💡 作者:韩信子@ShowMeAI
📘 数据分析实战系列:https://www.showmeai.tech/tutorials/40
📘 机器学习实战系列:https://www.showmeai.tech/tutorials/41
📘 本文地址:https://showmeai.tech/article-detail/397
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏ShowMeAI查看更多精彩内容

异常值是偏离数据集中大多数样本点的数据点。出现异常值的原因有很多,例如自然偏差、欺诈活动、人为或系统错误。不过,在我们进行任何统计分析或训练机器学习模型之前,对数据检测和识别异常值都是必不可少的,这个预处理的过程会影响最后的效果。

大家可以查看ShowMeAI的文章 📘基于统计方法的异常值检测代码实战,我们图解详述了进行异常值检测可以用的统计方法。
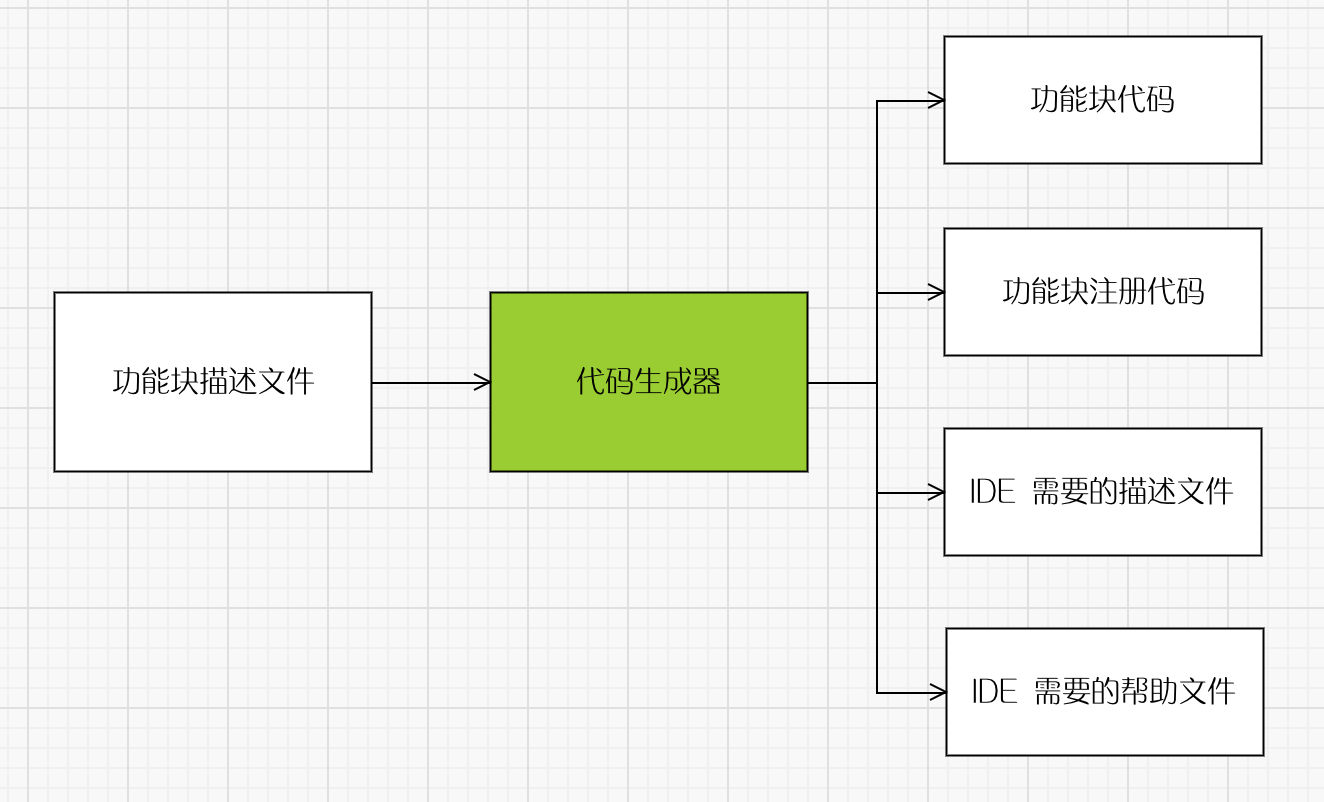
在本篇内容中,ShowMeAI将系统覆盖“单变量”和“多变量”异常值场景、以及使用统计方法和机器学习异常检测技术来识别它们,包括四分位距和标准差方法、孤立森林、DBSCAN模型以及 LOF 局部离群因子模型等。

💡 数据&场景方法概述
💦 数据
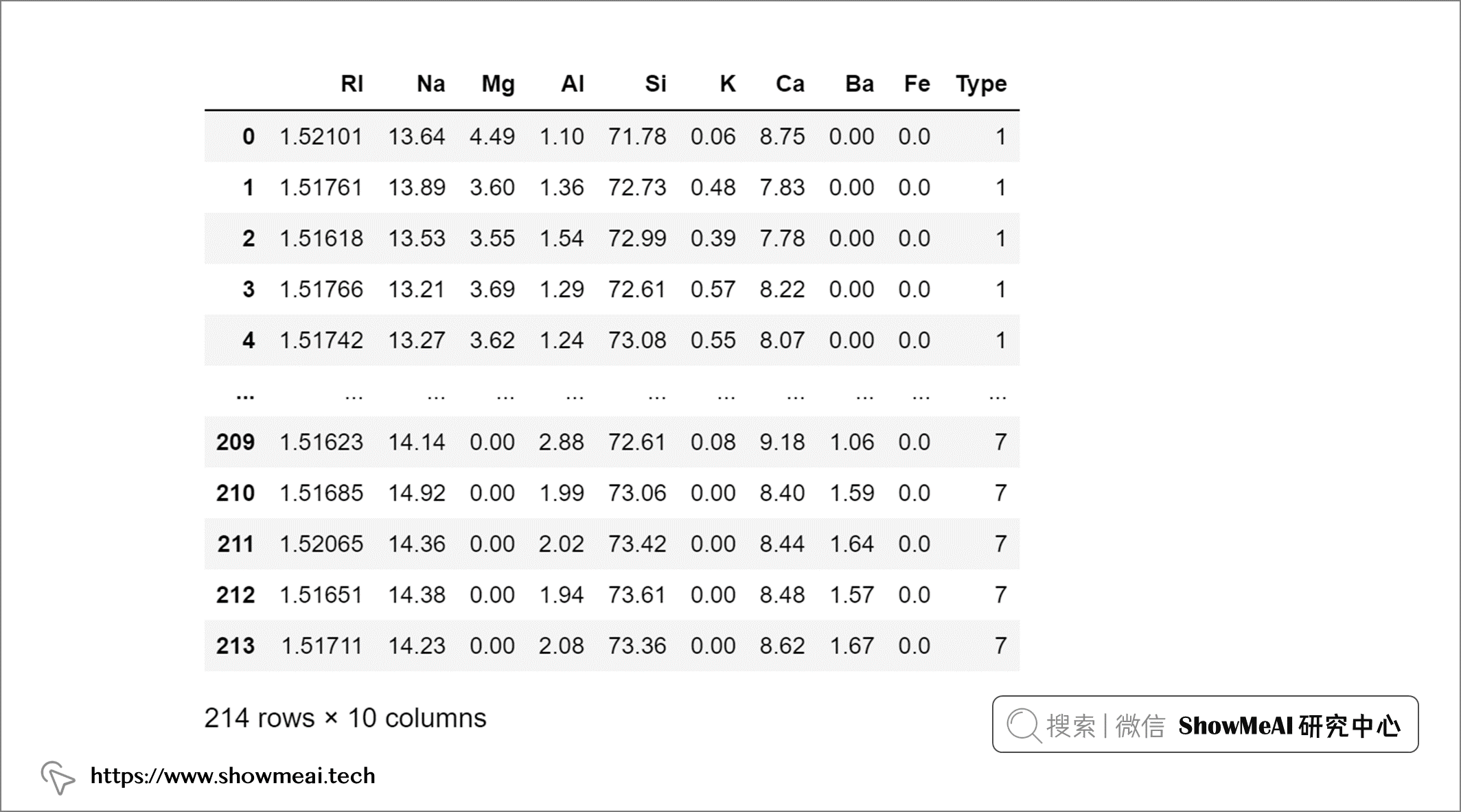
在本文中,我们将使用来自 UCI 的 🏆Glass Identification 数据集,数据集包含与玻璃含量和玻璃类型相关的 8 个属性。大家可以通过 ShowMeAI 的百度网盘地址下载。
🏆 实战数据集下载(百度网盘):公众号『ShowMeAI研究中心』回复『实战』,或者点击 这里 获取本文 [33]异常检测实战全景图:从统计方法到机器学习 『glass数据集』
⭐ ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub
我们加载数据并速览一下:
import pandas as pd
glass = pd.read_csv('glass.csv')
💦 单变量和多变量异常值
通过使用seaborn的pairplot我们可以绘制数据集不同字段之间的两两分布关系,可以可视化地查看数据的分布情况。

关于数据分析和可视化的知识与工具库使用,可以查看ShowMeAI的下述教程、文章和速查表
📘 图解数据分析:从入门到精通系列教程
📘 Python数据分析 | Seaborn工具与数据可视化
📘 数据科学工具库速查表 | Seaborn 速查表
import seaborn as sns
sns.pairplot(glass, diag_kws={'color':'red'})

