Innovation
使用RL学习KG中的关系路径推理
使用Supervised Policy Learning解决:KG中关系图大,如试错训练RL,难以收敛
使用双向路径搜索,减少中间节点数量
Introduction
PRA是一种学习推理路径的方法,使用基于RandomWalk的重启推理机制来执行多个有界深度优先搜索过程来查找relational path。但其在完全离散的空间中工作,使得比较KG中相似实体和关系变得困难。
本文提出了一种可控multi-hop推理的新方法:将路径学习过程构建为RL。和PRA相比,我们使用基于翻译的基于知识的嵌入方法TRansE编码RL agent的连续状态,在知识图的向量空间中。agent通过采样关系扩展路径来执行incremental步骤。使用具有新的奖励函数的policy gradient策略直到RL agent学习relational path。
DeepPath是第一个考虑在KG中使用RL学习关系路径的方法。
模型
Reinforcement Learning for Relation Reasoning
RL系统有两部分组成。第一部分是外部环境E,它指定agent与KG之间的交互动态,环境被建模为马尔科夫决策过程(MDP)。状态转移概率矩阵
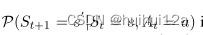
第二部分是RL agent代理,表示为一个决策网络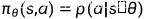 ,将状态向量映射到随机策略,神经网络参数
,将状态向量映射到随机策略,神经网络参数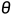 采用随机梯度下降法更新
采用随机梯度下降法更新

Action
从源实体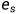 开始,agent使用策略网络选择最有希望的关系进行每一步的路径扩展,直到达到目标实体
开始,agent使用策略网络选择最有希望的关系进行每一步的路径扩展,直到达到目标实体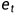 。为了保证策略网络的输出维数一致,将动作空间定义为KG中的所有关系。
。为了保证策略网络的输出维数一致,将动作空间定义为KG中的所有关系。
States
KG中的实体和关系是离散的atomic符号,现有的KG数据库通常含有大量的三元组,因此直接模拟所有atomic符号的状态是不可行的。我们使用翻译的模型TransE TransH表示实体和关系,将所有符号映射到低维向量空间。
本文框架中每个状态都捕获了agent在KG中的位置,采取一个操作后,agent将从一个实体移动到另一个实体,两者由agent刚刚采取的行动(关系 )联系起来。
在t步的状态向量为,其中表示当前实体的嵌入,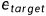 是目标实体的嵌入,在初始状态时
是目标实体的嵌入,在初始状态时 。本文没有在状态中加入推理关系,因为在寻找路径的过程中,推理关系的嵌入保持不变,对训练没有关注。
。本文没有在状态中加入推理关系,因为在寻找路径的过程中,推理关系的嵌入保持不变,对训练没有关注。
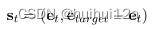
Rewards
奖励函数包括以下几个评分准则:
(1)Global accuracy
对于我们的环境设置,agent可以采取的行动的数量很大。不正确的序列决策会比正确决策多得多,不正确的决策序列会随着路径的长度呈指数级增长。第一个reward function:如果agent在一系列行动后达到目标,获得离线正奖励+1

(2)Path efficiency
对于关系推理任务,观察到短路径往往比长路径提供更可靠的推理证据;更短的关系链可以通过限制RL与环境交互长度提高推理效率。p为关系序列
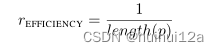
(3)Path diversity
本文使用positive samples训练agent,为每个关系寻找路径。这些训练样本 在向量空间具有相似的状态表示。agent倾向于寻找具有相似语法和语义的路径。这些路径通常包含冗余信息,因为其中一些可能是相关的。为了鼓励智能体寻找不同的路径,我们使用当前路径与现有路径之间的余弦相似度定义了一个多样性奖励函数:
在向量空间具有相似的状态表示。agent倾向于寻找具有相似语法和语义的路径。这些路径通常包含冗余信息,因为其中一些可能是相关的。为了鼓励智能体寻找不同的路径,我们使用当前路径与现有路径之间的余弦相似度定义了一个多样性奖励函数:
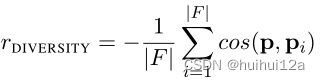

