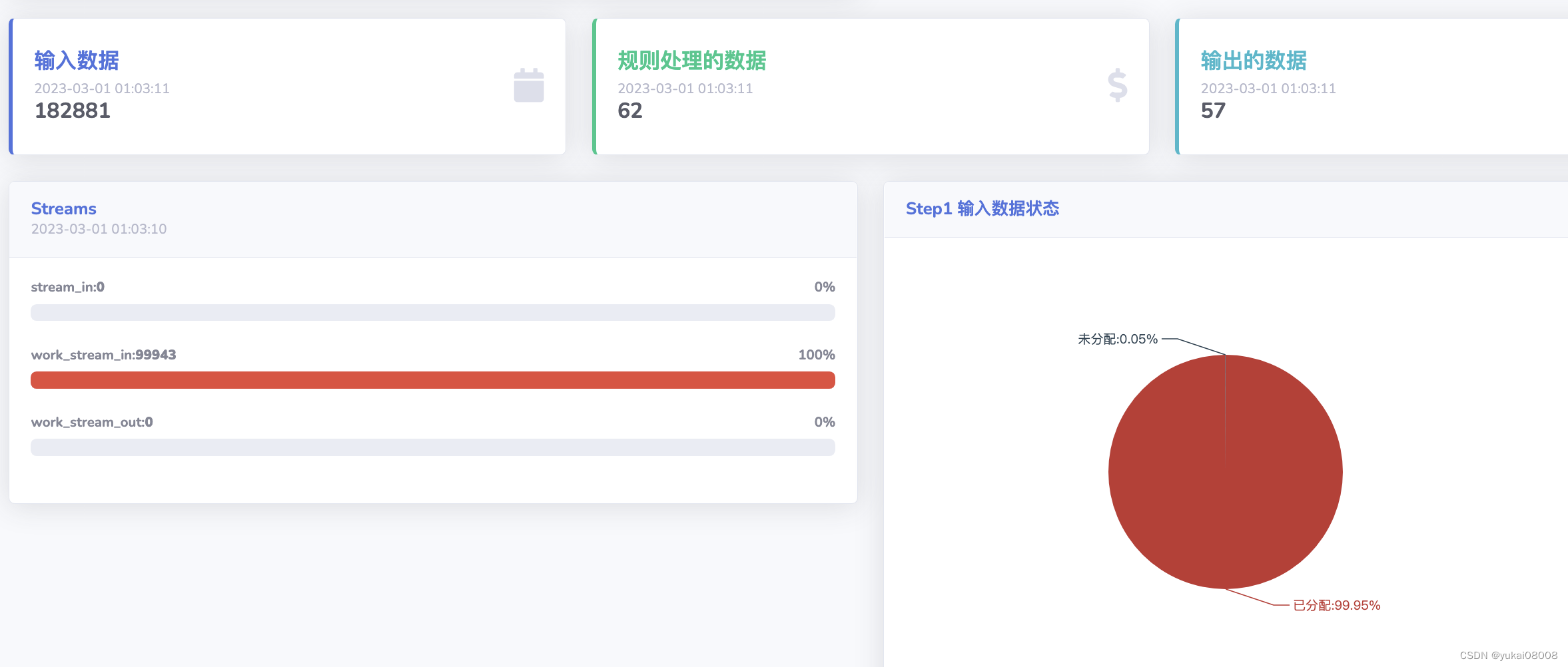
看起来是正常的