pairplot 的结果包含两两数据的关联分析和每个变量的分布结果,其中对角线为单变量的分布可视化,我们发现并非所有属性字段都具有遵循正态分布。事实上,大多数属性都偏向较低值(即 Ba、Fe)或较高值(即 Mg)*。
如果要检测单变量异常值,我们应该关注单个属性的分布,并找到远离该属性大部分数据的数据点。例如,如果我们选择属性“Na”并绘制箱线图,可以找到哪些数据点在上下边界之外,可以标记为异常值。
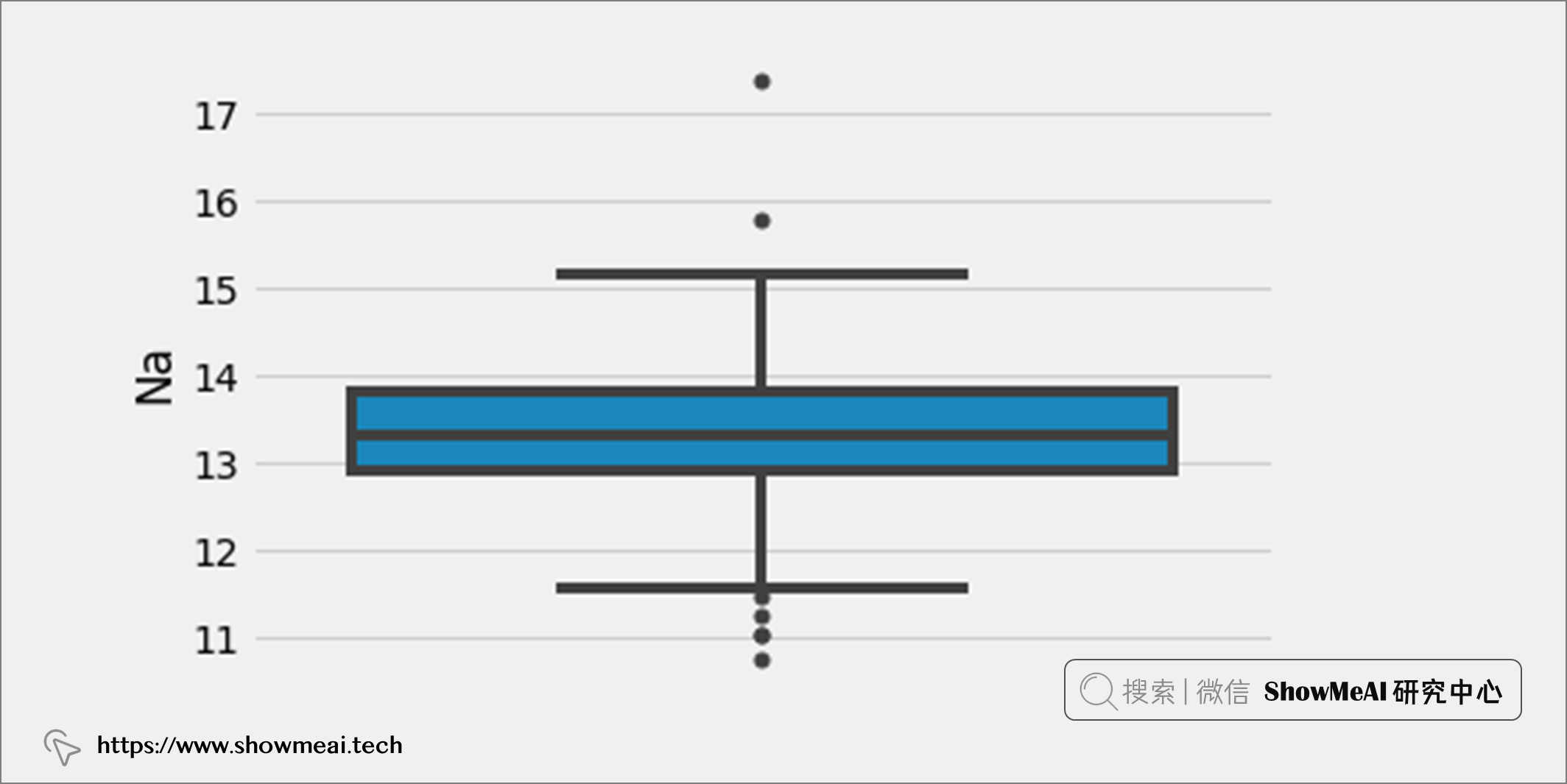
如果要检测多变量异常值,我们应该关注 n 维空间中至少两个变量的组合。例如,在上述数据集中,我们可以使用玻璃的所有八个属性并将它们绘制在 n 维空间中,并通过检测哪些数据点落在远处来找到多元异常值。
但是因为绘制三维以上的图非常困难,我们要想办法将八个维度的数据在低维空间内表征。我们可以使用PCA(主成分分析)降维方法完成,具体的代码如下所示:
关于数据降维原理和实践,可以查看ShowMeAI的下述文章:
📘图解机器学习 | 降维算法详解
from sklearn.decomposition import PCA
import plotly.express as px
# Dimensionality reduction to 3 dimensions
pca = PCA(n_components=3)
glass_pca = pca.fit_transform(glass.iloc[:, :-1])
# 3D scatterplot
fig = px.scatter_3d(x=glass_pca[:, 0],
y=glass_pca[:, 1],
z=glass_pca[:, 2],
color=glass.iloc[:, -1])
fig.show()
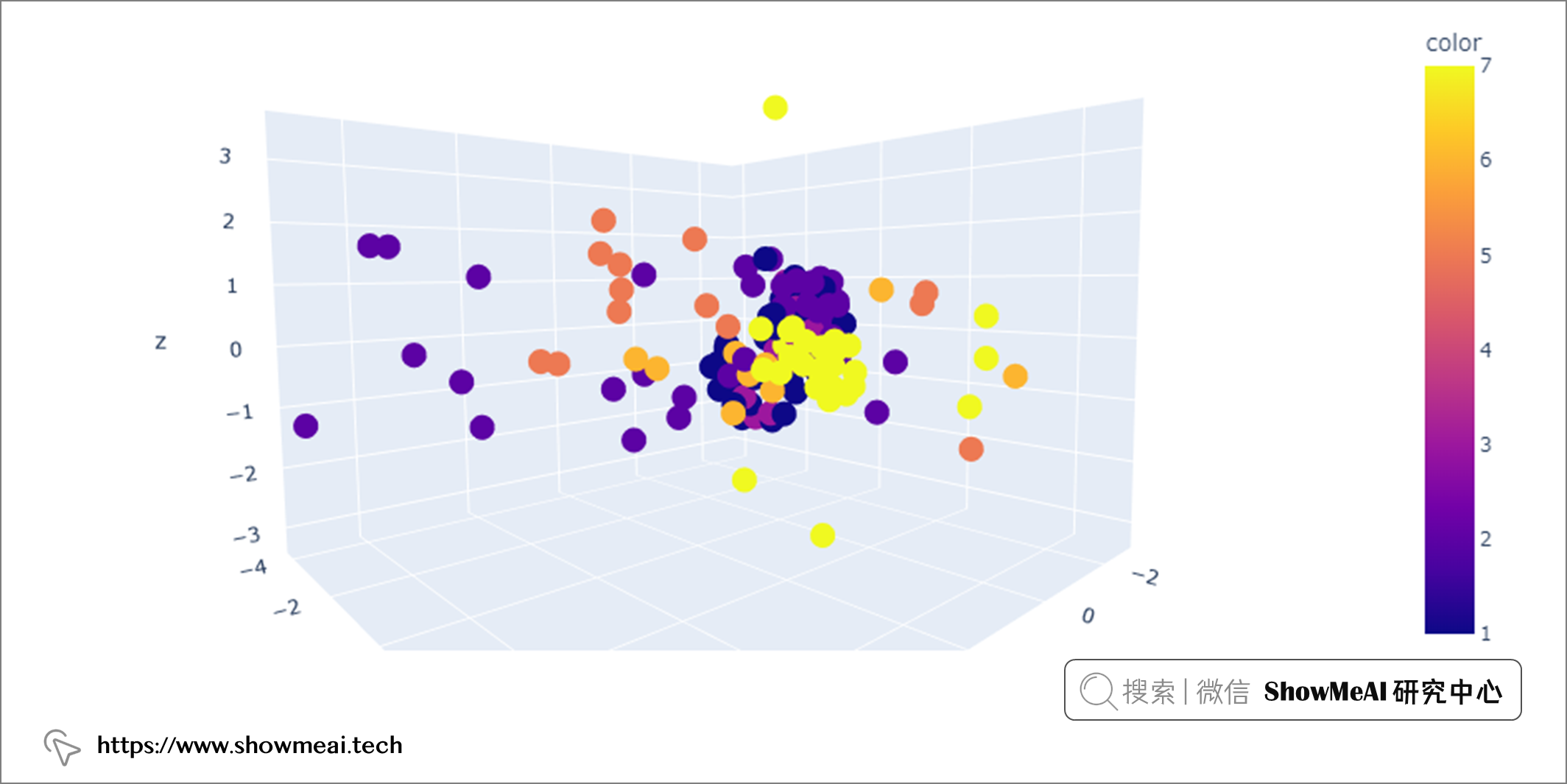
在上图中可以看到,有些数据点彼此靠近(组成密集区域),有些距离很远,可能是多变量异常值。
上面我们对异常值检测的场景方法做了一些简单介绍,下面ShowMeAI给大家系统讲解检测单变量和多变量异常值的方法。
💡 单变量异常值检测
💦 标准差法
假设一个变量是正态分布的,那它的直方图应遵循正态分布曲线(如下图所示),其中 68.2% 的数据值位于距均值1个标准差范围内,95.4% 的数据值位于距均值2个标准差范围内,99.7% 的数据值位于距均值3个标准差范围内。
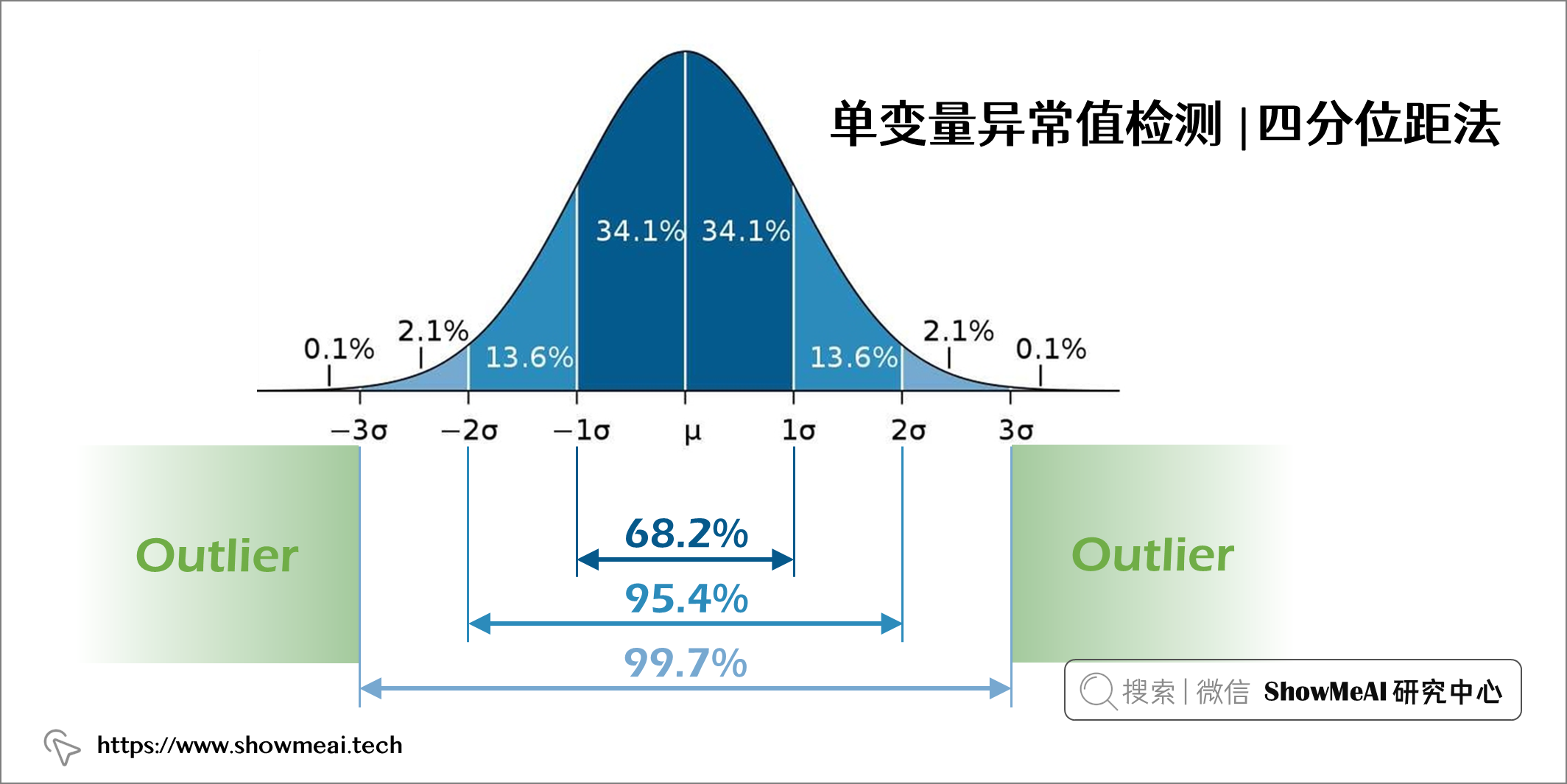
因此,如果有数据点距离平均值超过3个标准差,我们就可以将其视作异常值。这也是著名的异常检测3sigma法。具体的的代码实现如下:
# Find mean, standard deviation and cut off value
mean = glass["Na"].mean()
