近日,ICASSP 2023会议发出了审稿结果通知,语音及语言信息处理国家工程研究中心智能语音信息处理团队共18篇论文被会议接收,论文方向涵盖语音识别、语音合成、话者识别、语音增强、情感识别、声音事件检测等,各接收论文简介见后文。
来源丨语音及语言国家工程研究中心
语音及语言信息处理国家工程实验室于2011年由国家发改委正式批准成立,由中国科学技术大学和科大讯飞股份有限公司联合共建,是我国语音产业界唯一的国家级研究开发平台。2021年底,实验室通过国家发改委的优化整合评估,成功纳入新序列,并转建为语音及语言信息处理国家工程中心。
01
Neural Speech Phase Prediction based on Parallel Estimation Architecture and Anti-Wrapping Losses
论文作者:艾杨,凌震华
论文单位:中国科学技术大学
论文资源:
-
论文预印版下载地址:https://arxiv.org/abs/2211.15974
-
Demo语音网页:https://yangai520.github.io/NSPP
-
开源代码下载地址:https://github.com/yangai520/NSPP
论文简介:
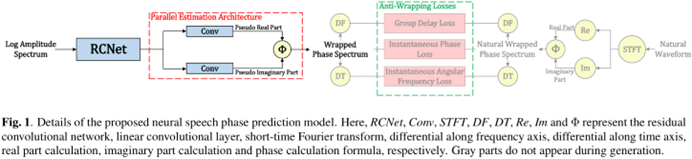
本文提出了一个全新的语音相位预测模型,通过神经网络实现从语音幅度谱到语音卷绕相位谱的直接预测。提出的模型由一个残差卷积网络和一个平行估计架构级联组成。其中,平行估计架构由两个平行的线性卷积层和一个相位计算公式组成,模拟从语音短时复数谱的实部和虚部到语音相位谱的计算过程并将预测的相位值严格限制在相位主值区间内。为了避免因相位卷绕特性造成的误差扩大问题,本文设计了抗卷绕损失训练模型,该损失定义在预测的卷绕相位谱和自然的卷绕相位谱之间,通过使用一个抗卷绕函数对瞬时相位误差、群延时误差和瞬时角频率误差激活得到。实验结果表明,综合考量重构语音质量和生成效率,本文提出的基于神经网络的语音相位预测模型的性能优于Griffin-Lim算法和其他基于神经网络的相位预测方法。
02 Speech Reconstruction from Silent Tongue and Lip Articulation by Pseudo Target Generation and Domain Adversarial Training
论文作者:郑瑞晨,艾杨,凌震华
论文单位:中国科学技术大学
论文资源:
Demo语音网页:https://zhengrachel.github.io/ImprovedTaLNet-demo/
论文简介:
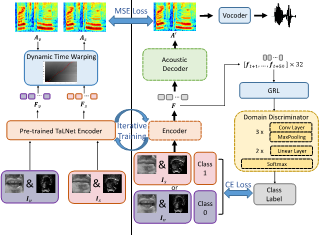
本文研究了从静默发声状态下的舌部超声图像和唇部视频中重构语音的任务。静默发声状态与正常发声状态相对应,指说话人在说话时只激活口内和口外发音器官,但不产生声音。我们采用了一种基于伪目标生成和域对抗训练的方法,采用迭代训练策略来提高静默发声状态下重构语音的清晰度和自然度。实验表明,与基线 TaLNet 模型相比,我们提出的方法显著提高了静默发声状态下重构语音的可懂度和自然度。当使用自动语音识别 (ASR) 模型测量语音可懂度时,我们提出的方法的单词错误率 (WER) 与基线相比降低了 15% 以上。此外,我们提出的方法在正常发声状态下重构语音的清晰度方面也优于基线,表现在将其 WER 降低了大约 10%。
