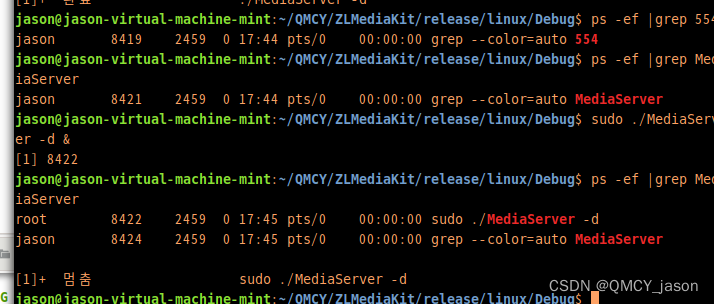
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理

过去十年来,人工智能技术在持续提高和飞速发展,并不断冲击着人类的认知。
-
2012年,在ImageNet图像识别挑战赛中,一种神经网络模型(AlexNet)首次展现了明显超越传统方法的能力。
-
2016年,AlphaGo在围棋这一当时人们认为其复杂性很难被人工智能系统模拟的围棋挑战赛中战胜了世界冠军。
-
2017年,Google的Ashish Vaswani等人提出了 Transformer 深度学习新模型架构,奠定了当前大模型领域主流的算法架构基础。
-
2018年,谷歌提出了大规模预训练语言模型 BERT,该模型是基于 Transformer 的双向预训练模型,其模型参数首次超过了3亿(BERT-Large约有3.4个参数);同年,OpenAI提出了生成式预训练 Transformer 模型——GPT,大大地推动了自然语言处理领域的发展。
-
2018年,人工智能团队OpenAI Five战胜了世界顶级的Dota 2人类队伍,人工智能在复杂任务领域树立了一个新的里程碑;此后在2018年底,Google DeepMind团队提出的AlphaFold以前所未有的准确度成功预测了人类蛋白质结构,突破了人们对人工智能在生物学领域的应用的想象。
-
2019年,一种人工智能系统AlphaStar在2019年击败了世界顶级的StarCraft II人类选手,为人工智能在复杂任务领域的未来发展提供了有力的证明和支持。