std = glass["Na"].std()
cutoff = 3 * std
# Define lower and upper boundaries
lower, upper = mean-cutoff, mean+cutoff
# Define new dataset by masking upper and lower boundaries
new_glass = glass[(glass["Na"] > lower) & (glass["Na"] < upper)]
通过使用标准偏差法,我们基于“Na”变量删除了2条极端记录。大家可以用同样的方法在其他属性上,检测和移除单变量异常值。
Shape of original dataset: (213, 9)
Shape of dataset after removing outliers in Na column: (211, 9)
💦 四分位距法
四分位数间距方法是一个基于箱线图的统计方法,它通过定义三个数据分布位点将数据进行划分,并计算得到统计边界值:
- 四分位数 1 (Q1) 表示第 25 个百分位数
- 四分位数 2 (Q2) 表示第 50 个百分位数
- 四分位数 3 (Q3) 表示第 75 个百分位数
箱线图中的方框表示 IQR 范围,定义为 Q1 和 Q3 之间的范围:IQR = Q3 — Q1
低于的数据点Q1 - 1.5*IQR或以上Q3 + 1.5*IQR被定义为异常值。如下图所示:
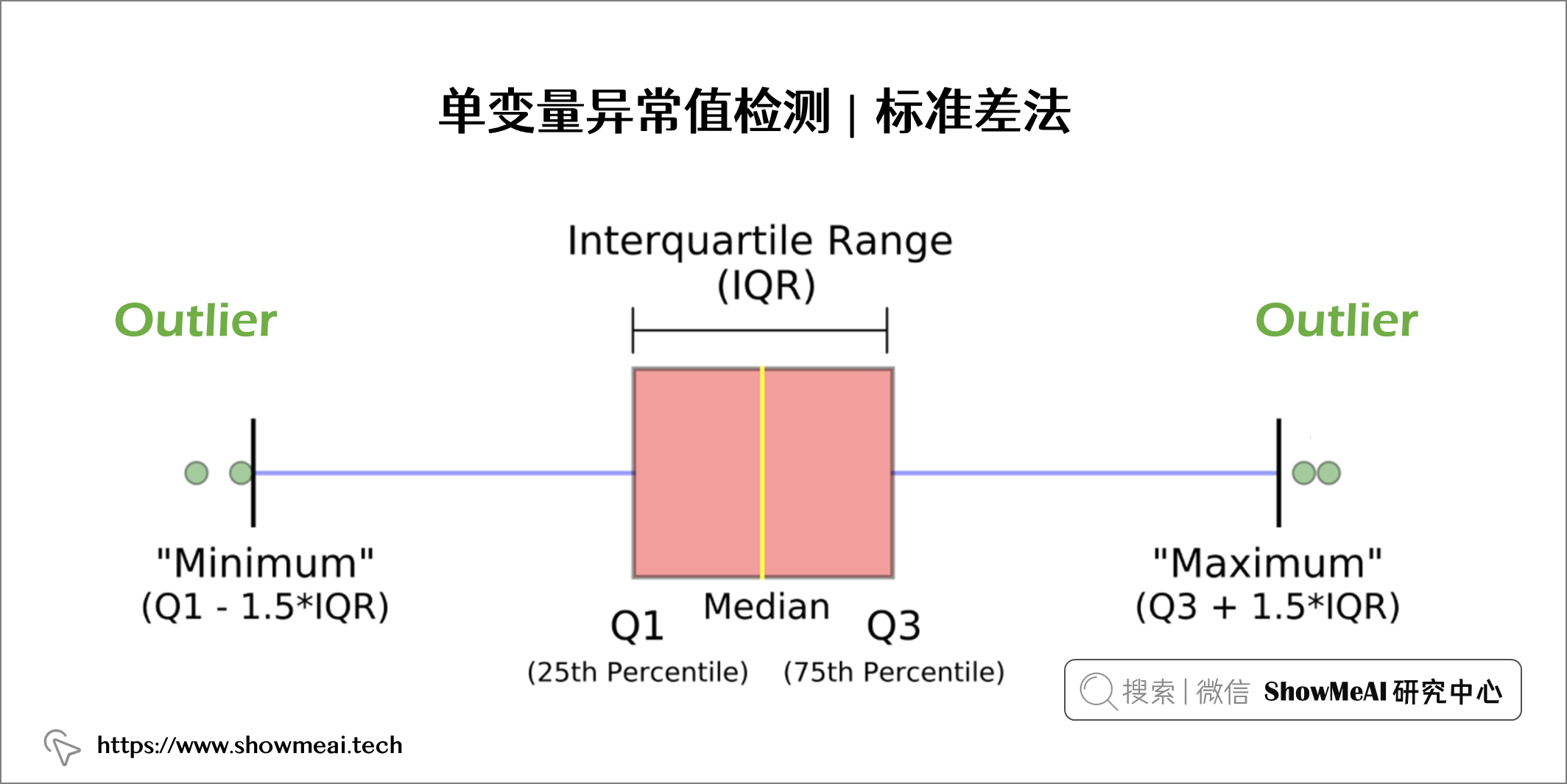
基于四分位距的异常检测代码实现如下所示:
# Find Q1, Q3, IQR and cut off value
q25, q75 = np.quantile(glass["Na"], 0.25), np.quantile(glass["Na"], 0.75)
iqr = q75 - q25
cutoff = 1.5 * iqr
# Define lower and upper boundaries
lower, upper = q25 - cutoff, q75 + cutoff
# Define new dataset by masking upper and lower boundaries
new_glass = glass[(glass["Na"] > lower) & (glass["Na"] < upper)]
Shape of original dataset: (213, 9)
Shape of dataset after removing outliers in Na column: (206, 9)
