面经
HDFS读写流程
1.读流程
- 客户端向NameNode发起读请求
- (如果存在)NameNode返回一批block地址
- 客户端与第一个block的拓扑距离最近的节点建立连接以packet(64kb)的单位读取数据块。
- 一个block读取完成后客户端会断开与该DataNode的连接,然后与下一个数据块的最近节点建立连接。
- 所有数据块读取完成后会在客户端拼接为一个完整的文件。
- 如果在读取过程中一个节点读取出错,客户端会去读取下一个拓扑距离最近的节点,该节点不再连接。
2.写流程
- 客户端向NameNode发起写入操作请求,NameNode对请求进行检测:文件是否已存在,父目录是否已存在,是否有权限进行写入。返回检查结果。
- 客户端将文件切分为128M大小的Block,向NameNode请求上传第一个Block
- NameNode返回一个DataNode集合(拓扑距离排序)
- 客户端与距离最近的DataNode通过RPC调用建立连接,后续节点通过同样的方式建立连接形成pipeline。
- 客户端将第一个数据块读入缓存中,在缓存中将数据块切分为大小为64kb的packet,数据以packet的形式在pipeline上传输。
- 数据块传输完毕后会在pipeline上反向传输ack,最终由DataNode1将确认消息ack传给客户端
- 重复以上步骤直到所有数据块传输完毕。
NameNode HA的实现原理
NN的HA主要由两个机制实现:共享editLog机制和ZKFC对namenode状态的控制
共享editLog机制:HA中有多台NN节点,其中有一台为ActiveNN,其他的节点为StandbyNN。Active节点负责对外界提供读写服务,并将操作日志向共享文件系统(QJM,NFS)进行同步,standby节点负责从共享文件系统中同步数据,以便于active节点异常时快速恢复。当active节点宕机或与共享文件系统连接超时时,共享文件系统会对该NN进行fencing,避免发生脑裂。DN需要向所有NN都发送数据块处理报告。为了实现热备,每个NN上都运行了一个轻量级故障转移控制器zkfc。
ZKFC对NameNode状态控制:
主要由两个组件实现:HealthMonitor,ActiveStandByElector
HealthMonitor:负责监视NN的状态。一旦NN的状态发生变化,HM会回调zkfc注册的方法进行主备选举。
ActiveStandByElector:主要负责主备选举,内部封装了zookeeper的处理逻辑。选举完成后会回调zkfc注册的方法进行主备切换。
整体流程:NN启动时会启动一个zkfc进行故障转移。zkfc启动时会初始化一个HealthMonitor,HM定时对NN的状态进行监控,一旦发现NN状态变化,就会回调zkfc注册的方法进行处理。如果需要进行选举,会由ActiveStandByElector与zookeeper进行交互实现主备选举。选举完成后ASE通过回调zkfc注册的方法对NN状态进行更改,从Active/Standby转换为StandBy/Active。
联邦机制
NameNode的联邦机制是用于对NameNode进行横向扩展,解决NameNode的内存瓶颈问题的。
由于NameNode对外提供服务的时候会将fsimage和edits文件加载至内存,所以NameNode的内存瓶颈问题主要是由于数据量过大。这里我们可以采用的解决方案:1.处理小文件
2.减少副本数量 3.增大block大小 4.硬件扩展,增加堆内存大小或者直接对NameNode进行联邦。
联邦的原理:
由于单个NameNode的内存有限,当数据量非常大或者访问量非常大时可能会导致内存不够出现OOM,主要以socketconnect out of time即DataNode与NameNode的连接超时表现出来。联邦的功能便是通过多个NameNode,对NameNode进行横向扩展,将NameNode的namespace进行分块实现。每个namespace互相独立提供服务(HA中使用的是同一个namespace),对数据块池不做划分。DataNode需要向所有的NameNode注册,并周期性的发送心跳以及块处理报告。执行来自所有NameNode的命令。
优点:处理了内存限制;提高了吞吐量;提供了隔离性
缺点:单点故障未处理;负载均衡问题;
Reduce是如何获得Map输出的分区文件的?
Reduce拉取
Kafka如何实现顺序消费
kafka的topic分区的作用就是提高消费效率,对应的读取方式也是多线程读取,这样自然就无法保证topic维度有序,如果需要实现顺序消费topic,就要对生产者/服务端/消费者三端做以下约束:
1.生产者端保证将数据写入一个分区(可以通过只创建一个分区或者通过指定key写入一个分区内)。
2.服务端创建只有一个分区的topic,开启幂等性来避免重传机制引起的乱序。
3.消费者端用一个线程从一个分区内读取数据
Spark Streaming消费Kafka的两种方式比较。如何提高Spark Streaming消费Kafka的并行度?