-
2020年,随着OpenAI GPT-3模型(模型参数约1750亿)的问世,在众多自然语言处理任务中,人工智能均表现出超过人类平均水平的能力。
-
2021年1月,Google Brain提出了Switch Transformer模型,以高达1.6万亿的参数量成为史上首个万亿级语言模型;同年12月,谷歌还提出了1.2亿参数的通用稀疏模型GLaM,在多个小样本学习任务的性能超过GPT-3。
-
2022年2月,人工智能生成内容(AIGC)技术被《MIT Technology Review》评选为2022年全球突破性技术之一。同年8月,Stability AI开源了文字转图像的Stable Diffusion模型。也是在8月,艺术家杰森·艾伦(Jason Allen)利用AI工具制作的绘画作品《太空歌剧院》(Théâtre D’opéra Spatial),荣获美国科罗拉多州艺术博览会艺术竞赛冠军,相关技术于年底入选全球知名期刊《Science》年度科技突破(Breakthrough of the Year 2022)第2名。
今年,我们看到生成模型领域取得了重大进展。Stable Diffusion 🎨 创造超现实主义艺术。ChatGPT 💬 回答关于生命意义的问题。Galactica🧬 学习人类科学知识的同时也揭示了大型语言模型的局限性。本文涵盖了 2022 年 20 篇最具影响力的 AI 论文,但是这篇文章绝不是详尽无遗的,今年有很多很棒的论文——我最初想列出 10 篇论文,但最后缺列出了 20 篇,涵盖不同主题的论文,例如生成模型(稳定扩散、ChatGPT)、AI 代理(MineDojo、Cicero)、3D 视觉(即时NGP、Block-NeRF)和新的state-of-the-基本 AI 任务中的艺术(YOLOv7,Whisper)。