03 Zero-shot Personalized Lip-to-Speech Synthesis with Face Image based Voice Control
论文作者:盛峥彦,艾杨,凌震华
论文单位:中国科学技术大学
论文资源:
Demo语音网页:https://levent9.github.io/Lip2Speech-demo/
论文简介:
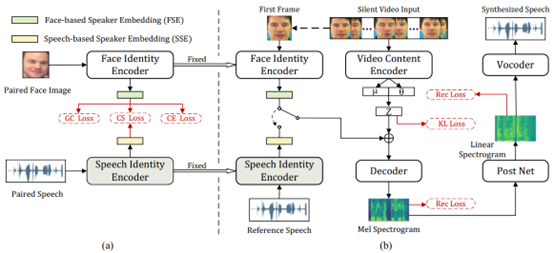
Lip-to-Speech (Lip2Speech) Synthesis是指根据人脸视频来进行语音合成,本文提出了一种基于人脸音色控制的zero-shot个性化Lip2Speech合成方法。人脸视频包含语义信息和话者信息,目前方法对于训练集外话者Lip2Speech合成语音的音色常常与话者信息相违和,因此本文采用变分自编码器结构解耦输入人脸视频中的话者信息和语义表征,额外输入的基于人脸的话者编码控制未见话者的音色;此外,考虑到数据集的稀缺性,提出了关联跨模态表征学习来提升基于人脸的话者编码对于音色控制的能力。实验表明,提出方法在合成语音的自然度上取得了更好的主客观性能,合成语音的音色和未见话者人脸形象更匹配。
04 A Multi-scale Feature Aggregation based Lightweight Network for Audio-visual Speech Enhancement
论文作者:徐海涛,魏亮发,张结,杨剑鸣,王燕南,高天,方昕,戴礼荣
论文单位:中国科学技术大学,腾讯天籁实验室,清华大学深圳国际研究生院,科大讯飞
论文简介:
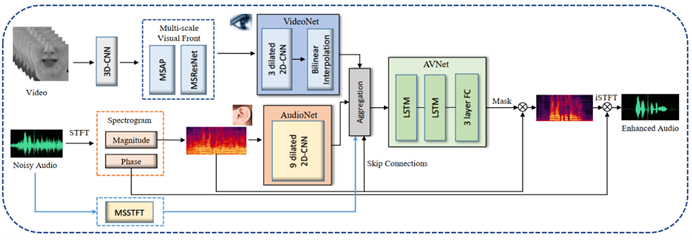
在提高语音质量上,音视频语音增强(Audio-visual Speech Enhancement, AVSE)方法已经被证明优于对应的纯音频语音增强(Audio-only Speech Enhancement, AOSE)方法。然而,当前的AVSE模型大多是重量级的,它们具有较大的参数量不利于模型的部署和实际的应用。在这项工作中,通过组合几种多模态、多尺度和多分支的策略,我们提出了一个轻量级的AVSE模型(M3Net)。对于视频和音频分支,我们设计了三种多尺度的方法,即多尺度平均池化(Multi-scale average pooling, MSAP)、多尺度残差网络(Multi-scale ResNet, MSResNet)和多尺度短时傅里叶变换(Multi-scale short time Fourier transform, MSSTFT)。此外,对于音视频特征聚合,我们也设计了四种跳转连接(Skip Connection)方法。四种Skip Connections方法对上述的三种多尺度技术都有很好的补充效果。实验结果表明,这些技术可以灵活地与现有的方法结合使用。更重要的是,与重量级网络相比,以更小的模型大小获得了相当的性能。
