第五章.最邻近规则分类(KNN)
5.1 最邻近规则分类(KNN)
1.KNN的计算方式
1).为了判断未知实例的类别,以所有已知类别的实例作为参照选择参数K。
2).计算未知实例与所有已知实例的距离 (利用欧氏距离公式)
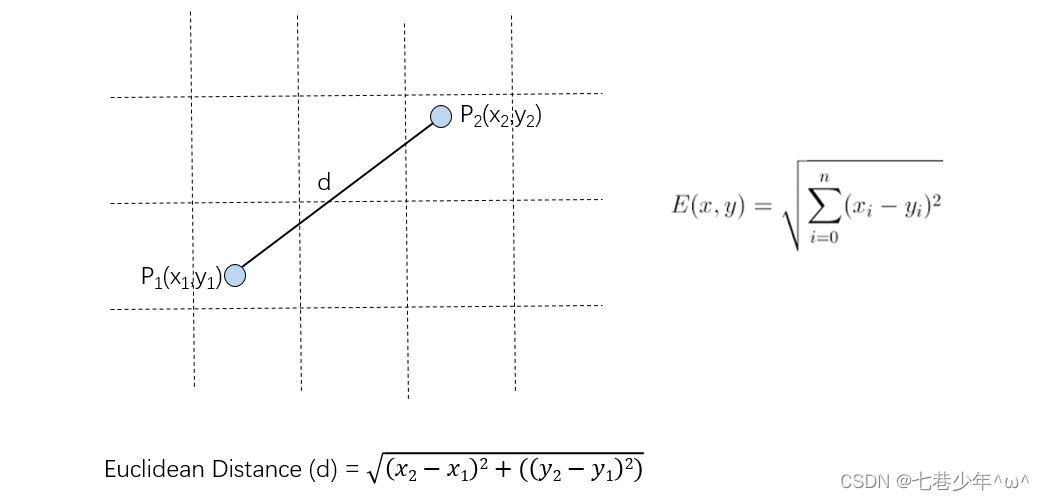
其他距离衡量:余弦值距离(cos), 相关度 (correlation), 曼哈顿距离 (Manhattan distance)链接: 其他距离衡量方式
3).选择最近的K个已知实例
- K的取值:一般取值为单数
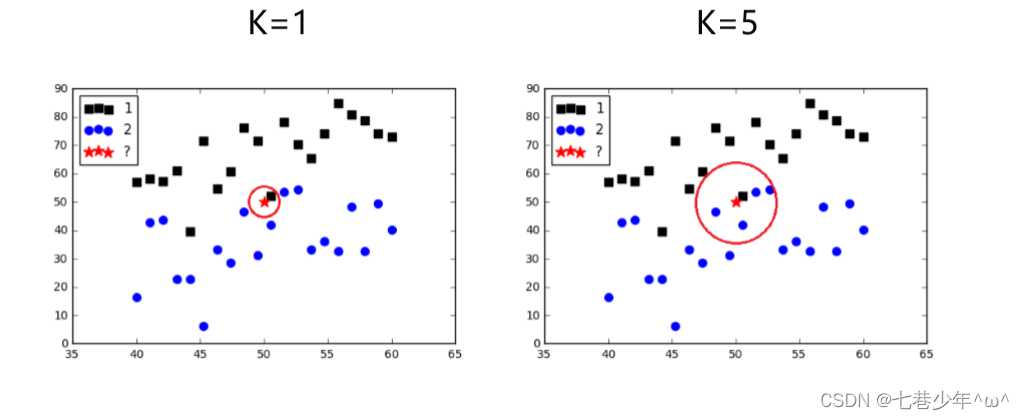
4).根据少数服从多数的投票法则(majority-voting),让未知实例归类为K个最邻近样本中最多数的类别。
2.KNN的缺点
1).算法复杂度高(需要比较所有已知实例与要分类的实例之间的距离)
2).当样本分布不平衡时,比如其中一类样本数量过大,新的未知实例容易被归类为这个主导样本。(原因:因为这类样本实例的数量过大,但这个新的未知实例并没有接近目标样本)

3.简单KNN示例
1).示例:电影类型的分类:判断“未知”是什么类型的电影
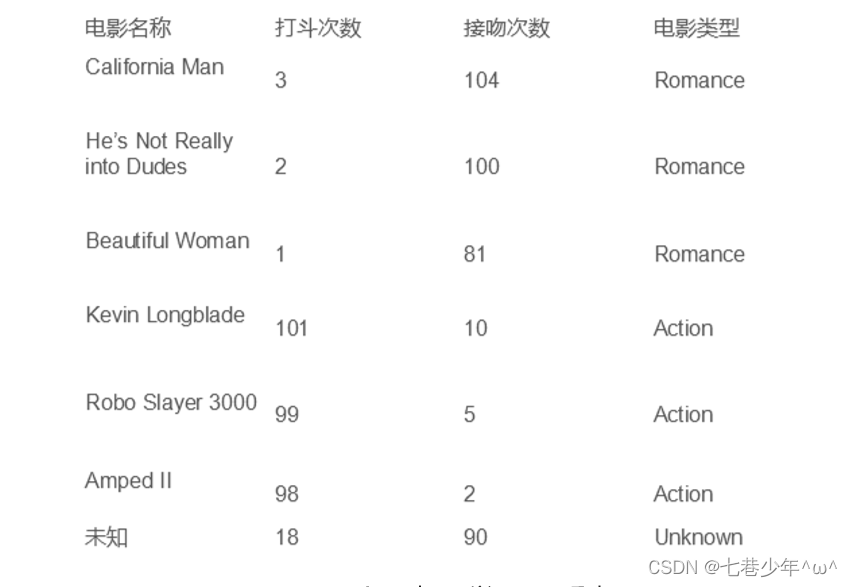
2).代码:
import numpy as np
import matplotlib.pyplot as plt
import operator
# 已知分类数据
x1 = np.array([3, 2, 1])
y1 = np.array([104, 100, 81])
x2 = np.array([101, 99, 98])
y2 = np.array([10, 5, 2])
scatter1 = plt.scatter(x1, y1, c='r')
scatter2 = plt.scatter(x2, y2, c='b')
# 位置数据
x = np.array([18])
y = np.array([90])
scatter3 = plt.scatter(x, y, c='k')
# 绘制图例
plt.legend(handles=[scatter1, scatter2, scatter3], labels=['LabelA', 'LabelB', 'X'], loc='best')
plt.show()
# 已知分类数据
x_data = np.array([[3, 104],
[2, 100],
[1, 81],
[101, 10],
[99, 5],
[81, 2]])
y_data = np.array(['A', 'A', 'A', 'B', 'B', 'B'])
x_test = np.array([18, 90])
# 计算样本数量
x_data_size = x_data.shape[0]
# 复制x_test数据,数据类型与x_data相同
x_test_new = np.tile(x_test, (x_data_size, 1))
# 欧式距离
distance = np.sqrt(np.sum((x_test_new - x_data) ** 2, axis=1))
# 排序:从小到大
sortDistance = distance.argsort()
print(sortDistance)