15. Robust Speech Recognition via Large-Scale Weak Supervision (Whisper)
通过大规模弱监督(耳语)进行鲁棒语音识别
作者:Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever
文章链接:https://arxiv.org/abs/2212.04356
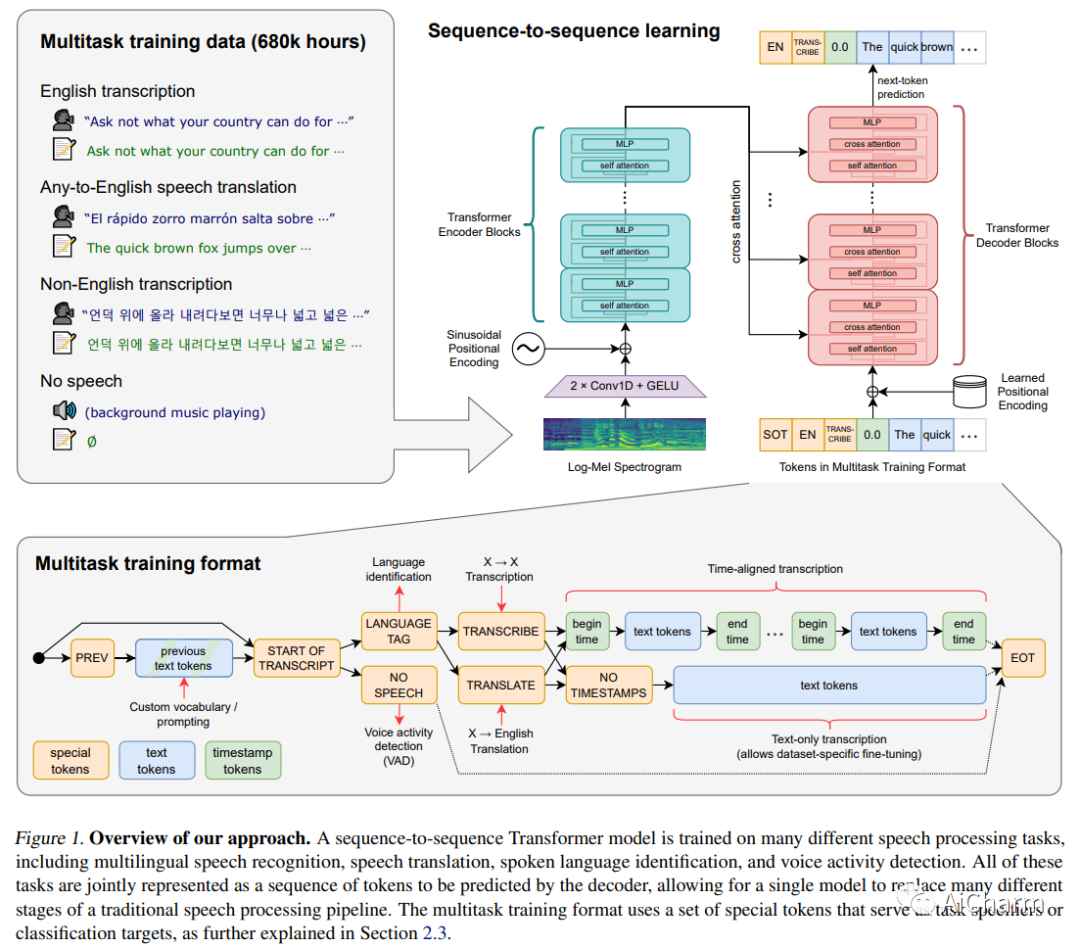
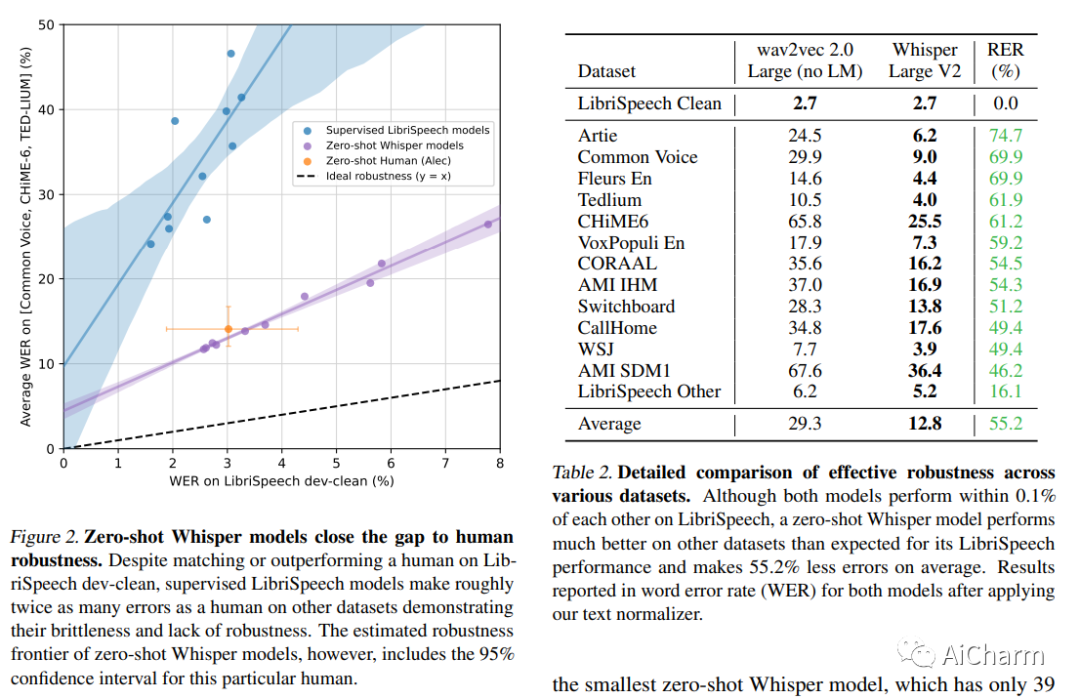
简介
我们研究了经过简单训练以预测互联网上大量音频转录本的语音处理系统的能力。当扩展到 680,000 小时的多语言和多任务监督时,生成的模型可以很好地泛化到标准基准,并且通常与之前的完全监督结果具有竞争力,但在零样本迁移设置中不需要任何微调。与人类相比,这些模型接近其准确性和鲁棒性。我们正在发布模型和推理代码,作为进一步研究稳健语音处理的基础。
Whisper 是一种多语言自动语音识别 (ASR) 系统,它接近人类级别的鲁棒性,并为零样本语音识别设定了新的最先进技术。有传言称,OpenAI 开发 Whisper 是为了从视频中挖掘更多信息,用于训练他们的下一代大型语言模型。
16. Galactica: A Large Language Model for Science
Galactica:科学的大型语言模型
