1.什么是LSTM
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
LSTM区别于RNN地方,主要就在于它在算法中加入了一个判断信息有用与否的"处理器",这个处理器作用的结构被称为cell。一个cell当中被放置了三扇门,分别叫做输入门、遗忘门和输出门。一个信息进入LSTM的网络当中,可以根据规则来判断是否有用。只有符合算法认证的信息才会留下,不符的信息则通过遗忘门被遗忘。
2.LSTM的优势
2-1 LSTM架构
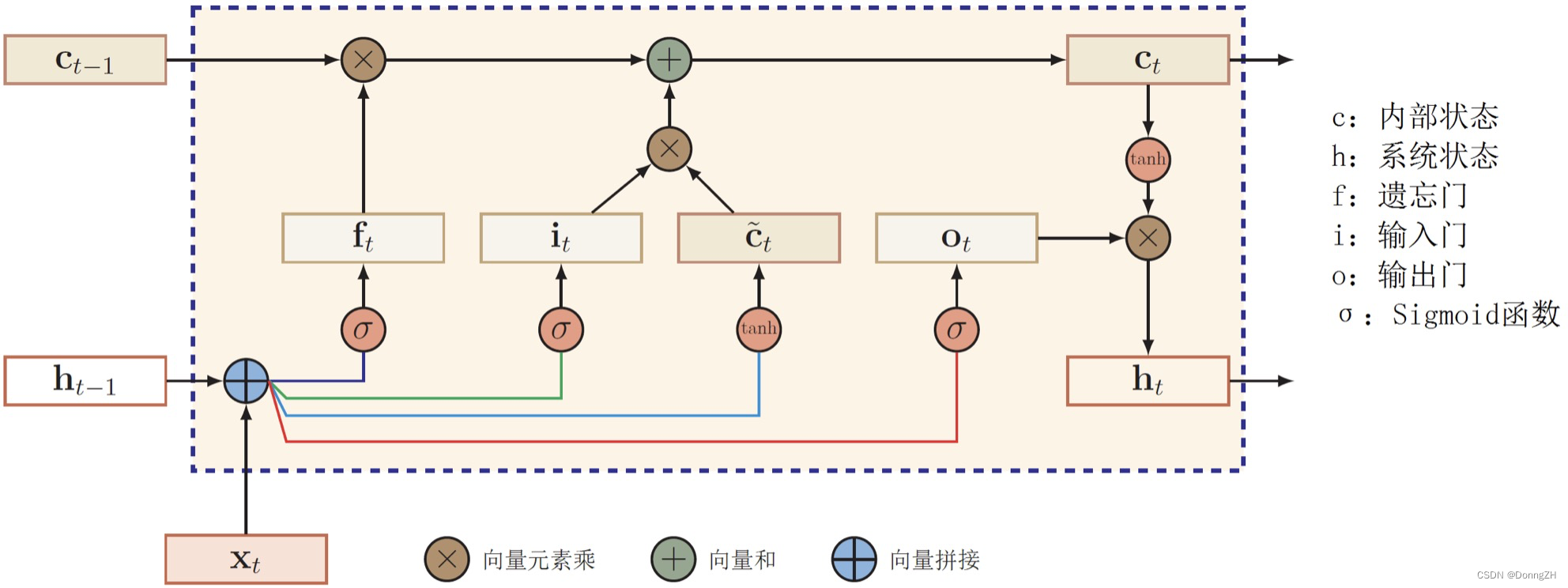
相比于RNN,LSTM的结构增加了三个门“遗忘门”、“输入门”、“输出门”。LSTM靠着一些“门”结构让信息有选择地影响循环神经网络中每个时刻的状态,所谓“门”结构,就是使用一个sigmoid的全连接层和一个按位做乘法的操作,这两个结合起来就是一个“门”结构。之所以叫“门”结构是因为使用sigmoid作为激活函数的全连接神经网络会输出一个0到1之间的数值,描述当前输入的有多少信息量可以通过这个结构。当门全打开时(sigmoid全连接层输出为1时),全部信息都能通过;当门全部关上时(sigmoid全连接层输出为0时),任何信息不能通过。如下图为LSTM的整体结构图,其中黄色的框代表的是激活函数,其中σ代表sigmoid函数(0-1之间),tanh自然就是tanh函数(-1-1之间);粉色的圆圈代表的是向量之间的运算。
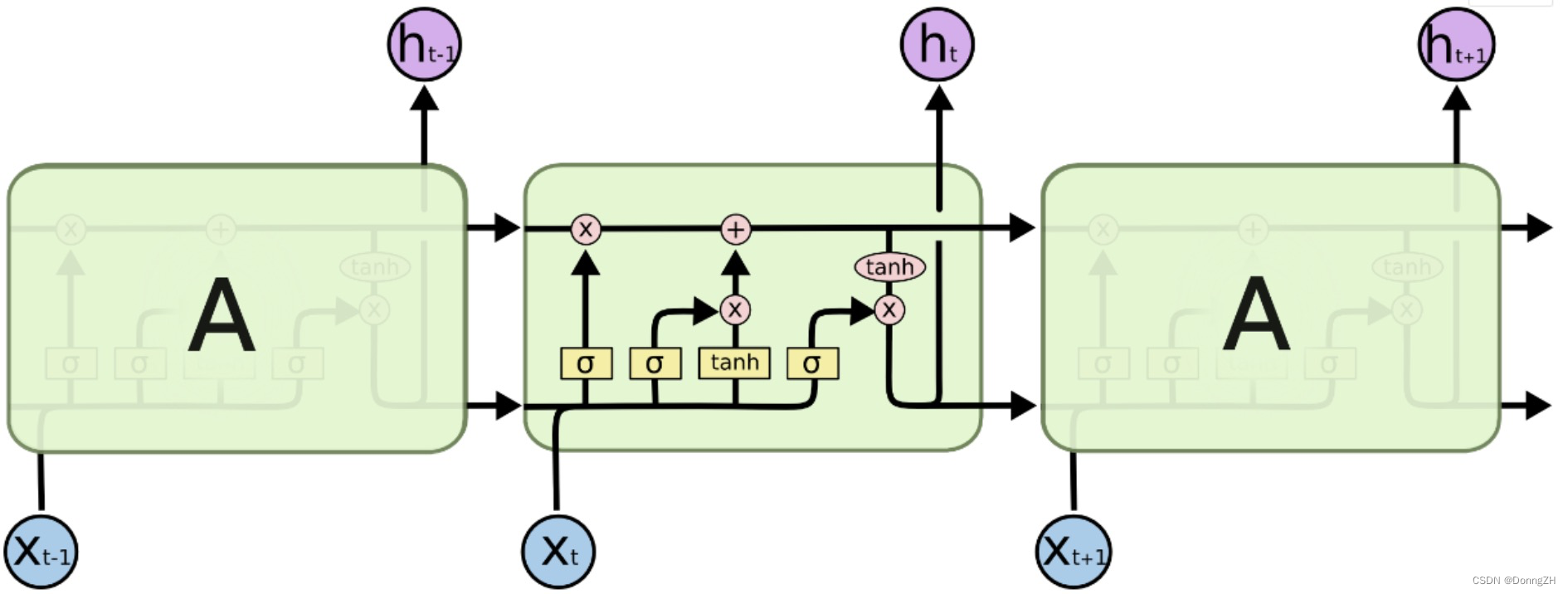
如下图为LSTM的内部结构图。