1. 基于Receiver的方式
这种方式是通过Receiver来被动接收数据。Receiver是基于Kafka的高级API来实现的。Receiver从kafka中获取的数据存储在Spark的Executor内存中(如果数据量暴增,batch堆积可能会导致OOM)然后等待Streaming job的处理。这种情况下如果spark出错,很容易造成数据丢失。这里就要开启WAL(Write Ahead Log)预写日志机制机制。这种机制会在接收到Kafka数据的同时将数据写入hadoop上的预写日志中,就算发生错误也可以通过日志恢复
2. 基于Direct的方式
这种方式是由计算的Executor来主动拉取数据,速度由自身控制。这种方式会周期性的访问Kafka来获取每个topic+partition的最新offset,从而划分每个batch的offset范围。当处理任务的job启动后,就会直接使用kafka的简单api来直接获取Kafka指定范围offset的数据。
对比
Receiver的方式通过Kafka高阶API在ZooKeeper中保存offset,是这是消费Kafka的传统方式。这种方式配合WAL机制可以保证数据零丢失的高可靠。但是无法实现只处理一次,因为Spark和Zookeeper可能不同步。而Direct机制使用简单Kafka消费API,SparkStreaming自己实现追踪消费的offset并通过CheckPoint保存,从而保证有且只消费一次。
Direct方式不需要通过WAL来实现高可靠,所以性能上比Receiver高。
提高并行度
基于Receiver的方式中,增加Receiver的数量只能增加从kafka中消费数据的线程,而数据处理也就是Spark读取数据的线程数不受影响,所以Receiver方式中只能通过多个输入DStream聚合(Union)的方式来实现提高并行度。
基于Direct方式中,由于是Spark直接拉取Kafka的数据,所以我们只需要创建有多个partition的RDD就可以消费多个partition的Topic。
如何保证Spark Streaming的精准一次性消费?
要实现精准一次消费就是要同时解决数据重复和数据丢失问题。数据丢失发生在Kafka中的数据被消费了,但是本地还未保存成功,offset变化,节点出错导致数据丢失。要避免这种错误,我们需要手动维护offset,当数据成功保存后再提交offset。数据重复就是数据已成功保存但offset未成功提交,进程挂了,就会造成重复消费,解决方案是开启幂等性。
项目中Spark Streaming消费Kakfa的offset保存在哪里?为什么不采用checkpoint保存offset,有什么缺点?
保存在mysql中 mysql保存kafka的offset
缺点:CheckPoint会将Spark Streaming运行时的元数据以及每次RDD的数据状态保存到一个持久化系统中,其中包括offset,一旦程序挂了也可以从CheckPoint中恢复。但是CheckPoint在第一次持久化时会将jar包序列化为二进制文件,每次重启时都会从这个二进制文件中恢复。这样的后果是一旦程序代码修改或迭代了,这里运行的依然是之前的jar包,就会出现两种错误:(1)启动报错,反序列化异常 (2)启动正常,但是运行的代码仍然是上一次的程序的代码。事实上大多数的公司的代码都会进行频繁的迭代,这样就需要对CheckPoint中的offset进行保存,下次运行时再读取保存的offset。而既然要对offset另外进行维护,还不如一开始就手动维护offset。
对RDD的理解
RDD:弹性分布式数据集
弹性:存储弹性,内存和磁盘的自动切换,Spark在执行任务时会将数据保存在内存中提高效率,但是内存不能被占满,所以内存占用到一定的程度后会自动切换为磁盘存储;容错的弹性,数据丢失可以通过血缘重新构造,实现自动恢复;计算的弹性,计算出错重试机制,出错了可以通过之前的逻辑进行重试;分片的弹性,可根据需要重新分片,比如根据executor数进行分区,可以提高资源利用率和计算效率。
分布式:数据分布在不同的节点
数据集:RDD封装了计算逻辑,并不保存数据。
数据抽象:RDD是一个抽象类,代码中需要子类来实现。
不可变:RDD是不可变的,要想改变只能产生新的RDD。
Spark作业运行流程?(从standalone和yarn两种模式进行阐述)
standalone和yarn的区别是调度任务处理者不同:standalone是通过内部master调度,yarn模式是通过yarn实现调度
client和cluster模式的区别:Driver启动在提交任务的client节点;任务被打包为一个task放入调度队列后等待分配资源,在分配的节点executor中开启Driver运行任务;
standalone和yarn模式分别从client,cluster模式解读运行流程
为什么Spark Shuffle比MapReduce Shuffle快(至少说出4个理由)?
注:shuffle过程spark和MapReduce都是基于磁盘的
- spark基于内存处理(尽量),可能会涉及磁盘io,MapReduce一定会涉及磁盘io
- spark省去了冗余的reduce阶段,MapReduce必须采用完整MapReduce。
- spark的中间数据可以保存在内存中,MapReduce则必须落盘重新读取。
- MapReduce的shuffle会有多处排序,且不可跳过;spark计算时不指定不排序。
- MapReduce采用多进程模型,每次启动都会涉及到进程的开启和关闭;spark采用多线程模型,启动任务时可以通过线程池中线程的复用实现,减少启动关闭task的开销。
java保证线程安全的方式有哪些?
java保证线程安全的方式
一个volatile修饰的变量,如果两个线程同时去写这个变量,线程安全吗?如果不安全该怎么使他变得安全?
不能
volatile不能保证线程安全
方法:加锁
Linux中怎么查看一个进程打开了哪些文件?
Linux中怎么查看一个进程打开了哪些文件
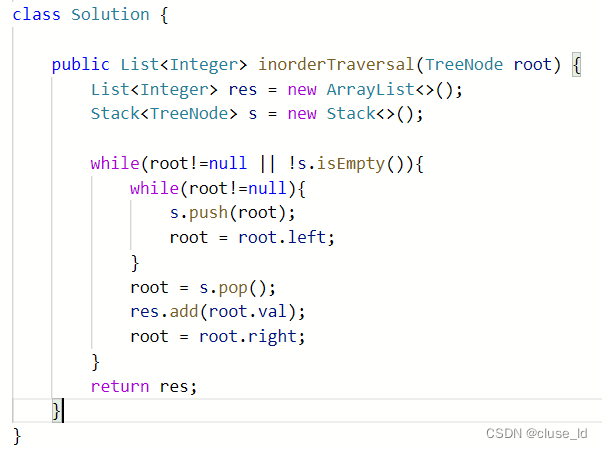
算法题:二叉树非递归中序遍历