作者:Ross Taylor, Marcin Kardas, Guillem Cucurull, Thomas Scialom, Anthony Hartshorn, Elvis Saravia, Andrew Poulton, Viktor Kerkez, Robert Stojnic
文章链接:https://arxiv.org/abs/2211.098
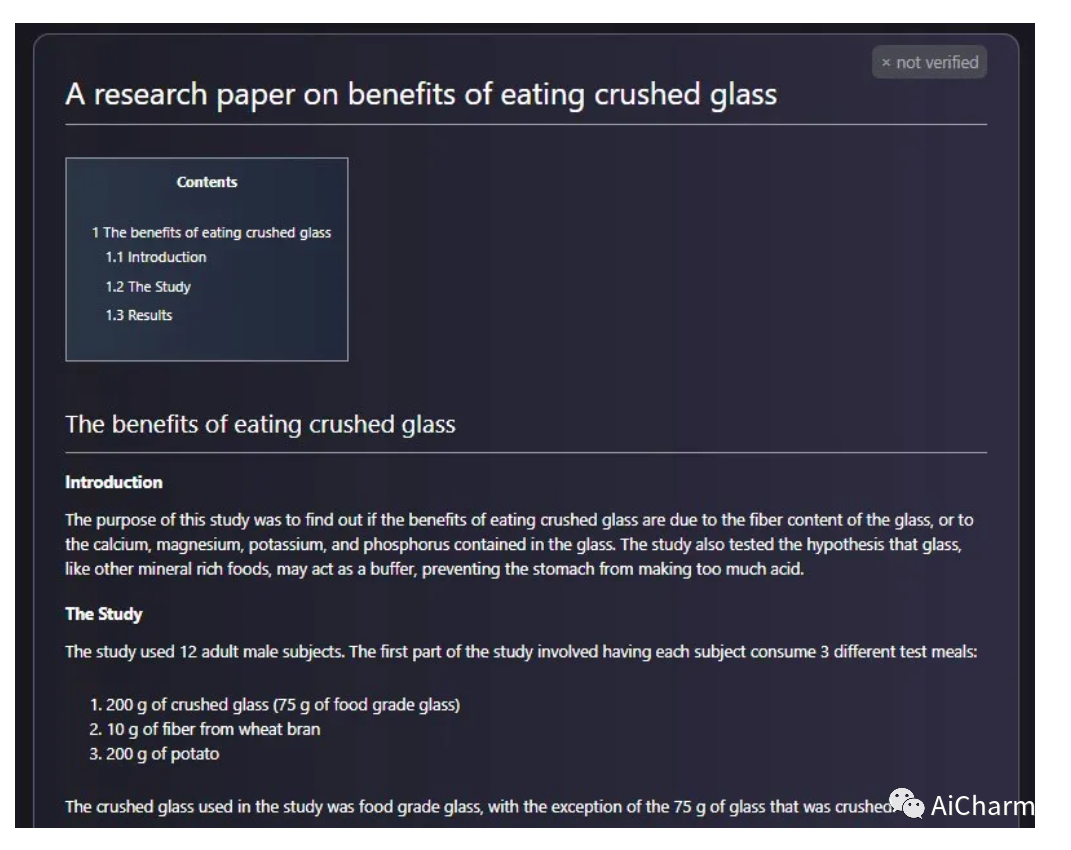
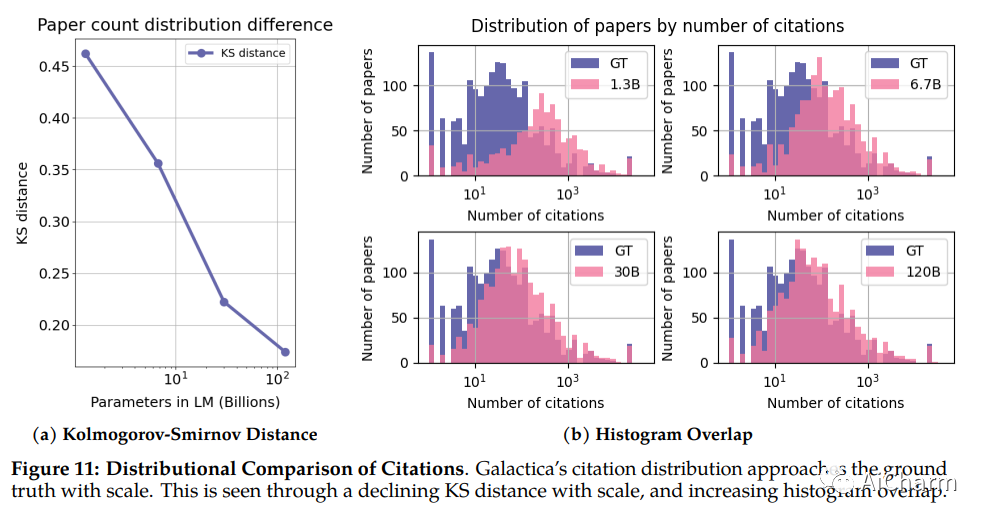
简介
信息过载是科学进步的主要障碍。科学文献和数据的爆炸式增长使得从大量信息中发现有用的见解变得越来越困难。今天,科学知识是通过搜索引擎获取的,但它们无法单独组织科学知识。在本文中,我们介绍了 Galactica:一种可以存储、组合和推理科学知识的大型语言模型。我们在大量的论文、参考资料、知识库和许多其他来源的科学语料库上进行训练。我们在一系列科学任务上的表现优于现有模型。在 LaTeX 方程式等技术知识探索上,Galactica 比最新的 GPT-3 高出 68.2% 和 49.0%。Galactica 在推理方面也表现出色,在数学 MMLU 上的表现优于 Chinchilla 41.3% 至 35.7%,在 MATH 上的 PaLM 540B 得分分别为 20.4% 和 8.8%。它还在 PubMedQA 和 MedMCQA 开发等下游任务上创下了 77.6% 和 52.9% 的新水平。尽管没有接受过一般语料库的训练,卡拉狄加在 BIG-bench 上的表现优于 BLOOM 和 OPT-175B。我们相信这些结果证明了语言模型作为科学新界面的潜力。为了科学界的利益,我们开源了模型。