图中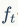 代表遗忘门,
代表遗忘门,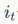 代表输入门,
代表输入门,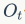 代表输出门。
代表输出门。是memroy cell,存储记忆信息。
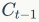 代表上一时刻的记忆信息,
代表上一时刻的记忆信息,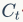 代表当前时刻的记忆信息,
代表当前时刻的记忆信息,是LSTM单元的输出,
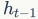 是前一刻的输出。
是前一刻的输出。
2-2 LSTM结构
2-2-1 细胞状态
LSTM的关键是细胞状态(直译:cell state),表示为 Ct ,用来保存当前LSTM的状态信息并传递到下一时刻的LSTM中。当前的LSTM接收来自上一个时刻的细胞状态 ,并与当前
LSTM接收的信号输入
共同作用产生当前LSTM的细胞状态
。
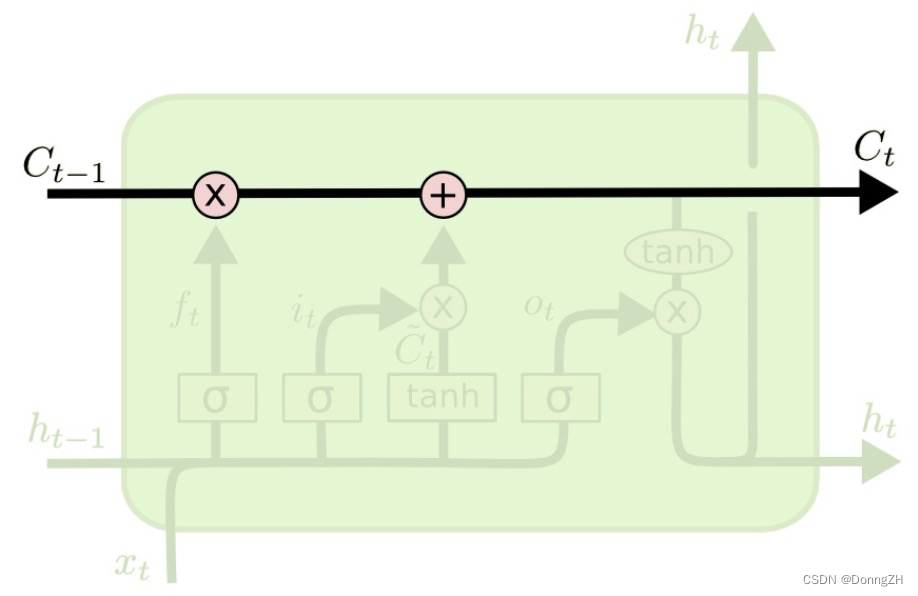
在LSTM中,采用专门设计的“门”来引入或者去除细胞状态 Ct 中的信息。门是一种让信息选择性通过的方法。有的门跟信号处理中的滤波器有点类似,允许信号部分通过或者通过时被门加工了;有的门也跟数字电路中的逻辑门类似,允许信号通过或者不通过。这里所采用的门包含一个神经网络层和一个按位的乘法操作。
2-2-2遗忘门
遗忘门决定了细胞状态 中的哪些信息将被遗忘。 遗忘门由一个sigmod神经网络层和一个按位乘操作构成。
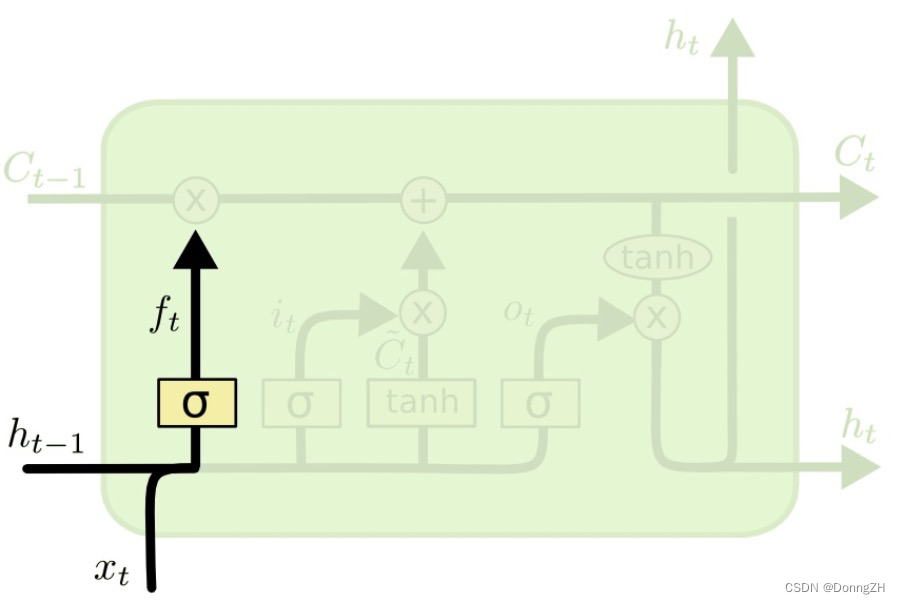
遗忘门包含一个sigmod神经网络层(黄色方框,神经网络参数为和
),接收t时刻的输入信号
和
时刻LSTM的上一个输出信号
,这两个信号进行拼接以后共同输入到神经网络层sigmod中,然后输出信号
,
是0-1到之间的数值,并与
相乘来决定
中的哪些信息将被保留,哪些信息将被舍弃。具体公式如下:
![]()
,
,
,那遗忘门的输入信号就是
和
的组合,
,然后通过sigmod神经网络层输出每个元素都是处于0-1之间的向量
与
按位相乘。
2-2-3 输入门
输入门的作用与遗忘门相反,它将决定新输入的信息和
中哪些信息将被保留。输入门包含两部分,一个是sigmod神经网络层(神经网络参数为
和
)和一个tanh神经网络层(神经网络参数为
和
)
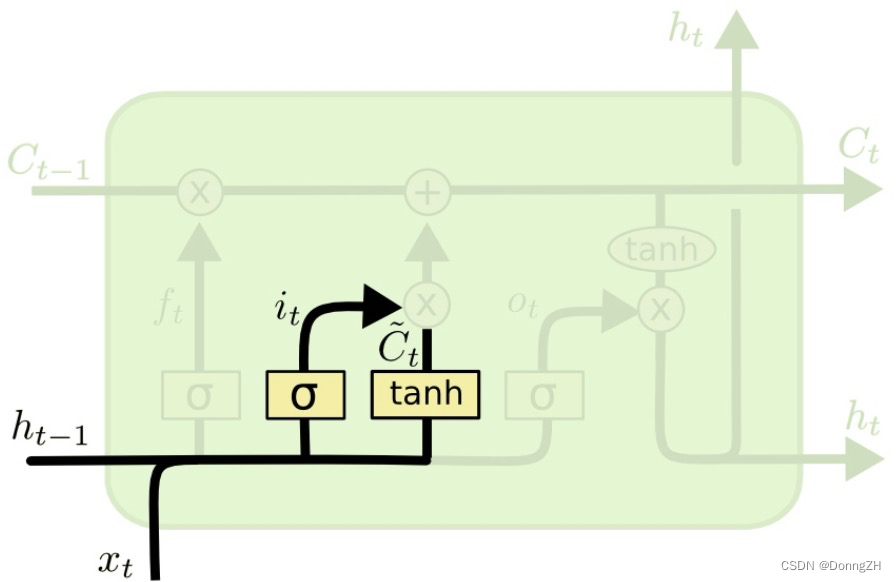
sigmod神经网络层的作用很明显,跟遗忘门一样,它接收 和
作为输入,然后输出一个0到1之间的数值
来决定哪些信息需要被更新;
![]()
Tanh神经网络层的作用是将输入的 和
整合,然后通过tanh神经网络层来创建一个新的状态候选向量
,
的值范围在-1到1之间。
![]()
输入门的输出由上述两个神经网络层的输出决定 与
相乘来选择哪些信息将被新加入到 时刻的细胞状态
中。
2-2-4 细胞状态更新
通过遗忘门和输入门,将可以细胞状态 Ct更新。

细胞状态更新公式如下:
![]()
将遗忘门的输出 与上一时刻的细胞状态
相乘来选择遗忘和保留一些信息,将输入门的输出与从遗忘门选择后的信息加和得到新的细胞状态
。这就表示t时刻的细胞状态
已经包含了此时需要丢弃的
时刻传递的信息和
时刻从输入信号获取的需要新加入的信息
。
将继续传递到
时刻的LSTM网络中,作为新的细胞状态传递下去。
2-2-5 输出门
输出门用来控制单元状态有多少输入到LSTM的当前输出
。由sigmod神经网络层和tanh激活函数以及按位乘操作组成。

和
作为输入,经过sigmod的神经网络层(神经网络层的网络参数为
和
),然后输出一个0到1之间的数值
;
![]()
经过一个tanh激活函数,此处需要注意的是(tanh是作为激活函数而不是神经网络层)得到一个在-1到1之间的树枝,并与
相乘得到输出信号
。之后
作为下一时刻的输入信号传递到下一阶段。
![]()
3.后记
LSTM通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息;而不像普通的RNN那样只能够“呆萌”地仅有一种记忆叠加方式。对很多需要“长期记忆”的任务来说,尤其好用。但也因为引入了很多内容,导致参数变多,也使得训练难度加大了很多。








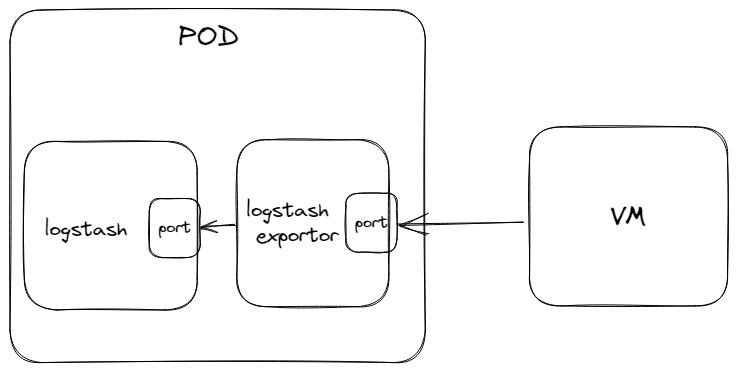
![【GO】k8s 管理系统项目23[前端部分–工作负载-Pod]](https://img-blog.csdnimg.cn/8a1fccb8065646748cc05b1da1b4ff04.png)