Policy Network
policy function  是将状态向量s映射到所有可能行动的概率分布,使用一个全连接神经网络参数化policy function,神经网络有两个隐藏层组成,每个隐藏层后市Relu,输出层使用softmax进行标准化。
是将状态向量s映射到所有可能行动的概率分布,使用一个全连接神经网络参数化policy function,神经网络有两个隐藏层组成,每个隐藏层后市Relu,输出层使用softmax进行标准化。
Training Pipeline
实践中,KG推理的挑战是关系集很大,策略网络的输出层维度往往很大。由于关系图的复杂性和较大的行动空间,如果采用RL算法的典型的方法,通过试错直接训练RL模型,RL模型的收敛性会很差,经过长时间训练也难以找到有价值的路径。
受ALphaGo采用的imitation learning pipeline,它使用专家动作训练一个supervised的policy network。在本文中的监督策略使用随机宽度优先搜索(BFS)训练的。
Supervised Policy Learning
对于每个关系,我们使用所有正样本(实体对)的子集学习监督策略,对于每个路径 ,使用REINFORCE算法更新最大化期望的累计reward。
,使用REINFORCE算法更新最大化期望的累计reward。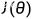 是一个episode的期望总reward,对于监督学习,我们对每一个成功的episode中的每一步提供+1奖励。
是一个episode的期望总reward,对于监督学习,我们对每一个成功的episode中的每一步提供+1奖励。
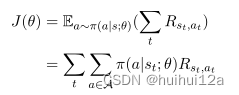
插入使用BFS找到的路径,更新策略网络的近似梯度如下
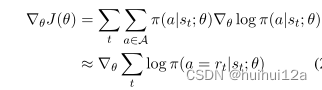
BFS是一种偏向于短路径的搜索算法。当插入这些偏置路径时,agent很难找到可能有用的更长的路径。在BFS中添加了一些随机机制。我们不再直接搜索源和目标之间的路径,而是随机选择一个中间节点einter,然后在(source, einter)和(einter, etarget)之间进行两次BFS。连接的路径用于训练agent。监督学习为agent体从失败的行为中学习节省了大量的精力。有了这些经验,我们就可以训练agent找到理想的路径。
Retraining with Rewards
为了找到由reward function控制的推理路径,本文使用reward function对监督策略网络进行再训练。从源节点开始,agent根据随机策略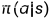 选择一个关系,以扩展其推理路径。这种联系可能会导致一个新的实体,也可能什么都没有。这些失败的步骤将导致agent收到负面奖励。在这些失败的步骤之后,agent将保持相同的状态。由于智能体遵循随机策略,因此智能体不会因重复错误步骤而陷入困境。为了提高训练效率,我们用一个上限来限制集合长度,如果agent未能在最大长度步骤内到达目标实体,则episode结束。在每次事件之后,使用以下梯度更新策略网络:其中
选择一个关系,以扩展其推理路径。这种联系可能会导致一个新的实体,也可能什么都没有。这些失败的步骤将导致agent收到负面奖励。在这些失败的步骤之后,agent将保持相同的状态。由于智能体遵循随机策略,因此智能体不会因重复错误步骤而陷入困境。为了提高训练效率,我们用一个上限来限制集合长度,如果agent未能在最大长度步骤内到达目标实体,则episode结束。在每次事件之后,使用以下梯度更新策略网络:其中 是定义的reward functions的线性组合。
是定义的reward functions的线性组合。
双向路径约束搜索
给定一个实体对,RL agent学习到的推理路径可以作为逻辑公式来预测关系链路,每个公式都使用双向搜索进行验证。在典型的KG中,一个简单的例子是一个实体节点可以链接到具有相同关系的大量邻居。一个简单的例子是关系personNationality−1,表示personNationality的倒数,通过这一联系,美国实体可以接触到许多邻国实体,如果推理公式中含有这样的链接关系,中间实体的数量可以呈指数增长。但如果我们从相反的方向验证公式,中间节点的数量可以大大减少。
实验
在大多数情况下,因为基于嵌入的方法没有用到路径信息,因此比基于路径的方法差。但是当在实体之间没有足够路径的时候,本文模型和PRA表现比较差,因为没有足够的推理证据
总结和未来工作
未来能否不用认为定义的奖励函数,而是训练一个判别模型给与奖励
KG没有足够的推理路径时的效果较差的问题。








![Python 不同分辨率图像峰值信噪比[PSNR]](https://img-blog.csdnimg.cn/0365b62292c24903aaceb225a754e8ca.jpeg)