我们可以看到,基于 IQR 技术,从“Na”变量维度我们删除了七个记录。我们注意到,基于标准偏差方法只能找到 2 个异常值,是非常极端的极值点,但是使用 IQR 方法我们能够检测到更多(5 个不是那么极端的记录)。我们可以基于实际场景和情况决定哪种方法。
💡 多变量异常值检测
💦 孤立森林算法-Isolation Forest
📘孤立森林 是一种基于随机森林的无监督机器学习算法。我们都知道,随机森林是一种集成学习模型,它使用基模型(比如 100 个决策树)组合和集成完成最后的预估。
关于随机森林算法的详解可以参考ShowMeAI的下述文章 📘图解机器学习 | 随机森林分类模型详解
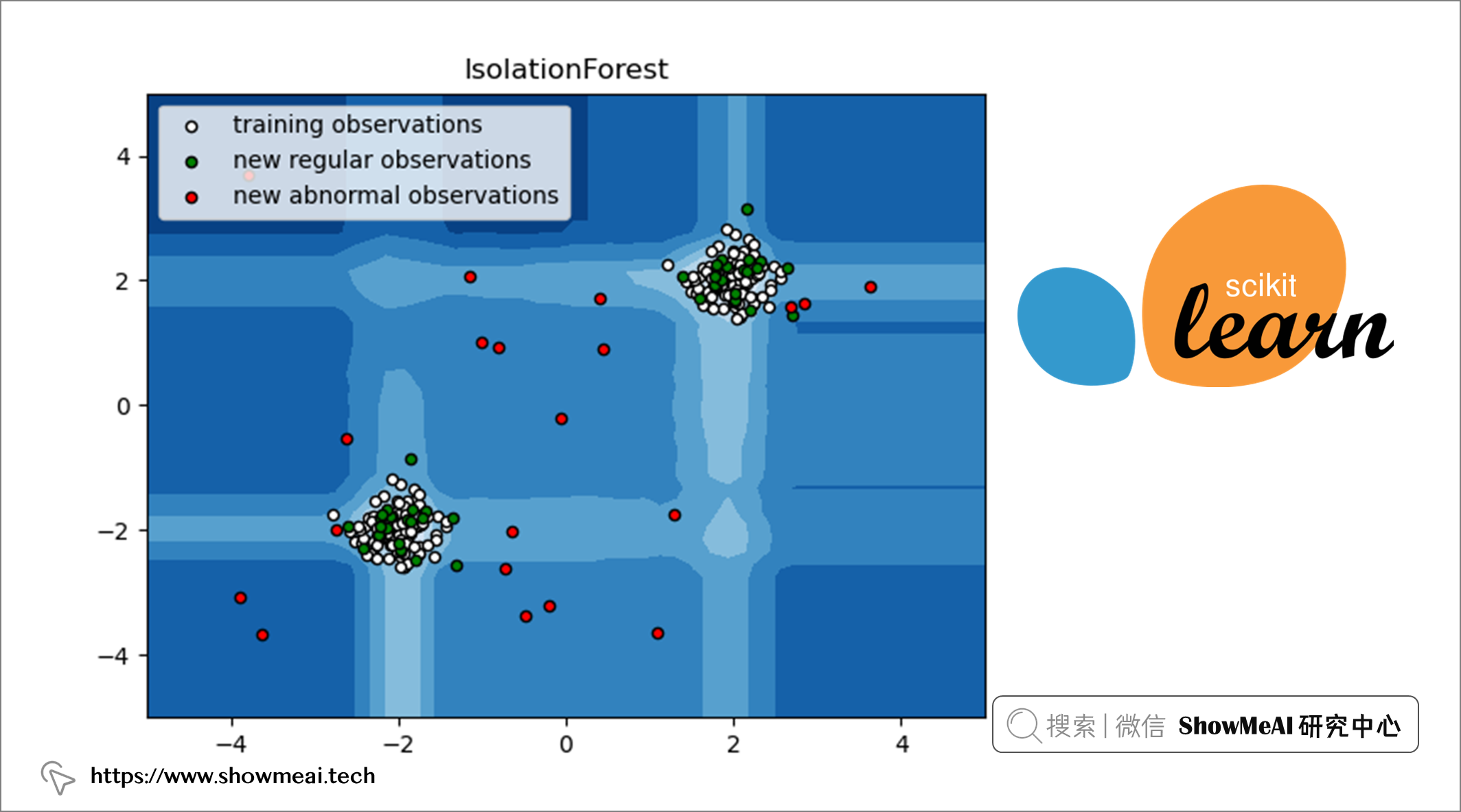
孤立森林遵循随机森林的方法,但相比之下,它检测(或叫做隔离)异常数据点。它有两个基本假设:离群值是少数样本,且它们是分布偏离的。
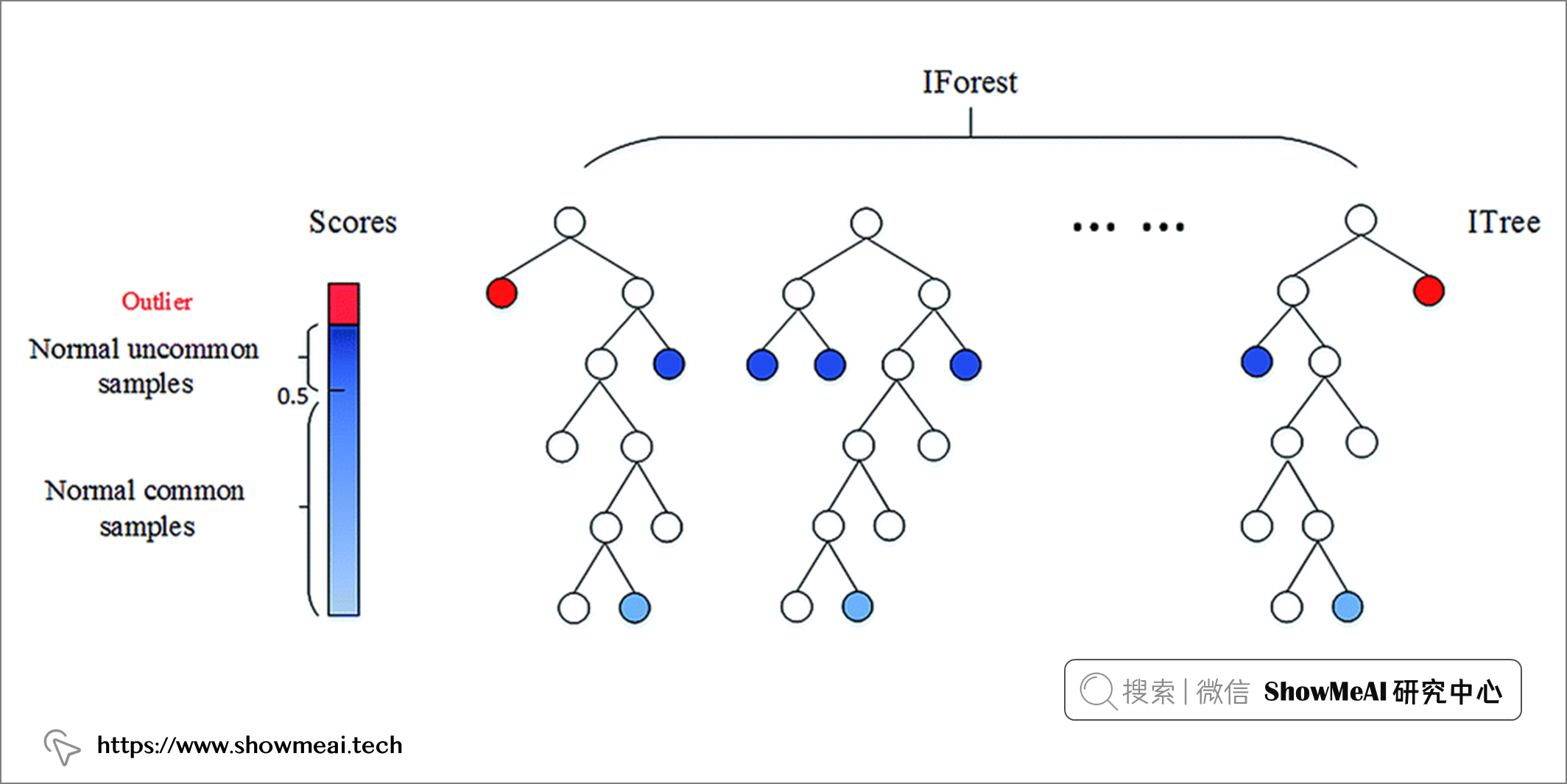
孤立森林通过随机选择一个特征,然后随机选择一个分割规则来分割所选特征的值来创建决策树。这个过程一直持续到达到设置的超参数值。在构建好的孤立森林中,如果树更短且对应分支样本数更少,则相应的值是异常值(少数和不寻常)。
我们一起来看看 scikit-learn 中的IsolationForest类对应应用方法:
from sklearn.ensemble import IsolationForest
IsolationForest(n_estimators=100, max_samples='auto', contamination='auto', max_features=1.0, bootstrap=False, n_jobs=None, random_state=None, verbose=0, warm_start=False)
Isolation Forest 算法有几个超参数:
n_estimators:表示要集成的基模型的数量。max_samples:表示用于训练模型的样本数。contamination:用于定义数据中异常值的比例。max_features:表示采样处的用于训练的特征数。
大家可以查看 📘文档 了解更多的信息。
from sklearn.ensemble import IsolationForest
# Initiate isolation forest
isolation = IsolationForest(n_estimators=100,
contamination='auto',
max_features=glass.shape[1])
# Fit and predict
isolation.fit(glass)
outliers_predicted = isolation.predict(glass)