05 Robust Data2vec: Noise-robust Speech Representation Learning for ASR by Combining Regression and Improved Contrastive Learning
论文作者:朱秋实,周龙,张结,刘树杰,胡宇晨,戴礼荣
论文单位:中国科学技术大学
论文资源:
论文预印版下载:https://arxiv.org/abs/2210.15324
论文简介:
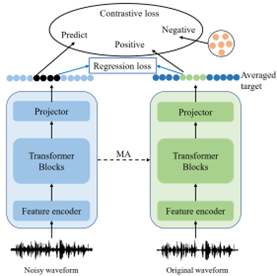
基于对比学习任务或回归任务的自监督预训练方法可以利用更多未标记的数据来提高语音识别(ASR)的性能。然而,将两个预训练任务结合起来并为对比学习构建不同的负样本能否提高模型的噪声鲁棒性仍然是未知的。在本文中,我们通过联合优化预训练阶段的对比学习任务和回归任务,提出了一种用于学习噪声鲁棒语音表征的模型:robust data2vec。此外,我们提出了两种改进的方法来提升模型性能。具体而言,我们首先构建基于patch的非语义负样本以提高预训练模型的噪声鲁棒性,这是通过将特征划分为不同大小的块(即所谓的负样本)来实现的。其次,通过分析正负样本的分布,我们提出去除容易区分的负样本,以提高预训练模型的判别能力。在CHiME-4数据集上的实验结果表明,我们的方法能够提高预训练模型在噪声场景中的性能。此外我们发现,与仅采用回归任务相比,对比学习和回归任务的联合训练可以在一定程度上避免模型崩塌。
06 Incorporating Lip Features into Audio-visual Multi-speaker DOA Estimation by Gated Fusion
论文作者:姜娅,陈航,杜俊,王青,李锦辉
论文单位:中国科学技术大学,佐治亚理工学院
论文简介:
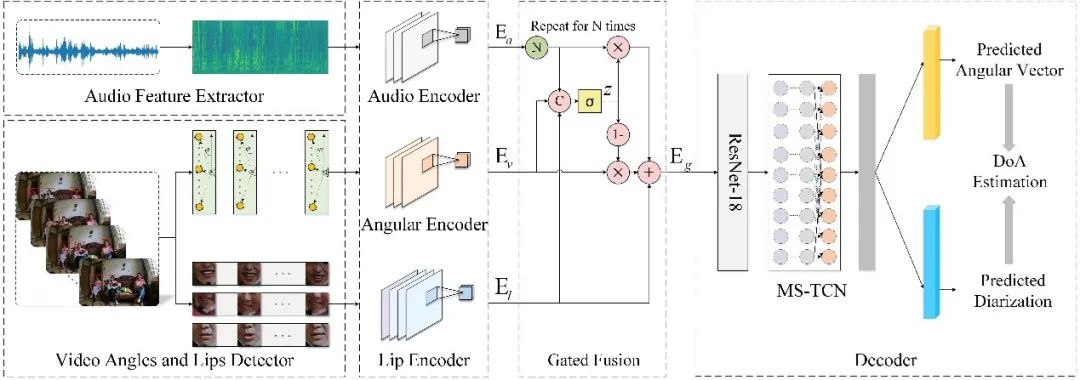
在本文中,我们提出了一种新的音视频多说话人DOA估计网络,该网络首次融合了多说话人的唇形特征,以适应复杂的多说话人重叠和背景噪声场景。首先,我们分别对多通道音频特征、视频中检测到的多说话人参考角度和唇型(RoI)进行编码。然后利用三模态门控融合模块将编码后的音频特征、多说话人的参考角度特征和唇形特征融合,以平衡它们对最终输出定位角度的贡献。融合后的特征被送入后端网络,通过联合网络预测的多说话人角度向量和活动概率来获得准确的DOA估计。实验结果表明,与之前在2021多模态信息语音处理(MISP)挑战赛数据集上所做的工作相比,该方法可以将定位误差减少73.48%,同时网络的定位精度相对提高了86.95%。定位结果的高精度和稳定性证明了所提出的模型在多说话人场景中的鲁棒性。
07 Quantum Tansfer Learning using the Large-scale Unsupervised Pre-trained Model WavLM-Large for Synthetic Speech Detection
论文作者:王若愚,杜俊,高天
论文单位:中国科学技术大学,科大讯飞
论文简介:
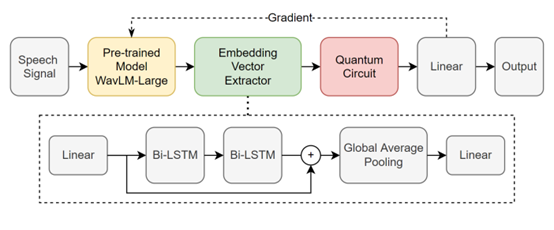
量子机器学习的发展展示了其相对于传统深度学习的量子优势,有望在有监督的分类数据集上发现新模式。这项工作提出了一个基于大规模无监督预训练模型的经典到量子的转移学习系统,以证明量子转移学习在合成语音检测方面的竞争性能。我们使用预训练模型WavLM-Large从语音信号中提取特征图,通过经典网络组件获得低维嵌入向量,然后用变量子电路(VQC)联合微调预训练模型和经典网络组件。我们在ASVspoof 2021 DF任务上对我们的系统进行了评估。使用量子电路模拟的实验表明量子传递学习可以提高经典传递学习基线的性能。经典转移学习基线在该任务上的表现。
08 Super Dilated Nested Arrays with Ideal Critical Weights and Increased Degrees of Freedom
论文作者:Ahmed M. A. Shaalan,杜俊
论文单位:中国科学技术大学,科大讯飞
论文简介:
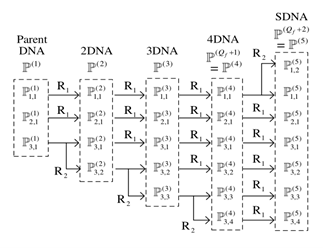
在本文中,最近引入的扩张嵌套阵列(DNA)的两个进一步的扩张,它拥有一个与嵌套阵列相同的虚拟ULA部分,但拥有两个虚拟ULA。它拥有与嵌套阵列相同的虚拟ULA部分,但拥有两个临界间距(2×λ/2)的密集物理ULA。本文介绍了最近引入的扩张嵌套阵列(DNA)的两个进一步的扩张,它们拥有与嵌套阵列相同的虚拟ULA部分,但拥有两个具有临界间距(2×λ/2)的密集物理ULA。介绍。在统一的父阵列数量不变的情况下 DOFs不变的情况下,在第一次扩张中,第一个密集的ULA 可以被重新排列Qf次,这样,所有的传感器对 与其中的临界传感器间的间距被完全 在一个指定的Q阶扩张嵌套阵列中被完全处理,对于 2≤Q≤Q_f+1,而在第二次扩张中,称为超级扩张嵌套阵列(SDNA)。而在被称为超级扩张嵌套阵列(SDNA)的第二次扩张中,Qth-阶DNA中的第二个密集的ULA也被重新排列。顺序的DNA也被重新排列,以便有固定的权重作为同质数组的那些。数值例子证明了这些阵列的优越性能。
09 Incorporating Visual Information Reconstruction into Progressive Learning for Optimizing Audio-Visual Speech Enhancement
论文作者:张辰悦,陈航,杜俊,殷保才,潘嘉,李锦辉
论文单位:中国科学技术大学,科大讯飞,佐治亚理工学院
论文简介:

传统的音视频语音增强网络将噪声语音和对应视频作为输入,直接学习干净语音的特征。为了减少学习目标和输入之间较大的信噪比差距,我们提出了一个基于mask的渐进式音视频语音增强框架(AVPL),同时结合视觉信息重建(VIR),逐步提升信噪比。AVPL的每一个阶段输入预训练的视觉嵌入(VE)和特定音频特征,预测提升一定信噪比后的mask。为提取更丰富的视觉特征,AVPL-VIR模型的每个阶段还将重建输入的视觉特征VE。在TCD-TIMIT数据集上的实验表明,无论是单音频还是音视频的渐进式学习,都明显优于传统的单步学习。此外,由于AVPL-VIR提取了更充分的视觉信息,因此在AVPL的基础上带来了进一步的提升。
10 An Experimental Study on Sound Event Localization and Detection under Realistic Testing Conditions
论文作者:牛树同,杜俊,王青,柴丽,吴华鑫,念朝旭,孙磊,方义,潘嘉,李锦辉
论文单位:中国科学技术大学,科大讯飞,佐治亚理工学院
论文简介:
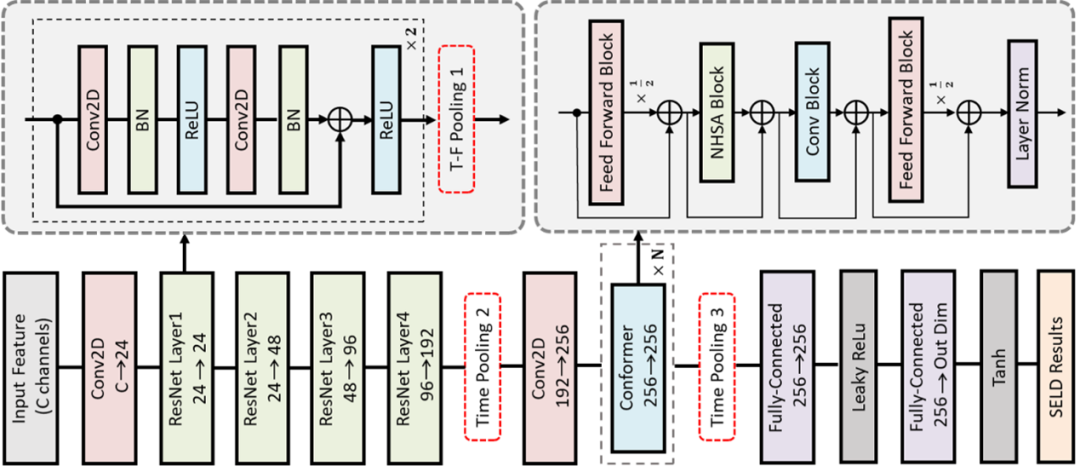
针对真实场景中的声音事件检测和定位任务(SELD),我们探索了四种数据扩增的方法和两种模型结构。在SELD任务中,相比于仿真的数据,真实数据由于房间中的混响和声音重叠段的存在更难处理。在这种情况下,我们首先基于ResNet-Conformer结构,在真实的DCASE 2022 数据集上比较了四种数据扩增方法。实验表明,由于仿真测试集和真实测试集之间的不匹配,除了语音通道交换(ACS)方法外,其余的三种在仿真数据集上可行的数据扩增方法在真实测试集上效果不明显。此外,在使用ACS的情况下,我们提出的改进的ResNet-Conformer进一步提升了SELD任务的性能。通过结合上述的两项技术,我们最终的系统在DCASE 2022挑战赛中取得了第一名的成绩。
11 Loss Function Design for DNN-Based Sound Event Localization and Detection on Low-Resource Realistic Data
论文作者:王青,杜俊,念朝旭,牛树同,柴丽,吴华鑫,潘嘉,李锦辉
论文单位:中国科学技术大学,科大讯飞,佐治亚理工学院
论文简介:
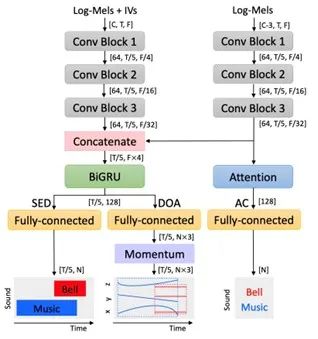
本研究重点关注基于深度神经网络(DNN)模型的损失函数设计,该模型由两个分支组成,用于解决低资源实际数据的声音事件定位与检测(SELD)。为此,我们提出了一个用于音频分类的辅助网络,为主网络提供全局事件信息,以使SELD预测结果更加稳健。此外,基于声音事件在时间维度上具有较强的连贯性,我们对到达方向(DOA)估计引入了一种动量策略,有效减少了定位误差。此外,我们在损失函数中添加了正则化项,以减轻小数据集上的模型过拟合问题。在声学场景和事件的检测与分类(DCASE)2022挑战赛任务3数据集上进行测试,实验表明这三种方法可以一致地提高SELD性能。与基线系统相比,所提出的损失函数在实际数据上的定位和检测精度都有显著改善。
12 The Multimodal Information based Speech Processing (Misp) 2022 Challenge: Audio-visual Diarization and Recognition
论文作者:王喆, 吴世龙, 陈航, 何茂奎, 杜俊, 李锦辉, 陈景东, Shinji Watanabe, Sabato Siniscalchi, Odette Scharenborg, 刘迪源, 殷保才, 潘嘉, 高建清, 刘聪