classCount = {}
# 设置K
k = 5
for i in range(k):
# 获取标签
votelabel = y_data[sortDistance[i]]
# 获取标签数量
classCount[votelabel] = classCount.get(votelabel, 0) + 1 # 返回该元素所对应的值
print(classCount)
# 根据operator.itemgetter(1)-第1个值对classCount排序,然后再取倒序,(classCount.items中包含两部分:key,value)
sortClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
print(sortClassCount)
# 获取数量最多的标签
knnclass = sortClassCount[0][0]
print(knnclass)
3).结果展示:

4.使用Iris数据集的KNN示例 (原理实现)
- 数据属性:萼片长度(sepal length),萼片宽度(sepal width),花瓣长度(petal length),花瓣宽度(petal width)
- 数据类别:Iris setosa, Iris versicolor, Iris virginica
1).代码:
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
import operator
def KNN(x_data, y_data, x_test, k):
# 计算样本数量
x_data_size = x_data.shape[0]
# 赋值x_test数据,类型与x_data相同
x_test_new = np.tile(x_test, (x_data_size, 1))
# 欧氏距离
distances = np.sqrt(np.sum((x_test_new - x_data) ** 2, axis=1))
# 距离按照从小到大的顺序进行排列
sortDistances = distances.argsort()
classCount = {}
for i in range(k):
# 获取标签
votelabel = y_data[sortDistances[i]]
# 统计标签数量
classCount[votelabel] = classCount.get(votelabel, 0) + 1 # 返回该元素所对应的值
# 根据operator.itemgetter(1)-第1个值对classCount排序,然后再取倒序,(classCount.items中包含两部分:key,value)
sortClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortClassCount[0][0]
# 载入数据
iris = load_iris()
# 切分数据
# x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2) # 分割数据0.2为测试数据,0.8为训练数据
# 打乱数据
data_size = iris.data.shape[0]
index = [i for i in range(data_size)]