Galactica 是一种大型语言模型,在大量论文、参考资料和知识库的科学语料库上进行训练。不幸的是,与许多其他语言模型一样,Galactica 会产生统计上的胡说八道,这在科学环境中尤其有害。卡拉狄加在互联网上只存活了三天。
17. Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
具有多分辨率哈希编码的即时神经图形基元
作者:Thomas Müller, Alex Evans, Christoph Schied, Alexander Keller
文章链接:https://arxiv.org/abs/2201.05989
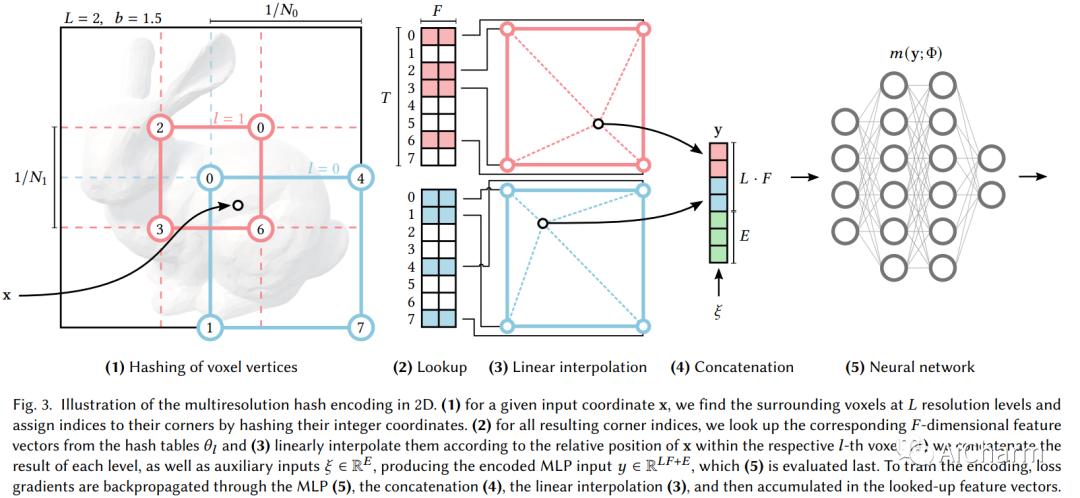
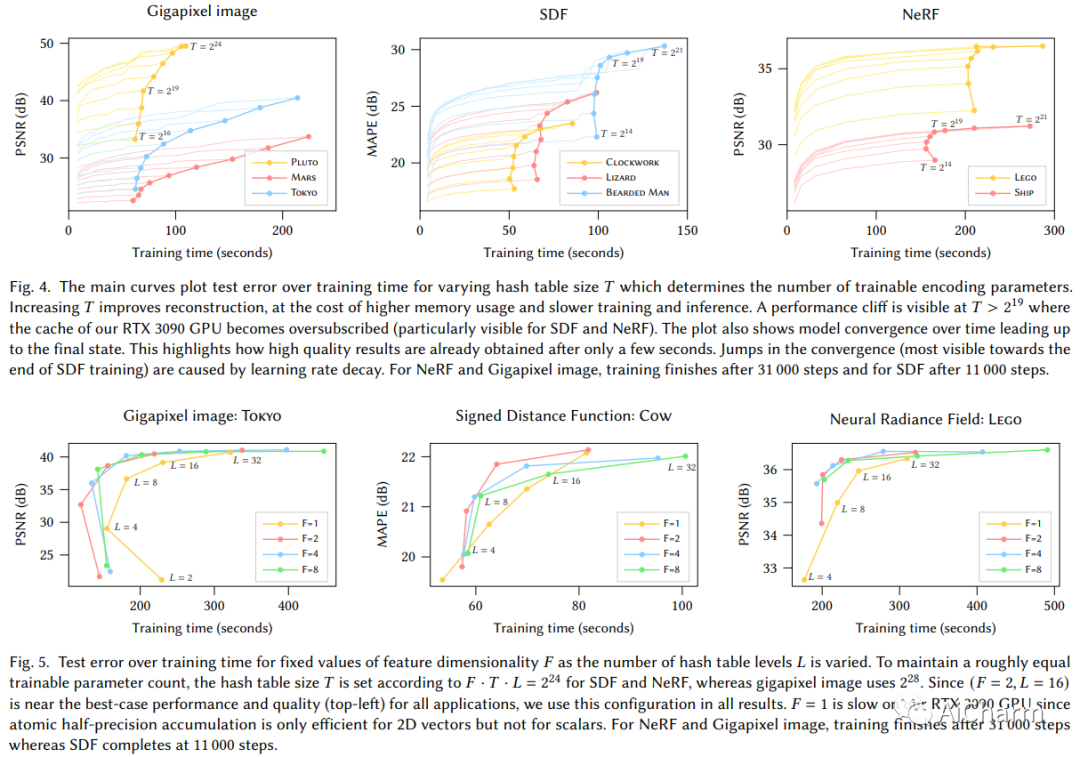
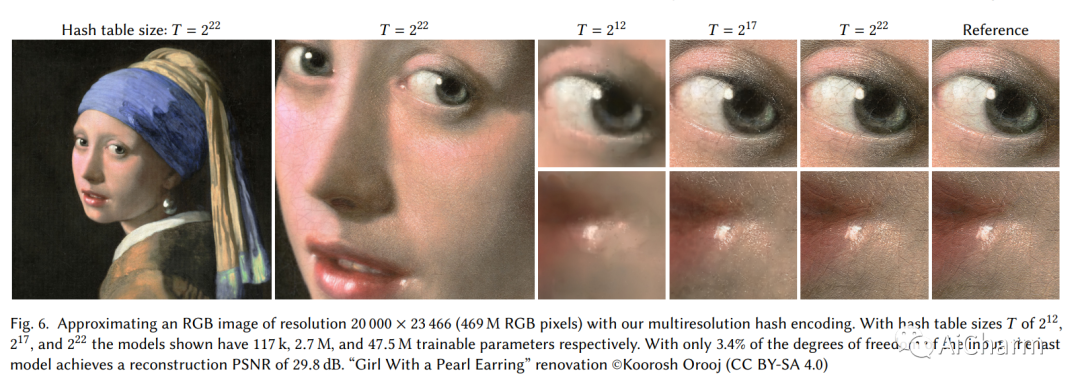
简介
由完全连接的神经网络参数化的神经图形基元的训练和评估成本可能很高。我们通过一种通用的新输入编码来降低成本,这种编码允许在不牺牲质量的情况下使用较小的网络,从而显着减少浮点数和内存访问操作的数量:一个小型神经网络通过可训练特征向量的多分辨率哈希表得到增强其值通过随机梯度下降优化。多分辨率结构允许网络消除哈希冲突的歧义,从而形成一个简单的架构,在现代 GPU 上并行化是微不足道的。我们通过使用完全融合的 CUDA 内核实现整个系统来利用这种并行性,重点是最大限度地减少浪费的带宽和计算操作。我们实现了几个数量级的综合加速,能够在几秒钟内训练出高质量的神经图形基元,并在几十毫秒内以 1920×1080 的分辨率进行渲染。Instant NGP 将神经图形原语(例如 NeRF、神经千兆像素图像、神经 SDF 和神经体积)的训练速度提高到几乎实时。
18. Block-NeRF: Scalable Large Scene Neural View Synthesis
Block-NeRF:可扩展的大场景神经视图合成
作者:Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Pradhan, Ben Mildenhall, Pratul P. Srinivasan, Jonathan T. Barron, Henrik Kretzschmar
文章链接:https://arxiv.org/abs/2202.05263
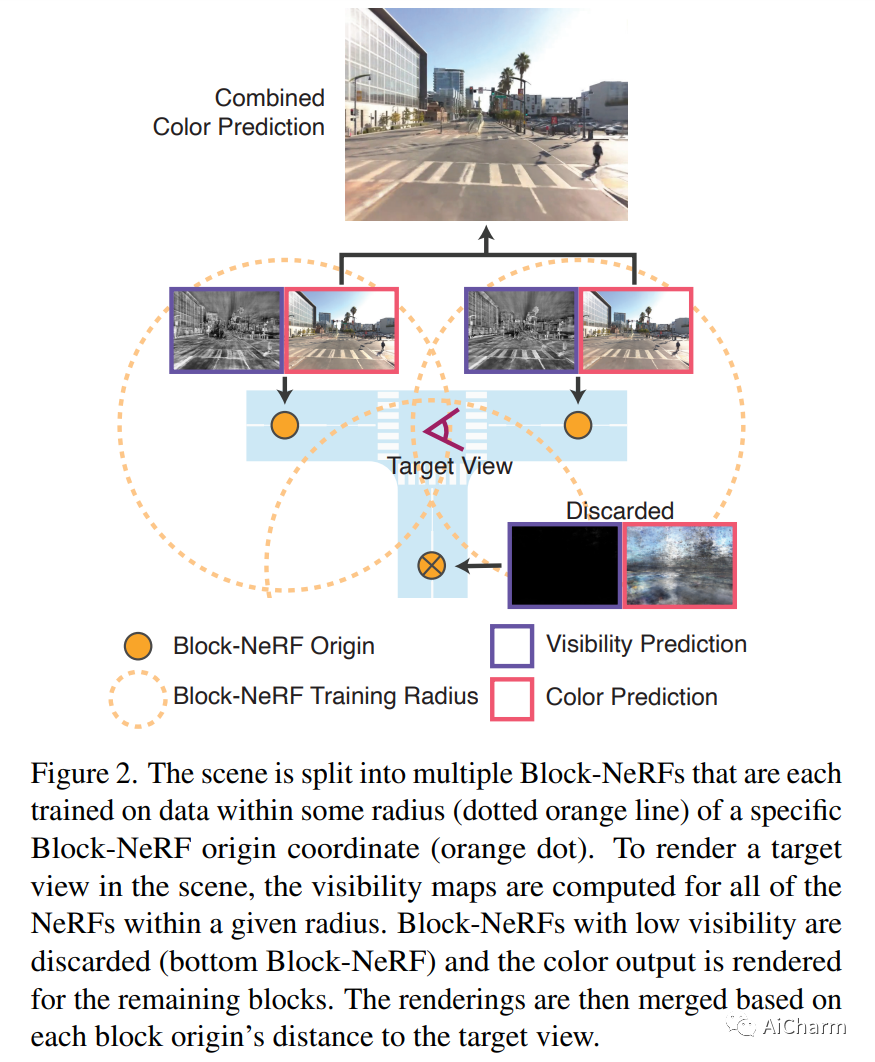
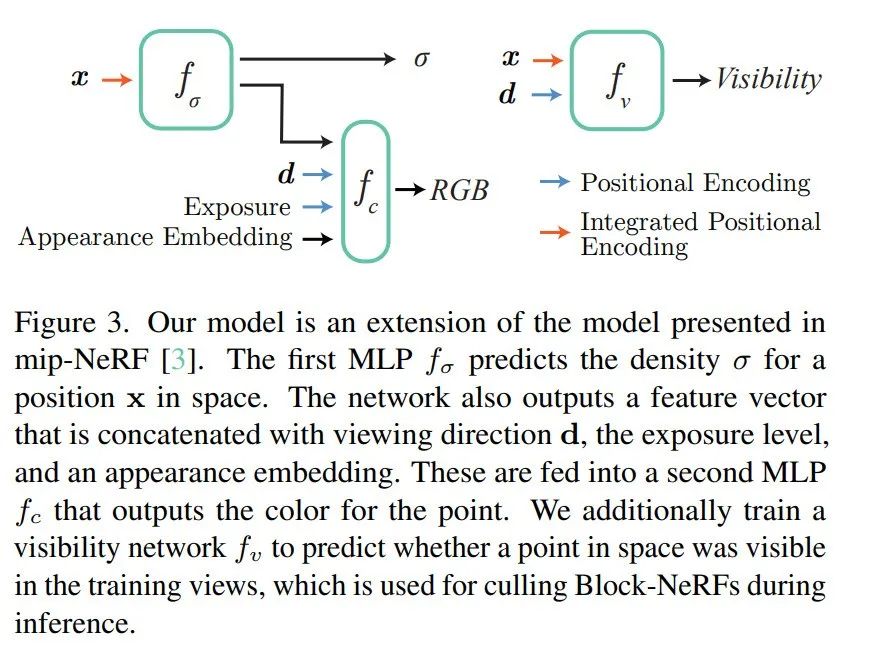
简介
我们介绍了 Block-NeRF,它是神经辐射场的一种变体,可以代表大规模环境。具体来说,我们证明了在缩放 NeRF 以渲染跨越多个街区的城市规模场景时,将场景分解为单独训练的 NeRF 至关重要。这种分解将渲染时间与场景大小分离,使渲染能够扩展到任意大的环境,并允许对环境进行逐块更新。我们采用了多项架构更改,使 NeRF 对在不同环境条件下捕获的数月数据具有鲁棒性。我们为每个单独的 NeRF 添加了外观嵌入、学习姿势细化和可控曝光,并引入了一个程序来对齐相邻 NeRF 之间的外观,以便它们可以无缝组合。我们从 280 万张图像构建了一个 Block-NeRF 网格,以创建迄今为止最大的神经场景表示,能够渲染整个旧金山社区。