论文单位:中国科学技术大学,佐治亚理工学院,西北工业大学,卡内基梅隆大学,恩纳大学,代尔夫特理工大学,科大讯飞
论文资源:开源代码下载:https://github.com/mispchallenge/misp2022_baseline
论文简介:
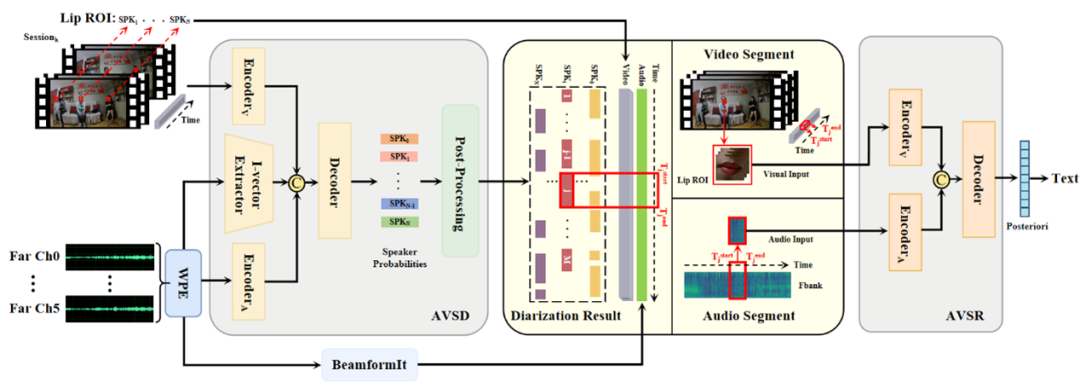
MISP (Multi-modal Information based Speech Processing,多模态信息语音处理)挑战赛旨在通过促进唤醒词、说话人日志、语音识别等技术的研究,扩展信号处理技术在特定场景中的应用。MISP2022挑战赛包括两个赛道:1)音视频说话人日志(AVSD),旨在利用音频和视频数据解决“谁在什么时候说话”;2)全新的音视频日志和识别(AVDR)任务,重在利用音视频说话人日志结果解决“谁在什么时候说了什么”的问题。两个赛道均聚焦于中文,使用真实家庭电视场景(2-6个人在电视噪音的背景下相互交流)中的远场音频和视频。本文介绍了MISP2022挑战的数据集、赛道设置和基线。我们对实验和实例的分析表明,AVDR基线系统具有良好的性能,但由于远场视频质量、背景中存在电视噪声和难以区分的说话人等原因,这一挑战存在困难性。
13 An Effective Anomalous Sound Detection Method based on Representation Learning with Simulated Anomalies
论文作者:陈晗,宋彦,卓著,周瑜,李裕宏,薛晖,Ian McLoughlin
论文单位:中国科学技术大学,新加坡理工大学,阿里巴巴
论文简介:
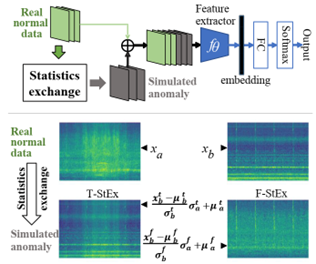
本文提出了一种基于数据拟合方法的异常声学检测系统。最近,许多ASD系统根据异常曝露(Outlier Exposure,OE)的策略在DCASE挑战赛中表现出不错的性能。这些方法将来自不同类别的正常样本视为伪异常样本并利用深度卷积神经网络来学习具有判别性的表征。然而,由于异常声音发生稀少,分布多样,并且在训练过程中不可利用,因此仅通过正常样本学习到的表征的能力可能是有限的。为了解决这个问题,我们提出了一种统计量变换(Statistic Exchange,StEx)的方法,该方法通过模拟异常样本来提高OE过程中表征学习的有效性。具体而言,从输入时频图的时间或频率维度中提取一阶和二阶统计量,然后通过交换不同类别的时频图的静态信息来生成模拟的异常数据。此外,我们还引入了离群(Out-of-Distribution,OOD)指标作为定性分析OE能力的重要度量,从而能够为ASD系统选择合适的异常模拟样本。在DCASE2021 Task2的开发数据集上进行的大量实验验证了基于OE的ASD模拟异常表征学习方法的有效性。
14 Joint Generative-Contrastive Representation Learning for Anomalous Sound Detection
论文作者:曾晓敏,宋彦,卓著,周瑜,李裕宏,薛晖,戴礼荣,Ian McLoughlin
