一文搞懂 Redis 中的缓存穿透、缓存击穿、缓存雪崩及其解决方案
- 1. 缓存穿透
- 1.1 什么是缓存穿透
- 1.2 缓存穿透的解决方案
- 1.2.1 缓存空对象
- 1.2.2 布隆过滤器
- 布隆过滤器工作原理
- Redis 使用布隆过滤器
- 2. 缓存击穿
- 1.1 什么是缓存击穿
- 1.2 缓存击穿的解决方案
- 1.2.1 设置热点数据永不过期
- 物理不过期
- 逻辑不过期
- 1.2.2 分布式锁
- 3. 缓存雪崩
- 1.1 什么是缓存雪崩
- 1.2 缓存雪崩的解决方案
- 1.2.1 均匀过期
- 1.2.2 加分布式锁
- 1.2.3 缓存永不过期
在生产环境中使用 Redis 的时候,有时遇到缓存异常的场景:缓存穿透、缓存击穿、缓存雪崩等。学习这些缓存异常出现的原因及其解决办法,能够帮助我们提高系统的可靠性和可用性。
先来看一张图,大致了解一下 缓存穿透、缓存击穿、缓存雪崩 的描述和解决方案:

1. 缓存穿透
1.1 什么是缓存穿透
缓存穿透是指客户端查询一个缓存、数据库都不存在的数据,导致客户端每次请求数据都会透过缓存,直接查询数据库,返回 null 给客户端。
如果有恶意攻击者不断请求系统中不存在的数据,会导致短时间大量请求落在数据库上,造成数据库压力过大,甚至击垮数据库系统。
1.2 缓存穿透的解决方案
1.2.1 缓存空对象
如果缓存、数据库里都没数据 -> 缓存设置一个空缓存 -> key: {}
伪代码:
goods = redisUtil.get(goodsKey);
if (goods.equals("{}")) {
return null;
}
if (goods == null) {
goods = queryMySQL();
if(goods = null){
redisUtil.set(goodsKey, "{}");
return null;
}
redisUtil.set(goodsKey, goods);
return goods;
}
问题:可能会存在大量空缓存,占用缓存空间。
解决方案:设置缓存过期时间 -> 3min 过期,请求同一个商品设置 key 延期(在这段时间可能会存在缓存和持久层数据不一致的场景)。
1.2.2 布隆过滤器
Redis 布隆过滤器
布隆过滤器工作原理
布隆过滤器(Bloom Filter)是一个高空间利用率的概率性数据结构,由二进制向量(即位数组)和一系列随机映射函数(即哈希函数)两部分组成。
布隆过滤器使用exists()来判断某个元素是否存在于自身结构中。当布隆过滤器判定某个值存在时,其实这个值只是有可能存在(这个误判概率大约在 1% 左右);当它说某个值不存在时,那这个值肯定不存在。
- 工作流程 - 添加元素
布隆过滤器主要由位数组和一系列 hash 函数构成,其中位数组的初始状态都为 0。
下面对布隆过滤器工作流程做简单描述,如下图所示:
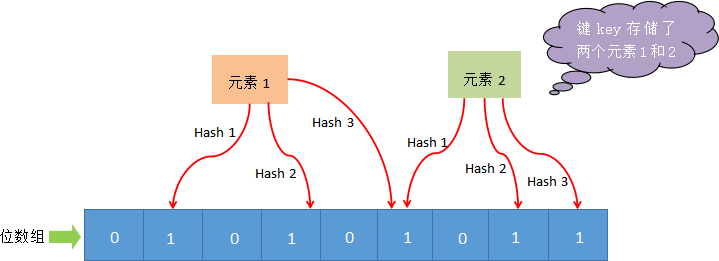
当使用布隆过滤器添加 key 时,会使用不同的 hash 函数对 key 存储的元素值进行哈希计算,从而会得到多个哈希值。根据哈希值计算出一个整数索引值,将该索引值与位数组长度做取余运算,最终得到一个位数组位置,并将该位置的值变为 1。每个 hash 函数都会计算出一个不同的位置,然后把数组中与之对应的位置变为 1。通过上述过程就完成了元素添加(add)操作。
- 工作流程 - 判定元素是否存在
当我们需要判断一个元素是否存时,其流程如下:首先对给定元素再次执行哈希计算,得到与添加元素时相同的位数组位置,判断所得位置是否都为 1,如果其中有一个为 0,那么说明元素不存在,若都为 1,则说明元素有可能存在。
- 为什么是可能 “存在”
那些被置为 1 的位置也可能是由于其他元素的操作而改变的。比如,元素1 和 元素2,这两个元素同时将一个位置变为了 1(图1所示)。在这种情况下,我们就不能判定 “元素 1” 一定存在,这是布隆过滤器存在误判的根本原因。
Redis 使用布隆过滤器
-
将元素添加到布隆过滤器;
-
判断元素是否存在布隆过滤器;
-
不存在则返回 null,存在则查询缓存、数据库。
2. 缓存击穿
1.1 什么是缓存击穿
缓存击穿是指,当缓存中的某个热点数据(key)过期了,在该热点数据重新载入之前,有大量的请求穿过缓存,直接查询数据库。这种情况会导致数据库压力瞬间骤增,造成大量请求阻塞,甚至直接挂掉。
1.2 缓存击穿的解决方案
1.2.1 设置热点数据永不过期
永不过期实际包含两层意思:
物理不过期
针对热点 key 不设置过期时间
逻辑不过期
把过期时间存在 key 对应的 value 里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建
从实战看这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,对于不追求严格强一致性的系统是可以接受的。
1.2.2 分布式锁
锁的对象就是 key,这样,当大量查询同一个 key 的请求并发进来时,只能有一个请求获取到锁,然后获取到锁的线程查询数据库,然后将结果放入到缓存中,然后释放锁,此时,其他处于锁等待的请求即可继续执行,由于此时缓存中已经有了数据,所以直接从缓存中获取到数据返回,并不会查询数据库。
3. 缓存雪崩
1.1 什么是缓存雪崩
缓存雪崩是指,当缓存中有大量的 key 在同一时刻过期,或者 Redis 直接宕机了,导致大量的查询请求全部到达数据库,造成数据库查询压力骤增,甚至直接挂掉。
1.2 缓存雪崩的解决方案
针对缓存中有大量的 key 在同一时刻过期,出现缓存雪崩,有如下方案:
1.2.1 均匀过期
设置不同的过期时间,让缓存失效的时间点尽量均匀。通常可以为有效期增加随机值或者统一规划有效期。
1.2.2 加分布式锁
跟缓存击穿解决思路一致,同一时间只让一个线程构建缓存,其他线程阻塞排队。
1.2.3 缓存永不过期
跟缓存击穿解决思路一致,缓存在物理上永远不过期,用一个异步的线程更新缓存。
对于 Redis 直接宕机出现缓存雪崩:
部署 Redis 时可以使用 Redis 的几种高可用方案部署:
- 主从(masterslave)架构
- 哨兵(sentinel)机制
- Redis集群(Redis Cluster)机构