# Address outliers in a new column
glass['outlier'] = outliers_predicted
我们通过将基模型的数量设置为 100,将最大特征设置为特征总数,将异常值占比设置为'auto',如果把它为 0.1,则总体 10% 的数据集将被定义为异常值。
我们在使用孤立森林学习后,调用 glass['outlier'].value_counts()可以看到有 19 条记录被标记为-1(即异常值),其余 195 条记录被标记为1(正常值)。
1 195
-1 19
Name: outlier, dtype: int64
像上文一样,我们可以通过使用 PCA 将特征降维到3个组件来可视化异常值。
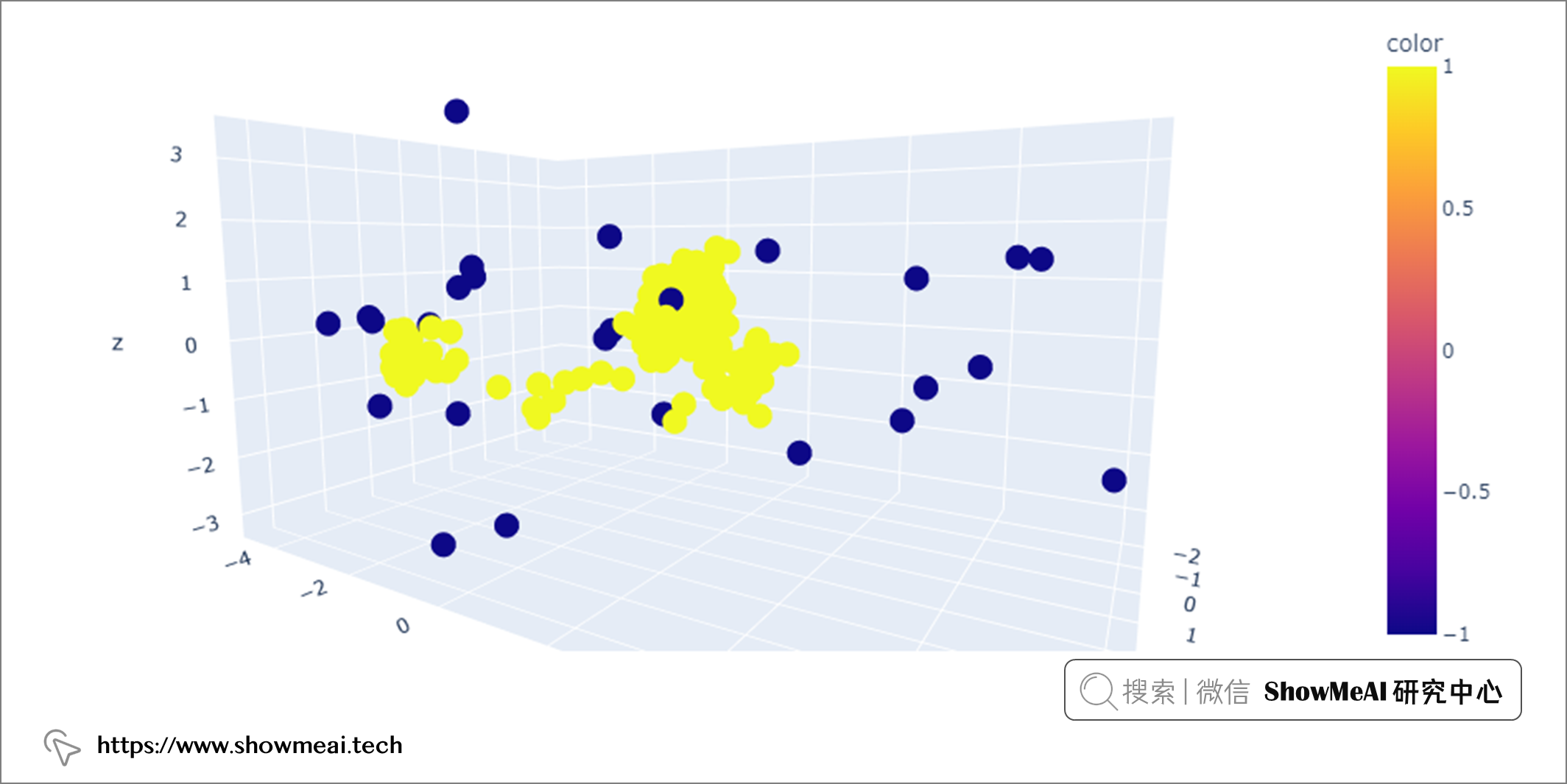
💦 基于空间密度的聚类算法-DBSCAN
📘DBSCAN 是一种流行的聚类算法,通常用作 K-means 的替代方法。它是基于分布密度的,专注于许多数据点所在的高密度区域。它通过测量数据之间的特征空间距离(即欧氏距离)来识别哪些样本可以聚类在一起。DBSCAN 作为聚类算法最大的优势之一就是我们不需要预先定义聚类的数量。
让我们看看如何基于 scikit-learn 来应用DBSCAN:
from sklearn.cluster import DBSCAN
DBSCAN(eps=0.5, min_samples=5, metric='euclidean', metric_params=None, algorithm='auto', leaf_size=30, p=None, n_jobs=None)
DBSCAN 有几个超参数:
eps(epsilon):考虑在同一个 cluster 中的两个数据点之间的最大距离。min_samples:核心点的接近数据点的数量。metric:用于计算不同点之间的距离度量方法。
大家可以查看 📘文档 了解更多的信息。
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import MinMaxScaler
# Initiate DBSCAN
dbscan = DBSCAN(eps=0.4, min_samples=10)
# Transform data
glass_x = np.array(glass).astype('float')
# Initiate scaler and scale data
scaler = MinMaxScaler()
glass_scaled = scaler.fit_transform(glass_x)
# Fit DBSCAN on scaled data
dbscan.fit(glass_scaled)
# Address outliers in a new column
glass['outlier'] = dbscan.labels_
在启动 DBSCAN 时,仔细选择超参数非常重要。例如,如果 eps 值选择得太小,那么大部分数据都可以归类为离群值,因为邻域区域被定义为更小。相反,如果 eps 值选择太大,则大多数点会被聚类算法聚到一起,因为它们很可能位于同一邻域内。这里我们使用 📘k 距离图 选择 eps 为 0.4。
import math
# Function to calculate k distance
def calculate_k_distance(X,k):
k_distance = []
for i in range(len(X)):
euclidean_dist = []
for j in range(len(X)):
euclidean_dist.append(
math.sqrt(
((X[i,0] - X[j,0]) ** 2) +
((X[i,1] - X[j,1]) ** 2)))
euclidean_dist.sort()
k_distance.append(euclidean_dist[k])
return k_distance
# Calculate and plot epsilon distance
eps_distance = calculate_k_distance(glass_scaled, 10)
px.histogram(eps_distance, labels={'value':'Epsilon distance'})
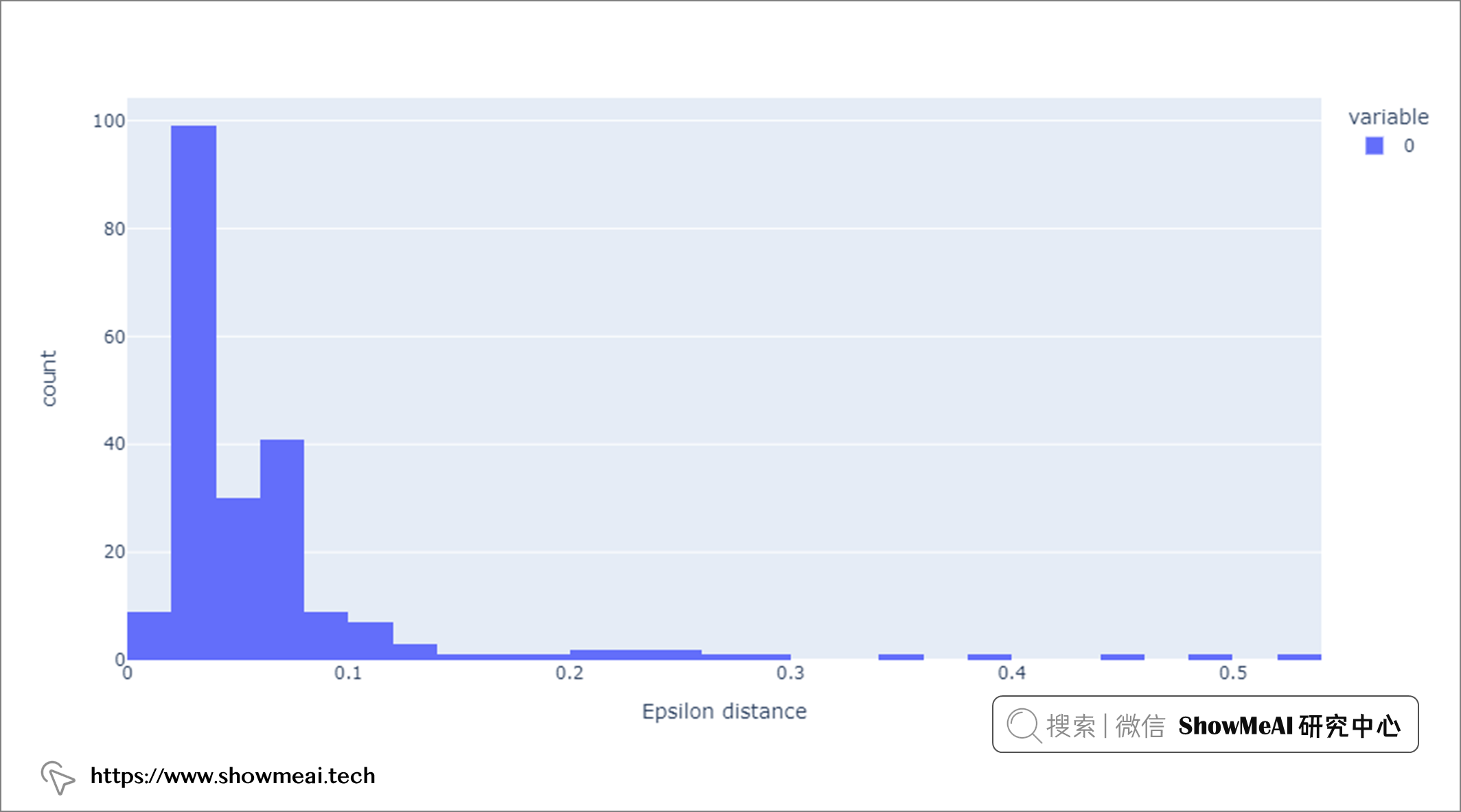
此外,min_samples是一个重要的超参数,通常等于或大于 3,大多数情况下选择 D+1,其中 D 是数据集的维度。在上述代码中,我们将min_samples设置为 10。
由于 DBSCAN 是通过密度来识别簇的,所以高密度区域是簇出现的地方,低密度区域是异常值出现的地方。经过DBSCAN建模,我们调用glass['outlier'].value_counts()可以看到有 22 条记录被标记为-1(异常值),其余 192 条记录被标记为1(正常值)。
0 192
-1 22
Name: outlier, dtype: int64
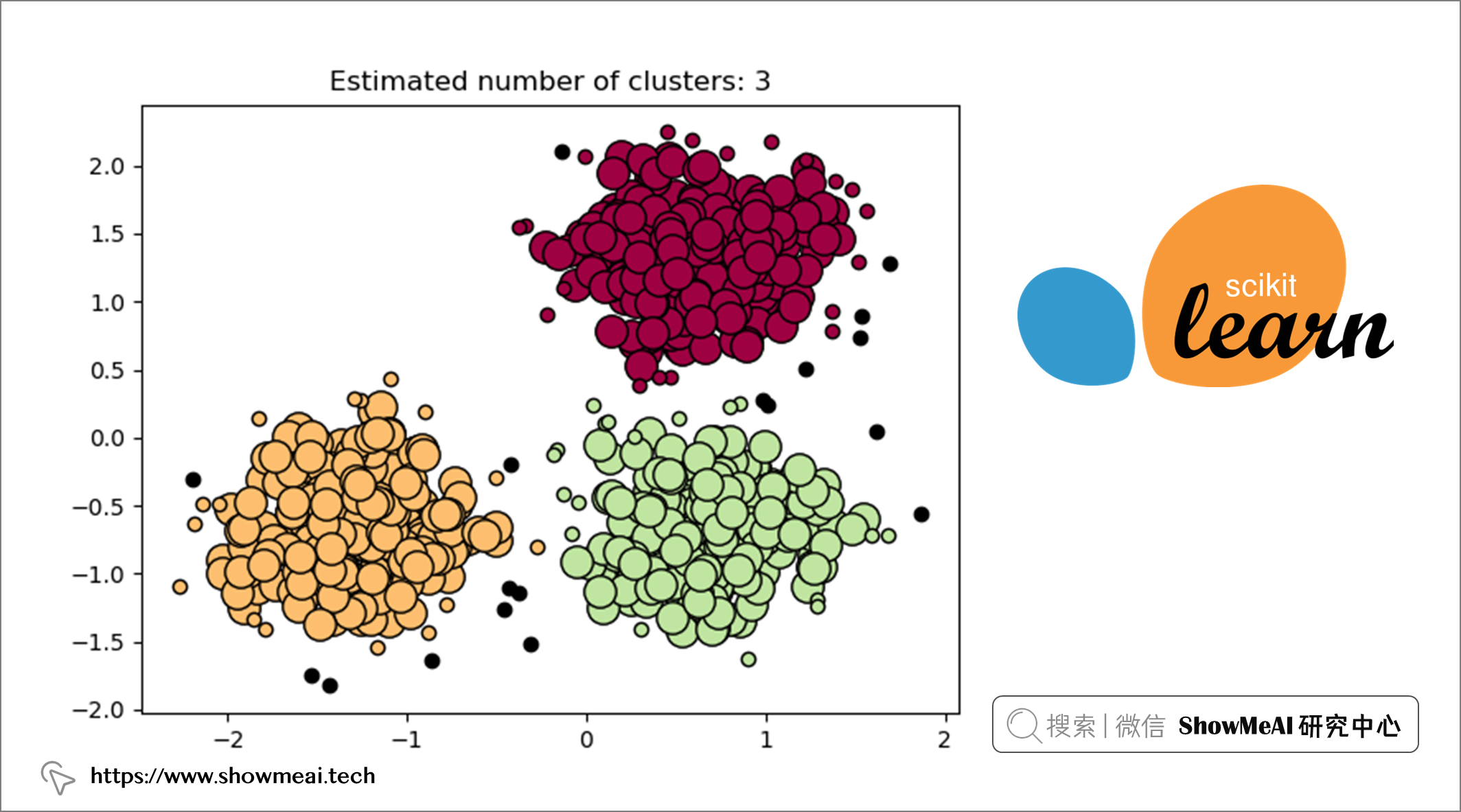
我们可以使用 PCA 可视化异常值。
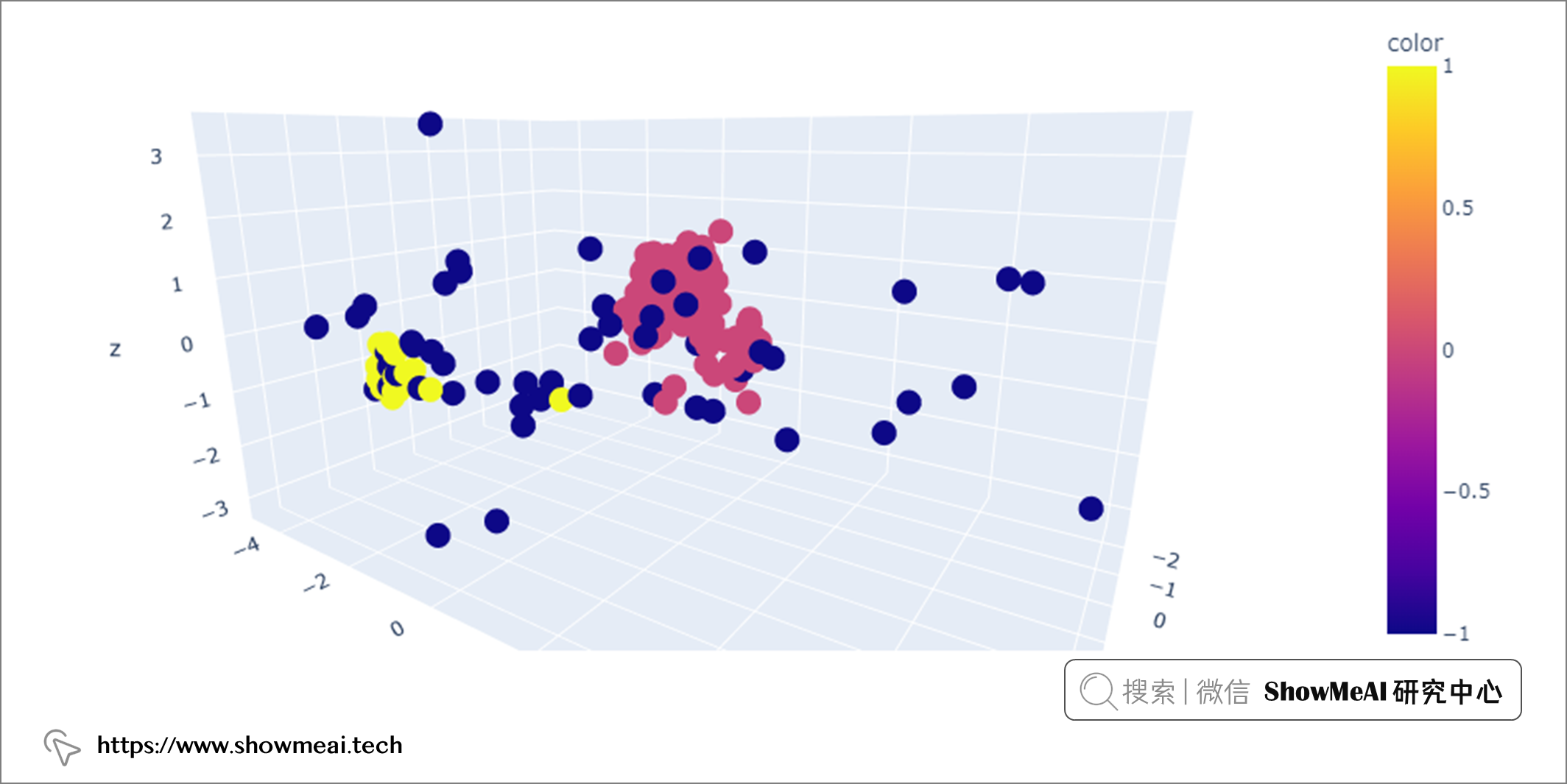
上图中,DBSCAN 检测到的异常值(黄色点)(eps=0.4,min_samples=10)
💦 局部异常因子算法-LOF
📘LOF 是一种流行的无监督异常检测算法,它计算数据点相对于其邻居的局部密度偏差。计算完成后,密度较低的点被视为异常值。
让我们看看基于 scikit-learn 的 LOF 实现。
from sklearn.neighbors import LocalOutlierFactor
LocalOutlierFactor(n_neighbors=20, algorithm='auto', leaf_size=30, metric='minkowski', p=2, metric_params=None, contamination='auto', novelty=False, n_jobs=None)
LOF 有几个超参数:
n_neighbors:用于选择默认等于 20 的邻居数量。contamination:用于定义离群值比例。
from sklearn.neighbors import LocalOutlierFactor
# Initiate LOF
lof = LocalOutlierFactor(n_neighbors=20, contamination='auto')
# Transform data
glass_x = np.array(glass).astype('float')
# Initiate scaler and scale data
scaler = MinMaxScaler()
glass_scaled = scaler.fit_transform(glass_x)
# Fit and predict on scaled data
clf = LocalOutlierFactor()
outliers_predicted = clf.fit_predict(glass)
# Address outliers in a new column
glass['outlier'] = outliers_predicted
LOF建模完成后,通过调用glass['outlier'].value_counts()我们可以看到有 34 条记录被标记为-1(异常值),其余 180 条记录被标记为1(正常值)。
1 180
-1 34
Name: outlier, dtype: int64
最后,我们可以使用 PCA 可视化这些异常值。
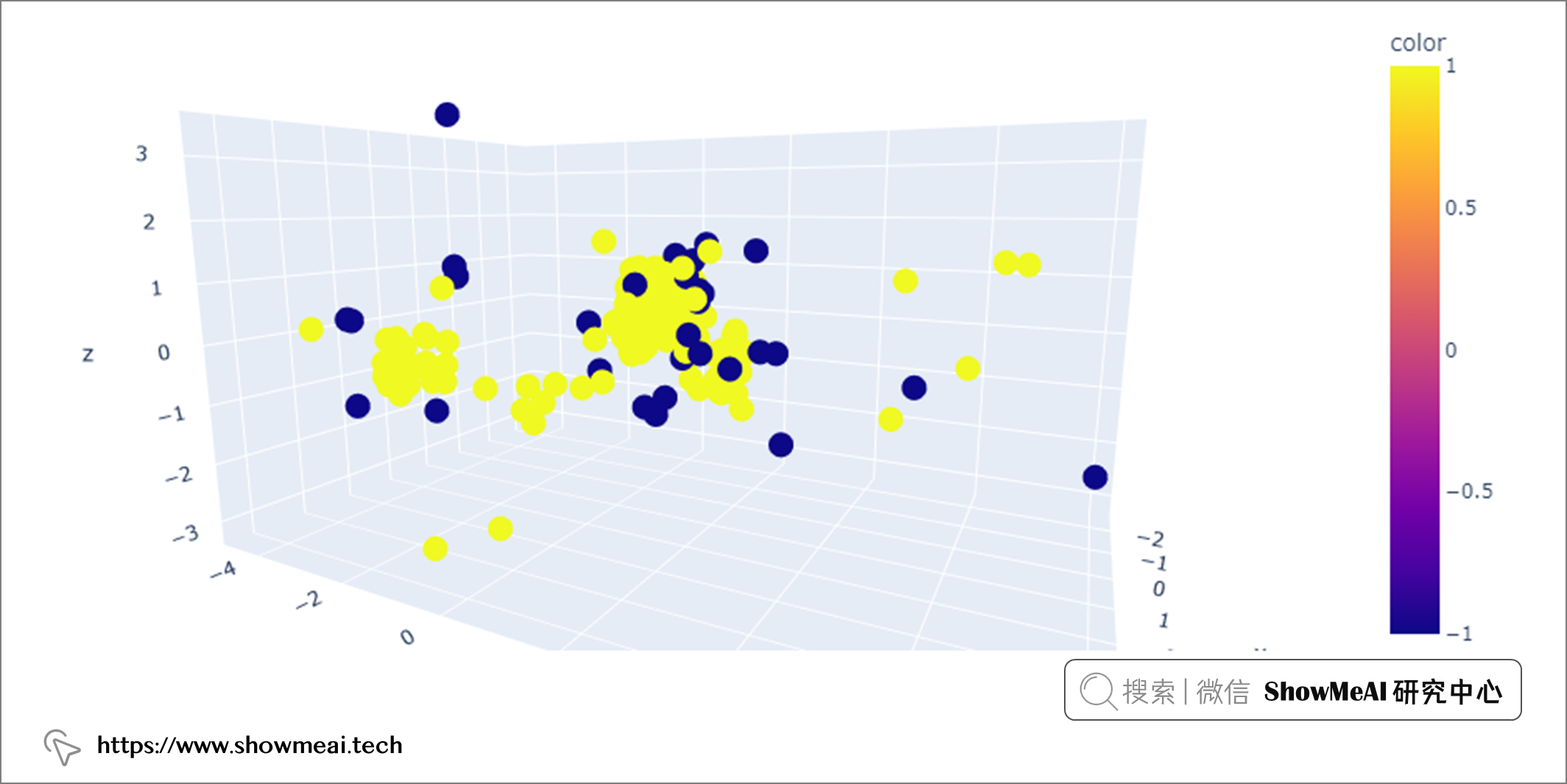
💡 总结
在本文中,我们探索了检测数据集中异常值的不同方法。我们从单变量离群值检测技术开始,涵盖了标准差和四分位距方法。然后,我们转向多变量离群值检测技术,涵盖孤立森林、DBSCAN 和局部离群值因子。通过这些方法,我们学习了如何使用特征空间中的所有维度来检测异常值。除了异常值检测之外,我们还使用了 PCA 降维技术对数据降维和进行可视化。
参考资料
- 📘 Glass Identification 数据集:https://www.kaggle.com/uciml/glass