论文单位:中国科学技术大学,新加坡理工大学,阿里巴巴
论文简介:
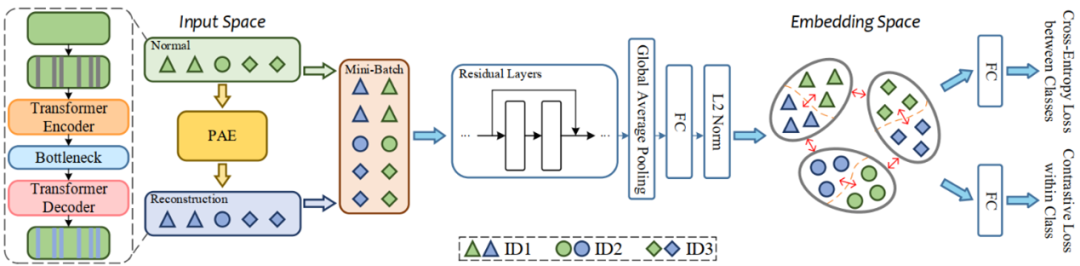
本文提出了一种联合生成式和对比学习(Generative-Contrastive,GeCo)的异常声学检测表征学习方法。在GeCo方法中,具有自注意力机制的预测自编码器(Predictive AutoEncoder,PAE)作为生成式模型,被用于实现帧级预测。同时,PAE的输出与原始正常样本共同用于多任务框架下的有监督对比表征学习。除类间交叉熵损失外,有监督对比学习损失被用于分离类内的原始正常样本和PAE的输出样本。基于PAE的自注意力机制,GeCo能够更好地捕获帧间上下文信息。此外,GeCo对生成式方法和对比学习的融合,使得模型提取的特征更有效且更具信息量。在DCASE2020 Task2开发集上的实验结果证明了GeCo的有效性。
15 AST-SED: An Effective Sound Event Detection Method based on Audio Spectrogram Transformer
论文作者:李康,宋彦,戴礼荣,Ian McLoughliln,方昕,柳林
论文单位:中国科学技术大学,新加坡理工大学,科大讯飞
论文简介:
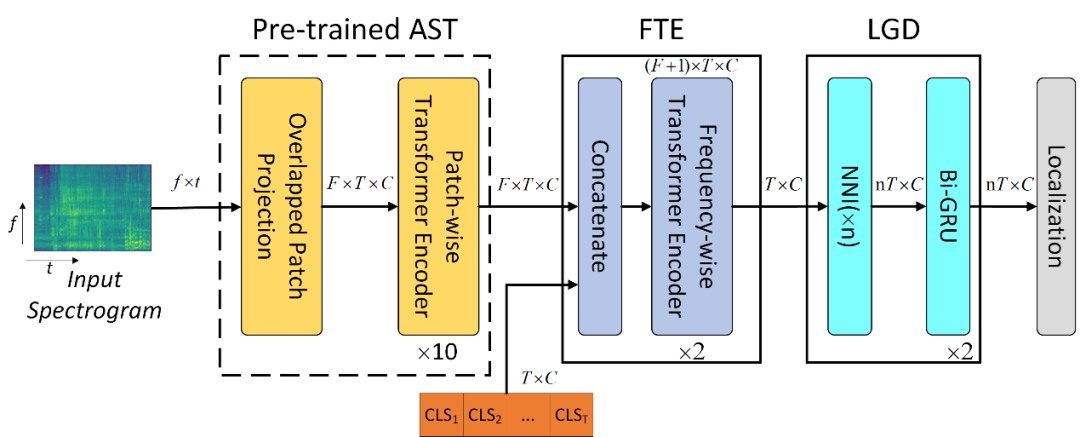
大规模数据预训练的AST(Audio Spectrogram Transformer)模型在声音事件分类任务(AT)上取得了很好的性能,但是直接利用AST的输出特征做声音事件检测任务(SED)不是最优的,对此,本文提出了一种编码器-解码器(Encoder-Decoder)的下游任务模块来高效地微调AST模型,在频率方向编码器中(Frequency-wise transformer encoder,FTE),采用了频率方向的多头自注意力机制来提高模型对一段音频中多种声音事件的辨别能力,在局部GRU解码器(Local GRU Decoder,LGD)中,将最近邻插值(NNI)和GRU组合,沿时间方向解码出高时间分辨率特征用于检测任务。在DCASE 2022 Task4 开发集上的结果表明,本文所提出的下游任务模块能大幅提高AST做检测任务的性能,且无需重新设计AST结构。
16 StarGAN-VC based Cross-Domain Data Augmentation for Speaker Verification
论文作者:胡航瑞,宋彦,张建涛,戴礼荣,Ian McLoughlin,卓著,周瑜,李裕宏,薛晖
论文单位:中国科学技术大学,新加坡理工大学,阿里巴巴
论文简介:
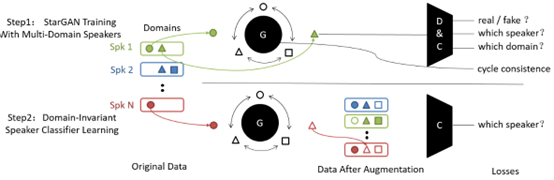