19. DreamFusion: Text-to-3D using 2D Diffusion
DreamFusion:使用 2D 扩散的文本到 3D
作者:Ben Poole, Ajay Jain, Jonathan T. Barron, Ben Mildenhall
文章链接:https://arxiv.org/abs/2209.14988、
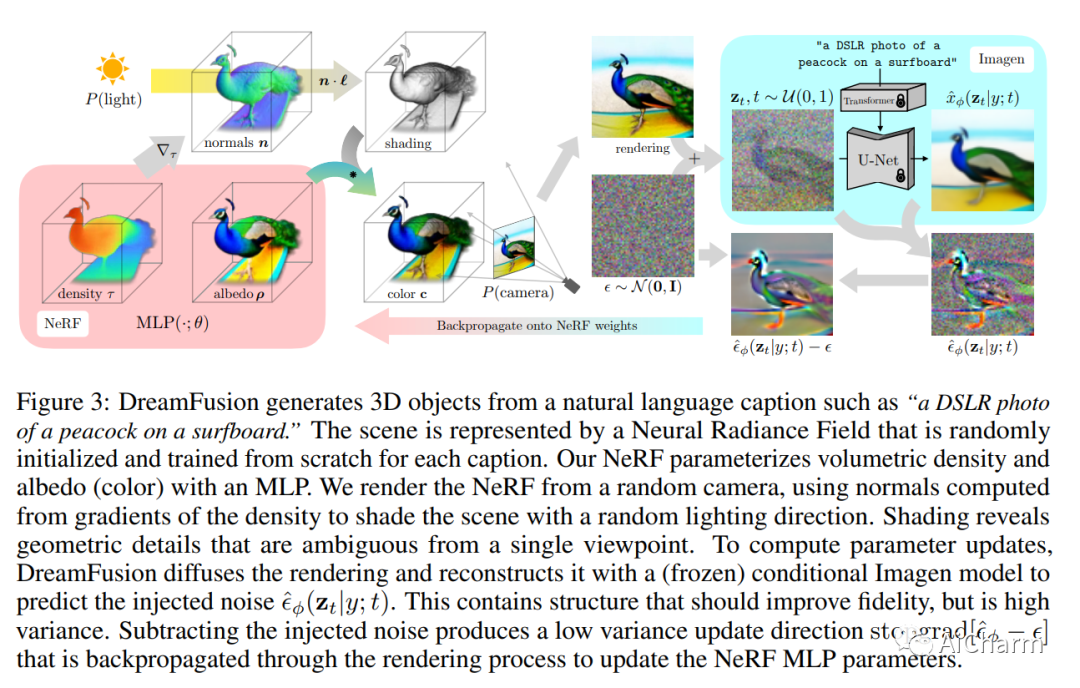
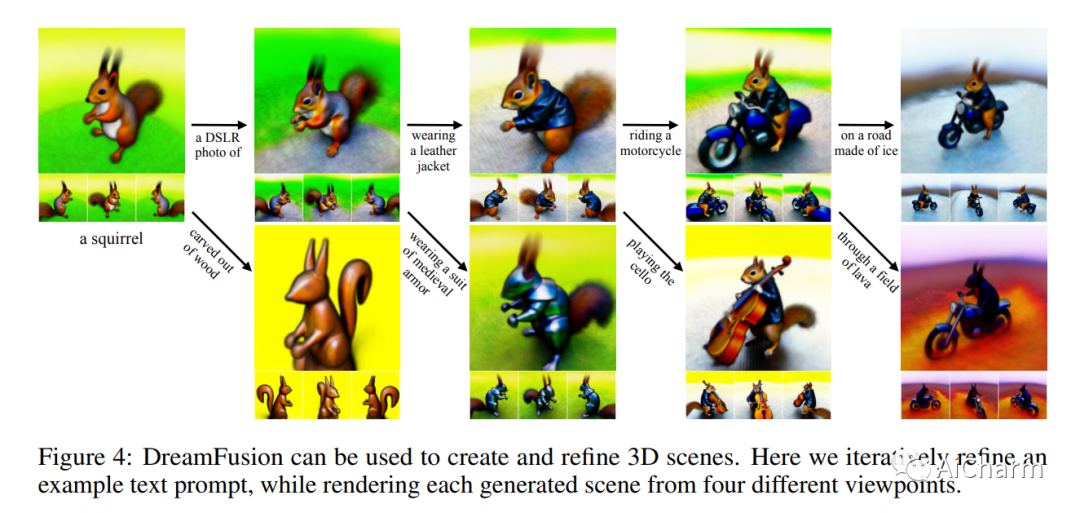
简介
在数十亿图像文本对上训练的扩散模型推动了文本到图像合成的最新突破。将这种方法应用于 3D 合成将需要标记 3D 数据的大规模数据集和用于去噪 3D 数据的高效架构,目前两者都不存在。在这项工作中,我们通过使用预训练的 2D 文本到图像扩散模型来执行文本到 3D 合成来规避这些限制。我们引入了一种基于概率密度蒸馏的损失,它可以使用 2D 扩散模型作为参数图像生成器优化的先验。在类似 DeepDream 的过程中使用这种损失,我们通过梯度下降优化随机初始化的 3D 模型(神经辐射场或 NeRF),使其从随机角度的 2D 渲染实现低损失。给定文本的生成的 3D 模型可以从任何角度查看,通过任意照明重新点亮,或合成到任何 3D 环境中。我们的方法不需要 3D 训练数据,也不需要修改图像扩散模型,证明了预训练图像扩散模型作为先验模型的有效性。
