文章目录
- 1 group by子句
- 2 回溯统计
- 3 having子句
1 group by子句
group by子句**:分组统计,根据某个字段将所有的结果分类,并进行数据统计分析
- 分组的目的不是为了显示数据,一定是为了统计数据
- group by子句一定是出现在where子句之后(如果同时存在)
- 分组统计可以进行统计细分:先分大组,然后大组分小组
- 分组统计需要使用统计函数
- group_concat():将组里的某个字段全部保留
- any_value():选择被分到同一组的数据里第一条数据的指定列值作为返回数据
- count():求对应分组的记录数量
- count(字段名):统计某个字段值的数量(NULL不统计)
- count(*):统计整个记录的数量(较多)
- sum():求对应分组中某个字段是和
- max()/min():求对应分组中某个字段的最大/最小值
- avg():求对应分组中某个字段的平均值
步骤
1、确定要进行数据统计
2、确定统计对象:分组字段(可以多个)
3、确定要统计的数据形式:选择对应统计函数
4、分组统计
- 原始数据
create table t_40(
id int primary key auto_increment,
name varchar(10) not null,
gender enum('男','女','保密'),
age tinyint unsigned not null,
class_name varchar(10) not null comment '班级名称'
)charset utf8;
insert into t_40 values(null,'鸣人','男',18,'木叶1班'),
(null,'佐助','男',18,'木叶1班'),
(null,'佐井','男',19,'木叶2班'),
(null,'大蛇丸','男',28,'木叶0班'),
(null,'卡卡西','男',29,'木叶0班'),
(null,'小樱','女',18,'木叶1班'),
(null,'雏田','女',18,'木叶1班'),
(null,'我爱罗','男',19,'木叶1班'),
(null,'向日葵','女',6,'木叶10班'),
(null,'博人','男',8,'木叶10班'),
(null,'鼬','男',28,'木叶0班');
- 统计每个班的人数
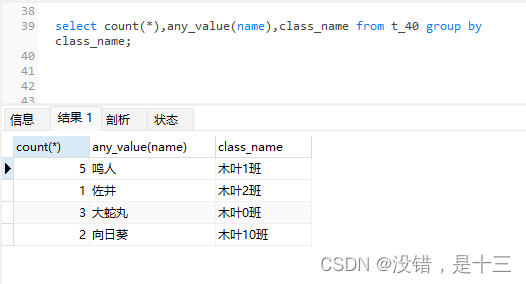
select count(*),class_name from t_40 group by class_name;

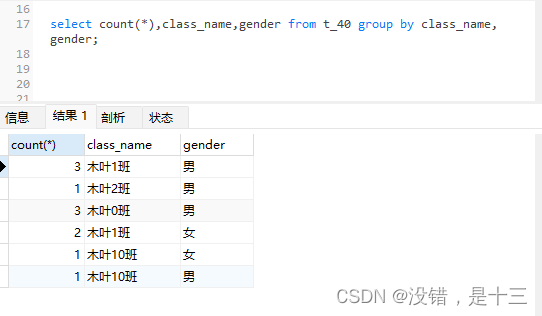
- 多分组:统计每个班的男女学生数量
select count(*),class_name,gender from t_40 group by class_name,gender;片
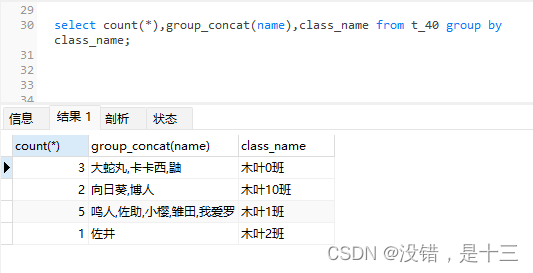
- 统计每个班里的人数,并记录班级学生的名字
select count(*),group_concat(name),class_name from t_40 group by class_name;
select count(*),any_value(name),class_name from t_40 group by class_name;
小结
1、分组与统计是不分离的,分组必然要用到统计,而统计一旦使用实际上就进行了分组
2、分组统计使用数据数据的查询只能依赖统计函数和被分组字段,而不能是其他字段(MySQL7以前可以,不过数据没意义:因为系统只保留组里的第一个)
3、group by子句有自己明确的位置:在where之后(where可以没有)
2 回溯统计
概念
回溯统计:在进行分组时(通常是多分组),每一次结果的回溯都进行一次汇总统计
- 回溯统计语法:在统计之后使用
with rollup
步骤
1、确定要进行分组统计
2、确定是多分组统计
3、需要对每次分组结果进行汇总
4、使用回溯统计
示例
统计每个班的男女同学数量,同时要知道班级人数总数
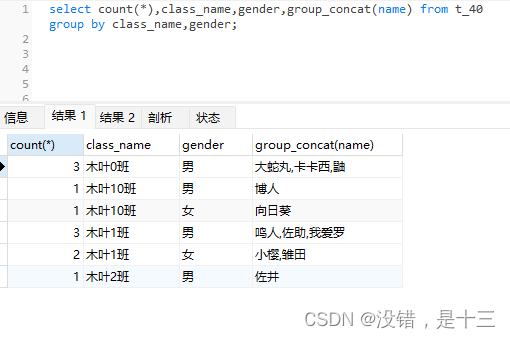
# 只统计每个班的男女同学数量,没有班级汇总
select count(*),class_name,gender,group_concat(name) from t_40 group by class_name,gender;
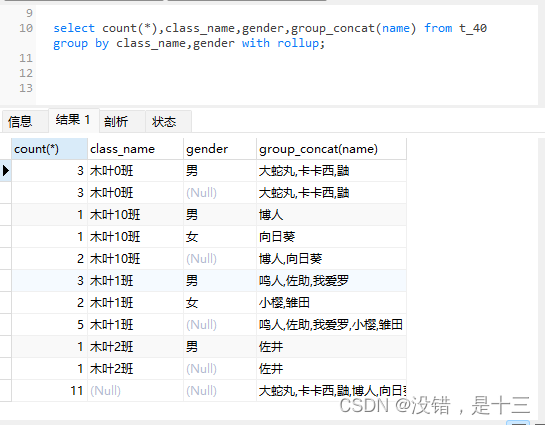
# 汇总统计:回溯
select count(*),class_name,gender,group_concat(name) from t_40 group by class_name,gender with rollup;
小结
1、回溯统计一般用在多字段分组中,用来统计各级分组的汇总数据
2、因为回溯统计会将对应的分组字段置空(不置空无法合并),所以回溯的数据还需要经过其他程序语言加工处理才能取出数据来
3 having子句
概念
having子句:类似于where子句,是用来进行条件筛选数据的
-
having子句本身是针对分组统计结果进行条件筛选的
-
having子句必须出现在group by子句之后(如果同时存在)
-
having针对的数据是在内存里已经加载的数据
-
having几乎能做where能做的所有事,但是where却不一定
- 字段别名(where针对磁盘数据,那时还没有)
- 统计结果(where在group by之前)
- 分组统计函数(having通常是针对group by存在的)
步骤
1、前面有分组统计
2、需要针对分组统计后的结果进行数据筛选
3、使用having组织条件进行筛选
select count(*) as `count`,class_name,group_concat(name) from t_40 group by class_name having `count` < 3;
小结
1、having也是用于数据筛选的,但是本质是针对分组统计,如果没有分组统计,不要使用having进行数据筛选
2、能用where解决问题的地方绝不使用having
- where针对磁盘读取数据,源头解决问题
- where能够限制无效数据进入内存,内存利用率较高,而having是针对内存数据筛选