说话人识别系统(ASV)在实际应用时,往往面临复杂的域偏移问题(例如信道环境或说话风格等不同),从而出现显著的性能下降。由于单说话人多条件(SSMC)数据难以收集,现有的域自适应方法难以保证同类别特征的跨域一致性。为此,本文提出了一种基于StarGAN-VC的跨域数据增强方法。受语音转换(VC)任务的启发,我们首先从训练集的SSMC数据中学习通用的同说话人跨域转换规律;再用其对全体数据进行跨域数据增强,从而提升训练集的类内多样性。考虑到ASV任务和VC任务的侧重点不同,我们对生成模型的训练超参数以及模型结构进行了适当的调整。我们在CNCeleb数据集上进行了实验验证,所提方法取得了约5-8%的相对基线提升,且与传统数据增强方法互补。
17 Self-Supervised Audio-Visual Speech Representations Learning by Multimodal Self-Distillation
论文作者:张景宣,万根顺,凌震华,潘嘉,高建清,刘聪
论文单位:中国科学技术大学,科大讯飞
论文简介:

本文提出了一种新的AV2vec模型,该模型基于多模态自蒸馏方法进行音视频语音表征学习。AV2vec模型采用了一个教师网络和一个学生网络。学生模型在训练中采用了掩码隐层特征回归的任务进行训练,而学生模型学习的目标特征是教师网络在线生成得到的。教师网络的模型参数是学生网络模型参数的指数平滑。因为本文提出的AV2vec模型的目标特征是在线生成的,AV2vec模型不需要像AV-HuBERT模型那样需要迭代训练,所以它的训练时间大幅度地减小到了AV-HuBERT模型的1/5。我们在本文中进一步提出了AV2vec-MLM模型,该模型基于类掩码语言模型的损失函数对AV2vec模型进行了进一步扩展。我们的实验结果表明,AV2vec模型的性能表现和AV-HuBERT基线相当。当进一步引入类掩码语言模型损失函数时,AV2vec-MLM在唇语识别、语音识别以及多模态语音识别的下游任务上都取得了最好的实验效果。
18 Reducing the gap between streaming and non-streaming Transducer-based ASR by adaptive two-stage knowledge distillation
论文作者:唐海桃,付钰,孙磊,薛嘉宾,刘丹,李永超,马志强,吴明辉,潘嘉,万根顺,赵明恩
论文单位:科大讯飞,浙江大学,哈尔滨工业大学
论文简介:
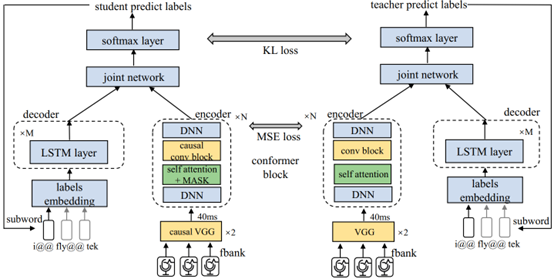
Transducer是流式语音识别的主流框架之一。由于上下文受限,流式Transducer模型和非流式之间存在性能差距。为了减小这种差距,一种有效的方法是确保它们的隐藏层和输出分布是一致的,这可以通过分层知识蒸馏来实现。然而,由于输出分布的学习依赖于隐藏层,同时确保流式和非流式分布的一致性比较困难。本文提出了一种自适应两阶段知识蒸馏方法,包括隐藏层学习和输出层学习。在前一阶段,我们通过应用均方误差损失函数学习完整上下文的隐藏表示。在后一阶段,我们设计了一种基于幂变换的自适应平滑方法来学习稳定的输出分布。在LibriSpeech数据集上,相比于原始流式Transducer,WER相对降低19%和拥有更快首字响应。








![Python 不同分辨率图像峰值信噪比[PSNR]](https://img-blog.csdnimg.cn/0365b62292c24903aaceb225a754e8ca.jpeg)