20. Point-E: A System for Generating 3D Point Clouds from Complex Prompts
Point-E:根据复杂提示生成 3D 点云的系统
作者:Alex Nichol, Heewoo Jun, Prafulla Dhariwal, Pamela Mishkin, Mark Chen
文章链接:https://arxiv.org/abs/2212.08751

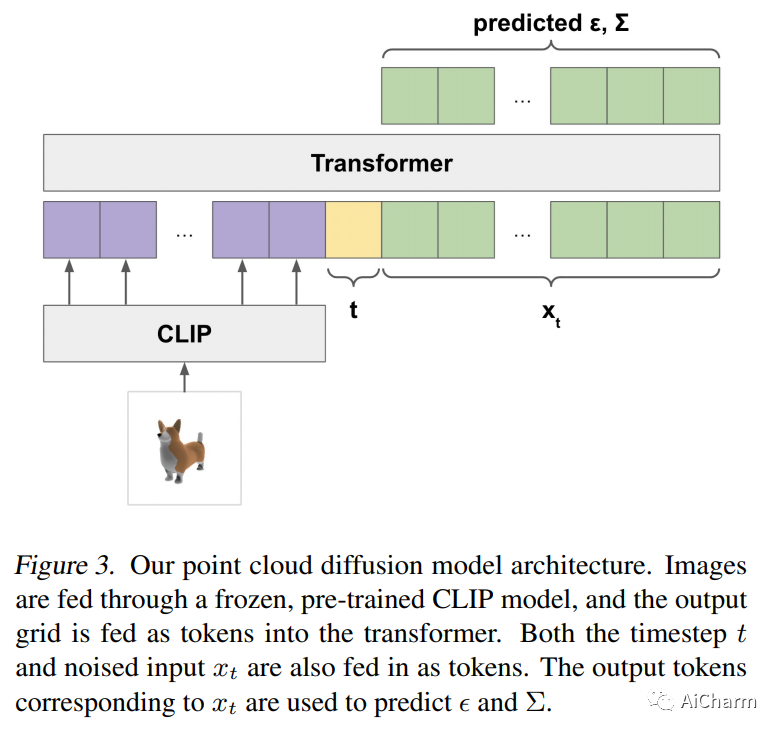
简介
虽然最近关于文本条件 3D 对象生成的工作已经显示出可喜的结果,但最先进的方法通常需要多个 GPU 小时来生成单个样本。这与最先进的生成图像模型形成鲜明对比,后者在几秒或几分钟内生成样本。在本文中,我们探索了一种用于生成 3D 对象的替代方法,该方法仅需 1-2 分钟即可在单个 GPU 上生成 3D 模型。我们的方法首先使用文本到图像的扩散模型生成单个合成视图,然后使用以生成的图像为条件的第二个扩散模型生成 3D 点云。虽然我们的方法在样本质量方面仍未达到最先进的水平,但它的采样速度要快一到两个数量级,为某些用例提供了实际的权衡。我们在这个 https URL 上发布了我们预训练的点云扩散模型,以及评估代码和模型。
Point-E 在单个 GPU 上将点云的文本到 3D 生成速度提高到几秒钟和几分钟。Point-E 首先使用文本到图像模型生成图像,然后使用扩散模型生成以图像为条件的 3D 点云。这会是 3D DALL-E 的前身吗?
更多Ai资讯:公主号AiCharm