- 📘 基于统计方法的异常值检测代码实战 :https://showmeai.tech/article-detail/336
- 📘 图解数据分析:从入门到精通系列教程:https://www.showmeai.tech/tutorials/33
- 📘 Python数据分析 | Seaborn工具与数据可视化:https://www.showmeai.tech/article-detail/151
- 📘 数据科学工具库速查表 | Seaborn 速查表:https://www.showmeai.tech/article-detail/105
- 📘图解机器学习 | 降维算法详解:https://showmeai.tech/article-detail/198
- 📘图解机器学习 | 随机森林分类模型详解:https://showmeai.tech/article-detail/191
- 📘 Scikit-Learn 的孤立森林模型:https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html
- 📘 Scikit-Learn 的 DBSCAN模型:https://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html?highlight=dbscan#sklearn.cluster.DBSCAN
- 📘 Scikit-Learn 的局部异常值因子模型:https://scikit-learn.org/stable/auto_examples/neighbors/plot_lof_outlier_detection.html#sphx-glr-auto-examples-neighbors-plot-lof-outlier-detection-py
推荐阅读
- 🌍 数据分析实战系列 :https://www.showmeai.tech/tutorials/40
- 🌍 机器学习数据分析实战系列:https://www.showmeai.tech/tutorials/41
- 🌍 深度学习数据分析实战系列:https://www.showmeai.tech/tutorials/42
- 🌍 TensorFlow数据分析实战系列:https://www.showmeai.tech/tutorials/43
- 🌍 PyTorch数据分析实战系列:https://www.showmeai.tech/tutorials/44
- 🌍 NLP实战数据分析实战系列:https://www.showmeai.tech/tutorials/45
- 🌍 CV实战数据分析实战系列:https://www.showmeai.tech/tutorials/46