np.random.shuffle(index)
iris.data = iris.data[index]
iris.target = iris.target[index]
# 切分数据集
test_size = 40
x_train = iris.data[test_size:]
x_test = iris.data[:test_size]
y_train = iris.target[test_size:]
y_test = iris.target[:test_size]
predictions = []
k = 5
for i in range(x_test.shape[0]):
predictions.append(KNN(x_train, y_train, x_test[i], k))
print(classification_report(y_test, predictions))
print(confusion_matrix(y_test, predictions))
2).结果展示:
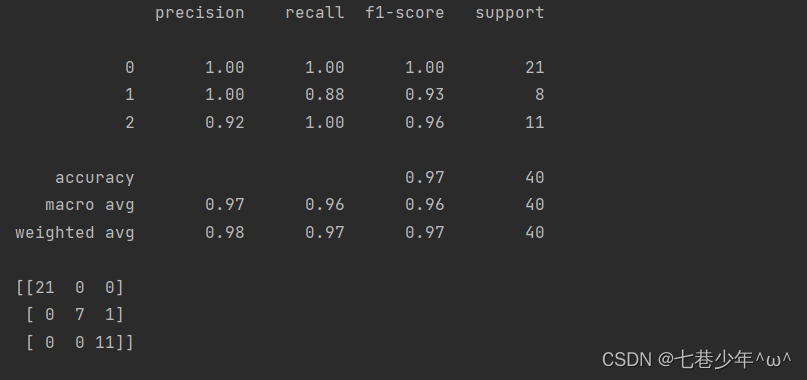
5.使用Iris数据集的KNN示例 (sklearn实现)
- 数据属性:萼片长度(sepal length),萼片宽度(sepal width),花瓣长度(petal length),花瓣宽度(petal width)
- 数据类别:Iris setosa, Iris versicolor, Iris virginica
1).代码:
import operator
import numpy as np
from sklearn import neighbors
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
# 载入数据
iris = load_iris()
# 切分数据
# x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2) # 分割数据0.2为测试数据,0.8为训练数据
# 打乱数据
data_size = iris.data.shape[0]
index = [i for i in range(data_size)]
np.random.shuffle(index)
iris.data = iris.data[index]
iris.target = iris.target[index]
# 切分数据集
test_size = 40
x_train = iris.data[test_size:]
x_test = iris.data[:test_size]
y_train = iris.target[test_size:]
y_test = iris.target[:test_size]
# 创建模型
knn_model = neighbors.KNeighborsClassifier(n_neighbors=3)
knn_model.fit(x_train, y_train)
predictions = knn_model.predict(x_test)
print(classification_report(y_test, predictions))
print(confusion_matrix(y_test, predictions))
2).结果展示: